 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Source-Free Machine Unlearning
Aug 20, 2025



As machine learning becomes more pervasive and data privacy regulations evolve, the ability to remove private or copyrighted information from trained models is becoming an increasingly critical requirement. Existing unlearning methods often rely on the assumption of having access to the entire training dataset during the forgetting process. However, this assumption may not hold true in practical scenarios where the original training data may not be accessible, i.e., the source-free setting. To address this challenge, we focus on the source-free unlearning scenario, where an unlearning algorithm must be capable of removing specific data from a trained model without requiring access to the original training dataset. Building on recent work, we present a method that can estimate the Hessian of the unknown remaining training data, a crucial component required for efficient unlearning. Leveraging this estimation technique, our method enables efficient zero-shot unlearning while providing robust theoretical guarantees on the unlearning performance, while maintaining performance on the remaining data. Extensive experiments over a wide range of datasets verify the efficacy of our method.
A Certified Unlearning Approach without Access to Source Data
Jun 06, 2025



With the growing adoption of data privacy regulations, the ability to erase private or copyrighted information from trained models has become a crucial requirement. Traditional unlearning methods often assume access to the complete training dataset, which is unrealistic in scenarios where the source data is no longer available. To address this challenge, we propose a certified unlearning framework that enables effective data removal \final{without access to the original training data samples}. Our approach utilizes a surrogate dataset that approximates the statistical properties of the source data, allowing for controlled noise scaling based on the statistical distance between the two. \updated{While our theoretical guarantees assume knowledge of the exact statistical distance, practical implementations typically approximate this distance, resulting in potentially weaker but still meaningful privacy guarantees.} This ensures strong guarantees on the model's behavior post-unlearning while maintaining its overall utility. We establish theoretical bounds, introduce practical noise calibration techniques, and validate our method through extensive experiments on both synthetic and real-world datasets. The results demonstrate the effectiveness and reliability of our approach in privacy-sensitive settings.
Gradient Inversion Attacks on Parameter-Efficient Fine-Tuning
Jun 04, 2025Federated learning (FL) allows multiple data-owners to collaboratively train machine learning models by exchanging local gradients, while keeping their private data on-device. To simultaneously enhance privacy and training efficiency, recently parameter-efficient fine-tuning (PEFT) of large-scale pretrained models has gained substantial attention in FL. While keeping a pretrained (backbone) model frozen, each user fine-tunes only a few lightweight modules to be used in conjunction, to fit specific downstream applications. Accordingly, only the gradients with respect to these lightweight modules are shared with the server. In this work, we investigate how the privacy of the fine-tuning data of the users can be compromised via a malicious design of the pretrained model and trainable adapter modules. We demonstrate gradient inversion attacks on a popular PEFT mechanism, the adapter, which allow an attacker to reconstruct local data samples of a target user, using only the accessible adapter gradients. Via extensive experiments, we demonstrate that a large batch of fine-tuning images can be retrieved with high fidelity. Our attack highlights the need for privacy-preserving mechanisms for PEFT, while opening up several future directions. Our code is available at https://github.com/info-ucr/PEFTLeak.
FLASH: Federated Learning Across Simultaneous Heterogeneities
Feb 13, 2024



The key premise of federated learning (FL) is to train ML models across a diverse set of data-owners (clients), without exchanging local data. An overarching challenge to this date is client heterogeneity, which may arise not only from variations in data distribution, but also in data quality, as well as compute/communication latency. An integrated view of these diverse and concurrent sources of heterogeneity is critical; for instance, low-latency clients may have poor data quality, and vice versa. In this work, we propose FLASH(Federated Learning Across Simultaneous Heterogeneities), a lightweight and flexible client selection algorithm that outperforms state-of-the-art FL frameworks under extensive sources of heterogeneity, by trading-off the statistical information associated with the client's data quality, data distribution, and latency. FLASH is the first method, to our knowledge, for handling all these heterogeneities in a unified manner. To do so, FLASH models the learning dynamics through contextual multi-armed bandits (CMAB) and dynamically selects the most promising clients. Through extensive experiments, we demonstrate that FLASH achieves substantial and consistent improvements over state-of-the-art baselines -- as much as 10% in absolute accuracy -- thanks to its unified approach. Importantly, FLASH also outperforms federated aggregation methods that are designed to handle highly heterogeneous settings and even enjoys a performance boost when integrated with them.
Plug-and-Play Transformer Modules for Test-Time Adaptation
Jan 10, 2024



Parameter-efficient tuning (PET) methods such as LoRA, Adapter, and Visual Prompt Tuning (VPT) have found success in enabling adaptation to new domains by tuning small modules within a transformer model. However, the number of domains encountered during test time can be very large, and the data is usually unlabeled. Thus, adaptation to new domains is challenging; it is also impractical to generate customized tuned modules for each such domain. Toward addressing these challenges, this work introduces PLUTO: a Plug-and-pLay modUlar Test-time domain adaptatiOn strategy. We pre-train a large set of modules, each specialized for different source domains, effectively creating a ``module store''. Given a target domain with few-shot unlabeled data, we introduce an unsupervised test-time adaptation (TTA) method to (1) select a sparse subset of relevant modules from this store and (2) create a weighted combination of selected modules without tuning their weights. This plug-and-play nature enables us to harness multiple most-relevant source domains in a single inference call. Comprehensive evaluations demonstrate that PLUTO uniformly outperforms alternative TTA methods and that selecting $\leq$5 modules suffice to extract most of the benefit. At a high level, our method equips pre-trained transformers with the capability to dynamically adapt to new domains, motivating a new paradigm for efficient and scalable domain adaptation.
Sparsified Secure Aggregation for Privacy-Preserving Federated Learning
Dec 23, 2021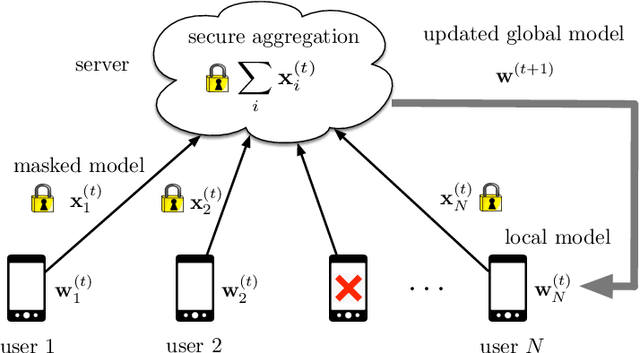
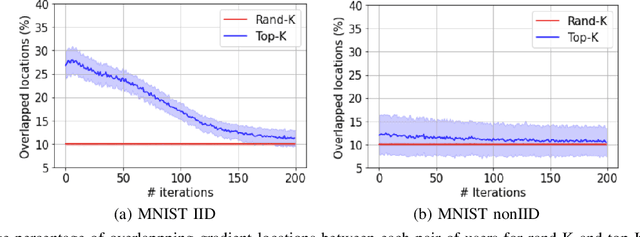
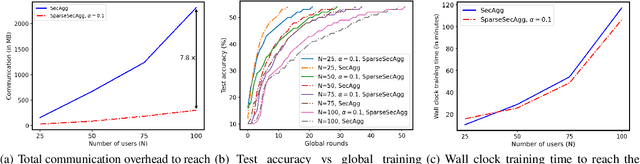
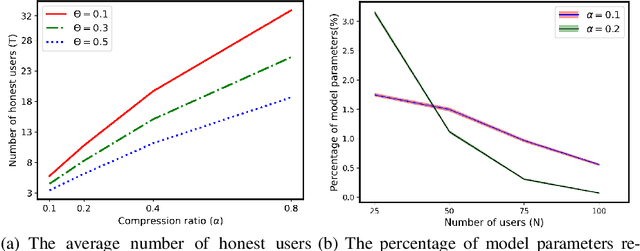
Secure aggregation is a popular protocol in privacy-preserving federated learning, which allows model aggregation without revealing the individual models in the clear. On the other hand, conventional secure aggregation protocols incur a significant communication overhead, which can become a major bottleneck in real-world bandwidth-limited applications. Towards addressing this challenge, in this work we propose a lightweight gradient sparsification framework for secure aggregation, in which the server learns the aggregate of the sparsified local model updates from a large number of users, but without learning the individual parameters. Our theoretical analysis demonstrates that the proposed framework can significantly reduce the communication overhead of secure aggregation while ensuring comparable computational complexity. We further identify a trade-off between privacy and communication efficiency due to sparsification. Our experiments demonstrate that our framework reduces the communication overhead by up to 7.8x, while also speeding up the wall clock training time by 1.13x, when compared to conventional secure aggregation benchmarks.
Securing Secure Aggregation: Mitigating Multi-Round Privacy Leakage in Federated Learning
Jun 07, 2021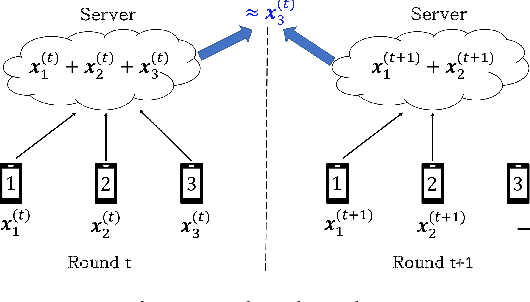
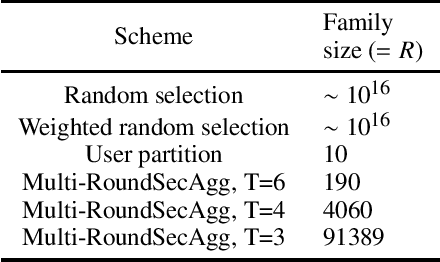
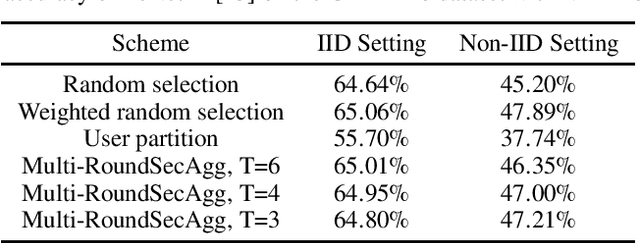
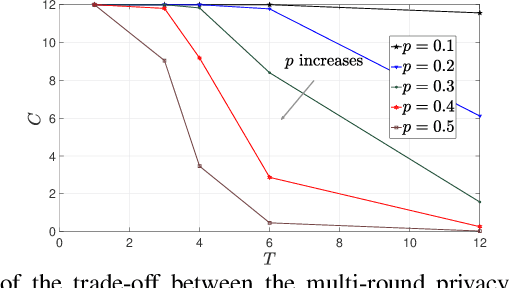
Secure aggregation is a critical component in federated learning, which enables the server to learn the aggregate model of the users without observing their local models. Conventionally, secure aggregation algorithms focus only on ensuring the privacy of individual users in a single training round. We contend that such designs can lead to significant privacy leakages over multiple training rounds, due to partial user selection/participation at each round of federated learning. In fact, we empirically show that the conventional random user selection strategies for federated learning lead to leaking users' individual models within number of rounds linear in the number of users. To address this challenge, we introduce a secure aggregation framework with multi-round privacy guarantees. In particular, we introduce a new metric to quantify the privacy guarantees of federated learning over multiple training rounds, and develop a structured user selection strategy that guarantees the long-term privacy of each user (over any number of training rounds). Our framework also carefully accounts for the fairness and the average number of participating users at each round. We perform several experiments on MNIST and CIFAR-10 datasets in the IID and the non-IID settings to demonstrate the performance improvement over the baseline algorithms, both in terms of privacy protection and test accuracy.
Sustainable Federated Learning
Feb 22, 2021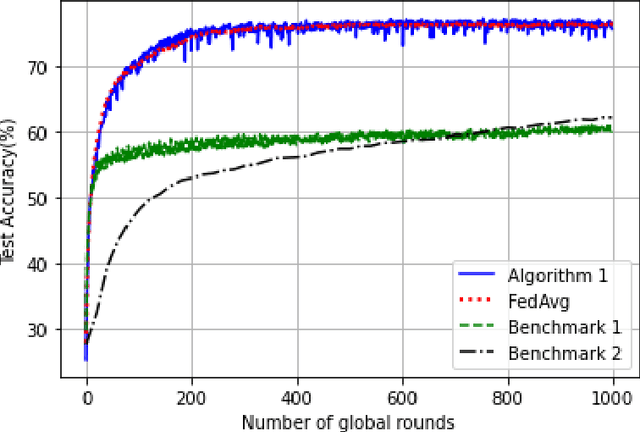
Potential environmental impact of machine learning by large-scale wireless networks is a major challenge for the sustainability of future smart ecosystems. In this paper, we introduce sustainable machine learning in federated learning settings, using rechargeable devices that can collect energy from the ambient environment. We propose a practical federated learning framework that leverages intermittent energy arrivals for training, with provable convergence guarantees. Our framework can be applied to a wide range of machine learning settings in networked environments, including distributed and federated learning in wireless and edge networks. Our experiments demonstrate that the proposed framework can provide significant performance improvement over the benchmark energy-agnostic federated learning settings.
Energy-Harvesting Distributed Machine Learning
Feb 10, 2021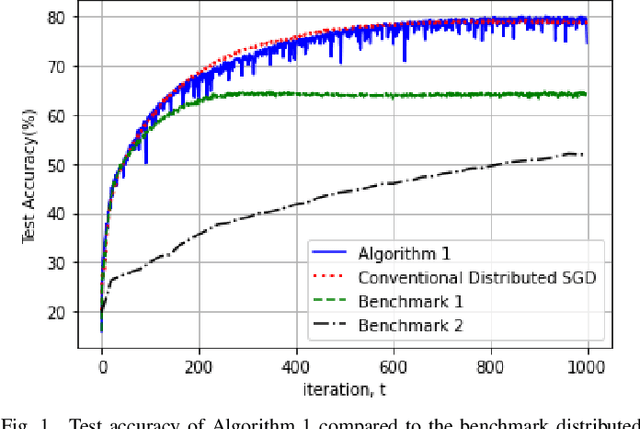
This paper provides a first study of utilizing energy harvesting for sustainable machine learning in distributed networks. We consider a distributed learning setup in which a machine learning model is trained over a large number of devices that can harvest energy from the ambient environment, and develop a practical learning framework with theoretical convergence guarantees. We demonstrate through numerical experiments that the proposed framework can significantly outperform energy-agnostic benchmarks. Our framework is scalable, requires only local estimation of the energy statistics, and can be applied to a wide range of distributed training settings, including machine learning in wireless networks, edge computing, and mobile internet of things.
A Scalable Approach for Privacy-Preserving Collaborative Machine Learning
Nov 03, 2020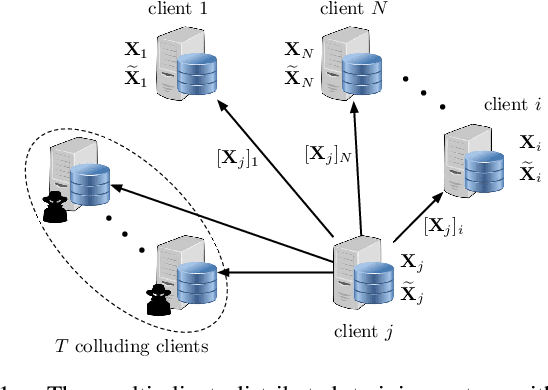

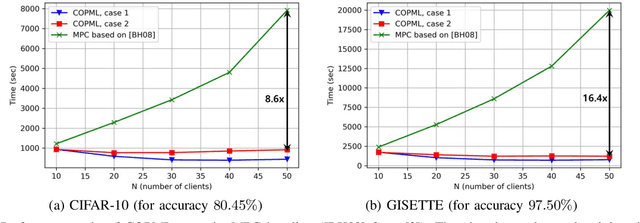
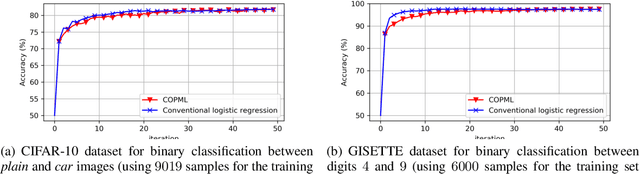
We consider a collaborative learning scenario in which multiple data-owners wish to jointly train a logistic regression model, while keeping their individual datasets private from the other parties. We propose COPML, a fully-decentralized training framework that achieves scalability and privacy-protection simultaneously. The key idea of COPML is to securely encode the individual datasets to distribute the computation load effectively across many parties and to perform the training computations as well as the model updates in a distributed manner on the securely encoded data. We provide the privacy analysis of COPML and prove its convergence. Furthermore, we experimentally demonstrate that COPML can achieve significant speedup in training over the benchmark protocols. Our protocol provides strong statistical privacy guarantees against colluding parties (adversaries) with unbounded computational power, while achieving up to $16\times$ speedup in the training time against the benchmark protocols.