 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiQ: Bringing back Bellman to LLMs
May 16, 2025



The fine-tuning of pre-trained large language models (LLMs) using reinforcement learning (RL) is generally formulated as direct policy optimization. This approach was naturally favored as it efficiently improves a pretrained LLM, seen as an initial policy. Another RL paradigm, Q-learning methods, has received far less attention in the LLM community while demonstrating major success in various non-LLM RL tasks. In particular, Q-learning effectiveness comes from its sample efficiency and ability to learn offline, which is particularly valuable given the high computational cost of sampling with LLMs. However, naively applying a Q-learning-style update to the model's logits is ineffective due to the specificity of LLMs. Our core contribution is to derive theoretically grounded loss functions from Bellman equations to adapt Q-learning methods to LLMs. To do so, we carefully adapt insights from the RL literature to account for LLM-specific characteristics, ensuring that the logits become reliable Q-value estimates. We then use this loss to build a practical algorithm, ShiQ for Shifted-Q, that supports off-policy, token-wise learning while remaining simple to implement. Finally, we evaluate ShiQ on both synthetic data and real-world benchmarks, e.g., UltraFeedback and BFCL-V3, demonstrating its effectiveness in both single-turn and multi-turn LLM settings
Sparsified Secure Aggregation for Privacy-Preserving Federated Learning
Dec 23, 2021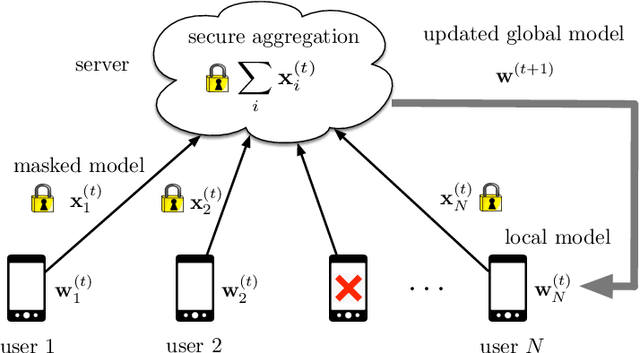
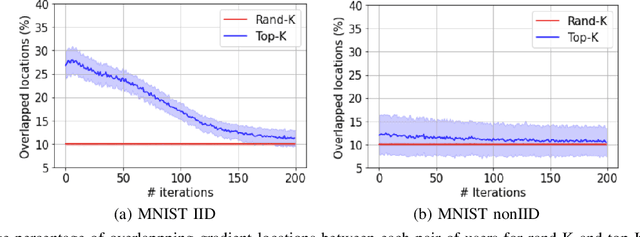
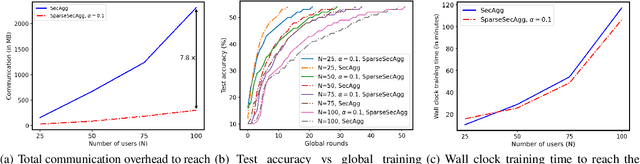
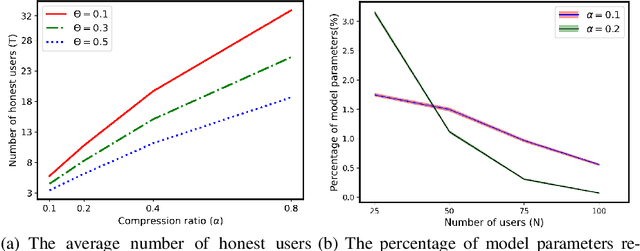
Secure aggregation is a popular protocol in privacy-preserving federated learning, which allows model aggregation without revealing the individual models in the clear. On the other hand, conventional secure aggregation protocols incur a significant communication overhead, which can become a major bottleneck in real-world bandwidth-limited applications. Towards addressing this challenge, in this work we propose a lightweight gradient sparsification framework for secure aggregation, in which the server learns the aggregate of the sparsified local model updates from a large number of users, but without learning the individual parameters. Our theoretical analysis demonstrates that the proposed framework can significantly reduce the communication overhead of secure aggregation while ensuring comparable computational complexity. We further identify a trade-off between privacy and communication efficiency due to sparsification. Our experiments demonstrate that our framework reduces the communication overhead by up to 7.8x, while also speeding up the wall clock training time by 1.13x, when compared to conventional secure aggregation benchmarks.