 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll Rivers Run to the Sea: Private Learning with Asymmetric Flows
Dec 05, 2023



Data privacy is of great concern in cloud machine-learning service platforms, when sensitive data are exposed to service providers. While private computing environments (e.g., secure enclaves), and cryptographic approaches (e.g., homomorphic encryption) provide strong privacy protection, their computing performance still falls short compared to cloud GPUs. To achieve privacy protection with high computing performance, we propose Delta, a new private training and inference framework, with comparable model performance as non-private centralized training. Delta features two asymmetric data flows: the main information-sensitive flow and the residual flow. The main part flows into a small model while the residuals are offloaded to a large model. Specifically, Delta embeds the information-sensitive representations into a low-dimensional space while pushing the information-insensitive part into high-dimension residuals. To ensure privacy protection, the low-dimensional information-sensitive part is secured and fed to a small model in a private environment. On the other hand, the residual part is sent to fast cloud GPUs, and processed by a large model. To further enhance privacy and reduce the communication cost, Delta applies a random binary quantization technique along with a DP-based technique to the residuals before sharing them with the public platform. We theoretically show that Delta guarantees differential privacy in the public environment and greatly reduces the complexity in the private environment. We conduct empirical analyses on CIFAR-10, CIFAR-100 and ImageNet datasets and ResNet-18 and ResNet-34, showing that Delta achieves strong privacy protection, fast training, and inference without significantly compromising the model utility.
Secure Aggregation for Buffered Asynchronous Federated Learning
Oct 05, 2021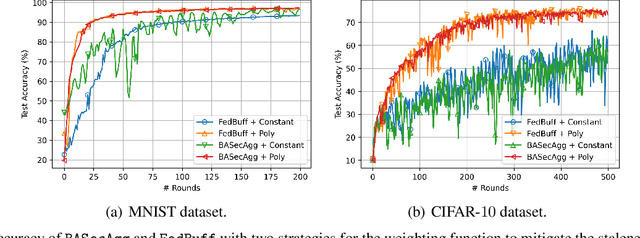
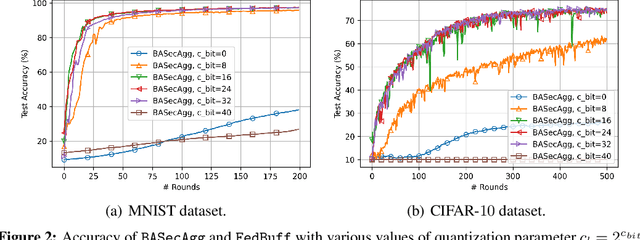
Federated learning (FL) typically relies on synchronous training, which is slow due to stragglers. While asynchronous training handles stragglers efficiently, it does not ensure privacy due to the incompatibility with the secure aggregation protocols. A buffered asynchronous training protocol known as FedBuff has been proposed recently which bridges the gap between synchronous and asynchronous training to mitigate stragglers and to also ensure privacy simultaneously. FedBuff allows the users to send their updates asynchronously while ensuring privacy by storing the updates in a trusted execution environment (TEE) enabled private buffer. TEEs, however, have limited memory which limits the buffer size. Motivated by this limitation, we develop a buffered asynchronous secure aggregation (BASecAgg) protocol that does not rely on TEEs. The conventional secure aggregation protocols cannot be applied in the buffered asynchronous setting since the buffer may have local models corresponding to different rounds and hence the masks that the users use to protect their models may not cancel out. BASecAgg addresses this challenge by carefully designing the masks such that they cancel out even if they correspond to different rounds. Our convergence analysis and experiments show that BASecAgg almost has the same convergence guarantees as FedBuff without relying on TEEs.
ApproxIFER: A Model-Agnostic Approach to Resilient and Robust Prediction Serving Systems
Sep 20, 2021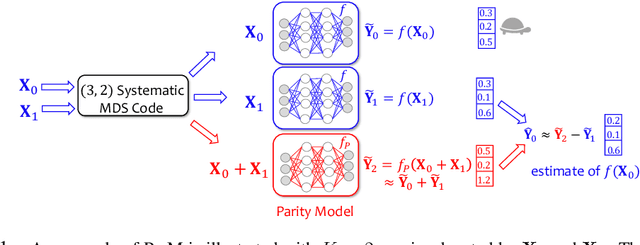
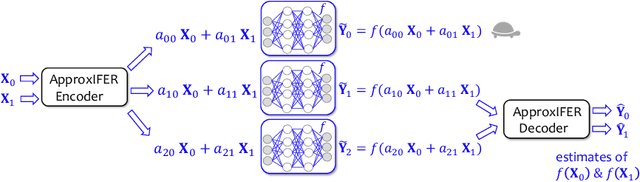
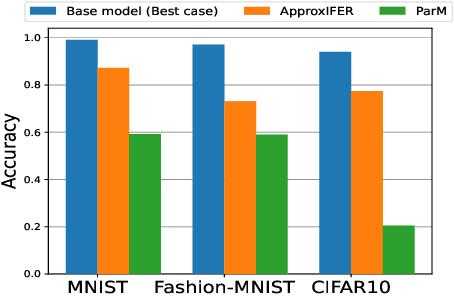
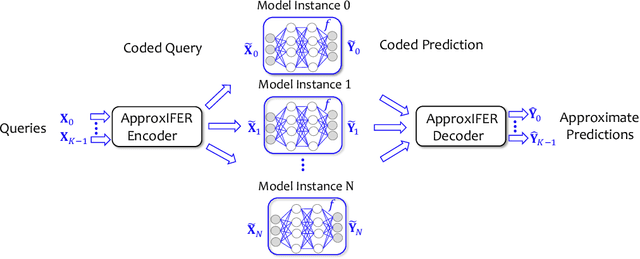
Due to the surge of cloud-assisted AI services, the problem of designing resilient prediction serving systems that can effectively cope with stragglers/failures and minimize response delays has attracted much interest. The common approach for tackling this problem is replication which assigns the same prediction task to multiple workers. This approach, however, is very inefficient and incurs significant resource overheads. Hence, a learning-based approach known as parity model (ParM) has been recently proposed which learns models that can generate parities for a group of predictions in order to reconstruct the predictions of the slow/failed workers. While this learning-based approach is more resource-efficient than replication, it is tailored to the specific model hosted by the cloud and is particularly suitable for a small number of queries (typically less than four) and tolerating very few (mostly one) number of stragglers. Moreover, ParM does not handle Byzantine adversarial workers. We propose a different approach, named Approximate Coded Inference (ApproxIFER), that does not require training of any parity models, hence it is agnostic to the model hosted by the cloud and can be readily applied to different data domains and model architectures. Compared with earlier works, ApproxIFER can handle a general number of stragglers and scales significantly better with the number of queries. Furthermore, ApproxIFER is robust against Byzantine workers. Our extensive experiments on a large number of datasets and model architectures also show significant accuracy improvement by up to 58% over the parity model approaches.
Verifiable Coded Computing: Towards Fast, Secure and Private Distributed Machine Learning
Jul 27, 2021
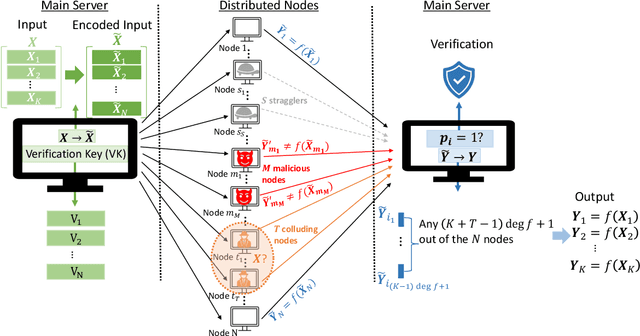
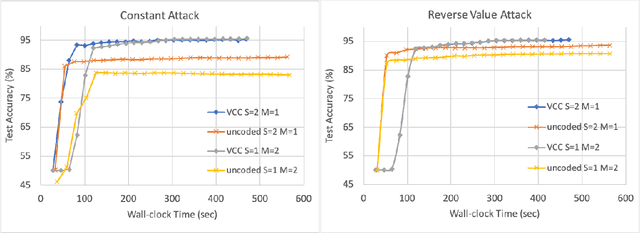
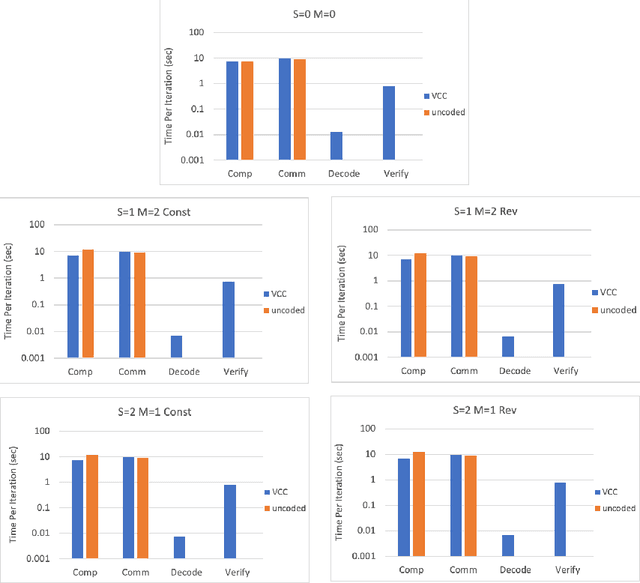
Stragglers, Byzantine workers, and data privacy are the main bottlenecks in distributed cloud computing. Several prior works proposed coded computing strategies to jointly address all three challenges. They require either a large number of workers, a significant communication cost or a significant computational complexity to tolerate malicious workers. Much of the overhead in prior schemes comes from the fact that they tightly couple coding for all three problems into a single framework. In this work, we propose Verifiable Coded Computing (VCC) framework that decouples Byzantine node detection challenge from the straggler tolerance. VCC leverages coded computing just for handling stragglers and privacy, and then uses an orthogonal approach of verifiable computing to tackle Byzantine nodes. Furthermore, VCC dynamically adapts its coding scheme to tradeoff straggler tolerance with Byzantine protection and vice-versa. We evaluate VCC on compute intensive distributed logistic regression application. Our experiments show that VCC speeds up the conventional uncoded implementation of distributed logistic regression by $3.2\times-6.9\times$, and also improves the test accuracy by up to $12.6\%$.
Securing Secure Aggregation: Mitigating Multi-Round Privacy Leakage in Federated Learning
Jun 07, 2021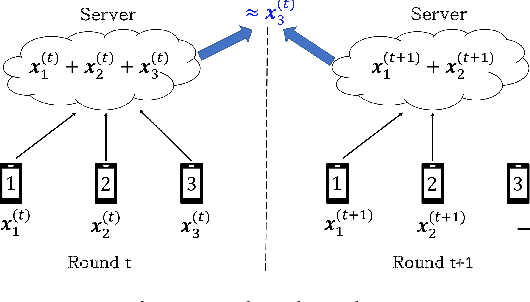
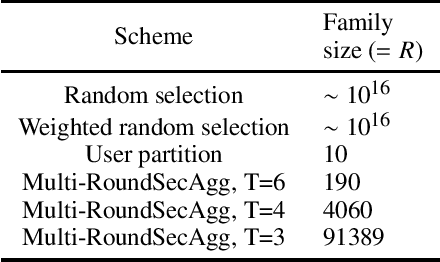
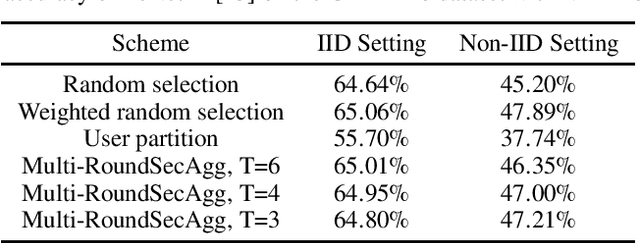
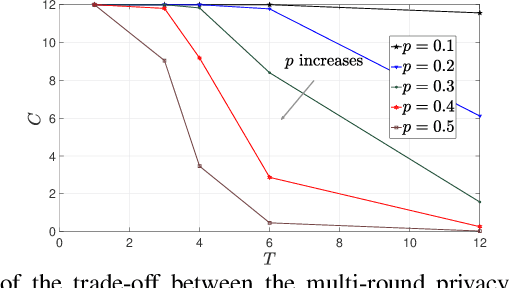
Secure aggregation is a critical component in federated learning, which enables the server to learn the aggregate model of the users without observing their local models. Conventionally, secure aggregation algorithms focus only on ensuring the privacy of individual users in a single training round. We contend that such designs can lead to significant privacy leakages over multiple training rounds, due to partial user selection/participation at each round of federated learning. In fact, we empirically show that the conventional random user selection strategies for federated learning lead to leaking users' individual models within number of rounds linear in the number of users. To address this challenge, we introduce a secure aggregation framework with multi-round privacy guarantees. In particular, we introduce a new metric to quantify the privacy guarantees of federated learning over multiple training rounds, and develop a structured user selection strategy that guarantees the long-term privacy of each user (over any number of training rounds). Our framework also carefully accounts for the fairness and the average number of participating users at each round. We perform several experiments on MNIST and CIFAR-10 datasets in the IID and the non-IID settings to demonstrate the performance improvement over the baseline algorithms, both in terms of privacy protection and test accuracy.
List-Decodable Coded Computing: Breaking the Adversarial Toleration Barrier
Jan 27, 2021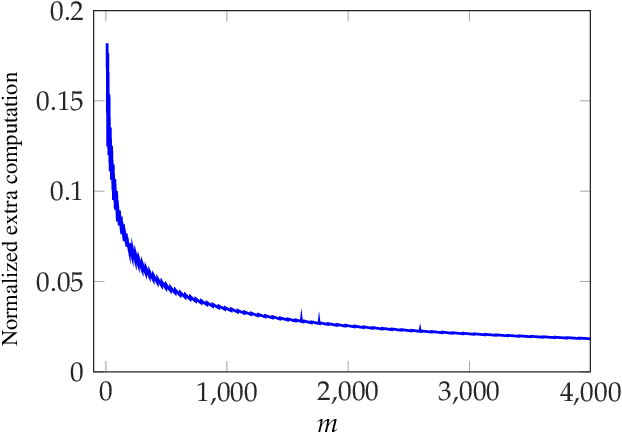
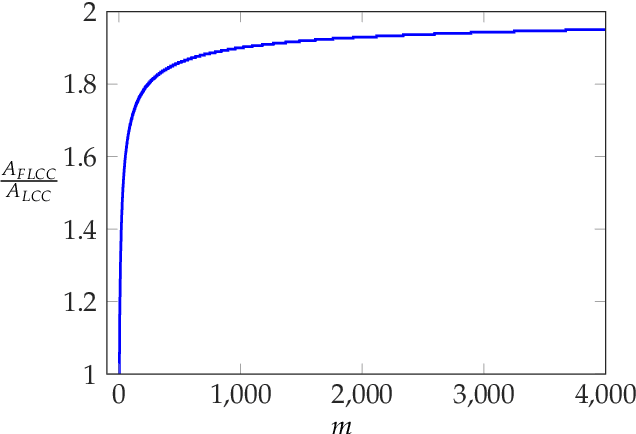
We consider the problem of coded computing where a computational task is performed in a distributed fashion in the presence of adversarial workers. We propose techniques to break the adversarial toleration threshold barrier previously known in coded computing. More specifically, we leverage list-decoding techniques for folded Reed-Solomon (FRS) codes and propose novel algorithms to recover the correct codeword using side information. In the coded computing setting, we show how the master node can perform certain carefully designed extra computations in order to obtain the side information. This side information will be then utilized to prune the output of list decoder in order to uniquely recover the true outcome. We further propose folded Lagrange coded computing, referred to as folded LCC or FLCC, to incorporate the developed techniques into a specific coded computing setting. Our results show that FLCC outperforms LCC by breaking the barrier on the number of adversaries that can be tolerated. In particular, the corresponding threshold in FLCC is improved by a factor of two compared to that of LCC.
On Polynomial Approximations for Privacy-Preserving and Verifiable ReLU Networks
Nov 11, 2020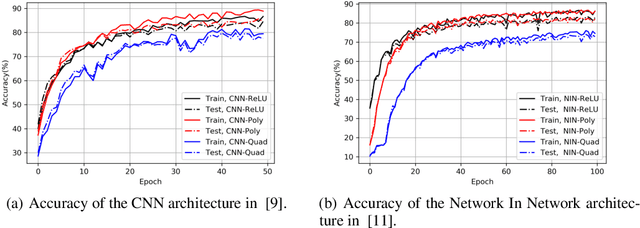
Outsourcing neural network inference tasks to an untrusted cloud raises data privacy and integrity concerns. In order to address these challenges, several privacy-preserving and verifiable inference techniques have been proposed based on replacing the non-polynomial activation functions such as the rectified linear unit (ReLU) function with polynomial activation functions. Such techniques usually require the polynomial coefficients to be in a finite field. Motivated by such requirements, several works proposed replacing the ReLU activation function with the square activation function. In this work, we empirically show that the square function is not the best second-degree polynomial that can replace the ReLU function in deep neural networks. We instead propose a second-degree polynomial activation function with a first order term and empirically show that it can lead to much better models. Our experiments on the CIFAR-$10$ dataset show that our proposed polynomial activation function significantly outperforms the square activation function.
Hierarchical Deep Double Q-Routing
Nov 20, 2019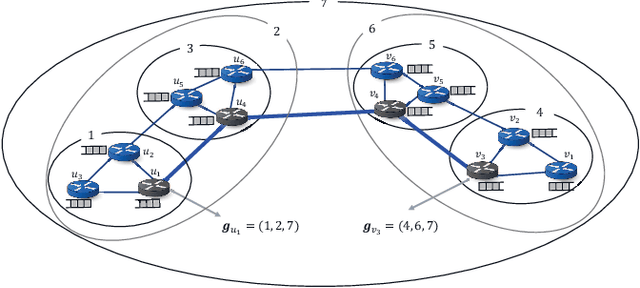
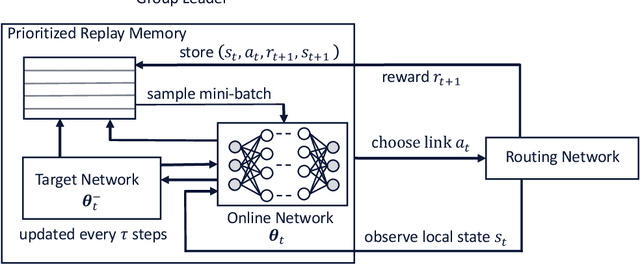
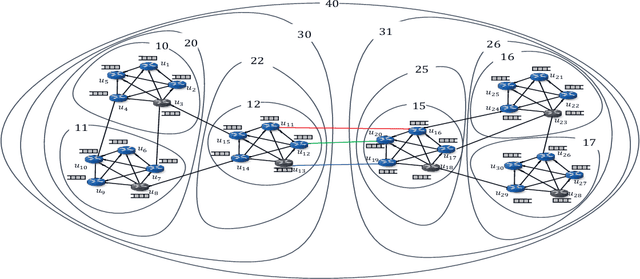
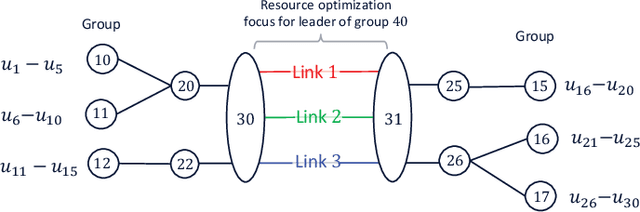
This paper explores a deep reinforcement learning approach applied to the packet routing problem with high-dimensional constraints instigated by dynamic and autonomous communication networks. Our approach is motivated by the fact that centralized path calculation approaches are often not scalable, whereas the distributed approaches with locally acting nodes are not fully aware of the end-to-end performance. We instead hierarchically distribute the path calculation over designated nodes in the network while taking into account the end-to-end performance. Specifically, we develop a hierarchical cluster-oriented adaptive per-flow path calculation mechanism by leveraging the Deep Double Q-network (DDQN) algorithm, where the end-to-end paths are calculated by the source nodes with the assistance of cluster (group) leaders at different hierarchical levels. In our approach, a deferred composite reward is designed to capture the end-to-end performance through a feedback signal from the source nodes to the group leaders and captures the local network performance through the local resource assessments by the group leaders. This approach scales in large networks, adapts to the dynamic demand, utilizes the network resources efficiently and can be applied to segment routing.