 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Dark Energy Science with Deep Generative Models of Galaxy Images
Nov 30, 2016
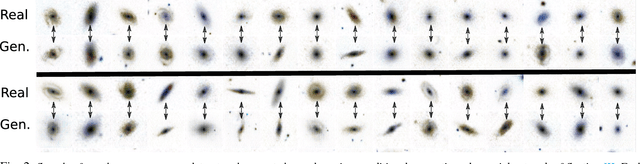

Understanding the nature of dark energy, the mysterious force driving the accelerated expansion of the Universe, is a major challenge of modern cosmology. The next generation of cosmological surveys, specifically designed to address this issue, rely on accurate measurements of the apparent shapes of distant galaxies. However, shape measurement methods suffer from various unavoidable biases and therefore will rely on a precise calibration to meet the accuracy requirements of the science analysis. This calibration process remains an open challenge as it requires large sets of high quality galaxy images. To this end, we study the application of deep conditional generative models in generating realistic galaxy images. In particular we consider variations on conditional variational autoencoder and introduce a new adversarial objective for training of conditional generative networks. Our results suggest a reliable alternative to the acquisition of expensive high quality observations for generating the calibration data needed by the next generation of cosmological surveys.
Annealing Gaussian into ReLU: a New Sampling Strategy for Leaky-ReLU RBM
Nov 11, 2016
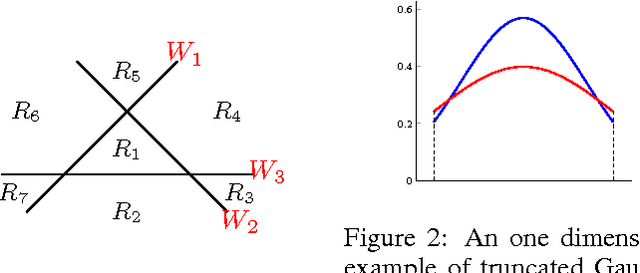
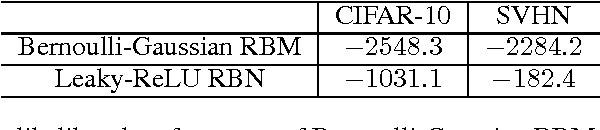
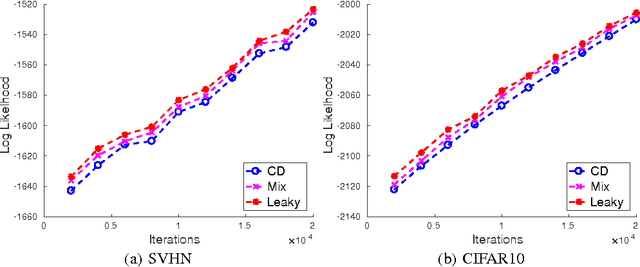
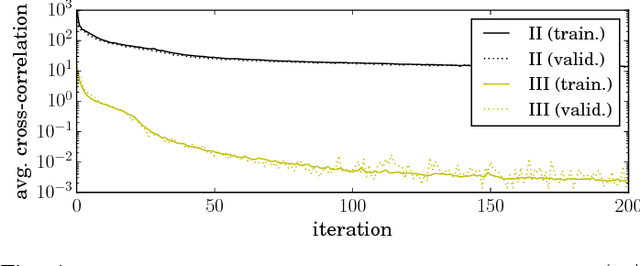
Restricted Boltzmann Machine (RBM) is a bipartite graphical model that is used as the building block in energy-based deep generative models. Due to numerical stability and quantifiability of the likelihood, RBM is commonly used with Bernoulli units. Here, we consider an alternative member of exponential family RBM with leaky rectified linear units -- called leaky RBM. We first study the joint and marginal distributions of leaky RBM under different leakiness, which provides us important insights by connecting the leaky RBM model and truncated Gaussian distributions. The connection leads us to a simple yet efficient method for sampling from this model, where the basic idea is to anneal the leakiness rather than the energy; -- i.e., start from a fully Gaussian/Linear unit and gradually decrease the leakiness over iterations. This serves as an alternative to the annealing of the temperature parameter and enables numerical estimation of the likelihood that are more efficient and more accurate than the commonly used annealed importance sampling (AIS). We further demonstrate that the proposed sampling algorithm enjoys faster mixing property than contrastive divergence algorithm, which benefits the training without any additional computational cost.
Learning Theory for Distribution Regression
Oct 21, 2016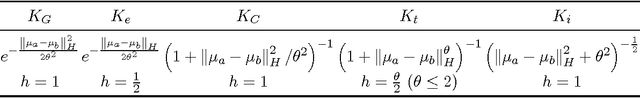

We focus on the distribution regression problem: regressing to vector-valued outputs from probability measures. Many important machine learning and statistical tasks fit into this framework, including multi-instance learning and point estimation problems without analytical solution (such as hyperparameter or entropy estimation). Despite the large number of available heuristics in the literature, the inherent two-stage sampled nature of the problem makes the theoretical analysis quite challenging, since in practice only samples from sampled distributions are observable, and the estimates have to rely on similarities computed between sets of points. To the best of our knowledge, the only existing technique with consistency guarantees for distribution regression requires kernel density estimation as an intermediate step (which often performs poorly in practice), and the domain of the distributions to be compact Euclidean. In this paper, we study a simple, analytically computable, ridge regression-based alternative to distribution regression, where we embed the distributions to a reproducing kernel Hilbert space, and learn the regressor from the embeddings to the outputs. Our main contribution is to prove that this scheme is consistent in the two-stage sampled setup under mild conditions (on separable topological domains enriched with kernels): we present an exact computational-statistical efficiency trade-off analysis showing that our estimator is able to match the one-stage sampled minimax optimal rate [Caponnetto and De Vito, 2007; Steinwart et al., 2009]. This result answers a 17-year-old open question, establishing the consistency of the classical set kernel [Haussler, 1999; Gaertner et. al, 2002] in regression. We also cover consistency for more recent kernels on distributions, including those due to [Christmann and Steinwart, 2010].
* Final version appeared at JMLR, with supplement. Code: https://bitbucket.org/szzoli/ite/. arXiv admin note: text overlap with arXiv:1402.1754
Stochastic Frank-Wolfe Methods for Nonconvex Optimization
Jul 29, 2016
We study Frank-Wolfe methods for nonconvex stochastic and finite-sum optimization problems. Frank-Wolfe methods (in the convex case) have gained tremendous recent interest in machine learning and optimization communities due to their projection-free property and their ability to exploit structured constraints. However, our understanding of these algorithms in the nonconvex setting is fairly limited. In this paper, we propose nonconvex stochastic Frank-Wolfe methods and analyze their convergence properties. For objective functions that decompose into a finite-sum, we leverage ideas from variance reduction techniques for convex optimization to obtain new variance reduced nonconvex Frank-Wolfe methods that have provably faster convergence than the classical Frank-Wolfe method. Finally, we show that the faster convergence rates of our variance reduced methods also translate into improved convergence rates for the stochastic setting.
Stochastic Neural Networks with Monotonic Activation Functions
Jul 22, 2016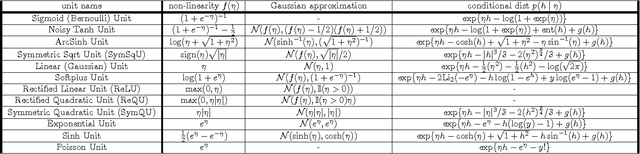
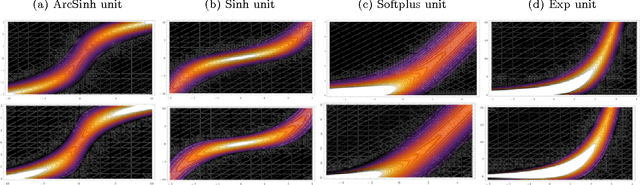
We propose a Laplace approximation that creates a stochastic unit from any smooth monotonic activation function, using only Gaussian noise. This paper investigates the application of this stochastic approximation in training a family of Restricted Boltzmann Machines (RBM) that are closely linked to Bregman divergences. This family, that we call exponential family RBM (Exp-RBM), is a subset of the exponential family Harmoniums that expresses family members through a choice of smooth monotonic non-linearity for each neuron. Using contrastive divergence along with our Gaussian approximation, we show that Exp-RBM can learn useful representations using novel stochastic units.
Fast Stochastic Methods for Nonsmooth Nonconvex Optimization
May 23, 2016


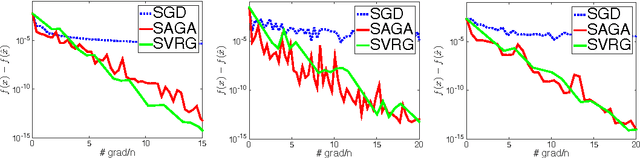
We analyze stochastic algorithms for optimizing nonconvex, nonsmooth finite-sum problems, where the nonconvex part is smooth and the nonsmooth part is convex. Surprisingly, unlike the smooth case, our knowledge of this fundamental problem is very limited. For example, it is not known whether the proximal stochastic gradient method with constant minibatch converges to a stationary point. To tackle this issue, we develop fast stochastic algorithms that provably converge to a stationary point for constant minibatches. Furthermore, using a variant of these algorithms, we show provably faster convergence than batch proximal gradient descent. Finally, we prove global linear convergence rate for an interesting subclass of nonsmooth nonconvex functions, that subsumes several recent works. This paper builds upon our recent series of papers on fast stochastic methods for smooth nonconvex optimization [22, 23], with a novel analysis for nonconvex and nonsmooth functions.
High Dimensional Bayesian Optimisation and Bandits via Additive Models
May 13, 2016
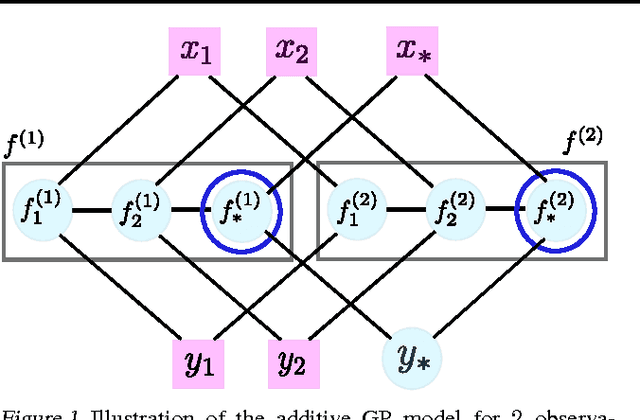
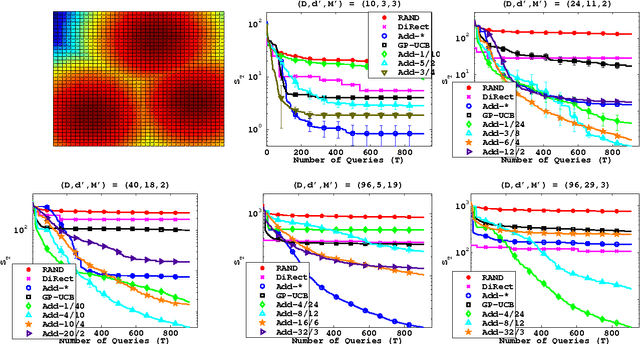
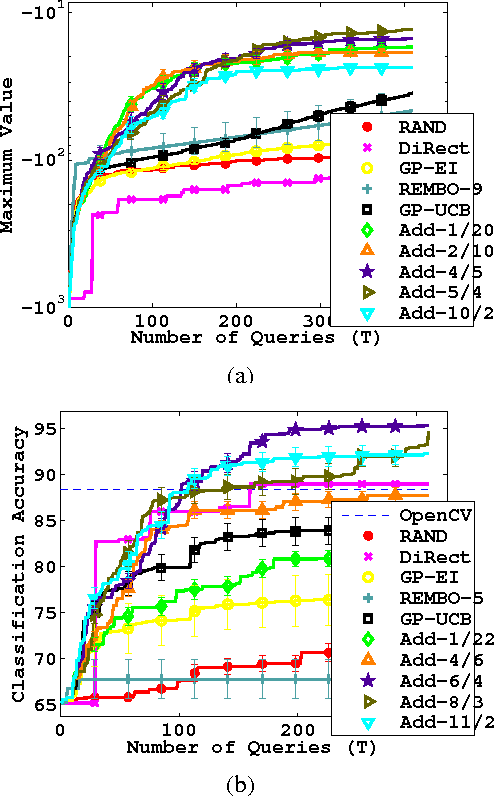
Bayesian Optimisation (BO) is a technique used in optimising a $D$-dimensional function which is typically expensive to evaluate. While there have been many successes for BO in low dimensions, scaling it to high dimensions has been notoriously difficult. Existing literature on the topic are under very restrictive settings. In this paper, we identify two key challenges in this endeavour. We tackle these challenges by assuming an additive structure for the function. This setting is substantially more expressive and contains a richer class of functions than previous work. We prove that, for additive functions the regret has only linear dependence on $D$ even though the function depends on all $D$ dimensions. We also demonstrate several other statistical and computational benefits in our framework. Via synthetic examples, a scientific simulation and a face detection problem we demonstrate that our method outperforms naive BO on additive functions and on several examples where the function is not additive.
Stochastic Variance Reduction for Nonconvex Optimization
Apr 04, 2016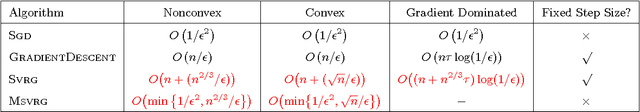
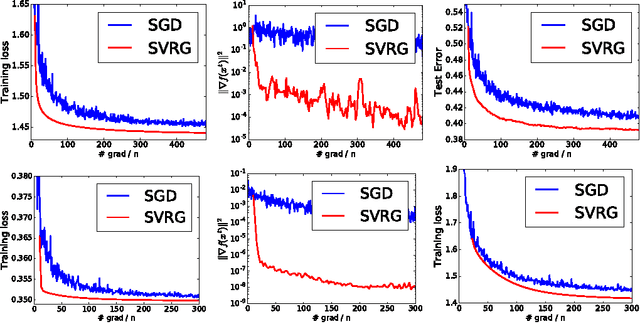
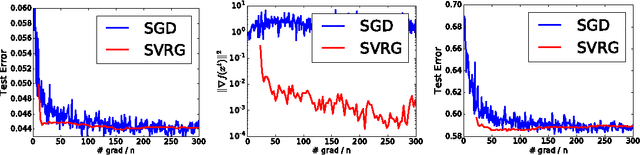
We study nonconvex finite-sum problems and analyze stochastic variance reduced gradient (SVRG) methods for them. SVRG and related methods have recently surged into prominence for convex optimization given their edge over stochastic gradient descent (SGD); but their theoretical analysis almost exclusively assumes convexity. In contrast, we prove non-asymptotic rates of convergence (to stationary points) of SVRG for nonconvex optimization, and show that it is provably faster than SGD and gradient descent. We also analyze a subclass of nonconvex problems on which SVRG attains linear convergence to the global optimum. We extend our analysis to mini-batch variants of SVRG, showing (theoretical) linear speedup due to mini-batching in parallel settings.
Fast Incremental Method for Nonconvex Optimization
Mar 19, 2016
We analyze a fast incremental aggregated gradient method for optimizing nonconvex problems of the form $\min_x \sum_i f_i(x)$. Specifically, we analyze the SAGA algorithm within an Incremental First-order Oracle framework, and show that it converges to a stationary point provably faster than both gradient descent and stochastic gradient descent. We also discuss a Polyak's special class of nonconvex problems for which SAGA converges at a linear rate to the global optimum. Finally, we analyze the practically valuable regularized and minibatch variants of SAGA. To our knowledge, this paper presents the first analysis of fast convergence for an incremental aggregated gradient method for nonconvex problems.
Boolean Matrix Factorization and Noisy Completion via Message Passing
Feb 04, 2016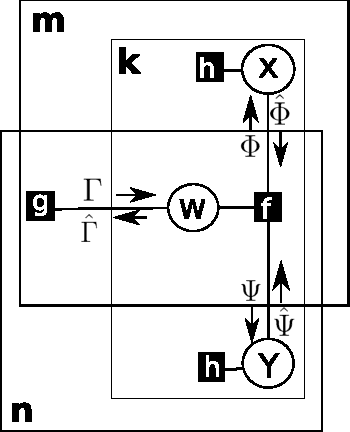
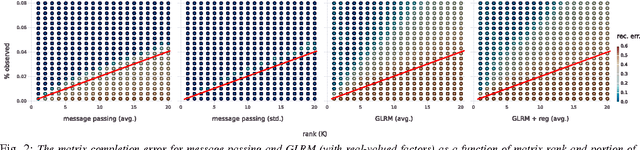
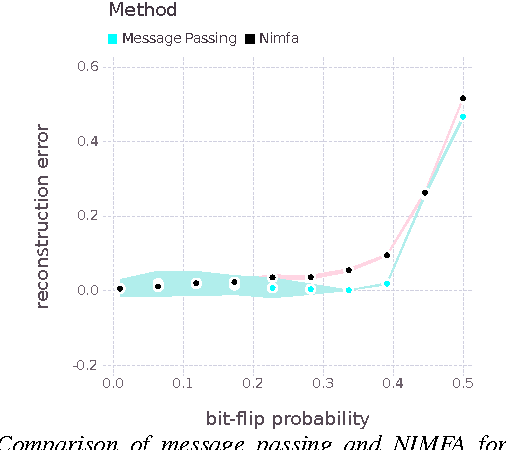
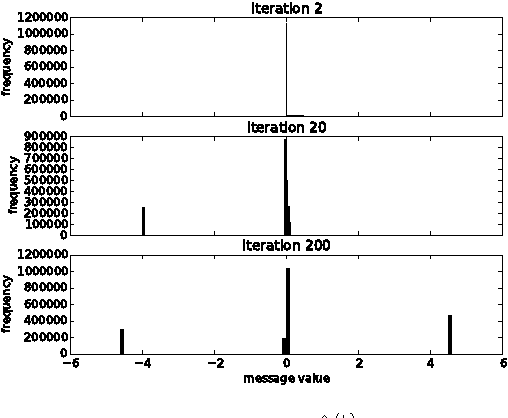
Boolean matrix factorization and Boolean matrix completion from noisy observations are desirable unsupervised data-analysis methods due to their interpretability, but hard to perform due to their NP-hardness. We treat these problems as maximum a posteriori inference problems in a graphical model and present a message passing approach that scales linearly with the number of observations and factors. Our empirical study demonstrates that message passing is able to recover low-rank Boolean matrices, in the boundaries of theoretically possible recovery and compares favorably with state-of-the-art in real-world applications, such collaborative filtering with large-scale Boolean data.