 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape Consistent 2D Keypoint Estimation under Domain Shift
Aug 04, 2020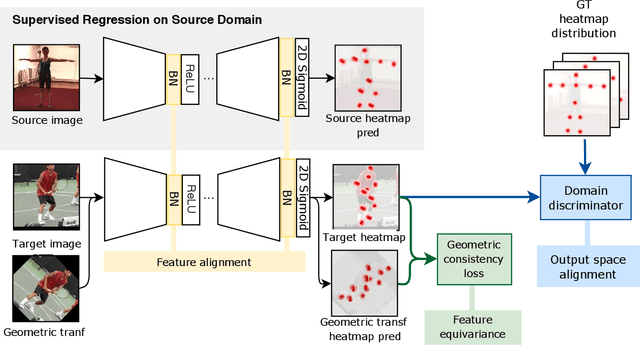

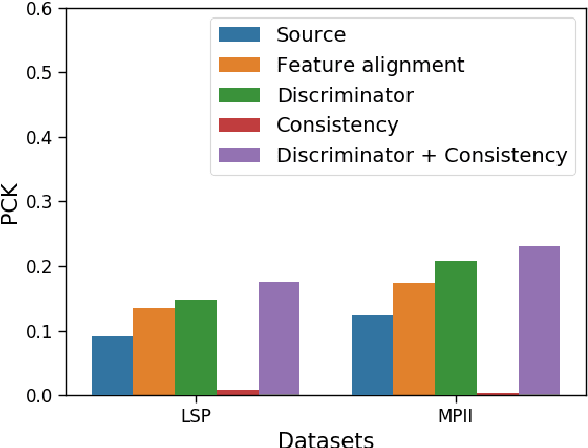
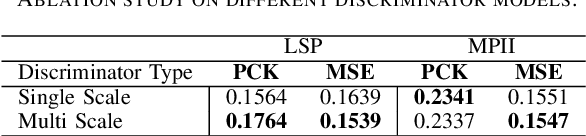
Recent unsupervised domain adaptation methods based on deep architectures have shown remarkable performance not only in traditional classification tasks but also in more complex problems involving structured predictions (e.g. semantic segmentation, depth estimation). Following this trend, in this paper we present a novel deep adaptation framework for estimating keypoints under domain shift}, i.e. when the training (source) and the test (target) images significantly differ in terms of visual appearance. Our method seamlessly combines three different components: feature alignment, adversarial training and self-supervision. Specifically, our deep architecture leverages from domain-specific distribution alignment layers to perform target adaptation at the feature level. Furthermore, a novel loss is proposed which combines an adversarial term for ensuring aligned predictions in the output space and a geometric consistency term which guarantees coherent predictions between a target sample and its perturbed version. Our extensive experimental evaluation conducted on three publicly available benchmarks shows that our approach outperforms state-of-the-art domain adaptation methods in the 2D keypoint prediction task.
Self-Supervised Learning Across Domains
Jul 24, 2020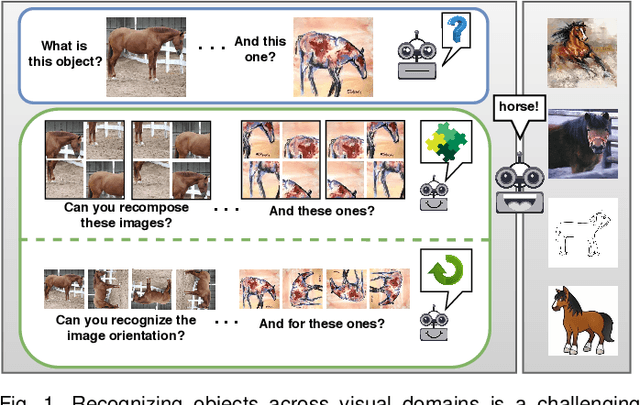
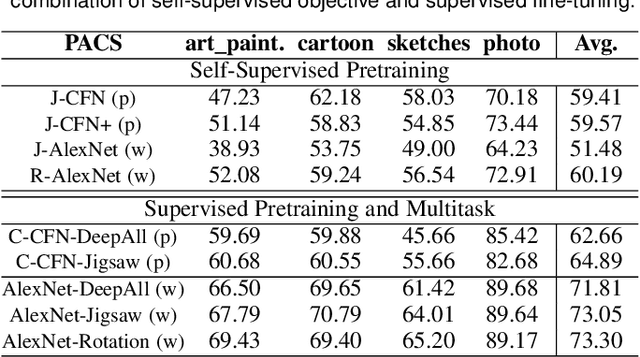
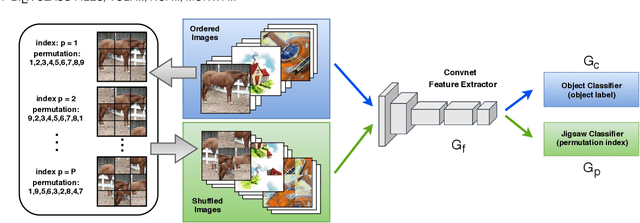
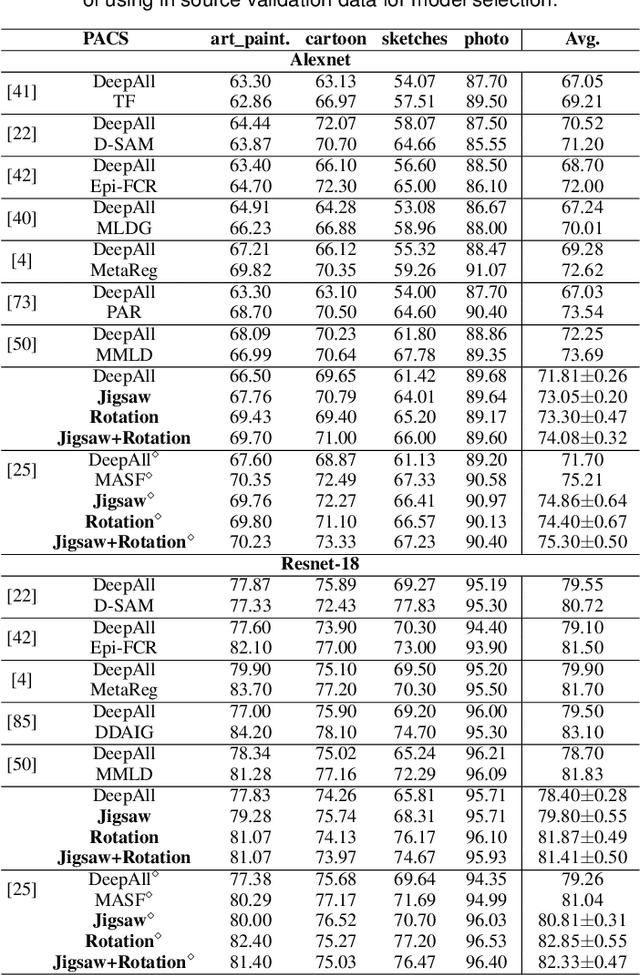
Human adaptability relies crucially on learning and merging knowledge from both supervised and unsupervised tasks: the parents point out few important concepts, but then the children fill in the gaps on their own. This is particularly effective, because supervised learning can never be exhaustive and thus learning autonomously allows to discover invariances and regularities that help to generalize. In this paper we propose to apply a similar approach to the problem of object recognition across domains: our model learns the semantic labels in a supervised fashion, and broadens its understanding of the data by learning from self-supervised signals on the same images. This secondary task helps the network to learn the concepts like spatial orientation and part correlation, while acting as a regularizer for the classification task. Extensive experiments confirm our intuition and show that our multi-task method combining supervised and self-supervised knowledge shows competitive results with respect to more complex domain generalization and adaptation solutions. It also proves its potential in the novel and challenging predictive and partial domain adaptation scenarios.
One-Shot Unsupervised Cross-Domain Detection
May 23, 2020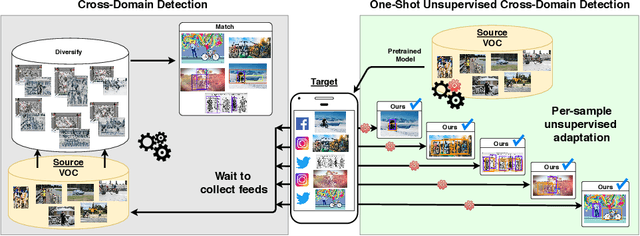
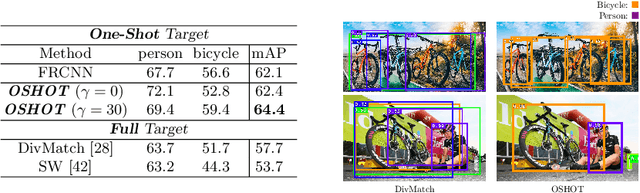
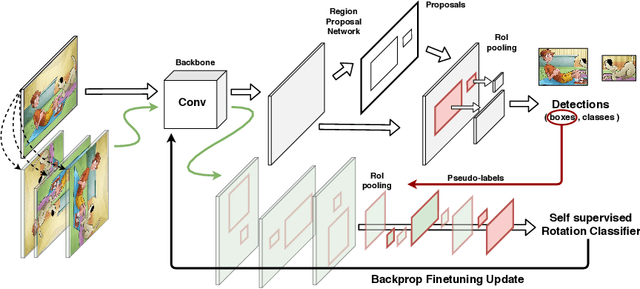
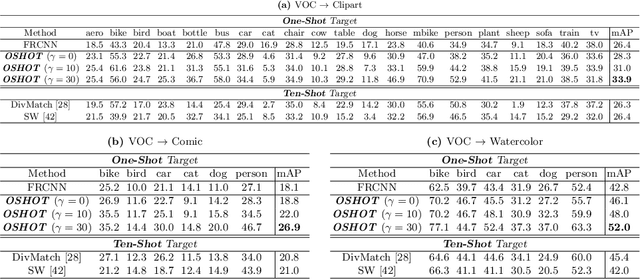
Despite impressive progress in object detection over the last years, it is still an open challenge to reliably detect objects across visual domains. Although the topic has attracted attention recently, current approaches all rely on the ability to access a sizable amount of target data for use at training time. This is a heavy assumption, as often it is not possible to anticipate the domain where a detector will be used, nor to access it in advance for data acquisition. Consider for instance the task of monitoring image feeds from social media: as every image is created and uploaded by a different user it belongs to a different target domain that is impossible to foresee during training. This paper addresses this setting, presenting an object detection algorithm able to perform unsupervised adaption across domains by using only one target sample, seen at test time. We achieve this by introducing a multi-task architecture that one-shot adapts to any incoming sample by iteratively solving a self-supervised task on it. We further enhance this auxiliary adaptation with cross-task pseudo-labeling. A thorough benchmark analysis against the most recent cross-domain detection methods and a detailed ablation study show the advantage of our method, which sets the state-of-the-art in the defined one-shot scenario.
Unsupervised Domain Adaptation through Inter-modal Rotation for RGB-D Object Recognition
Apr 21, 2020
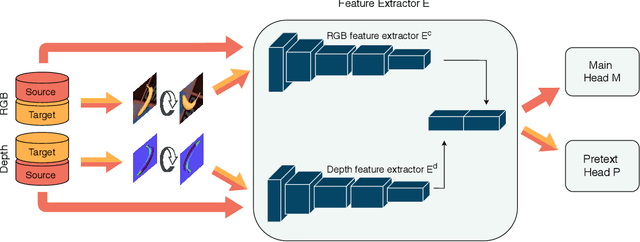


Unsupervised Domain Adaptation (DA) exploits the supervision of a label-rich source dataset to make predictions on an unlabeled target dataset by aligning the two data distributions. In robotics, DA is used to take advantage of automatically generated synthetic data, that come with "free" annotation, to make effective predictions on real data. However, existing DA methods are not designed to cope with the multi-modal nature of RGB-D data, which are widely used in robotic vision. We propose a novel RGB-D DA method that reduces the synthetic-to-real domain shift by exploiting the inter-modal relation between the RGB and depth image. Our method consists of training a convolutional neural network to solve, in addition to the main recognition task, the pretext task of predicting the relative rotation between the RGB and depth image. To evaluate our method and encourage further research in this area, we define two benchmark datasets for object categorization and instance recognition. With extensive experiments, we show the benefits of leveraging the inter-modal relations for RGB-D DA.
Boosting Deep Open World Recognition by Clustering
Apr 20, 2020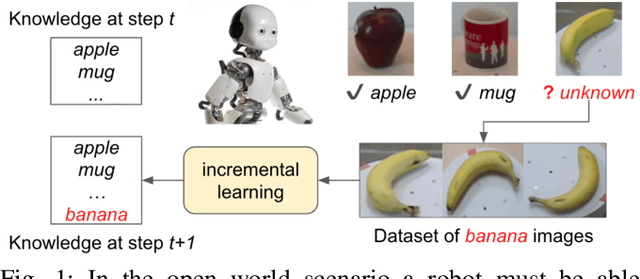
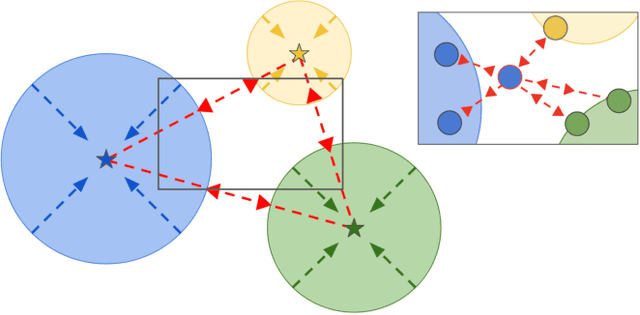
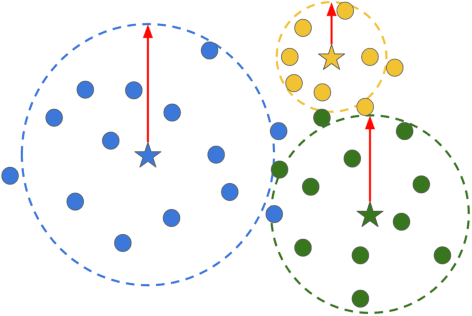

While convolutional neural networks have brought significant advances in robot vision, their ability is often limited to closed world scenarios, where the number of semantic concepts to be recognized is determined by the available training set. Since it is practically impossible to capture all possible semantic concepts present in the real world in a single training set, we need to break the closed world assumption, equipping our robot with the capability to act in an open world. To provide such ability, a robot vision system should be able to (i) identify whether an instance does not belong to the set of known categories (i.e. open set recognition), and (ii) extend its knowledge to learn new classes over time (i.e. incremental learning). In this work, we show how we can boost the performance of deep open world recognition algorithms by means of a new loss formulation enforcing a global to local clustering of class-specific features. In particular, a first loss term, i.e. global clustering, forces the network to map samples closer to the class centroid they belong to while the second one, local clustering, shapes the representation space in such a way that samples of the same class get closer in the representation space while pushing away neighbours belonging to other classes. Moreover, we propose a strategy to learn class-specific rejection thresholds, instead of heuristically estimating a single global threshold, as in previous works. Experiments on RGB-D Object and Core50 datasets show the effectiveness of our approach.
IDDA: a large-scale multi-domain dataset for autonomous driving
Apr 17, 2020

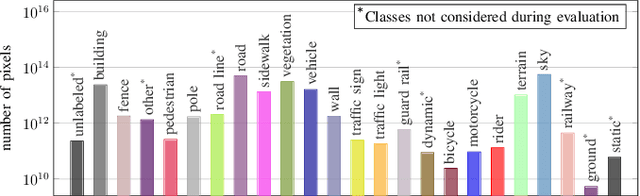
Semantic segmentation is key in autonomous driving. Using deep visual learning architectures is not trivial in this context, because of the challenges in creating suitable large scale annotated datasets. This issue has been traditionally circumvented through the use of synthetic datasets, that have become a popular resource in this field. They have been released with the need to develop semantic segmentation algorithms able to close the visual domain shift between the training and test data. Although exacerbated by the use of artificial data, the problem is extremely relevant in this field even when training on real data. Indeed, weather conditions, viewpoint changes and variations in the city appearances can vary considerably from car to car, and even at test time for a single, specific vehicle. How to deal with domain adaptation in semantic segmentation, and how to leverage effectively several different data distributions (source domains) are important research questions in this field. To support work in this direction, this paper contributes a new large scale, synthetic dataset for semantic segmentation with more than 100 different source visual domains. The dataset has been created to explicitly address the challenges of domain shift between training and test data in various weather and view point conditions, in seven different city types. Extensive benchmark experiments assess the dataset, showcasing open challenges for the current state of the art. The dataset will be available at: https://idda-dataset.github.io/home/ .
Joint Encoding of Appearance and Motion Features with Self-supervision for First Person Action Recognition
Feb 10, 2020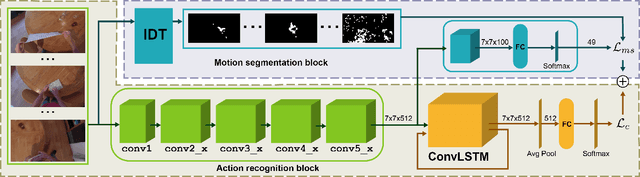
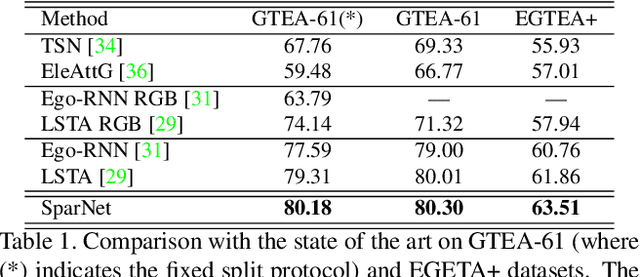

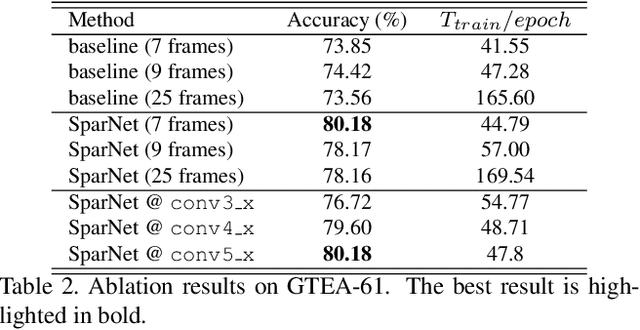
Wearable cameras are becoming more and more popular in several applications, increasing the interest of the research community in developing approaches for recognizing actions from a first-person point of view. An open challenge is how to cope with the limited amount of motion information available about the action itself, as opposed to the more investigated third-person action recognition scenario. When focusing on manipulation tasks, videos tend to record only parts of the movement, making crucial the understanding of the objects being manipulated and of their context. Previous works addressed this issue with two-stream architectures, one dedicated to modeling the appearance of objects involved in the action, another dedicated to extracting motion features from optical flow. In this paper, we argue that features from these two information channels should be learned jointly to capture the spatio-temporal correlations between the two in a better way. To this end, we propose a single stream architecture able to do so, thanks to the addition of a self-supervised block that uses a pretext motion segmentation task to intertwine motion and appearance knowledge. Experiments on several publicly available databases show the power of our approach.
Modeling the Background for Incremental Learning in Semantic Segmentation
Feb 03, 2020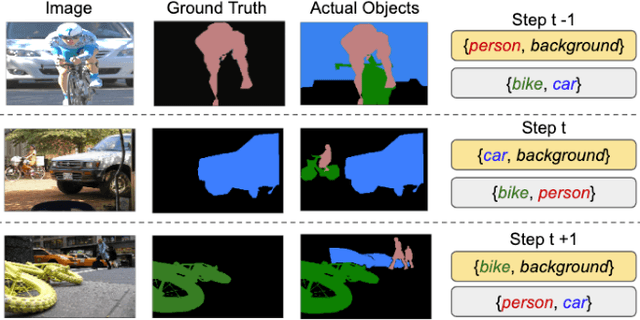
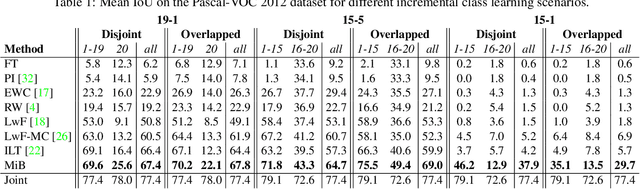
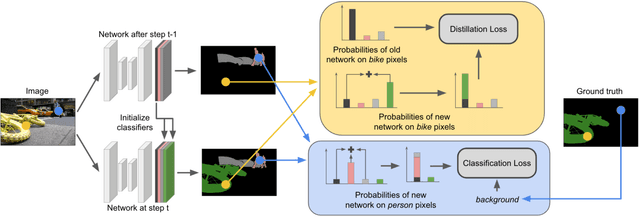
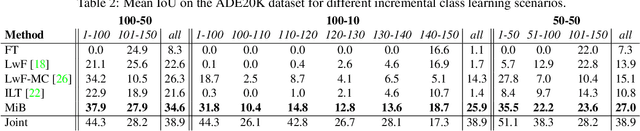
Despite their effectiveness in a wide range of tasks, deep architectures suffer from some important limitations. In particular, they are vulnerable to catastrophic forgetting, i.e. they perform poorly when they are required to update their model as new classes are available but the original training set is not retained. This paper addresses this problem in the context of semantic segmentation. Current strategies fail on this task because they do not consider a peculiar aspect of semantic segmentation: since each training step provides annotation only for a subset of all possible classes, pixels of the background class (i.e. pixels that do not belong to any other classes) exhibit a semantic distribution shift. In this work we revisit classical incremental learning methods, proposing a new distillation-based framework which explicitly accounts for this shift. Furthermore, we introduce a novel strategy to initialize classifier's parameters, thus preventing biased predictions toward the background class. We demonstrate the effectiveness of our approach with an extensive evaluation on the Pascal-VOC 2012 and ADE20K datasets, significantly outperforming state of the art incremental learning methods.
Learning to Generalize One Sample at a Time with Self-Supervision
Oct 11, 2019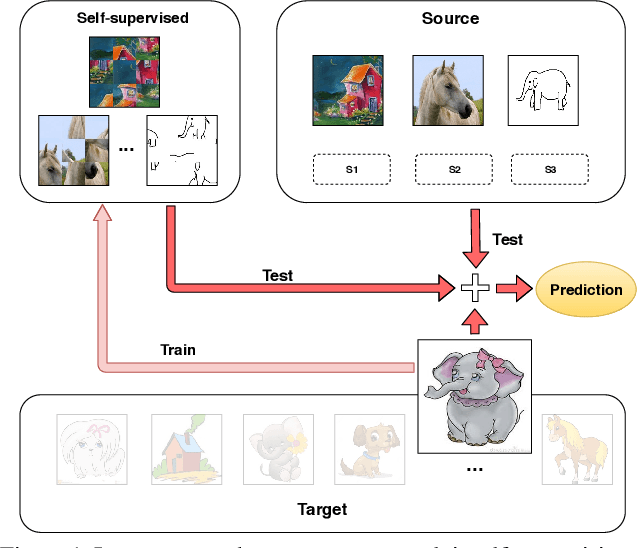
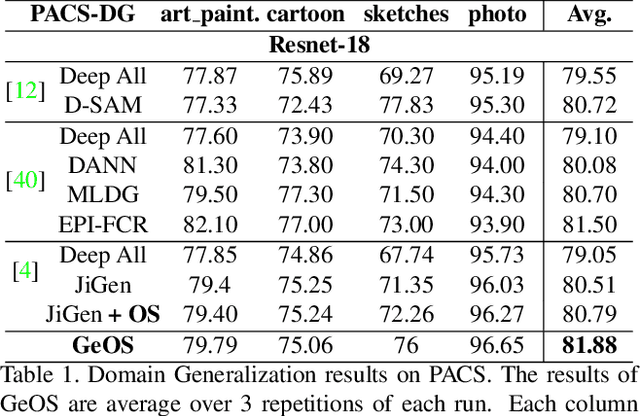
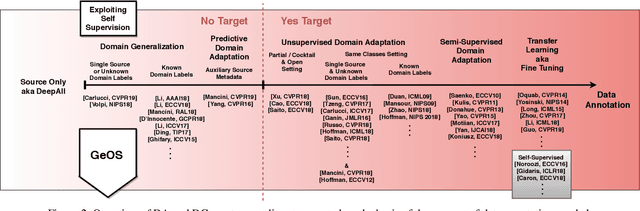
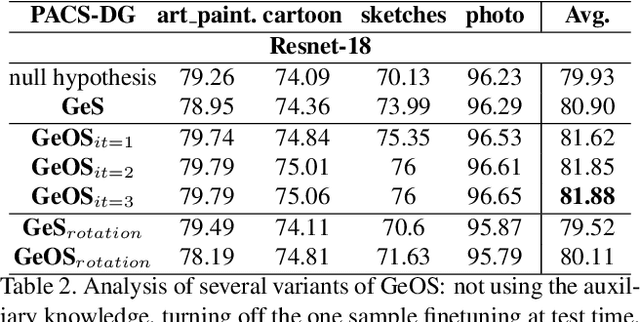
Although deep networks have significantly increased the performance of visual recognition methods, it is still challenging to achieve the robustness across visual domains that is necessary for real-world applications. To tackle this issue, research on domain adaptation and generalization has flourished over the last decade. An important aspect to consider when assessing the work done in the literature so far is the amount of data annotation necessary for training each approach, both at the source and target level. In this paper we argue that the data annotation overload should be minimal, as it is costly. Hence, we propose to use self-supervised learning to achieve domain generalization and adaptation. We consider learning regularities from non annotated data as an auxiliary task, and cast the problem within an Auxiliary Learning principled framework. Moreover, we suggest to further exploit the ability to learn about visual domains from non annotated images by learning from target data while testing, as data are presented to the algorithm one sample at a time. Results on three different scenarios confirm the value of our approach.
Knowledge is Never Enough: Towards Web Aided Deep Open World Recognition
Jun 04, 2019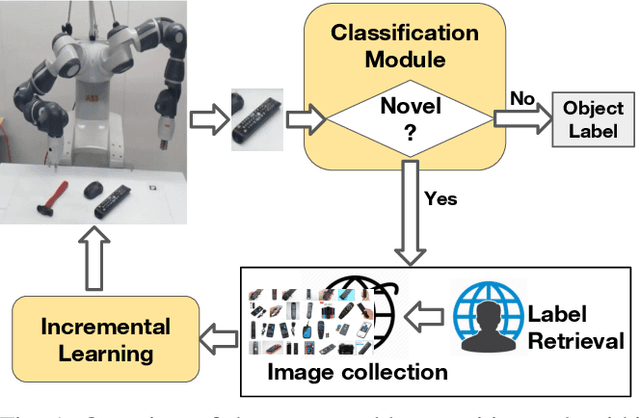
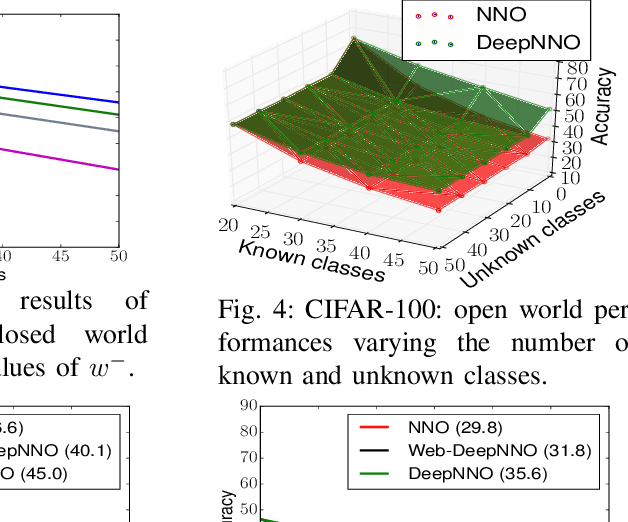
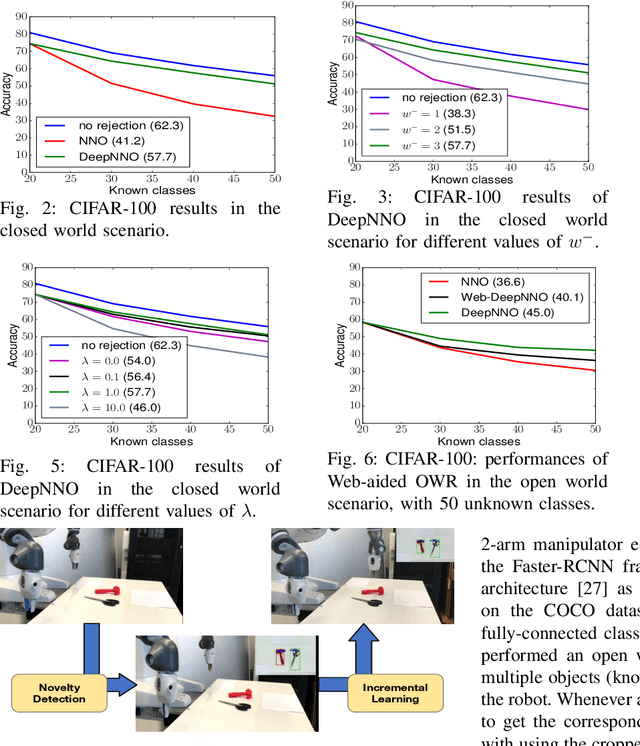
While today's robots are able to perform sophisticated tasks, they can only act on objects they have been trained to recognize. This is a severe limitation: any robot will inevitably see new objects in unconstrained settings, and thus will always have visual knowledge gaps. However, standard visual modules are usually built on a limited set of classes and are based on the strong prior that an object must belong to one of those classes. Identifying whether an instance does not belong to the set of known categories (i.e. open set recognition), only partially tackles this problem, as a truly autonomous agent should be able not only to detect what it does not know, but also to extend dynamically its knowledge about the world. We contribute to this challenge with a deep learning architecture that can dynamically update its known classes in an end-to-end fashion. The proposed deep network, based on a deep extension of a non-parametric model, detects whether a perceived object belongs to the set of categories known by the system and learns it without the need to retrain the whole system from scratch. Annotated images about the new category can be provided by an 'oracle' (i.e. human supervision), or by autonomous mining of the Web. Experiments on two different databases and on a robot platform demonstrate the promise of our approach.