 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Visual Geo-localization Benchmark
Apr 07, 2022
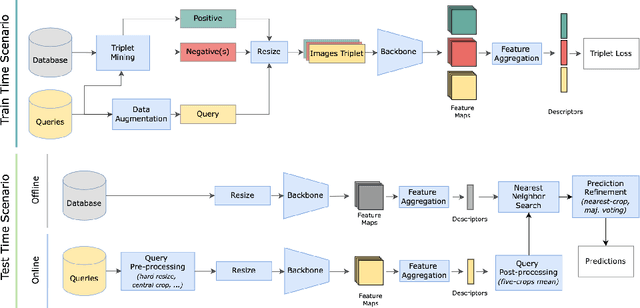

In this paper, we propose a new open-source benchmarking framework for Visual Geo-localization (VG) that allows to build, train, and test a wide range of commonly used architectures, with the flexibility to change individual components of a geo-localization pipeline. The purpose of this framework is twofold: i) gaining insights into how different components and design choices in a VG pipeline impact the final results, both in terms of performance (recall@N metric) and system requirements (such as execution time and memory consumption); ii) establish a systematic evaluation protocol for comparing different methods. Using the proposed framework, we perform a large suite of experiments which provide criteria for choosing backbone, aggregation and negative mining depending on the use-case and requirements. We also assess the impact of engineering techniques like pre/post-processing, data augmentation and image resizing, showing that better performance can be obtained through somewhat simple procedures: for example, downscaling the images' resolution to 80% can lead to similar results with a 36% savings in extraction time and dataset storage requirement. Code and trained models are available at https://deep-vg-bench.herokuapp.com/.
Rethinking Visual Geo-localization for Large-Scale Applications
Apr 07, 2022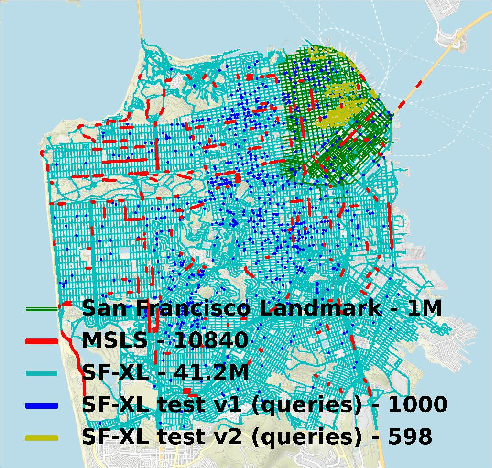
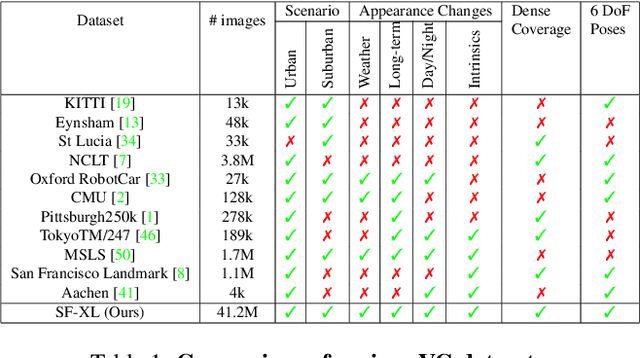
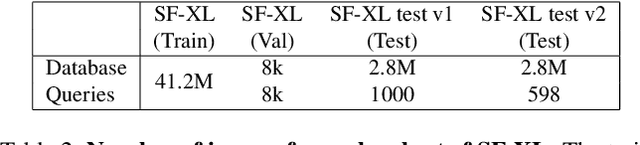

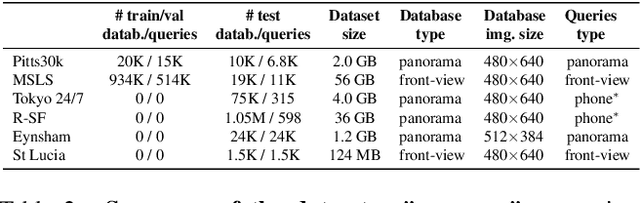
Visual Geo-localization (VG) is the task of estimating the position where a given photo was taken by comparing it with a large database of images of known locations. To investigate how existing techniques would perform on a real-world city-wide VG application, we build San Francisco eXtra Large, a new dataset covering a whole city and providing a wide range of challenging cases, with a size 30x bigger than the previous largest dataset for visual geo-localization. We find that current methods fail to scale to such large datasets, therefore we design a new highly scalable training technique, called CosPlace, which casts the training as a classification problem avoiding the expensive mining needed by the commonly used contrastive learning. We achieve state-of-the-art performance on a wide range of datasets and find that CosPlace is robust to heavy domain changes. Moreover, we show that, compared to the previous state-of-the-art, CosPlace requires roughly 80% less GPU memory at train time, and it achieves better results with 8x smaller descriptors, paving the way for city-wide real-world visual geo-localization. Dataset, code and trained models are available for research purposes at https://github.com/gmberton/CosPlace.
Improving Generalization in Federated Learning by Seeking Flat Minima
Mar 24, 2022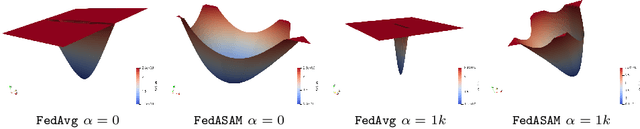
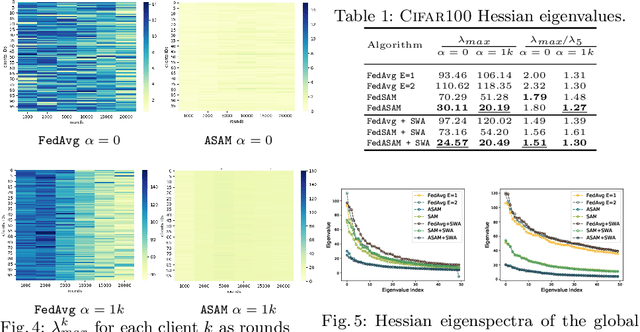

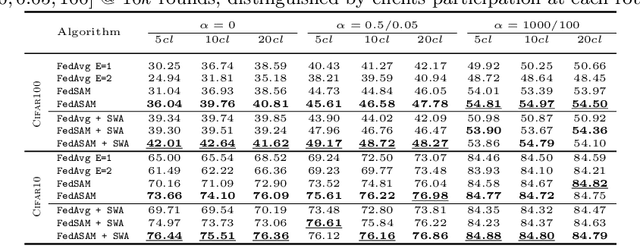
Models trained in federated settings often suffer from degraded performances and fail at generalizing, especially when facing heterogeneous scenarios. In this work, we investigate such behavior through the lens of geometry of the loss and Hessian eigenspectrum, linking the model's lack of generalization capacity to the sharpness of the solution. Motivated by prior studies connecting the sharpness of the loss surface and the generalization gap, we show that i) training clients locally with Sharpness-Aware Minimization (SAM) or its adaptive version (ASAM) and ii) averaging stochastic weights (SWA) on the server-side can substantially improve generalization in Federated Learning and help bridging the gap with centralized models. By seeking parameters in neighborhoods having uniform low loss, the model converges towards flatter minima and its generalization significantly improves in both homogeneous and heterogeneous scenarios. Empirical results demonstrate the effectiveness of those optimizers across a variety of benchmark vision datasets (e.g. CIFAR10/100, Landmarks-User-160k, IDDA) and tasks (large scale classification, semantic segmentation, domain generalization).
FedDrive: Generalizing Federated Learning to Semantic Segmentation in Autonomous Driving
Feb 28, 2022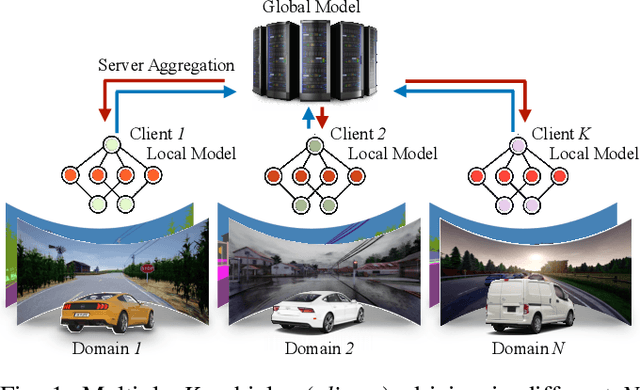


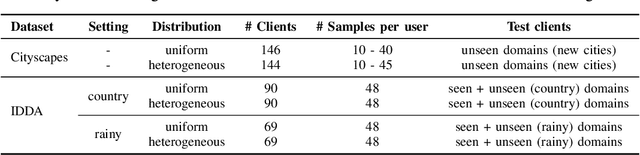
Semantic Segmentation is essential to make self-driving vehicles autonomous, enabling them to understand their surroundings by assigning individual pixels to known categories. However, it operates on sensible data collected from the users' cars; thus, protecting the clients' privacy becomes a primary concern. For similar reasons, Federated Learning has been recently introduced as a new machine learning paradigm aiming to learn a global model while preserving privacy and leveraging data on millions of remote devices. Despite several efforts on this topic, no work has explicitly addressed the challenges of federated learning in semantic segmentation for driving so far. To fill this gap, we propose FedDrive, a new benchmark consisting of three settings and two datasets, incorporating the real-world challenges of statistical heterogeneity and domain generalization. We benchmark state-of-the-art algorithms from the federated learning literature through an in-depth analysis, combining them with style transfer methods to improve their generalization ability. We demonstrate that correctly handling normalization statistics is crucial to deal with the aforementioned challenges. Furthermore, style transfer improves performance when dealing with significant appearance shifts. We plan to make both the code and the benchmark publicly available to the research community.
Modeling the Background for Incremental and Weakly-Supervised Semantic Segmentation
Jan 31, 2022



Deep neural networks have enabled major progresses in semantic segmentation. However, even the most advanced neural architectures suffer from important limitations. First, they are vulnerable to catastrophic forgetting, i.e. they perform poorly when they are required to incrementally update their model as new classes are available. Second, they rely on large amount of pixel-level annotations to produce accurate segmentation maps. To tackle these issues, we introduce a novel incremental class learning approach for semantic segmentation taking into account a peculiar aspect of this task: since each training step provides annotation only for a subset of all possible classes, pixels of the background class exhibit a semantic shift. Therefore, we revisit the traditional distillation paradigm by designing novel loss terms which explicitly account for the background shift. Additionally, we introduce a novel strategy to initialize classifier's parameters at each step in order to prevent biased predictions toward the background class. Finally, we demonstrate that our approach can be extended to point- and scribble-based weakly supervised segmentation, modeling the partial annotations to create priors for unlabeled pixels. We demonstrate the effectiveness of our approach with an extensive evaluation on the Pascal-VOC, ADE20K, and Cityscapes datasets, significantly outperforming state-of-the-art methods.
Speeding up Heterogeneous Federated Learning with Sequentially Trained Superclients
Jan 26, 2022



Federated Learning (FL) allows training machine learning models in privacy-constrained scenarios by enabling the cooperation of edge devices without requiring local data sharing. This approach raises several challenges due to the different statistical distribution of the local datasets and the clients' computational heterogeneity. In particular, the presence of highly non-i.i.d. data severely impairs both the performance of the trained neural network and its convergence rate, increasing the number of communication rounds requested to reach a performance comparable to that of the centralized scenario. As a solution, we propose FedSeq, a novel framework leveraging the sequential training of subgroups of heterogeneous clients, i.e. superclients, to emulate the centralized paradigm in a privacy-compliant way. Given a fixed budget of communication rounds, we show that FedSeq outperforms or match several state-of-the-art federated algorithms in terms of final performance and speed of convergence. Finally, our method can be easily integrated with other approaches available in the literature. Empirical results show that combining existing algorithms with FedSeq further improves its final performance and convergence speed. We test our method on CIFAR-10 and CIFAR-100 and prove its effectiveness in both i.i.d. and non-i.i.d. scenarios.
Learning Semantics for Visual Place Recognition through Multi-Scale Attention
Jan 25, 2022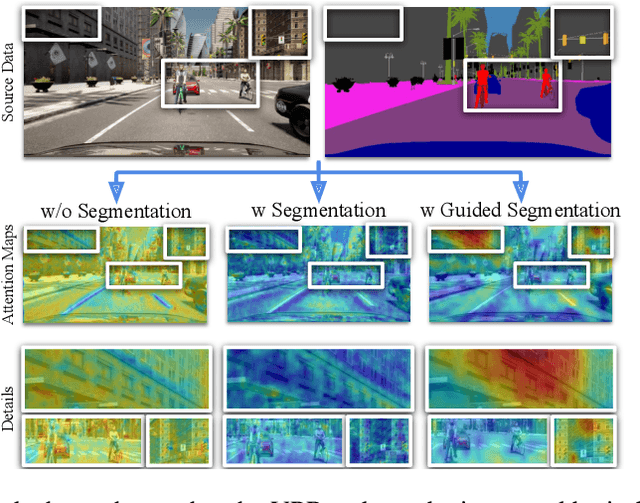
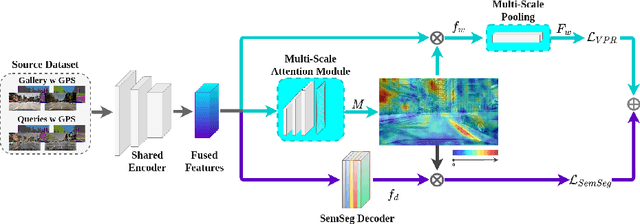
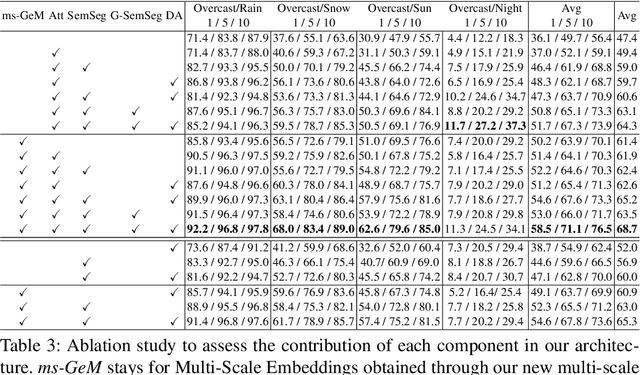
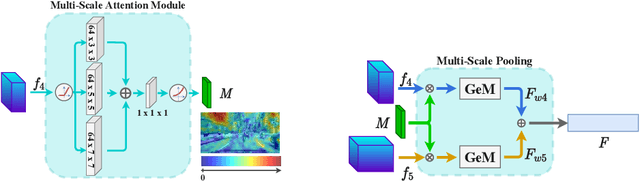
In this paper we address the task of visual place recognition (VPR), where the goal is to retrieve the correct GPS coordinates of a given query image against a huge geotagged gallery. While recent works have shown that building descriptors incorporating semantic and appearance information is beneficial, current state-of-the-art methods opt for a top down definition of the significant semantic content. Here we present the first VPR algorithm that learns robust global embeddings from both visual appearance and semantic content of the data, with the segmentation process being dynamically guided by the recognition of places through a multi-scale attention module. Experiments on various scenarios validate this new approach and demonstrate its performance against state-of-the-art methods. Finally, we propose the first synthetic-world dataset suited for both place recognition and segmentation tasks.
A Contrastive Distillation Approach for Incremental Semantic Segmentation in Aerial Images
Dec 07, 2021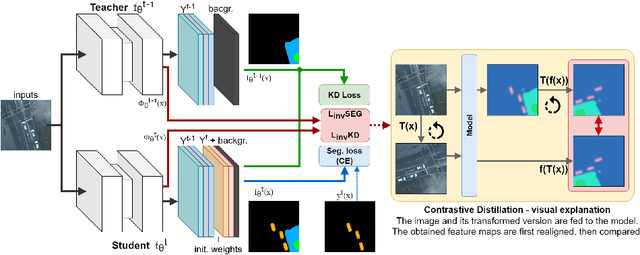
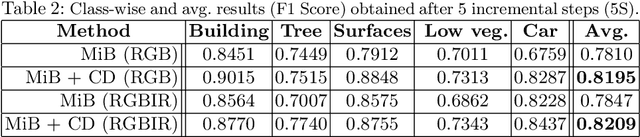
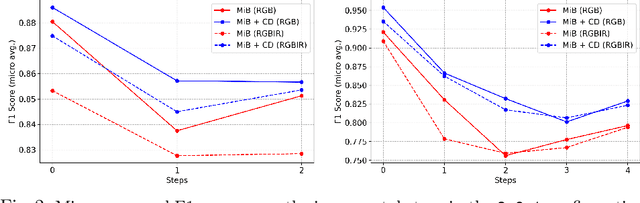
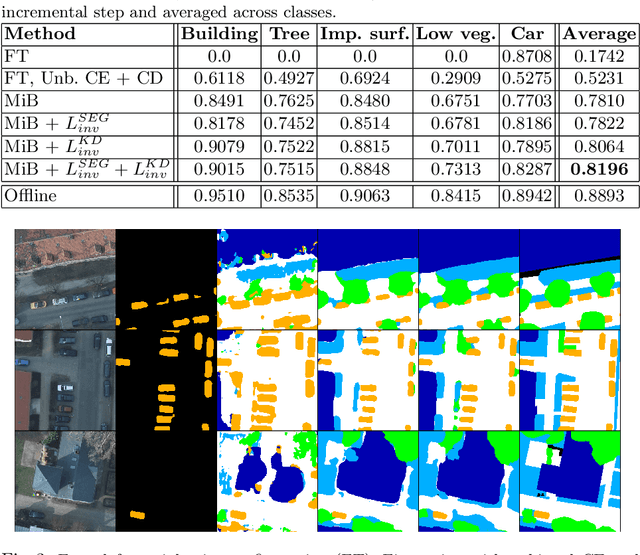
Incremental learning represents a crucial task in aerial image processing, especially given the limited availability of large-scale annotated datasets. A major issue concerning current deep neural architectures is known as catastrophic forgetting, namely the inability to faithfully maintain past knowledge once a new set of data is provided for retraining. Over the years, several techniques have been proposed to mitigate this problem for image classification and object detection. However, only recently the focus has shifted towards more complex downstream tasks such as instance or semantic segmentation. Starting from incremental-class learning for semantic segmentation tasks, our goal is to adapt this strategy to the aerial domain, exploiting a peculiar feature that differentiates it from natural images, namely the orientation. In addition to the standard knowledge distillation approach, we propose a contrastive regularization, where any given input is compared with its augmented version (i.e. flipping and rotations) in order to minimize the difference between the segmentation features produced by both inputs. We show the effectiveness of our solution on the Potsdam dataset, outperforming the incremental baseline in every test. Code available at: https://github.com/edornd/contrastive-distillation.
E$^2$MOTION: Motion Augmented Event Stream for Egocentric Action Recognition
Dec 07, 2021
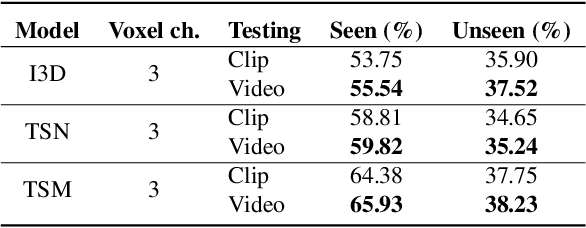


Event cameras are novel bio-inspired sensors, which asynchronously capture pixel-level intensity changes in the form of "events". Due to their sensing mechanism, event cameras have little to no motion blur, a very high temporal resolution and require significantly less power and memory than traditional frame-based cameras. These characteristics make them a perfect fit to several real-world applications such as egocentric action recognition on wearable devices, where fast camera motion and limited power challenge traditional vision sensors. However, the ever-growing field of event-based vision has, to date, overlooked the potential of event cameras in such applications. In this paper, we show that event data is a very valuable modality for egocentric action recognition. To do so, we introduce N-EPIC-Kitchens, the first event-based camera extension of the large-scale EPIC-Kitchens dataset. In this context, we propose two strategies: (i) directly processing event-camera data with traditional video-processing architectures (E$^2$(GO)) and (ii) using event-data to distill optical flow information (E$^2$(GO)MO). On our proposed benchmark, we show that event data provides a comparable performance to RGB and optical flow, yet without any additional flow computation at deploy time, and an improved performance of up to 4% with respect to RGB only information.
Incremental Learning in Semantic Segmentation from Image Labels
Dec 03, 2021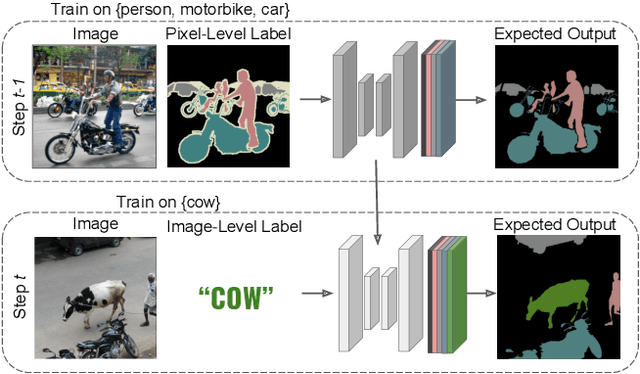
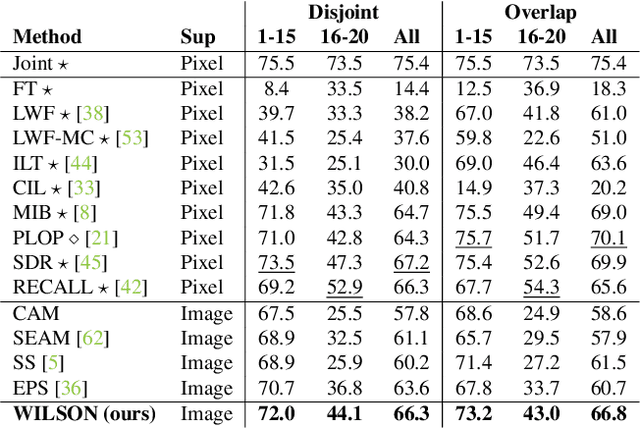
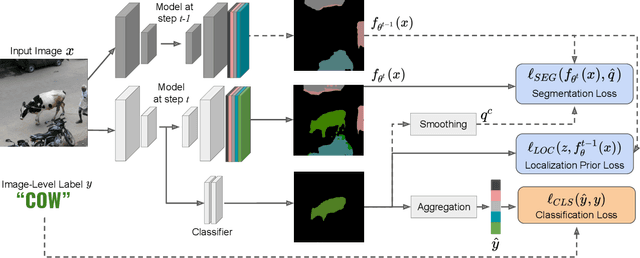
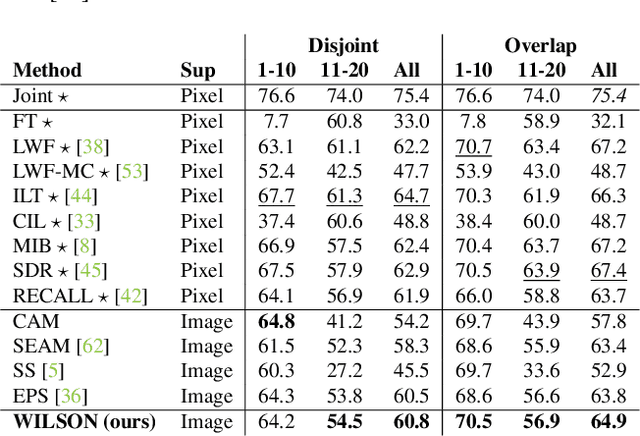
Although existing semantic segmentation approaches achieve impressive results, they still struggle to update their models incrementally as new categories are uncovered. Furthermore, pixel-by-pixel annotations are expensive and time-consuming. This paper proposes a novel framework for Weakly Incremental Learning for Semantic Segmentation, that aims at learning to segment new classes from cheap and largely available image-level labels. As opposed to existing approaches, that need to generate pseudo-labels offline, we use an auxiliary classifier, trained with image-level labels and regularized by the segmentation model, to obtain pseudo-supervision online and update the model incrementally. We cope with the inherent noise in the process by using soft-labels generated by the auxiliary classifier. We demonstrate the effectiveness of our approach on the Pascal VOC and COCO datasets, outperforming offline weakly-supervised methods and obtaining results comparable with incremental learning methods with full supervision.