 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSEC-LDA: Boosting Topic Modeling with Embedded Vocabulary Selection
Jan 15, 2020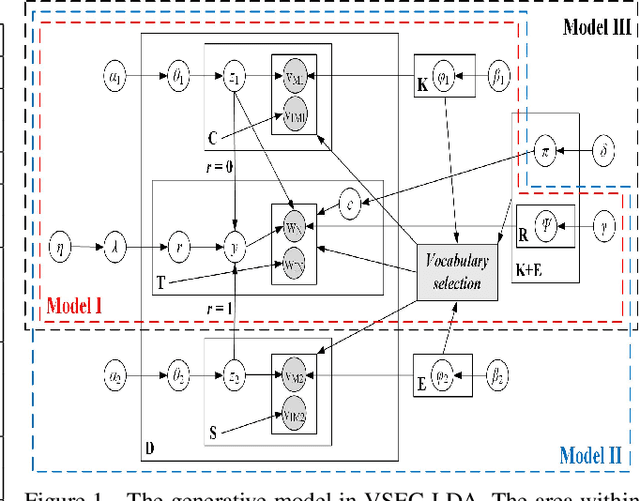

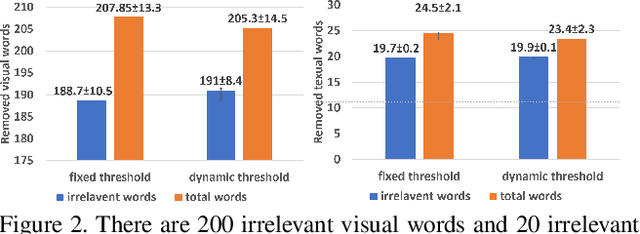
Topic modeling has found wide application in many problems where latent structures of the data are crucial for typical inference tasks. When applying a topic model, a relatively standard pre-processing step is to first build a vocabulary of frequent words. Such a general pre-processing step is often independent of the topic modeling stage, and thus there is no guarantee that the pre-generated vocabulary can support the inference of some optimal (or even meaningful) topic models appropriate for a given task, especially for computer vision applications involving "visual words". In this paper, we propose a new approach to topic modeling, termed Vocabulary-Selection-Embedded Correspondence-LDA (VSEC-LDA), which learns the latent model while simultaneously selecting most relevant words. The selection of words is driven by an entropy-based metric that measures the relative contribution of the words to the underlying model, and is done dynamically while the model is learned. We present three variants of VSEC-LDA and evaluate the proposed approach with experiments on both synthetic and real databases from different applications. The results demonstrate the effectiveness of built-in vocabulary selection and its importance in improving the performance of topic modeling.
Recognizing Video Events with Varying Rhythms
Jan 14, 2020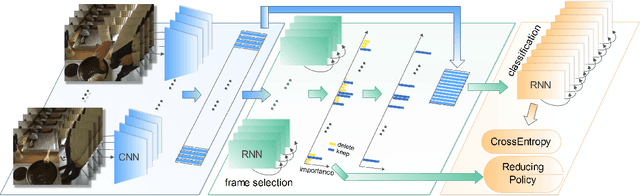
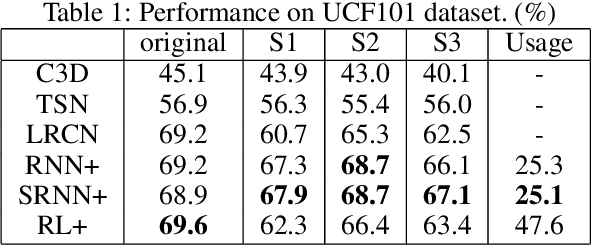


Recognizing Video events in long, complex videos with multiple sub-activities has received persistent attention recently. This task is more challenging than traditional action recognition with short, relatively homogeneous video clips. In this paper, we investigate the problem of recognizing long and complex events with varying action rhythms, which has not been considered in the literature but is a practical challenge. Our work is inspired in part by how humans identify events with varying rhythms: quickly catching frames contributing most to a specific event. We propose a two-stage \emph{end-to-end} framework, in which the first stage selects the most significant frames while the second stage recognizes the event using the selected frames. Our model needs only \emph{event-level labels} in the training stage, and thus is more practical when the sub-activity labels are missing or difficult to obtain. The results of extensive experiments show that our model can achieve significant improvement in event recognition from long videos while maintaining high accuracy even if the test videos suffer from severe rhythm changes. This demonstrates the potential of our method for real-world video-based applications, where test and training videos can differ drastically in rhythms of sub-activities.
Deep Residual Dense U-Net for Resolution Enhancement in Accelerated MRI Acquisition
Jan 13, 2020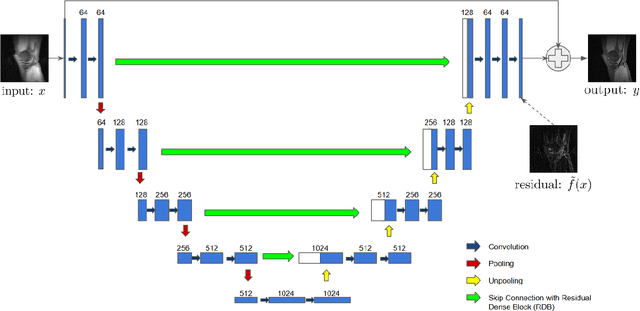

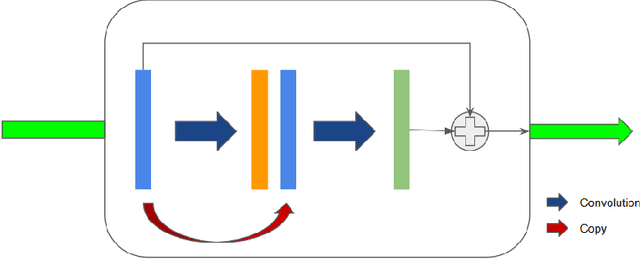
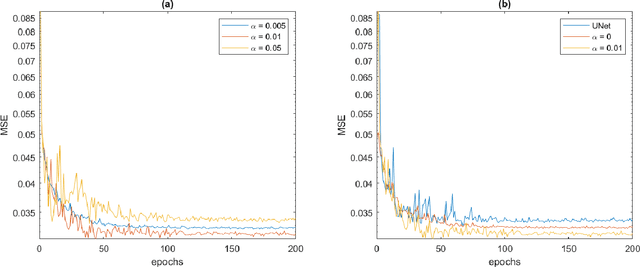
Typical Magnetic Resonance Imaging (MRI) scan may take 20 to 60 minutes. Reducing MRI scan time is beneficial for both patient experience and cost considerations. Accelerated MRI scan may be achieved by acquiring less amount of k-space data (down-sampling in the k-space). However, this leads to lower resolution and aliasing artifacts for the reconstructed images. There are many existing approaches for attempting to reconstruct high-quality images from down-sampled k-space data, with varying complexity and performance. In recent years, deep-learning approaches have been proposed for this task, and promising results have been reported. Still, the problem remains challenging especially because of the high fidelity requirement in most medical applications employing reconstructed MRI images. In this work, we propose a deep-learning approach, aiming at reconstructing high-quality images from accelerated MRI acquisition. Specifically, we use Convolutional Neural Network (CNN) to learn the differences between the aliased images and the original images, employing a U-Net-like architecture. Further, a micro-architecture termed Residual Dense Block (RDB) is introduced for learning a better feature representation than the plain U-Net. Considering the peculiarity of the down-sampled k-space data, we introduce a new term to the loss function in learning, which effectively employs the given k-space data during training to provide additional regularization on the update of the network weights. To evaluate the proposed approach, we compare it with other state-of-the-art methods. In both visual inspection and evaluation using standard metrics, the proposed approach is able to deliver improved performance, demonstrating its potential for providing an effective solution.
Plan-Recognition-Driven Attention Modeling for Visual Recognition
Dec 02, 2018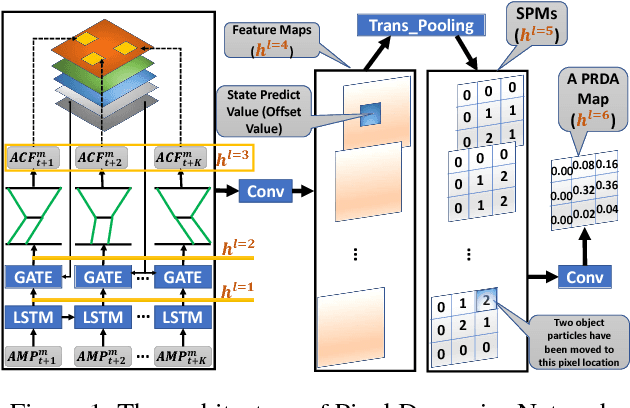

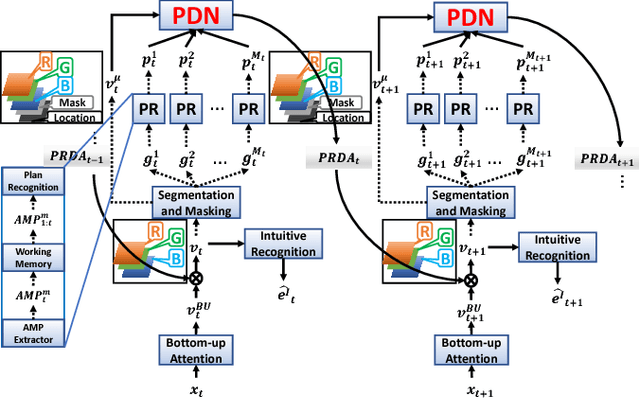

Human visual recognition of activities or external agents involves an interplay between high-level plan recognition and low-level perception. Given that, a natural question to ask is: can low-level perception be improved by high-level plan recognition? We formulate the problem of leveraging recognized plans to generate better top-down attention maps \cite{gazzaniga2009,baluch2011} to improve the perception performance. We call these top-down attention maps specifically as plan-recognition-driven attention maps. To address this problem, we introduce the Pixel Dynamics Network. Pixel Dynamics Network serves as an observation model, which predicts next states of object points at each pixel location given observation of pixels and pixel-level action feature. This is like internally learning a pixel-level dynamics model. Pixel Dynamics Network is a kind of Convolutional Neural Network (ConvNet), with specially-designed architecture. Therefore, Pixel Dynamics Network could take the advantage of parallel computation of ConvNets, while learning the pixel-level dynamics model. We further prove the equivalence between Pixel Dynamics Network as an observation model, and the belief update in partially observable Markov decision process (POMDP) framework. We evaluate our Pixel Dynamics Network in event recognition tasks. We build an event recognition system, ER-PRN, which takes Pixel Dynamics Network as a subroutine, to recognize events based on observations augmented by plan-recognition-driven attention.
Mean Local Group Average Precision : A New Performance Metric for Hashing-based Retrieval
Nov 24, 2018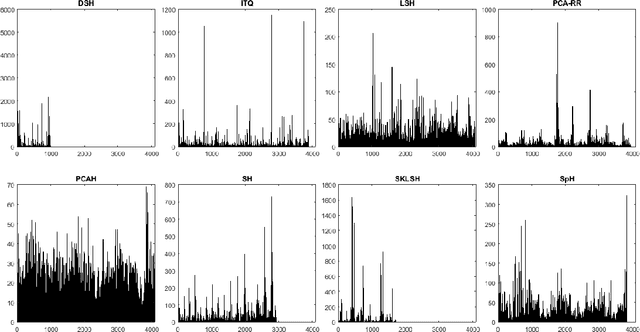

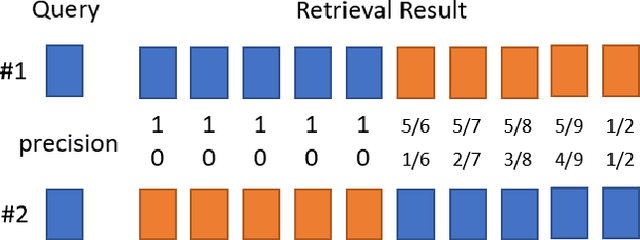
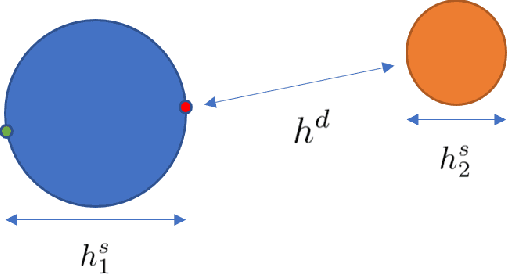
The research on hashing techniques for visual data is gaining increased attention in recent years due to the need for compact representations supporting efficient search/retrieval in large-scale databases such as online images. Among many possibilities, Mean Average Precision(mAP) has emerged as the dominant performance metric for hashing-based retrieval. One glaring shortcoming of mAP is its inability in balancing retrieval accuracy and utilization of hash codes: pushing a system to attain higher mAP will inevitably lead to poorer utilization of the hash codes. Poor utilization of the hash codes hinders good retrieval because of increased collision of samples in the hash space. This means that a model giving a higher mAP values does not necessarily do a better job in retrieval. In this paper, we introduce a new metric named Mean Local Group Average Precision (mLGAP) for better evaluation of the performance of hashing-based retrieval. The new metric provides a retrieval performance measure that also reconciles the utilization of hash codes, leading to a more practically meaningful performance metric than conventional ones like mAP. To this end, we start by mathematical analysis of the deficiencies of mAP for hashing-based retrieval. We then propose mLGAP and show why it is more appropriate for hashing-based retrieval. Experiments on image retrieval are used to demonstrate the effectiveness of the proposed metric.
Unsupervised Deep Image Hashing through Tag Embeddings
Jun 15, 2018
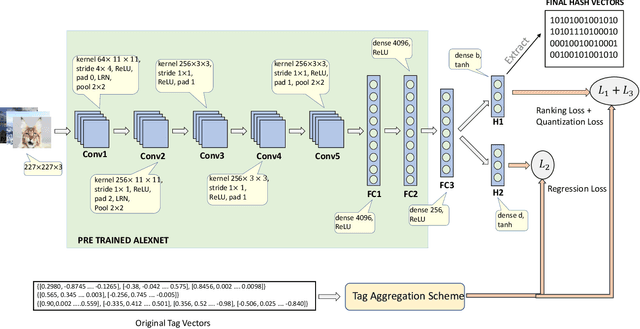
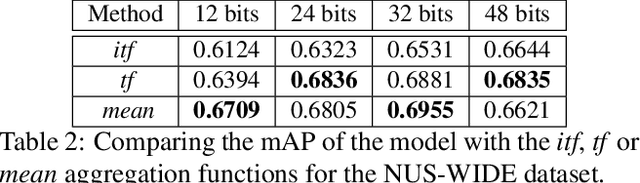
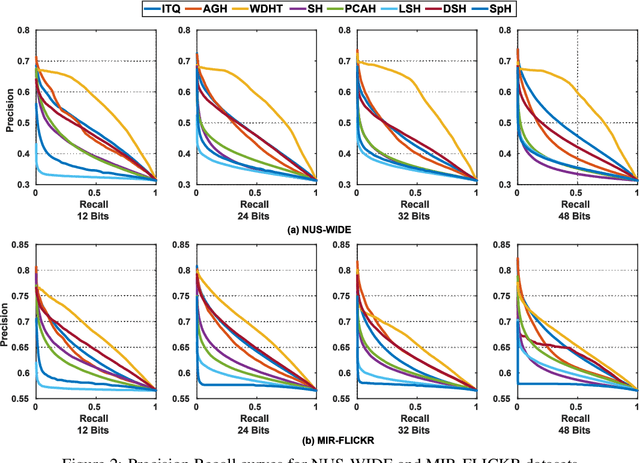
Many approaches to semantic image hashing have been formulated as supervised learning problems that utilize images and label information to learn the binary hash codes. However, large-scale labelled image data is expensive to obtain, thus imposing a restriction on the usage of such algorithms. On the other hand, unlabelled image data is abundant due to the existence of many Web image repositories. Such Web images may often come with images tags that contains useful information, although raw tags in general do not readily lead to semantic labels. Motivated by this scenario, we formulate the problem of image hashing as an unsupervised learning problem. We utilize the information contained in the user-generated tags associated with the images to learn the hash codes. More specifically, we extract the word2vec semantic embeddings of the tags and use the information contained in them for constraining the learning. Accordingly, we name our model Unsupervised Deep Hashing using Tag Embeddings (UDHT). UDHT is tested for the task of semantic image retrieval and is compared against several state-of-art unsupervised models. Results show that our approach sets a new state-of-art in the area of unsupervised image hashing.
Training Neural Networks by Using Power Linear Units (PoLUs)
Feb 01, 2018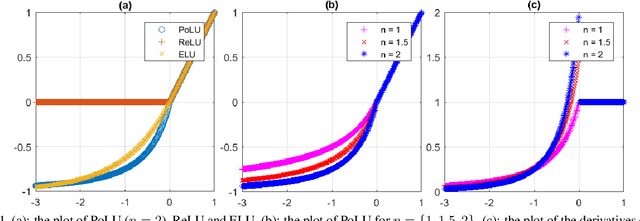

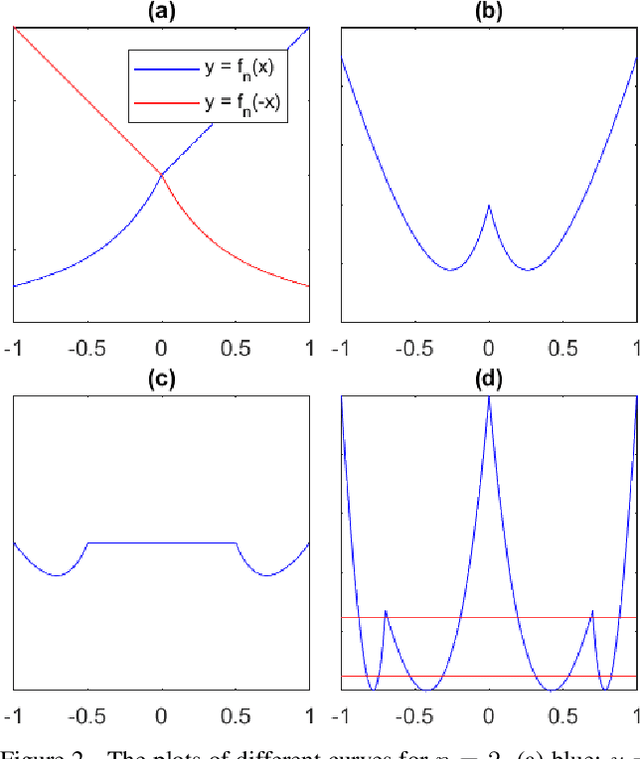

In this paper, we introduce "Power Linear Unit" (PoLU) which increases the nonlinearity capacity of a neural network and thus helps improving its performance. PoLU adopts several advantages of previously proposed activation functions. First, the output of PoLU for positive inputs is designed to be identity to avoid the gradient vanishing problem. Second, PoLU has a non-zero output for negative inputs such that the output mean of the units is close to zero, hence reducing the bias shift effect. Thirdly, there is a saturation on the negative part of PoLU, which makes it more noise-robust for negative inputs. Furthermore, we prove that PoLU is able to map more portions of every layer's input to the same space by using the power function and thus increases the number of response regions of the neural network. We use image classification for comparing our proposed activation function with others. In the experiments, MNIST, CIFAR-10, CIFAR-100, Street View House Numbers (SVHN) and ImageNet are used as benchmark datasets. The neural networks we implemented include widely-used ELU-Network, ResNet-50, and VGG16, plus a couple of shallow networks. Experimental results show that our proposed activation function outperforms other state-of-the-art models with most networks.
Recognizing Plans by Learning Embeddings from Observed Action Distributions
Dec 05, 2017
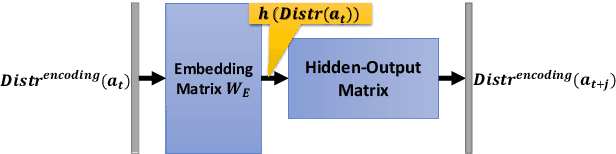

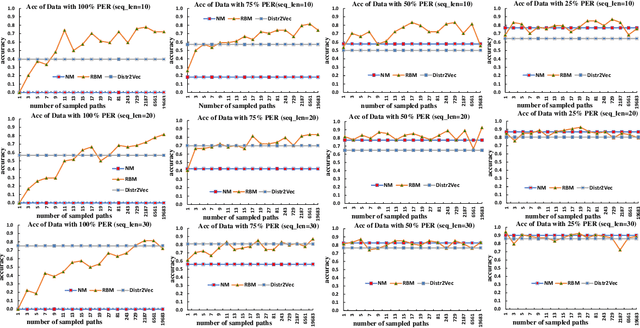
Recent advances in visual activity recognition have raised the possibility of applications such as automated video surveillance. Effective approaches for such problems however require the ability to recognize the plans of the agents from video information. Although traditional plan recognition algorithms depend on access to sophisticated domain models, one recent promising direction involves learning shallow models directly from the observed activity sequences, and using them to recognize/predict plans. One limitation of such approaches is that they expect observed action sequences as training data. In many cases involving vision or sensing from raw data, there is considerably uncertainty about the specific action at any given time point. The most we can expect in such cases is probabilistic information about the action at that point. The training data will then be sequences of such observed action distributions. In this paper, we focus on doing effective plan recognition with such uncertain observations. Our contribution is a novel extension of word vector embedding techniques to directly handle such observation distributions as input. This involves computing embeddings by minimizing the distance between distributions (measured as KL-divergence). We will show that our approach has superior performance when the perception error rate (PER) is higher, and competitive performance when the PER is lower. We will also explore the possibility of using importance sampling techniques to handle observed action distributions with traditional word vector embeddings. We will show that although such approaches can give good recognition accuracy, they take significantly longer training time and their performance will degrade significantly at higher perception error rate.
Joint Cuts and Matching of Partitions in One Graph
Nov 27, 2017
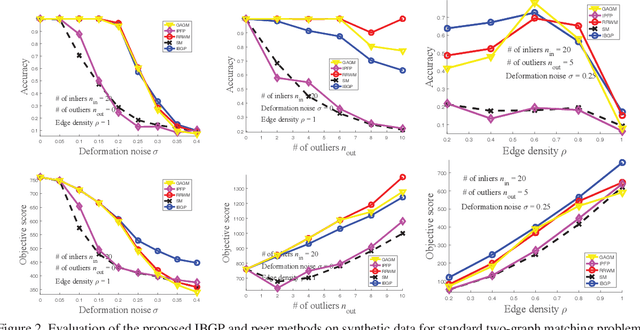
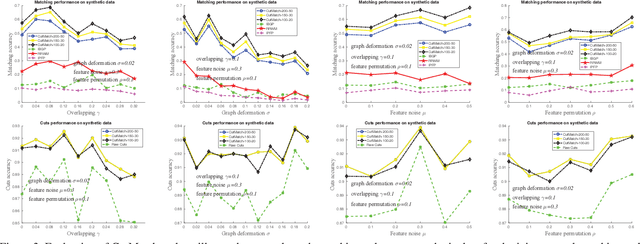
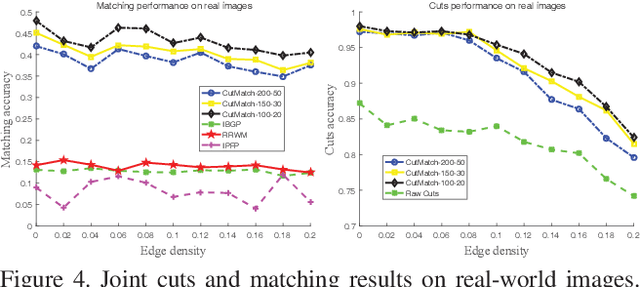
As two fundamental problems, graph cuts and graph matching have been investigated over decades, resulting in vast literature in these two topics respectively. However the way of jointly applying and solving graph cuts and matching receives few attention. In this paper, we first formalize the problem of simultaneously cutting a graph into two partitions i.e. graph cuts and establishing their correspondence i.e. graph matching. Then we develop an optimization algorithm by updating matching and cutting alternatively, provided with theoretical analysis. The efficacy of our algorithm is verified on both synthetic dataset and real-world images containing similar regions or structures.
Capturing Localized Image Artifacts through a CNN-based Hyper-image Representation
Nov 14, 2017
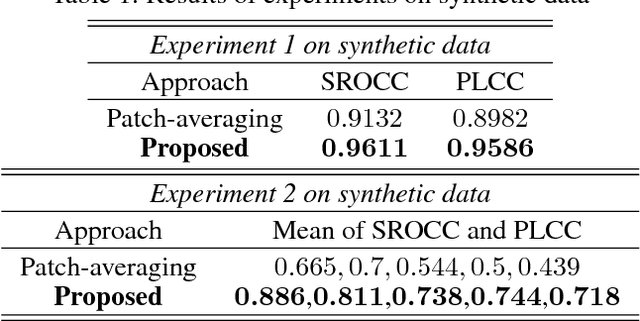
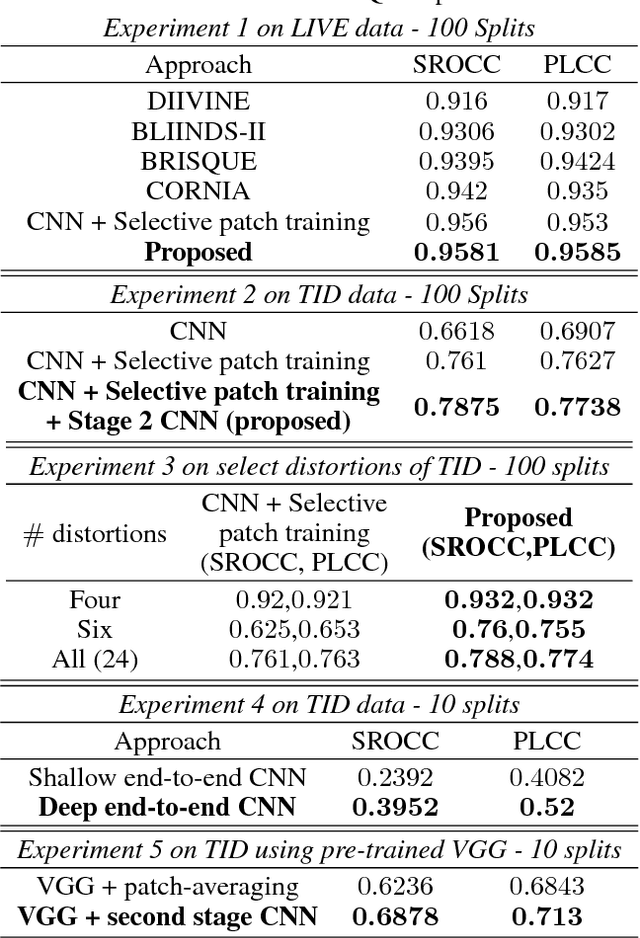

Training deep CNNs to capture localized image artifacts on a relatively small dataset is a challenging task. With enough images at hand, one can hope that a deep CNN characterizes localized artifacts over the entire data and their effect on the output. However, on smaller datasets, such deep CNNs may overfit and shallow ones find it hard to capture local artifacts. Thus some image-based small-data applications first train their framework on a collection of patches (instead of the entire image) to better learn the representation of localized artifacts. Then the output is obtained by averaging the patch-level results. Such an approach ignores the spatial correlation among patches and how various patch locations affect the output. It also fails in cases where few patches mainly contribute to the image label. To combat these scenarios, we develop the notion of hyper-image representations. Our CNN has two stages. The first stage is trained on patches. The second stage utilizes the last layer representation developed in the first stage to form a hyper-image, which is used to train the second stage. We show that this approach is able to develop a better mapping between the image and its output. We analyze additional properties of our approach and show its effectiveness on one synthetic and two real-world vision tasks - no-reference image quality estimation and image tampering detection - by its performance improvement over existing strong baselines.