 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnrolled Decomposed Unpaired Learning for Controllable Low-Light Video Enhancement
Aug 22, 2024



Obtaining pairs of low/normal-light videos, with motions, is more challenging than still images, which raises technical issues and poses the technical route of unpaired learning as a critical role. This paper makes endeavors in the direction of learning for low-light video enhancement without using paired ground truth. Compared to low-light image enhancement, enhancing low-light videos is more difficult due to the intertwined effects of noise, exposure, and contrast in the spatial domain, jointly with the need for temporal coherence. To address the above challenge, we propose the Unrolled Decomposed Unpaired Network (UDU-Net) for enhancing low-light videos by unrolling the optimization functions into a deep network to decompose the signal into spatial and temporal-related factors, which are updated iteratively. Firstly, we formulate low-light video enhancement as a Maximum A Posteriori estimation (MAP) problem with carefully designed spatial and temporal visual regularization. Then, via unrolling the problem, the optimization of the spatial and temporal constraints can be decomposed into different steps and updated in a stage-wise manner. From the spatial perspective, the designed Intra subnet leverages unpair prior information from expert photography retouched skills to adjust the statistical distribution. Additionally, we introduce a novel mechanism that integrates human perception feedback to guide network optimization, suppressing over/under-exposure conditions. Meanwhile, to address the issue from the temporal perspective, the designed Inter subnet fully exploits temporal cues in progressive optimization, which helps achieve improved temporal consistency in enhancement results. Consequently, the proposed method achieves superior performance to state-of-the-art methods in video illumination, noise suppression, and temporal consistency across outdoor and indoor scenes.
Sliced Maximal Information Coefficient: A Training-Free Approach for Image Quality Assessment Enhancement
Aug 19, 2024



Full-reference image quality assessment (FR-IQA) models generally operate by measuring the visual differences between a degraded image and its reference. However, existing FR-IQA models including both the classical ones (eg, PSNR and SSIM) and deep-learning based measures (eg, LPIPS and DISTS) still exhibit limitations in capturing the full perception characteristics of the human visual system (HVS). In this paper, instead of designing a new FR-IQA measure, we aim to explore a generalized human visual attention estimation strategy to mimic the process of human quality rating and enhance existing IQA models. In particular, we model human attention generation by measuring the statistical dependency between the degraded image and the reference image. The dependency is captured in a training-free manner by our proposed sliced maximal information coefficient and exhibits surprising generalization in different IQA measures. Experimental results verify the performance of existing IQA models can be consistently improved when our attention module is incorporated. The source code is available at https://github.com/KANGX99/SMIC.
Adaptive Image Quality Assessment via Teaching Large Multimodal Model to Compare
May 29, 2024



While recent advancements in large multimodal models (LMMs) have significantly improved their abilities in image quality assessment (IQA) relying on absolute quality rating, how to transfer reliable relative quality comparison outputs to continuous perceptual quality scores remains largely unexplored. To address this gap, we introduce Compare2Score-an all-around LMM-based no-reference IQA (NR-IQA) model, which is capable of producing qualitatively comparative responses and effectively translating these discrete comparative levels into a continuous quality score. Specifically, during training, we present to generate scaled-up comparative instructions by comparing images from the same IQA dataset, allowing for more flexible integration of diverse IQA datasets. Utilizing the established large-scale training corpus, we develop a human-like visual quality comparator. During inference, moving beyond binary choices, we propose a soft comparison method that calculates the likelihood of the test image being preferred over multiple predefined anchor images. The quality score is further optimized by maximum a posteriori estimation with the resulting probability matrix. Extensive experiments on nine IQA datasets validate that the Compare2Score effectively bridges text-defined comparative levels during training with converted single image quality score for inference, surpassing state-of-the-art IQA models across diverse scenarios. Moreover, we verify that the probability-matrix-based inference conversion not only improves the rating accuracy of Compare2Score but also zero-shot general-purpose LMMs, suggesting its intrinsic effectiveness.
2AFC Prompting of Large Multimodal Models for Image Quality Assessment
Feb 02, 2024



While abundant research has been conducted on improving high-level visual understanding and reasoning capabilities of large multimodal models~(LMMs), their visual quality assessment~(IQA) ability has been relatively under-explored. Here we take initial steps towards this goal by employing the two-alternative forced choice~(2AFC) prompting, as 2AFC is widely regarded as the most reliable way of collecting human opinions of visual quality. Subsequently, the global quality score of each image estimated by a particular LMM can be efficiently aggregated using the maximum a posterior estimation. Meanwhile, we introduce three evaluation criteria: consistency, accuracy, and correlation, to provide comprehensive quantifications and deeper insights into the IQA capability of five LMMs. Extensive experiments show that existing LMMs exhibit remarkable IQA ability on coarse-grained quality comparison, but there is room for improvement on fine-grained quality discrimination. The proposed dataset sheds light on the future development of IQA models based on LMMs. The codes will be made publicly available at https://github.com/h4nwei/2AFC-LMMs.
Perceptual Quality Assessment of Face Video Compression: A Benchmark and An Effective Method
May 04, 2023



Recent years have witnessed an exponential increase in the demand for face video compression, and the success of artificial intelligence has expanded the boundaries beyond traditional hybrid video coding. Generative coding approaches have been identified as promising alternatives with reasonable perceptual rate-distortion trade-offs, leveraging the statistical priors of face videos. However, the great diversity of distortion types in spatial and temporal domains, ranging from the traditional hybrid coding frameworks to generative models, present grand challenges in compressed face video quality assessment (VQA). In this paper, we introduce the large-scale Compressed Face Video Quality Assessment (CFVQA) database, which is the first attempt to systematically understand the perceptual quality and diversified compression distortions in face videos. The database contains 3,240 compressed face video clips in multiple compression levels, which are derived from 135 source videos with diversified content using six representative video codecs, including two traditional methods based on hybrid coding frameworks, two end-to-end methods, and two generative methods. In addition, a FAce VideO IntegeRity (FAVOR) index for face video compression was developed to measure the perceptual quality, considering the distinct content characteristics and temporal priors of the face videos. Experimental results exhibit its superior performance on the proposed CFVQA dataset. The benchmark is now made publicly available at: https://github.com/Yixuan423/Compressed-Face-Videos-Quality-Assessment.
Debiased Mapping for Full-Reference Image Quality Assessment
Feb 22, 2023Mapping images to deep feature space for comparisons has been wildly adopted in recent learning-based full-reference image quality assessment (FR-IQA) models. Analogous to the classical classification task, the ideal mapping space for quality regression should possess both inter-class separability and intra-class compactness. The inter-class separability that focuses on the discrimination of images with different quality levels has been highly emphasized in existing models. However, the intra-class compactness that maintains small objective quality variance of images with the same or indistinguishable quality escapes the research attention, potentially leading to the perception-biased measures. In this paper, we reveal that such bias is mainly caused by the unsuitable subspace that the features are projected and compared in. To account for this, we develop the Debiased Mapping based quality Measure (DMM), which relies on the orthonormal bases of deep learning features formed by singular value decomposition (SVD). The SVD in deep learning feature domain, which overwhelmingly separates the quality variations with singular values and projection bases, facilitates the quality inference with dedicatedly designed distance measure. Experiments on different IQA databases demonstrate the mapping method is able to mitigate the perception bias efficiently, and the superior performance on quality prediction verifies the effectiveness of our method. The implementation will be publicly available.
From Distance to Dependency: A Paradigm Shift of Full-reference Image Quality Assessment
Nov 09, 2022



Deep learning-based full-reference image quality assessment (FR-IQA) models typically rely on the feature distance between the reference and distorted images. However, the underlying assumption of these models that the distance in the deep feature domain could quantify the quality degradation does not scientifically align with the invariant texture perception, especially when the images are generated artificially by neural networks. In this paper, we bring a radical shift in inferring the quality with learned features and propose the Deep Image Dependency (DID) based FR-IQA model. The feature dependency facilitates the comparisons of deep learning features in a high-order manner with Brownian distance covariance, which is characterized by the joint distribution of the features from reference and test images, as well as their marginal distributions. This enables the quantification of the feature dependency against nonlinear transformation, which is far beyond the computation of the numerical errors in the feature space. Experiments on image quality prediction, texture image similarity, and geometric invariance validate the superior performance of our proposed measure.
Learning from Mixed Datasets: A Monotonic Image Quality Assessment Model
Sep 28, 2022
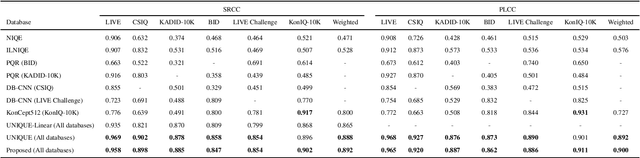
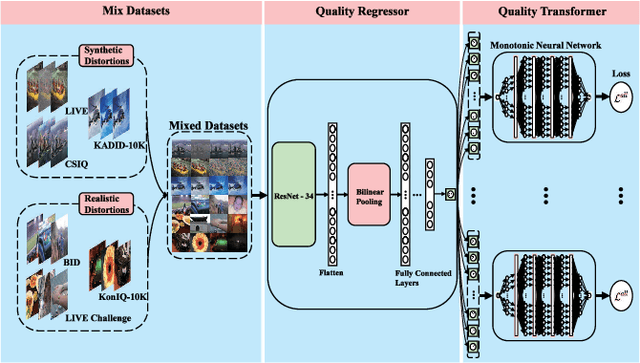

Deep learning based image quality assessment (IQA) models usually learn to predict image quality from a single dataset, leading the model to overfit specific scenes. To account for this, mixed datasets training can be an effective way to enhance the generalization capability of the model. However, it is nontrivial to combine different IQA datasets, as their quality evaluation criteria, score ranges, view conditions, as well as subjects are usually not shared during the image quality annotation. In this paper, instead of aligning the annotations, we propose a monotonic neural network for IQA model learning with different datasets combined. In particular, our model consists of a dataset-shared quality regressor and several dataset-specific quality transformers. The quality regressor aims to obtain the perceptual qualities of each dataset while each quality transformer maps the perceptual qualities to the corresponding dataset annotations with their monotonicity maintained. The experimental results verify the effectiveness of the proposed learning strategy and our code is available at https://github.com/fzp0424/MonotonicIQA.
Deep Feature Statistics Mapping for Generalized Screen Content Image Quality Assessment
Sep 14, 2022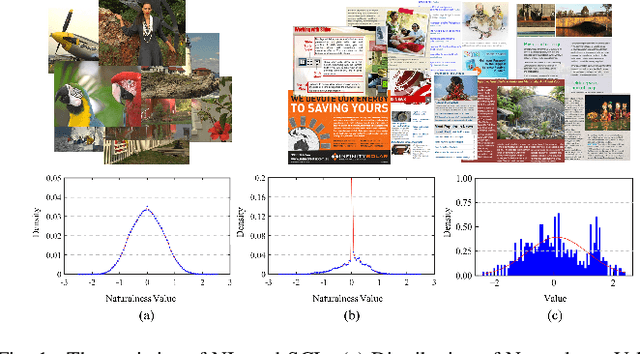
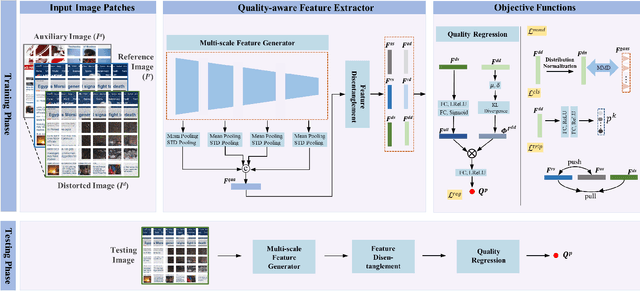

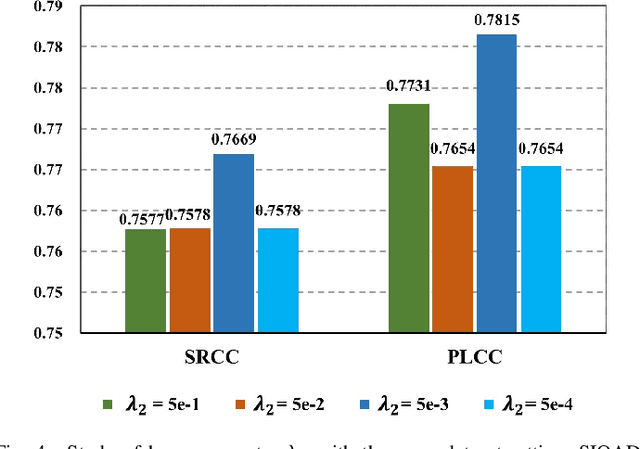
The statistical regularities of natural images, referred to as natural scene statistics, play an important role in no-reference image quality assessment. However, it has been widely acknowledged that screen content images (SCIs), which are typically computer generated, do not hold such statistics. Here we make the first attempt to learn the statistics of SCIs, based upon which the quality of SCIs can be effectively determined. The underlying mechanism of the proposed approach is based upon the wild assumption that the SCIs, which are not physically acquired, still obey certain statistics that could be understood in a learning fashion. We empirically show that the statistics deviation could be effectively leveraged in quality assessment, and the proposed method is superior when evaluated in different settings. Extensive experimental results demonstrate the Deep Feature Statistics based SCI Quality Assessment (DFSS-IQA) model delivers promising performance compared with existing NR-IQA models and shows a high generalization capability in the cross-dataset settings. The implementation of our method is publicly available at https://github.com/Baoliang93/DFSS-IQA.
Just Noticeable Difference Modeling for Face Recognition System
Sep 13, 2022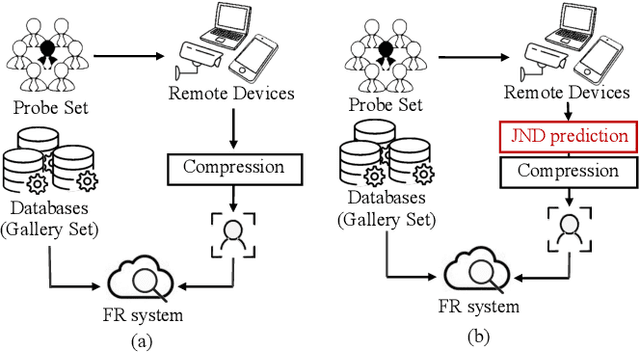
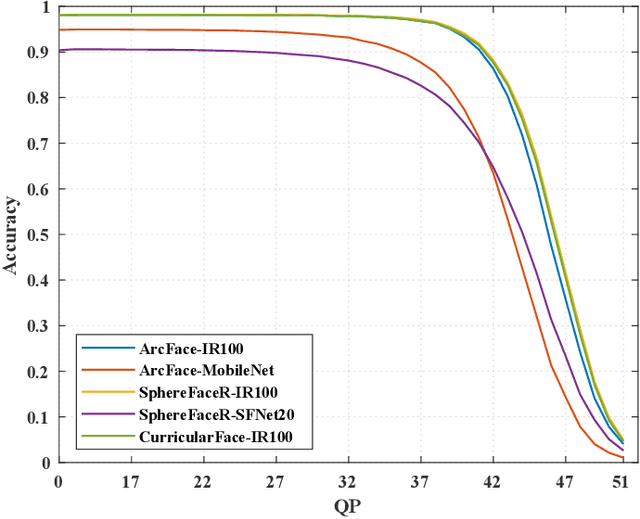
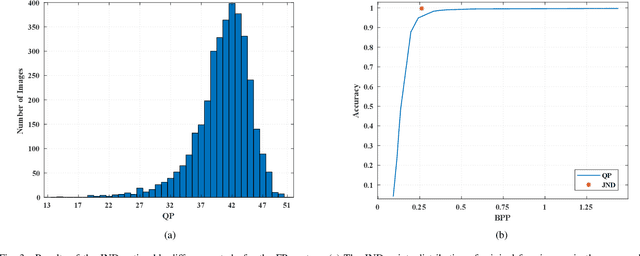
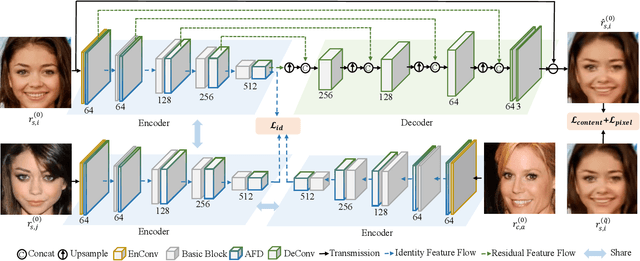
High-quality face images are required to guarantee the stability and reliability of automatic face recognition (FR) systems in surveillance and security scenarios. However, a massive amount of face data is usually compressed before being analyzed due to limitations on transmission or storage. The compressed images may lose the powerful identity information, resulting in the performance degradation of the FR system. Herein, we make the first attempt to study just noticeable difference (JND) for the FR system, which can be defined as the maximum distortion that the FR system cannot notice. More specifically, we establish a JND dataset including 3530 original images and 137,670 compressed images generated by advanced reference encoding/decoding software based on the Versatile Video Coding (VVC) standard (VTM-15.0). Subsequently, we develop a novel JND prediction model to directly infer JND images for the FR system. In particular, in order to maximum redundancy removal without impairment of robust identity information, we apply the encoder with multiple feature extraction and attention-based feature decomposition modules to progressively decompose face features into two uncorrelated components, i.e., identity and residual features, via self-supervised learning. Then, the residual feature is fed into the decoder to generate the residual map. Finally, the predicted JND map is obtained by subtracting the residual map from the original image. Experimental results have demonstrated that the proposed model achieves higher accuracy of JND map prediction compared with the state-of-the-art JND models, and is capable of saving more bits while maintaining the performance of the FR system compared with VTM-15.0.