 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLT-GAN: Self-Supervised GAN with Latent Transformation Detection
Oct 19, 2020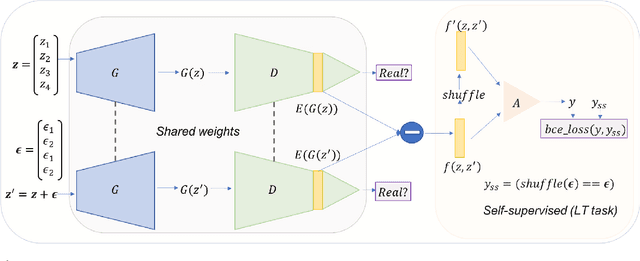
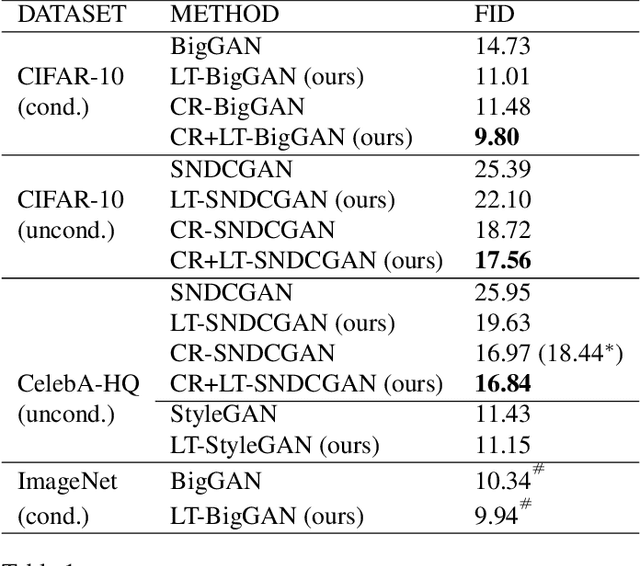

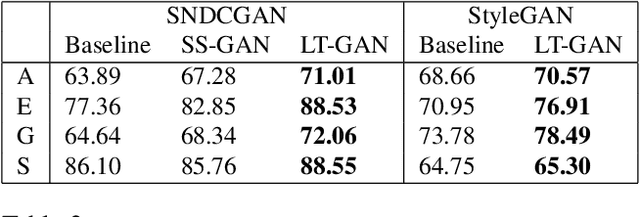
Generative Adversarial Networks (GANs) coupled with self-supervised tasks have shown promising results in unconditional and semi-supervised image generation. We propose a self-supervised approach (LT-GAN) to improve the generation quality and diversity of images by estimating the GAN-induced transformation (i.e. transformation induced in the generated images by perturbing the latent space of generator). Specifically, given two pairs of images where each pair comprises of a generated image and its transformed version, the self-supervision task aims to identify whether the latent transformation applied in the given pair is same to that of the other pair. Hence, this auxiliary loss encourages the generator to produce images that are distinguishable by the auxiliary network, which in turn promotes the synthesis of semantically consistent images with respect to latent transformations. We show the efficacy of this pretext task by improving the image generation quality in terms of FID on state-of-the-art models for both conditional and unconditional settings on CIFAR-10, CelebA-HQ and ImageNet datasets. Moreover, we empirically show that LT-GAN helps in improving controlled image editing for CelebA-HQ and ImageNet over baseline models. We experimentally demonstrate that our proposed LT self-supervision task can be effectively combined with other state-of-the-art training techniques for added benefits. Consequently, we show that our approach achieves the new state-of-the-art FID score of 9.8 on conditional CIFAR-10 image generation.
Unsupervised Hierarchical Concept Learning
Oct 06, 2020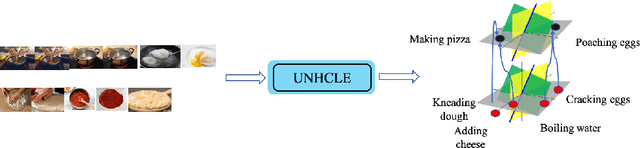

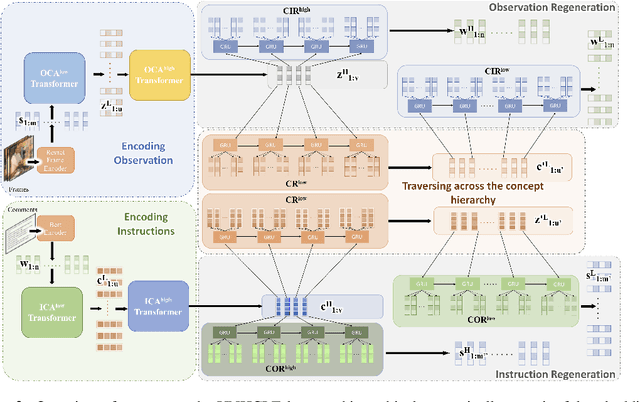
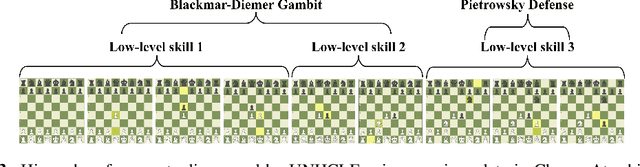
Discovering concepts (or temporal abstractions) in an unsupervised manner from demonstration data in the absence of an environment is an important problem. Organizing these discovered concepts hierarchically at different levels of abstraction is useful in discovering patterns, building ontologies, and generating tutorials from demonstration data. However, recent work to discover such concepts without access to any environment does not discover relationships (or a hierarchy) between these discovered concepts. In this paper, we present a Transformer-based concept abstraction architecture UNHCLE (pronounced uncle) that extracts a hierarchy of concepts in an unsupervised way from demonstration data. We empirically demonstrate how UNHCLE discovers meaningful hierarchies using datasets from Chess and Cooking domains. Finally, we show how UNHCLE learns meaningful language labels for concepts by using demonstration data augmented with natural language for cooking and chess. All of our code is available at https://github.com/UNHCLE/UNHCLE
TRACE: Transform Aggregate and Compose Visiolinguistic Representations for Image Search with Text Feedback
Sep 03, 2020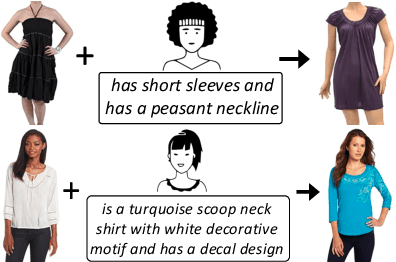
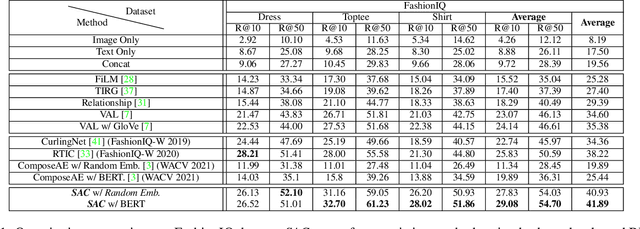
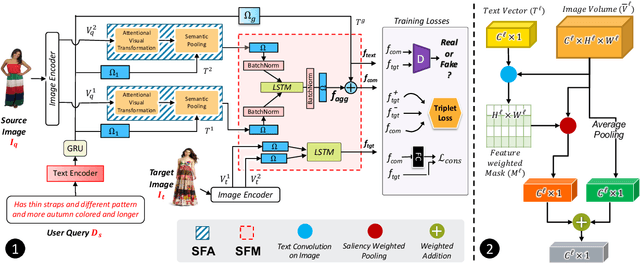
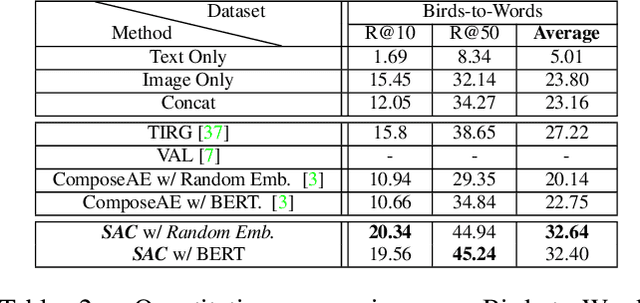
The ability to efficiently search for images over an indexed database is the cornerstone for several user experiences. Incorporating user feedback, through multi-modal inputs provide flexible and interaction to serve fine-grained specificity in requirements. We specifically focus on text feedback, through descriptive natural language queries. Given a reference image and textual user feedback, our goal is to retrieve images that satisfy constraints specified by both of these input modalities. The task is challenging as it requires understanding the textual semantics from the text feedback and then applying these changes to the visual representation. To address these challenges, we propose a novel architecture TRACE which contains a hierarchical feature aggregation module to learn the composite visio-linguistic representations. TRACE achieves the SOTA performance on 3 benchmark datasets: FashionIQ, Shoes, and Birds-to-Words, with an average improvement of at least ~5.7%, ~3%, and ~5% respectively in R@K metric. Our extensive experiments and ablation studies show that TRACE consistently outperforms the existing techniques by significant margins both quantitatively and qualitatively.
Retrospective Loss: Looking Back to Improve Training of Deep Neural Networks
Jun 24, 2020
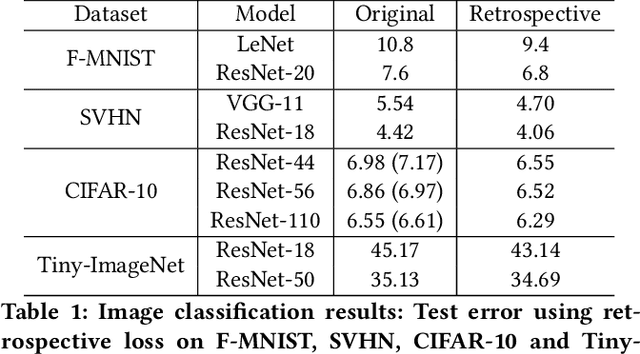
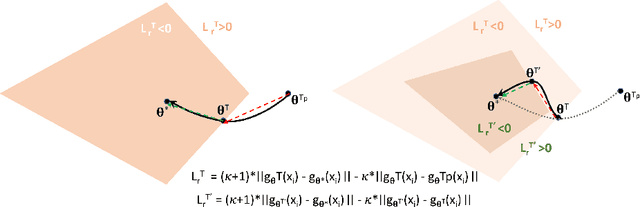
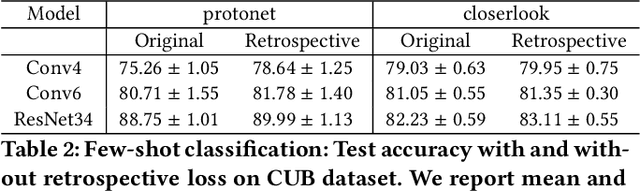
Deep neural networks (DNNs) are powerful learning machines that have enabled breakthroughs in several domains. In this work, we introduce a new retrospective loss to improve the training of deep neural network models by utilizing the prior experience available in past model states during training. Minimizing the retrospective loss, along with the task-specific loss, pushes the parameter state at the current training step towards the optimal parameter state while pulling it away from the parameter state at a previous training step. Although a simple idea, we analyze the method as well as to conduct comprehensive sets of experiments across domains - images, speech, text, and graphs - to show that the proposed loss results in improved performance across input domains, tasks, and architectures.
SimPropNet: Improved Similarity Propagation for Few-shot Image Segmentation
May 02, 2020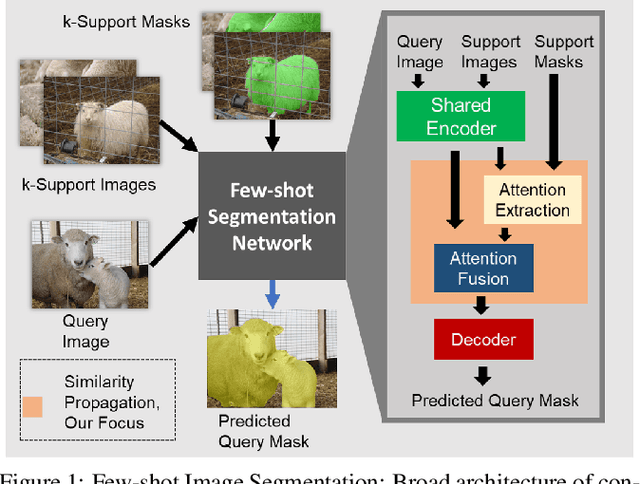

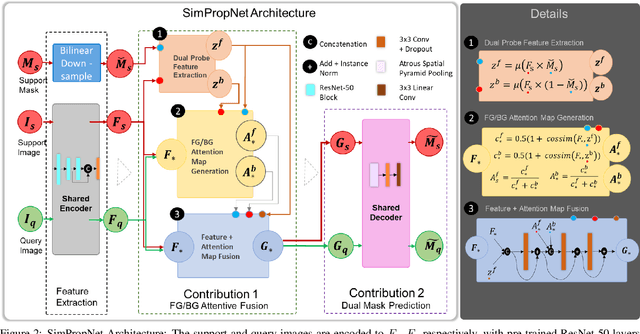
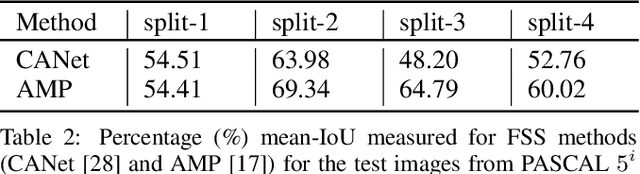
Few-shot segmentation (FSS) methods perform image segmentation for a particular object class in a target (query) image, using a small set of (support) image-mask pairs. Recent deep neural network based FSS methods leverage high-dimensional feature similarity between the foreground features of the support images and the query image features. In this work, we demonstrate gaps in the utilization of this similarity information in existing methods, and present a framework - SimPropNet, to bridge those gaps. We propose to jointly predict the support and query masks to force the support features to share characteristics with the query features. We also propose to utilize similarities in the background regions of the query and support images using a novel foreground-background attentive fusion mechanism. Our method achieves state-of-the-art results for one-shot and five-shot segmentation on the PASCAL-5i dataset. The paper includes detailed analysis and ablation studies for the proposed improvements and quantitative comparisons with contemporary methods.
Exploring Neural Models for Parsing Natural Language into First-Order Logic
Feb 16, 2020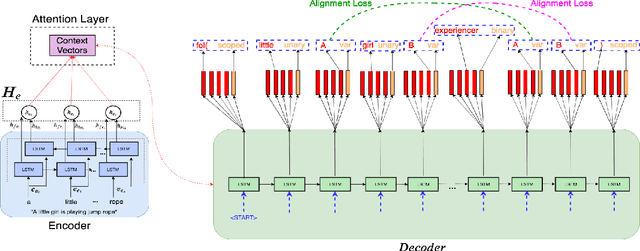
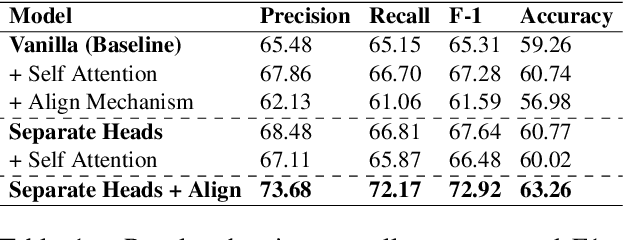
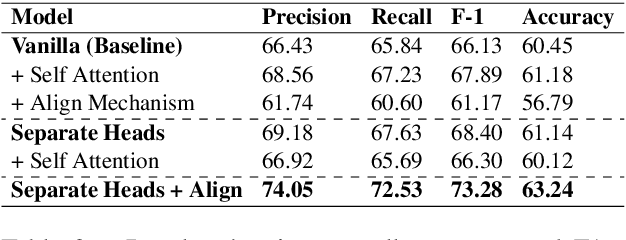
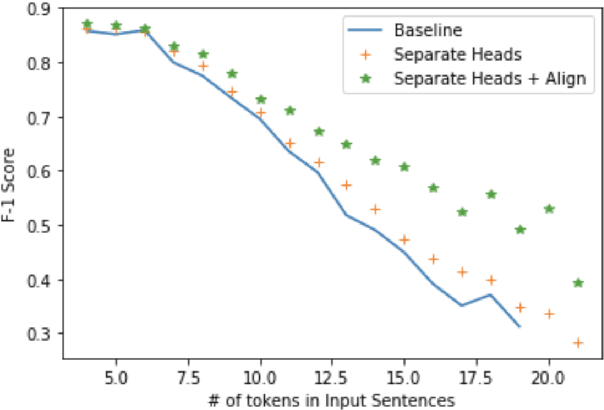
Semantic parsing is the task of obtaining machine-interpretable representations from natural language text. We consider one such formal representation - First-Order Logic (FOL) and explore the capability of neural models in parsing English sentences to FOL. We model FOL parsing as a sequence to sequence mapping task where given a natural language sentence, it is encoded into an intermediate representation using an LSTM followed by a decoder which sequentially generates the predicates in the corresponding FOL formula. We improve the standard encoder-decoder model by introducing a variable alignment mechanism that enables it to align variables across predicates in the predicted FOL. We further show the effectiveness of predicting the category of FOL entity - Unary, Binary, Variables and Scoped Entities, at each decoder step as an auxiliary task on improving the consistency of generated FOL. We perform rigorous evaluations and extensive ablations. We also aim to release our code as well as large scale FOL dataset along with models to aid further research in logic-based parsing and inference in NLP.
Inducing Cooperative behaviour in Sequential-Social dilemmas through Multi-Agent Reinforcement Learning using Status-Quo Loss
Feb 13, 2020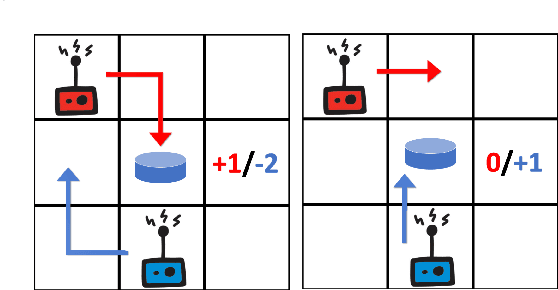

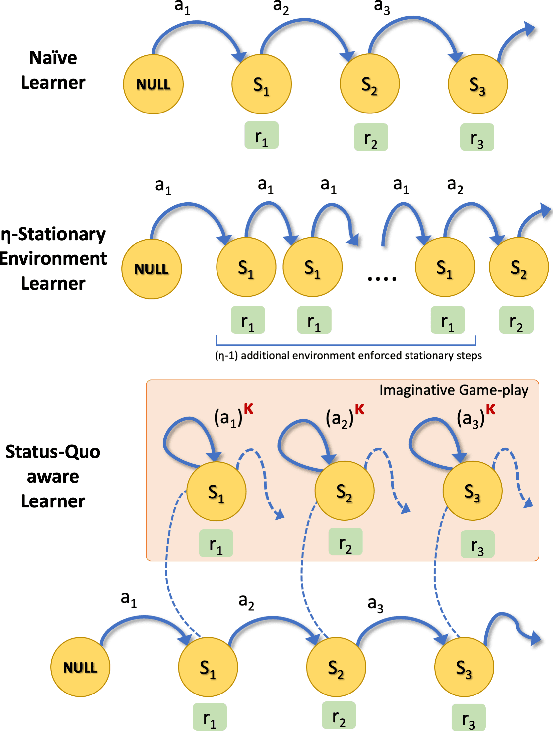
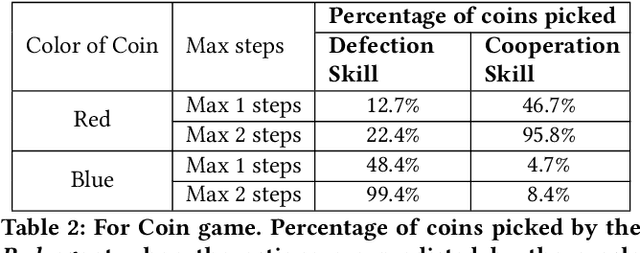
In social dilemma situations, individual rationality leads to sub-optimal group outcomes. Several human engagements can be modeled as a sequential (multi-step) social dilemmas. However, in contrast to humans, Deep Reinforcement Learning agents trained to optimize individual rewards in sequential social dilemmas converge to selfish, mutually harmful behavior. We introduce a status-quo loss (SQLoss) that encourages an agent to stick to the status quo, rather than repeatedly changing its policy. We show how agents trained with SQLoss evolve cooperative behavior in several social dilemma matrix games. To work with social dilemma games that have visual input, we propose GameDistill. GameDistill uses self-supervision and clustering to automatically extract cooperative and selfish policies from a social dilemma game. We combine GameDistill and SQLoss to show how agents evolve socially desirable cooperative behavior in the Coin Game.
ShapeVis: High-dimensional Data Visualization at Scale
Jan 21, 2020
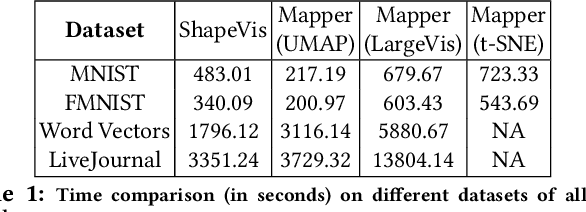
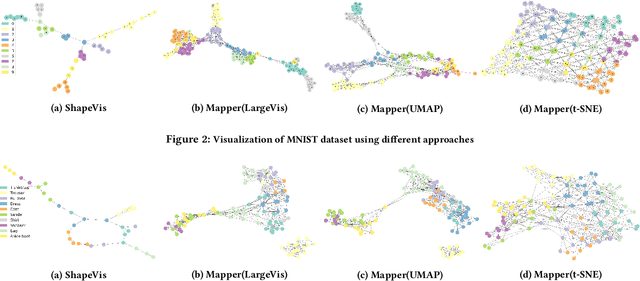
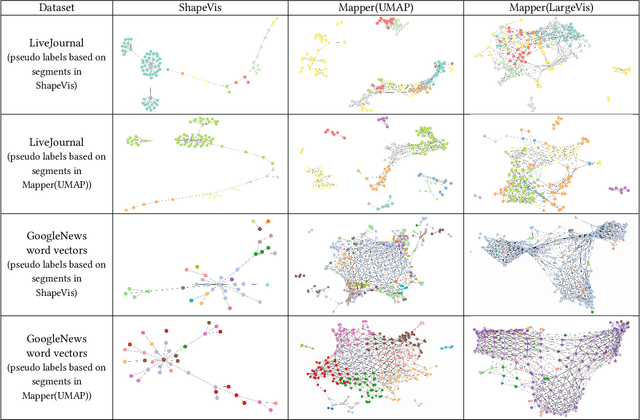
We present ShapeVis, a scalable visualization technique for point cloud data inspired from topological data analysis. Our method captures the underlying geometric and topological structure of the data in a compressed graphical representation. Much success has been reported by the data visualization technique Mapper, that discreetly approximates the Reeb graph of a filter function on the data. However, when using standard dimensionality reduction algorithms as the filter function, Mapper suffers from considerable computational cost. This makes it difficult to scale to high-dimensional data. Our proposed technique relies on finding a subset of points called landmarks along the data manifold to construct a weighted witness-graph over it. This graph captures the structural characteristics of the point cloud, and its weights are determined using a Finite Markov Chain. We further compress this graph by applying induced maps from standard community detection algorithms. Using techniques borrowed from manifold tearing, we prune and reinstate edges in the induced graph based on their modularity to summarize the shape of data. We empirically demonstrate how our technique captures the structural characteristics of real and synthetic data sets. Further, we compare our approach with Mapper using various filter functions like t-SNE, UMAP, LargeVis and show that our algorithm scales to millions of data points while preserving the quality of data visualization.
SieveNet: A Unified Framework for Robust Image-Based Virtual Try-On
Jan 17, 2020
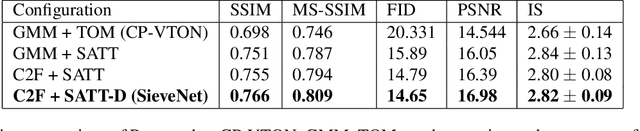
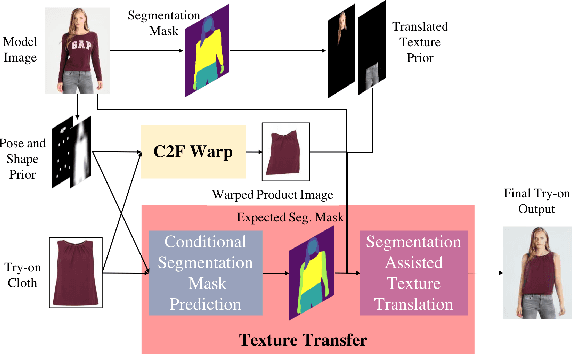
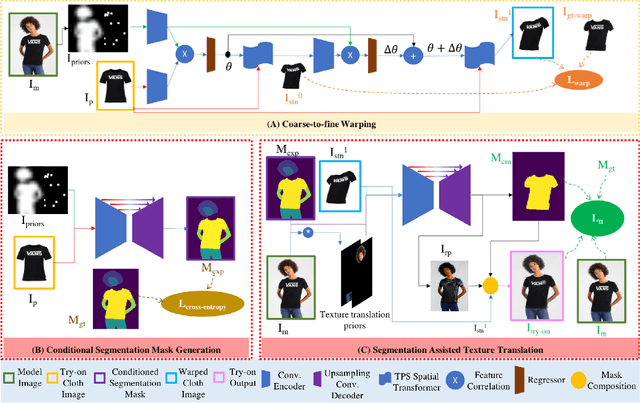
Image-based virtual try-on for fashion has gained considerable attention recently. The task requires trying on a clothing item on a target model image. An efficient framework for this is composed of two stages: (1) warping (transforming) the try-on cloth to align with the pose and shape of the target model, and (2) a texture transfer module to seamlessly integrate the warped try-on cloth onto the target model image. Existing methods suffer from artifacts and distortions in their try-on output. In this work, we present SieveNet, a framework for robust image-based virtual try-on. Firstly, we introduce a multi-stage coarse-to-fine warping network to better model fine-grained intricacies (while transforming the try-on cloth) and train it with a novel perceptual geometric matching loss. Next, we introduce a try-on cloth conditioned segmentation mask prior to improve the texture transfer network. Finally, we also introduce a dueling triplet loss strategy for training the texture translation network which further improves the quality of the generated try-on results. We present extensive qualitative and quantitative evaluations of each component of the proposed pipeline and show significant performance improvements against the current state-of-the-art method.
Explain Your Move: Understanding Agent Actions Using Focused Feature Saliency
Dec 31, 2019

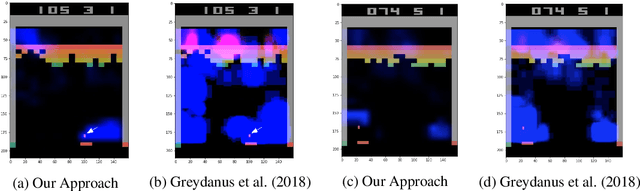
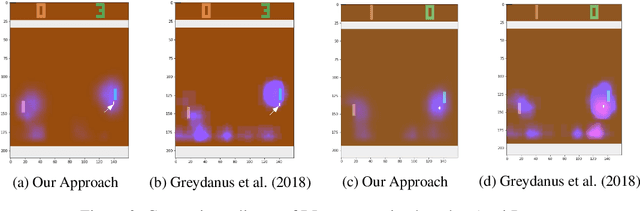
As deep reinforcement learning (RL) is applied to more tasks, there is a need to visualize and understand the behavior of learned agents. Saliency maps explain agent behavior by highlighting the features of the input state that are most relevant for the agent in taking an action. Existing perturbation-based approaches to compute saliency often highlight regions of the input that are not relevant to the action taken by the agent. Our approach generates more focused saliency maps by balancing two aspects (specificity and relevance) that capture different desiderata of saliency. The first captures the impact of perturbation on the relative expected reward of the action to be explained. The second downweights irrelevant features that alter the relative expected rewards of actions other than the action to be explained. We compare our approach with existing approaches on agents trained to play board games (Chess and Go) and Atari games (Breakout, Pong and Space Invaders). We show through illustrative examples (Chess, Atari, Go), human studies (Chess), and automated evaluation methods (Chess) that our approach generates saliency maps that are more interpretable for humans than existing approaches.