 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Distribution as a Lever for Guiding Optimizers Toward Superior Generalization in LLMs
Jan 31, 2026Can modifying the training data distribution guide optimizers toward solutions with improved generalization when training large language models (LLMs)? In this work, we theoretically analyze an in-context linear regression model with multi-head linear self-attention, and compare the training dynamics of two gradient based optimizers, namely gradient descent (GD) and sharpness-aware minimization (SAM), the latter exhibiting superior generalization properties but is prohibitively expensive for training even medium-sized LLMs. We show, for the first time, that SAM induces a lower simplicity bias (SB)-the tendency of an optimizer to preferentially learn simpler features earlier in training-and identify this reduction as a key factor underlying its improved generalization performance. Motivated by this insight, we demonstrate that altering the training data distribution by upsampling or augmenting examples learned later in training similarly reduces SB and leads to improved generalization. Our extensive experiments show that our strategy improves the performance of multiple LLMs-including Phi2-2.7B , Llama3.2-1B, Gemma3-1B-PT, and Qwen3-0.6B-Base-achieving relative accuracy gains up to 18% when fine-tuned with AdamW and Muon on mathematical reasoning tasks.
Beyond What Seems Necessary: Hidden Gains from Scaling Training-Time Reasoning Length under Outcome Supervision
Jan 31, 2026Training LLMs to think and reason for longer has become a key ingredient in building state-of-the-art models that can solve complex problems previously out of reach. Recent efforts pursue this in different ways, such as RL fine-tuning to elicit long CoT or scaling latent reasoning through architectural recurrence. This makes reasoning length an important scaling knob. In this work, we identify a novel phenomenon (both theoretically and experimentally): under outcome-only supervision, out-of-distribution (OOD) performance can continue improving as training-time reasoning length (e.g., the token budget in RL, or the loop count in looped Transformers) increases, even after in-distribution (ID) performance has saturated. This suggests that robustness may require a larger budget than ID validation alone would indicate. We provide theoretical explanations via two mechanisms: (i) self-iteration can induce a stronger inductive bias in the hypothesis class, reshaping ID-optimal solutions in ways that improve OOD generalization; and (ii) when shortcut solutions that work for ID samples but not for OOD samples persist in the hypothesis class, regularization can reduce the learned solution's reliance on these shortcuts as the number of self-iterations increases. We complement the theory with empirical evidence from two realizations of scaling training-time reasoning length: increasing the number of loops in looped Transformers on a synthetic task, and increasing token budgets during RL fine-tuning of LLMs on mathematical reasoning.
Tuning the Implicit Regularizer of Masked Diffusion Language Models: Enhancing Generalization via Insights from $k$-Parity
Jan 30, 2026Masked Diffusion Language Models have recently emerged as a powerful generative paradigm, yet their generalization properties remain understudied compared to their auto-regressive counterparts. In this work, we investigate these properties within the setting of the $k$-parity problem (computing the XOR sum of $k$ relevant bits), where neural networks typically exhibit grokking -- a prolonged plateau of chance-level performance followed by sudden generalization. We theoretically decompose the Masked Diffusion (MD) objective into a Signal regime which drives feature learning, and a Noise regime which serves as an implicit regularizer. By training nanoGPT using MD objective on the $k$-parity problem, we demonstrate that MD objective fundamentally alters the learning landscape, enabling rapid and simultaneous generalization without experiencing grokking. Furthermore, we leverage our theoretical insights to optimize the distribution of the mask probability in the MD objective. Our method significantly improves perplexity for 50M-parameter models and achieves superior results across both pre-training from scratch and supervised fine-tuning. Specifically, we observe performance gains peaking at $8.8\%$ and $5.8\%$, respectively, on 8B-parameter models, confirming the scalability and effectiveness of our framework in large-scale masked diffusion language model regimes.
Data Selection for Fine-tuning Vision Language Models via Cross Modal Alignment Trajectories
Oct 01, 2025Data-efficient learning aims to eliminate redundancy in large training datasets by training models on smaller subsets of the most informative examples. While data selection has been extensively explored for vision models and large language models (LLMs), it remains underexplored for Large Vision-Language Models (LVLMs). Notably, none of existing methods can outperform random selection at different subset sizes. In this work, we propose the first principled method for data-efficient instruction tuning of LVLMs. We prove that examples with similar cross-modal attention matrices during instruction tuning have similar gradients. Thus, they influence model parameters in a similar manner and convey the same information to the model during training. Building on this insight, we propose XMAS, which clusters examples based on the trajectories of the top singular values of their attention matrices obtained from fine-tuning a small proxy LVLM. By sampling a balanced subset from these clusters, XMAS effectively removes redundancy in large-scale LVLM training data. Extensive experiments show that XMAS can discard 50% of the LLaVA-665k dataset and 85% of the Vision-Flan dataset while fully preserving performance of LLaVA-1.5-7B on 10 downstream benchmarks and speeding up its training by 1.2x. This is 30% more data reduction compared to the best baseline for LLaVA-665k. The project's website can be found at https://bigml-cs-ucla.github.io/XMAS-project-page/.
LoRA is All You Need for Safety Alignment of Reasoning LLMs
Jul 22, 2025



Reasoning LLMs have demonstrated remarkable breakthroughs in solving complex problems that were previously out of reach. To ensure LLMs do not assist with harmful requests, safety alignment fine-tuning is necessary in the post-training phase. However, safety alignment fine-tuning has recently been shown to significantly degrade reasoning abilities, a phenomenon known as the "Safety Tax". In this work, we show that using LoRA for SFT on refusal datasets effectively aligns the model for safety without harming its reasoning capabilities. This is because restricting the safety weight updates to a low-rank space minimizes the interference with the reasoning weights. Our extensive experiments across four benchmarks covering math, science, and coding show that this approach produces highly safe LLMs -- with safety levels comparable to full-model fine-tuning -- without compromising their reasoning abilities. Additionally, we observe that LoRA induces weight updates with smaller overlap with the initial weights compared to full-model fine-tuning. We also explore methods that further reduce such overlap -- via regularization or during weight merging -- and observe some improvement on certain tasks. We hope this result motivates designing approaches that yield more consistent improvements in the reasoning-safety trade-off.
Bootstrapping LLM Robustness for VLM Safety via Reducing the Pretraining Modality Gap
May 30, 2025Ensuring Vision-Language Models (VLMs) generate safe outputs is crucial for their reliable deployment. However, LVLMs suffer from drastic safety degradation compared to their LLM backbone. Even blank or irrelevant images can trigger LVLMs to generate harmful responses to prompts that would otherwise be refused in text-only contexts. The modality gap between image and text representations has been recently hypothesized to contribute to safety degradation of LVLMs. However, if and how the amount of modality gap affects LVLMs' safety is not studied. In this work, we show that the amount of modality gap is highly inversely correlated with VLMs' safety. Then, we show that this modality gap is introduced during pretraining LVLMs and persists through fine-tuning. Inspired by this observation, we propose a regularization to reduce the modality gap during pretraining. Our extensive experiments on LLaVA v1.5, ShareGPT4V, and MiniGPT-4 show that our method substantially improves safety alignment of LVLMs, reducing unsafe rate by up to 16.3% without compromising performance, and can further boost existing defenses by up to 18.2%.
Do We Need All the Synthetic Data? Towards Targeted Synthetic Image Augmentation via Diffusion Models
May 27, 2025Synthetically augmenting training datasets with diffusion models has been an effective strategy for improving generalization of image classifiers. However, existing techniques struggle to ensure the diversity of generation and increase the size of the data by up to 10-30x to improve the in-distribution performance. In this work, we show that synthetically augmenting part of the data that is not learned early in training outperforms augmenting the entire dataset. By analyzing a two-layer CNN, we prove that this strategy improves generalization by promoting homogeneity in feature learning speed without amplifying noise. Our extensive experiments show that by augmenting only 30%-40% of the data, our method boosts the performance by up to 2.8% in a variety of scenarios, including training ResNet, ViT and DenseNet on CIFAR-10, CIFAR-100, and TinyImageNet, with a range of optimizers including SGD and SAM. Notably, our method applied with SGD outperforms the SOTA optimizer, SAM, on CIFAR-100 and TinyImageNet. It can also easily stack with existing weak and strong augmentation strategies to further boost the performance.
DD-Ranking: Rethinking the Evaluation of Dataset Distillation
May 19, 2025



In recent years, dataset distillation has provided a reliable solution for data compression, where models trained on the resulting smaller synthetic datasets achieve performance comparable to those trained on the original datasets. To further improve the performance of synthetic datasets, various training pipelines and optimization objectives have been proposed, greatly advancing the field of dataset distillation. Recent decoupled dataset distillation methods introduce soft labels and stronger data augmentation during the post-evaluation phase and scale dataset distillation up to larger datasets (e.g., ImageNet-1K). However, this raises a question: Is accuracy still a reliable metric to fairly evaluate dataset distillation methods? Our empirical findings suggest that the performance improvements of these methods often stem from additional techniques rather than the inherent quality of the images themselves, with even randomly sampled images achieving superior results. Such misaligned evaluation settings severely hinder the development of DD. Therefore, we propose DD-Ranking, a unified evaluation framework, along with new general evaluation metrics to uncover the true performance improvements achieved by different methods. By refocusing on the actual information enhancement of distilled datasets, DD-Ranking provides a more comprehensive and fair evaluation standard for future research advancements.
Synthetic Text Generation for Training Large Language Models via Gradient Matching
Feb 24, 2025Synthetic data has the potential to improve the performance, training efficiency, and privacy of real training examples. Nevertheless, existing approaches for synthetic text generation are mostly heuristics and cannot generate human-readable text without compromising the privacy of real data or provide performance guarantees for training Large Language Models (LLMs). In this work, we propose the first theoretically rigorous approach for generating synthetic human-readable text that guarantees the convergence and performance of LLMs during fine-tuning on a target task. To do so, we leverage Alternating Direction Method of Multipliers (ADMM) that iteratively optimizes the embeddings of synthetic examples to match the gradient of the target training or validation data, and maps them to a sequence of text tokens with low perplexity. In doing so, the generated synthetic text can guarantee convergence of the model to a close neighborhood of the solution obtained by fine-tuning on real data. Experiments on various classification tasks confirm the effectiveness of our proposed approach.
Verify when Uncertain: Beyond Self-Consistency in Black Box Hallucination Detection
Feb 20, 2025
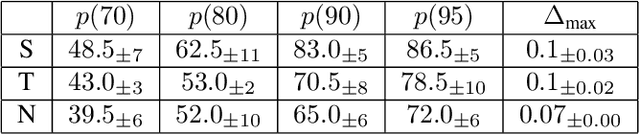
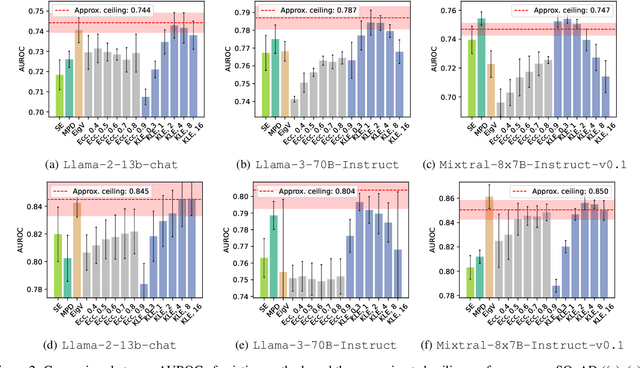
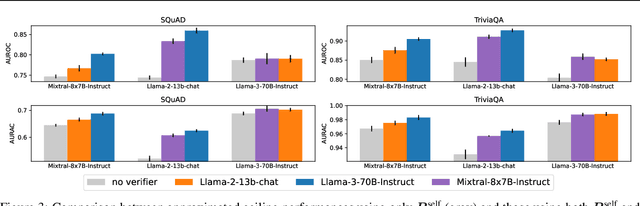
Large Language Models (LLMs) suffer from hallucination problems, which hinder their reliability in sensitive applications. In the black-box setting, several self-consistency-based techniques have been proposed for hallucination detection. We empirically study these techniques and show that they achieve performance close to that of a supervised (still black-box) oracle, suggesting little room for improvement within this paradigm. To address this limitation, we explore cross-model consistency checking between the target model and an additional verifier LLM. With this extra information, we observe improved oracle performance compared to purely self-consistency-based methods. We then propose a budget-friendly, two-stage detection algorithm that calls the verifier model only for a subset of cases. It dynamically switches between self-consistency and cross-consistency based on an uncertainty interval of the self-consistency classifier. We provide a geometric interpretation of consistency-based hallucination detection methods through the lens of kernel mean embeddings, offering deeper theoretical insights. Extensive experiments show that this approach maintains high detection performance while significantly reducing computational cost.