 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScholarly Wikidata: Population and Exploration of Conference Data in Wikidata using LLMs
Nov 13, 2024



Several initiatives have been undertaken to conceptually model the domain of scholarly data using ontologies and to create respective Knowledge Graphs. Yet, the full potential seems unleashed, as automated means for automatic population of said ontologies are lacking, and respective initiatives from the Semantic Web community are not necessarily connected: we propose to make scholarly data more sustainably accessible by leveraging Wikidata's infrastructure and automating its population in a sustainable manner through LLMs by tapping into unstructured sources like conference Web sites and proceedings texts as well as already existing structured conference datasets. While an initial analysis shows that Semantic Web conferences are only minimally represented in Wikidata, we argue that our methodology can help to populate, evolve and maintain scholarly data as a community within Wikidata. Our main contributions include (a) an analysis of ontologies for representing scholarly data to identify gaps and relevant entities/properties in Wikidata, (b) semi-automated extraction -- requiring (minimal) manual validation -- of conference metadata (e.g., acceptance rates, organizer roles, programme committee members, best paper awards, keynotes, and sponsors) from websites and proceedings texts using LLMs. Finally, we discuss (c) extensions to visualization tools in the Wikidata context for data exploration of the generated scholarly data. Our study focuses on data from 105 Semantic Web-related conferences and extends/adds more than 6000 entities in Wikidata. It is important to note that the method can be more generally applicable beyond Semantic Web-related conferences for enhancing Wikidata's utility as a comprehensive scholarly resource. Source Repository: https://github.com/scholarly-wikidata/ DOI: https://doi.org/10.5281/zenodo.10989709 License: Creative Commons CC0 (Data), MIT (Code)
Grid-Based Projection of Spatial Data into Knowledge Graphs
Nov 04, 2024



The Spatial Knowledge Graphs (SKG) are experiencing growing adoption as a means to model real-world entities, proving especially invaluable in domains like crisis management and urban planning. Considering that RDF specifications offer limited support for effectively managing spatial information, it's common practice to include text-based serializations of geometrical features, such as polygons and lines, as string literals in knowledge graphs. Consequently, Spatial Knowledge Graphs (SKGs) often rely on geo-enabled RDF Stores capable of parsing, interpreting, and indexing such serializations. In this paper, we leverage grid cells as the foundational element of SKGs and demonstrate how efficiently the spatial characteristics of real-world entities and their attributes can be encoded within knowledge graphs. Furthermore, we introduce a novel methodology for representing street networks in knowledge graphs, diverging from the conventional practice of individually capturing each street segment. Instead, our approach is based on tessellating the street network using grid cells and creating a simplified representation that could be utilized for various routing and navigation tasks, solely relying on RDF specifications.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020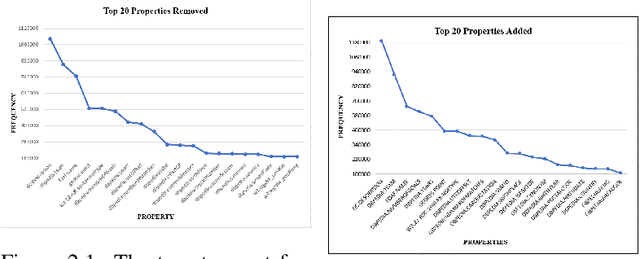
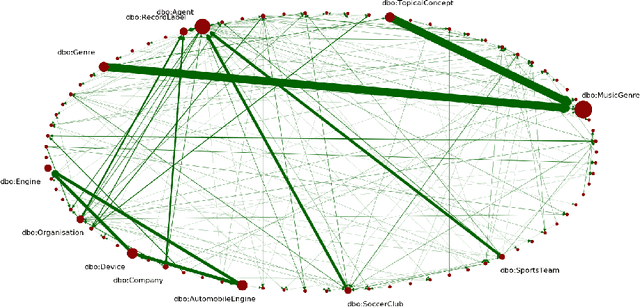

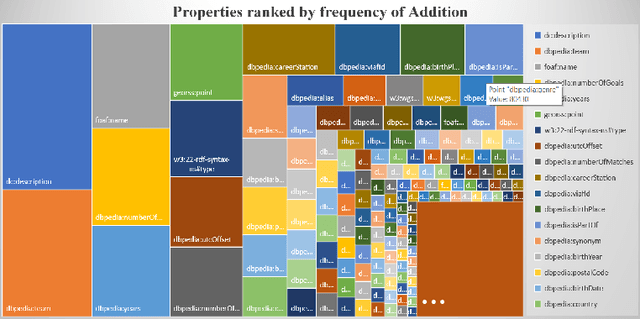
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.
Challenges of Linking Organizational Information in Open Government Data to Knowledge Graphs
Aug 14, 2020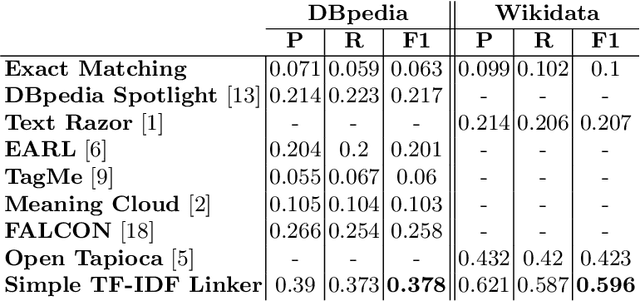
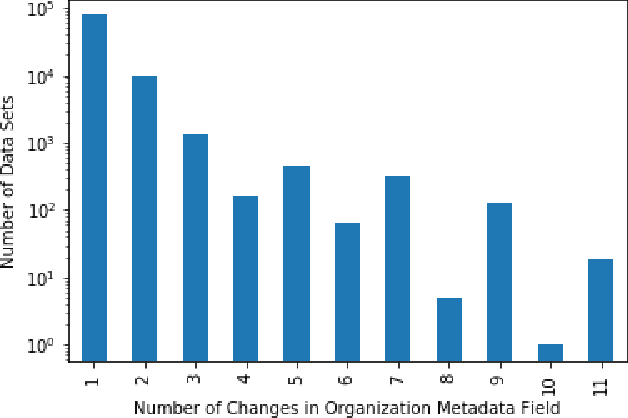
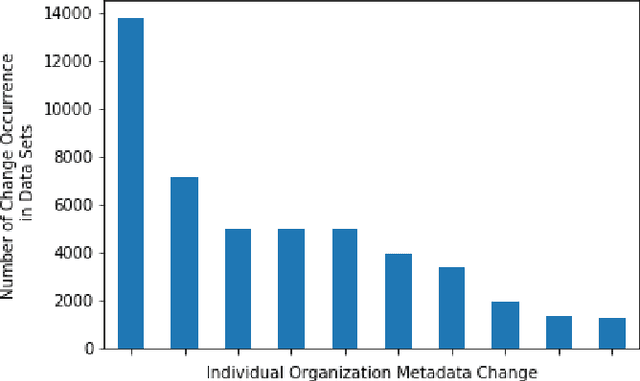
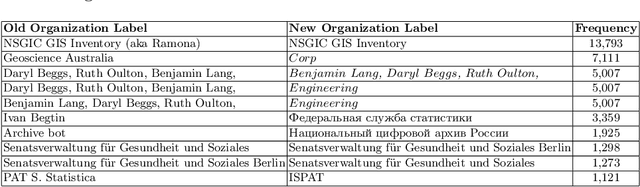
Open Government Data (OGD) is being published by various public administration organizations around the globe. Within the metadata of OGD data catalogs, the publishing organizations (1) are not uniquely and unambiguously identifiable and, even worse, (2) change over time, by public administration units being merged or restructured. In order to enable fine-grained analyses or searches on Open Government Data on the level of publishing organizations, linking those from OGD portals to publicly available knowledge graphs (KGs) such as Wikidata and DBpedia seems like an obvious solution. Still, as we show in this position paper, organization linking faces significant challenges, both in terms of available (portal) metadata and KGs in terms of data quality and completeness. We herein specifically highlight five main challenges, namely regarding (1) temporal changes in organizations and in the portal metadata, (2) lack of a base ontology for describing organizational structures and changes in public knowledge graphs, (3) metadata and KG data quality, (4) multilinguality, and (5) disambiguating public sector organizations. Based on available OGD portal metadata from the Open Data Portal Watch, we provide an in-depth analysis of these issues, make suggestions for concrete starting points on how to tackle them along with a call to the community to jointly work on these open challenges.
Knowledge Graphs
Mar 28, 2020
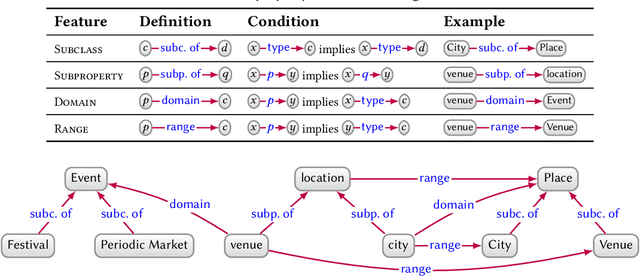
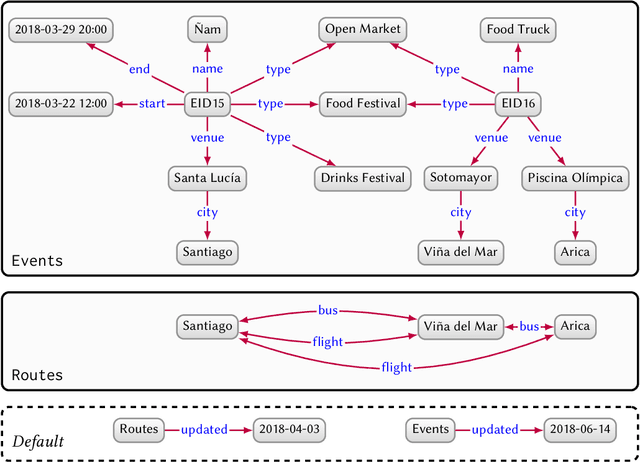
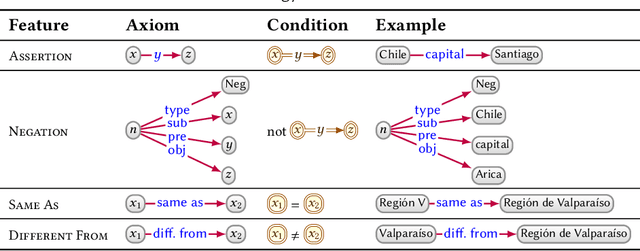
In this paper we provide a comprehensive introduction to knowledge graphs, which have recently garnered significant attention from both industry and academia in scenarios that require exploiting diverse, dynamic, large-scale collections of data. After a general introduction, we motivate and contrast various graph-based data models and query languages that are used for knowledge graphs. We discuss the roles of schema, identity, and context in knowledge graphs. We explain how knowledge can be represented and extracted using a combination of deductive and inductive techniques. We summarise methods for the creation, enrichment, quality assessment, refinement, and publication of knowledge graphs. We provide an overview of prominent open knowledge graphs and enterprise knowledge graphs, their applications, and how they use the aforementioned techniques. We conclude with high-level future research directions for knowledge graphs.
The SPECIAL-K Personal Data Processing Transparency and Compliance Platform
Jan 26, 2020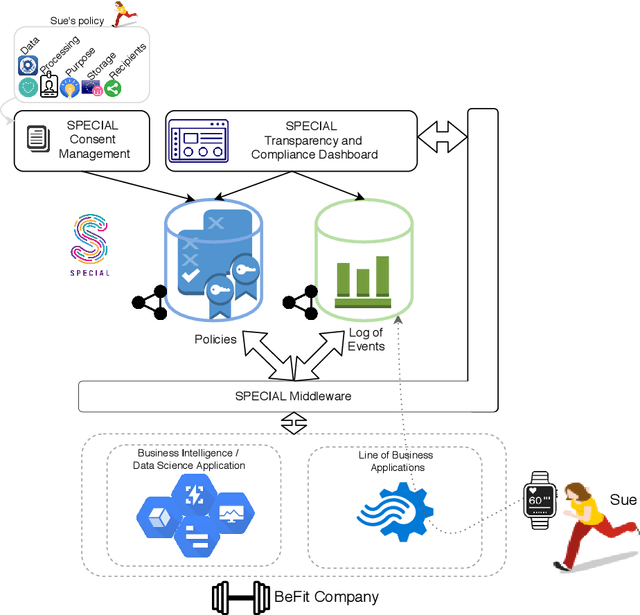
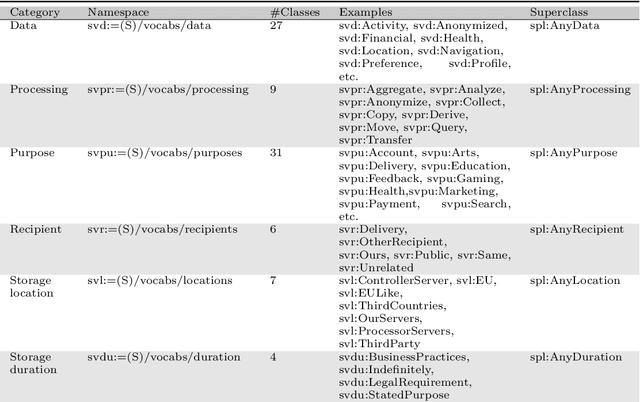
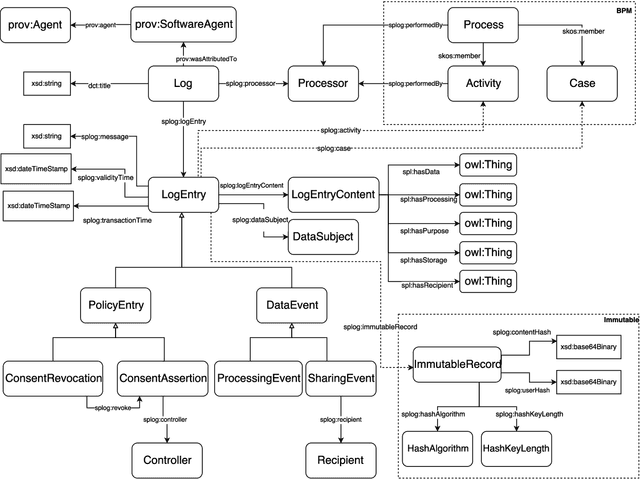

The European General Data Protection Regulation (GDPR) brings new challenges for companies, who must provide transparency with respect to personal data processing and sharing within and between organisations. Additionally companies need to demonstrate that their systems and business processes comply with usage constraints specified by data subjects. This paper first presents the Linked Data ontologies and vocabularies developed within the SPECIAL EU H2020 project, which can be used to represent data usage policies and data processing and sharing events, including the consent provided by the data subject and subsequent changes to or revocation of said consent. Following on from this, we propose a concrete transparency and compliance architecture, referred to as SPECIAL-K, that can automatically verify that data processing and sharing complies with the relevant usage control policies. Our evaluation, based on a new transparency and compliance benchmark, shows the efficiency and scalability of the system with increasing number of events and users, covering a wide range of real-world streaming and batch processing scenarios.
Message Passing for Complex Question Answering over Knowledge Graphs
Aug 19, 2019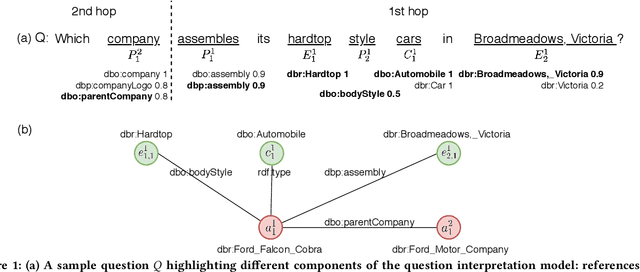
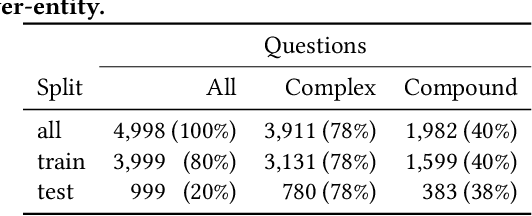
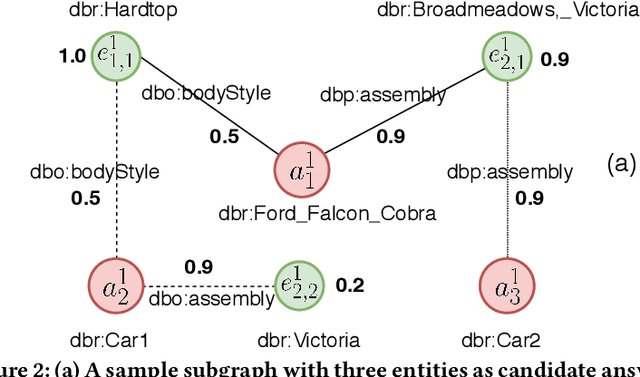
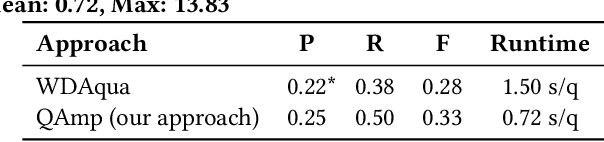
Question answering over knowledge graphs (KGQA) has evolved from simple single-fact questions to complex questions that require graph traversal and aggregation. We propose a novel approach for complex KGQA that uses unsupervised message passing, which propagates confidence scores obtained by parsing an input question and matching terms in the knowledge graph to a set of possible answers. First, we identify entity, relationship, and class names mentioned in a natural language question, and map these to their counterparts in the graph. Then, the confidence scores of these mappings propagate through the graph structure to locate the answer entities. Finally, these are aggregated depending on the identified question type. This approach can be efficiently implemented as a series of sparse matrix multiplications mimicking joins over small local subgraphs. Our evaluation results show that the proposed approach outperforms the state-of-the-art on the LC-QuAD benchmark. Moreover, we show that the performance of the approach depends only on the quality of the question interpretation results, i.e., given a correct relevance score distribution, our approach always produces a correct answer ranking. Our error analysis reveals correct answers missing from the benchmark dataset and inconsistencies in the DBpedia knowledge graph. Finally, we provide a comprehensive evaluation of the proposed approach accompanied with an ablation study and an error analysis, which showcase the pitfalls for each of the question answering components in more detail.
Measuring Semantic Coherence of a Conversation
Jun 17, 2018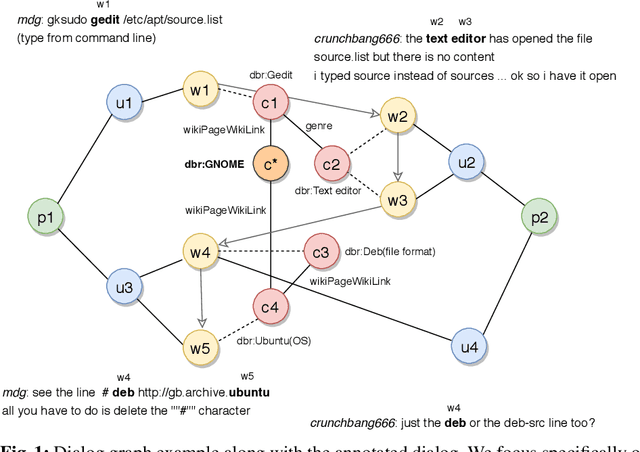
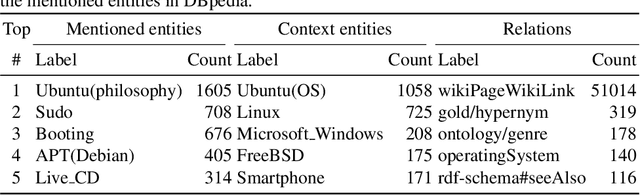

Conversational systems have become increasingly popular as a way for humans to interact with computers. To be able to provide intelligent responses, conversational systems must correctly model the structure and semantics of a conversation. We introduce the task of measuring semantic (in)coherence in a conversation with respect to background knowledge, which relies on the identification of semantic relations between concepts introduced during a conversation. We propose and evaluate graph-based and machine learning-based approaches for measuring semantic coherence using knowledge graphs, their vector space embeddings and word embedding models, as sources of background knowledge. We demonstrate how these approaches are able to uncover different coherence patterns in conversations on the Ubuntu Dialogue Corpus.
OWL: Yet to arrive on the Web of Data?
Feb 01, 2012
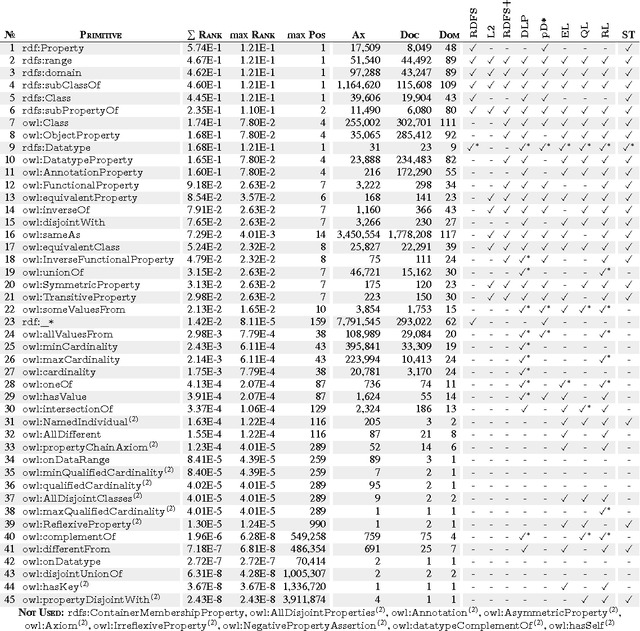
Seven years on from OWL becoming a W3C recommendation, and two years on from the more recent OWL 2 W3C recommendation, OWL has still experienced only patchy uptake on the Web. Although certain OWL features (like owl:sameAs) are very popular, other features of OWL are largely neglected by publishers in the Linked Data world. This may suggest that despite the promise of easy implementations and the proposal of tractable profiles suggested in OWL's second version, there is still no "right" standard fragment for the Linked Data community. In this paper, we (1) analyse uptake of OWL on the Web of Data, (2) gain insights into the OWL fragment that is actually used/usable on the Web, where we arrive at the conclusion that this fragment is likely to be a simplified profile based on OWL RL, (3) propose and discuss such a new fragment, which we call OWL LD (for Linked Data).
Embedding Non-Ground Logic Programs into Autoepistemic Logic for Knowledge Base Combination
Jun 11, 2010

In the context of the Semantic Web, several approaches to the combination of ontologies, given in terms of theories of classical first-order logic and rule bases, have been proposed. They either cast rules into classical logic or limit the interaction between rules and ontologies. Autoepistemic logic (AEL) is an attractive formalism which allows to overcome these limitations, by serving as a uniform host language to embed ontologies and nonmonotonic logic programs into it. For the latter, so far only the propositional setting has been considered. In this paper, we present three embeddings of normal and three embeddings of disjunctive non-ground logic programs under the stable model semantics into first-order AEL. While the embeddings all correspond with respect to objective ground atoms, differences arise when considering non-atomic formulas and combinations with first-order theories. We compare the embeddings with respect to stable expansions and autoepistemic consequences, considering the embeddings by themselves, as well as combinations with classical theories. Our results reveal differences and correspondences of the embeddings and provide useful guidance in the choice of a particular embedding for knowledge combination.