 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Content Moderation for German Newspaper Comments
May 27, 2025The increasing volume of online discussions requires advanced automatic content moderation to maintain responsible discourse. While hate speech detection on social media is well-studied, research on German-language newspaper forums remains limited. Existing studies often neglect platform-specific context, such as user history and article themes. This paper addresses this gap by developing and evaluating binary classification models for automatic content moderation in German newspaper forums, incorporating contextual information. Using LSTM, CNN, and ChatGPT-3.5 Turbo, and leveraging the One Million Posts Corpus from the Austrian newspaper Der Standard, we assess the impact of context-aware models. Results show that CNN and LSTM models benefit from contextual information and perform competitively with state-of-the-art approaches. In contrast, ChatGPT's zero-shot classification does not improve with added context and underperforms.
Building a Knowledge Graph of Distributed Ledger Technologies
Mar 29, 2023


Distributed ledger systems have become more prominent and successful in recent years, with a focus on blockchains and cryptocurrency. This has led to various misunderstandings about both the technology itself and its capabilities, as in many cases blockchain and cryptocurrency is used synonymously and other applications are often overlooked. Therefore, as a whole, the view of distributed ledger technology beyond blockchains and cryptocurrencies is very limited. Existing vocabularies and ontologies often focus on single aspects of the technology, or in some cases even just on one product. This potentially leads to other types of distributed ledgers and their possible use cases being neglected. In this paper, we present a knowledge graph and an ontology for distributed ledger technologies, which includes security considerations to model aspects such as threats and vulnerabilities, application domains, as well as relevant standards and regulations. Such a knowledge graph improves the overall understanding of distributed ledgers, reveals their strengths, and supports the work of security personnel, i.e. analysts and system architects. We discuss potential uses and follow semantic web best practices to evaluate and publish the ontology and knowledge graph.
Challenges of Linking Organizational Information in Open Government Data to Knowledge Graphs
Aug 14, 2020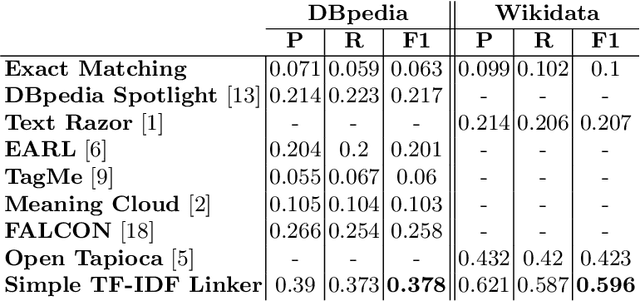
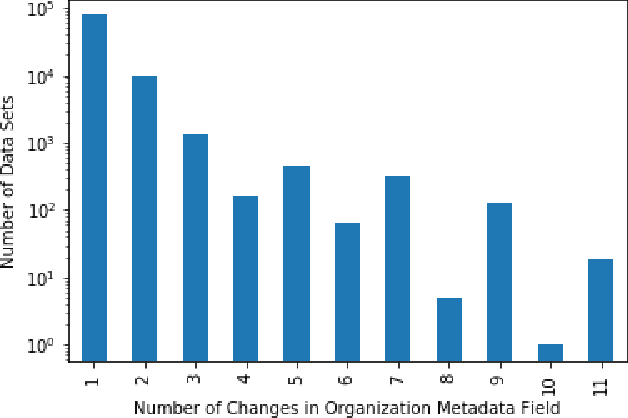
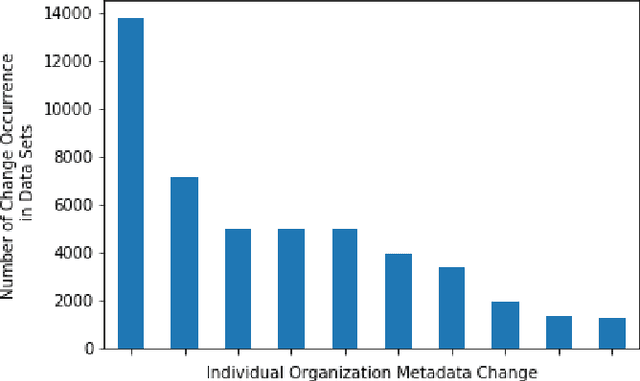
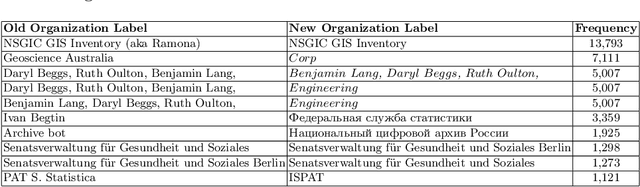
Open Government Data (OGD) is being published by various public administration organizations around the globe. Within the metadata of OGD data catalogs, the publishing organizations (1) are not uniquely and unambiguously identifiable and, even worse, (2) change over time, by public administration units being merged or restructured. In order to enable fine-grained analyses or searches on Open Government Data on the level of publishing organizations, linking those from OGD portals to publicly available knowledge graphs (KGs) such as Wikidata and DBpedia seems like an obvious solution. Still, as we show in this position paper, organization linking faces significant challenges, both in terms of available (portal) metadata and KGs in terms of data quality and completeness. We herein specifically highlight five main challenges, namely regarding (1) temporal changes in organizations and in the portal metadata, (2) lack of a base ontology for describing organizational structures and changes in public knowledge graphs, (3) metadata and KG data quality, (4) multilinguality, and (5) disambiguating public sector organizations. Based on available OGD portal metadata from the Open Data Portal Watch, we provide an in-depth analysis of these issues, make suggestions for concrete starting points on how to tackle them along with a call to the community to jointly work on these open challenges.
Knowledge Graphs
Mar 28, 2020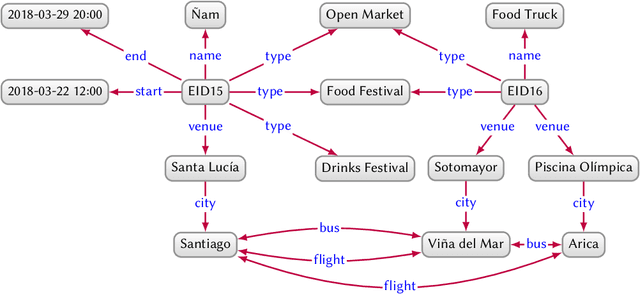
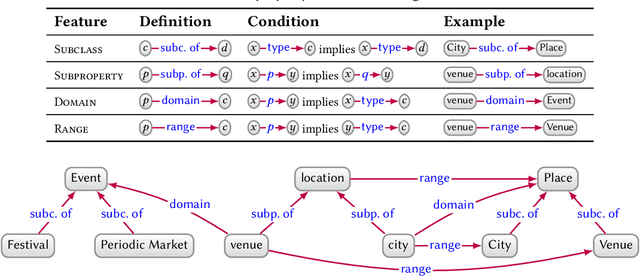
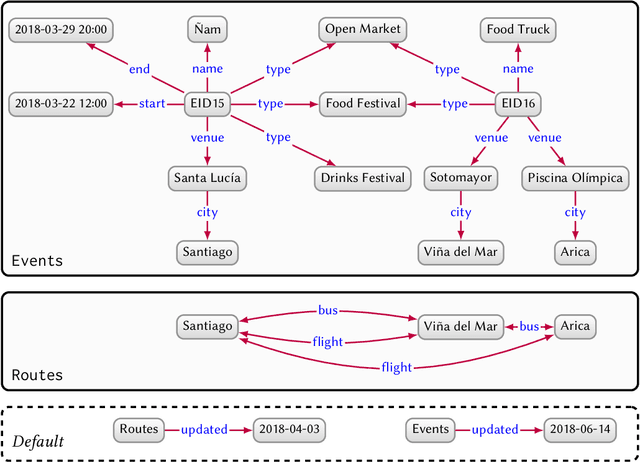
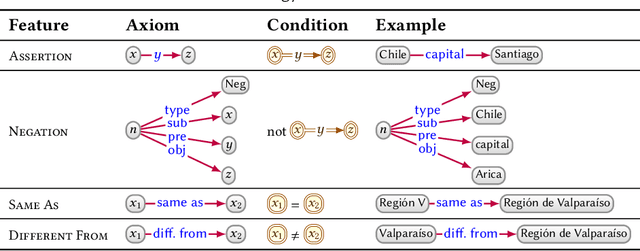
In this paper we provide a comprehensive introduction to knowledge graphs, which have recently garnered significant attention from both industry and academia in scenarios that require exploiting diverse, dynamic, large-scale collections of data. After a general introduction, we motivate and contrast various graph-based data models and query languages that are used for knowledge graphs. We discuss the roles of schema, identity, and context in knowledge graphs. We explain how knowledge can be represented and extracted using a combination of deductive and inductive techniques. We summarise methods for the creation, enrichment, quality assessment, refinement, and publication of knowledge graphs. We provide an overview of prominent open knowledge graphs and enterprise knowledge graphs, their applications, and how they use the aforementioned techniques. We conclude with high-level future research directions for knowledge graphs.