 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixes That Fail: Self-Defeating Improvements in Machine-Learning Systems
Mar 22, 2021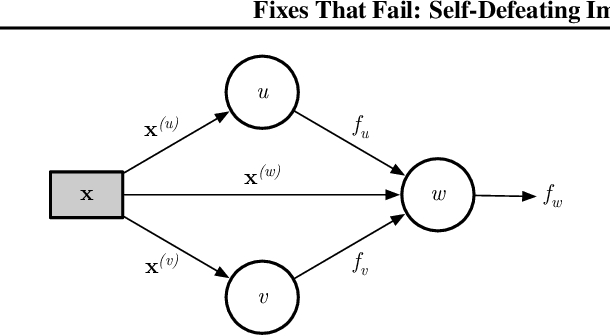
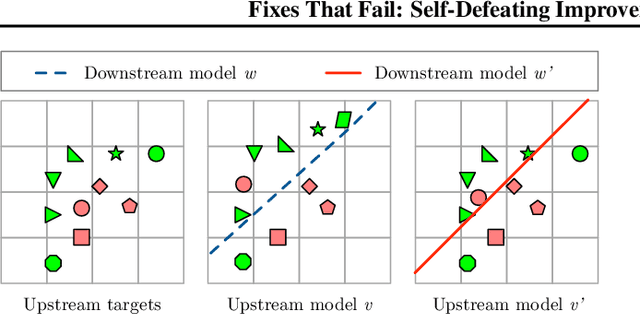
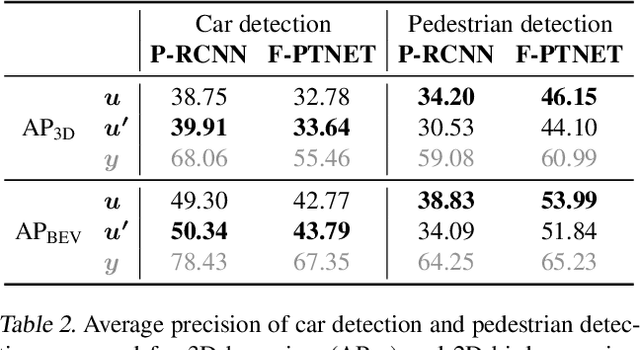
Machine-learning systems such as self-driving cars or virtual assistants are composed of a large number of machine-learning models that recognize image content, transcribe speech, analyze natural language, infer preferences, rank options, etc. These systems can be represented as directed acyclic graphs in which each vertex is a model, and models feed each other information over the edges. Oftentimes, the models are developed and trained independently, which raises an obvious concern: Can improving a machine-learning model make the overall system worse? We answer this question affirmatively by showing that improving a model can deteriorate the performance of downstream models, even after those downstream models are retrained. Such self-defeating improvements are the result of entanglement between the models. We identify different types of entanglement and demonstrate via simple experiments how they can produce self-defeating improvements. We also show that self-defeating improvements emerge in a realistic stereo-based object detection system.
Measuring Data Leakage in Machine-Learning Models with Fisher Information
Feb 23, 2021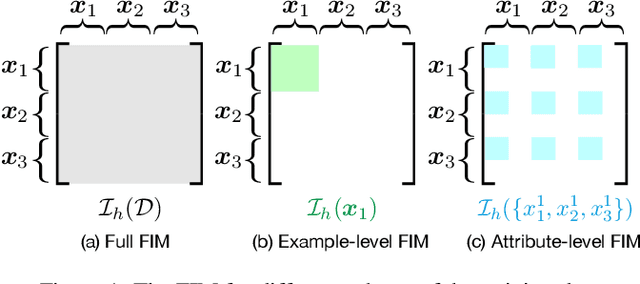
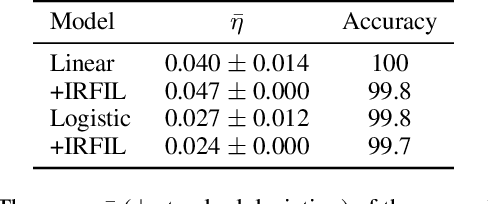
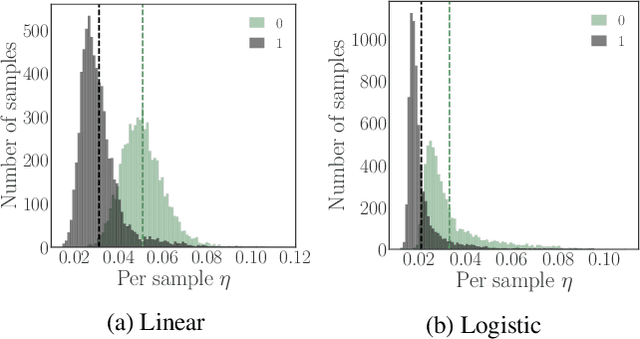

Machine-learning models contain information about the data they were trained on. This information leaks either through the model itself or through predictions made by the model. Consequently, when the training data contains sensitive attributes, assessing the amount of information leakage is paramount. We propose a method to quantify this leakage using the Fisher information of the model about the data. Unlike the worst-case a priori guarantees of differential privacy, Fisher information loss measures leakage with respect to specific examples, attributes, or sub-populations within the dataset. We motivate Fisher information loss through the Cram\'{e}r-Rao bound and delineate the implied threat model. We provide efficient methods to compute Fisher information loss for output-perturbed generalized linear models. Finally, we empirically validate Fisher information loss as a useful measure of information leakage.
Data Appraisal Without Data Sharing
Dec 11, 2020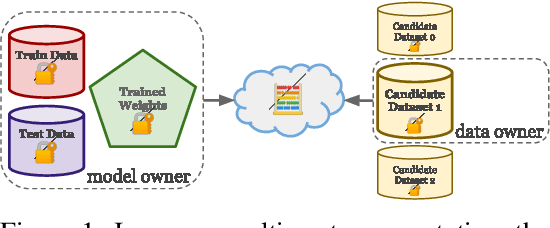

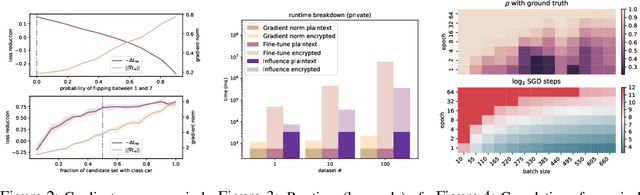
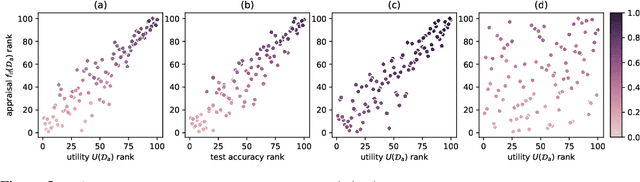
One of the most effective approaches to improving the performance of a machine-learning model is to acquire additional training data. To do so, a model owner may seek to acquire relevant training data from a data owner. Before procuring the data, the model owner needs to appraise the data. However, the data owner generally does not want to share the data until after an agreement is reached. The resulting Catch-22 prevents efficient data markets from forming. To address this problem, we develop data appraisal methods that do not require data sharing by using secure multi-party computation. Specifically, we study methods that: (1) compute parameter gradient norms, (2) perform model fine-tuning, and (3) compute influence functions. Our experiments show that influence functions provide an appealing trade-off between high-quality appraisal and required computation.
Differentiable Weighted Finite-State Transducers
Oct 02, 2020

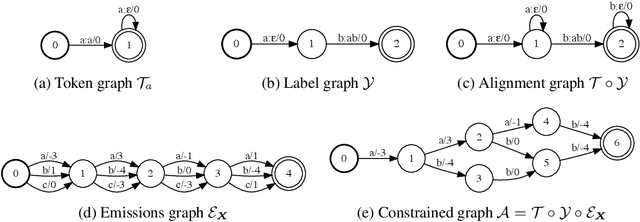
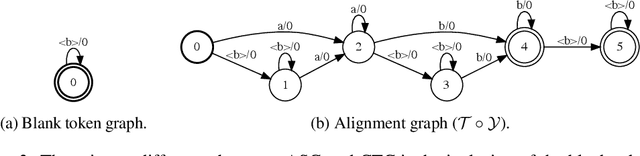
We introduce a framework for automatic differentiation with weighted finite-state transducers (WFSTs) allowing them to be used dynamically at training time. Through the separation of graphs from operations on graphs, this framework enables the exploration of new structured loss functions which in turn eases the encoding of prior knowledge into learning algorithms. We show how the framework can combine pruning and back-off in transition models with various sequence-level loss functions. We also show how to learn over the latent decomposition of phrases into word pieces. Finally, to demonstrate that WFSTs can be used in the interior of a deep neural network, we propose a convolutional WFST layer which maps lower-level representations to higher-level representations and can be used as a drop-in replacement for a traditional convolution. We validate these algorithms with experiments in handwriting recognition and speech recognition.
The Trade-Offs of Private Prediction
Jul 09, 2020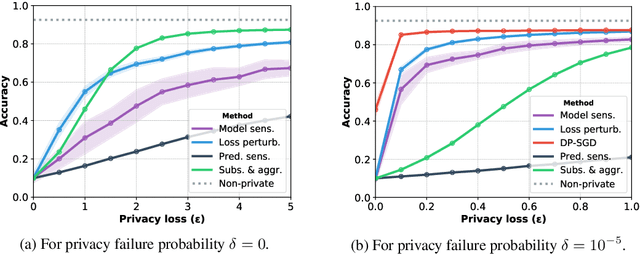
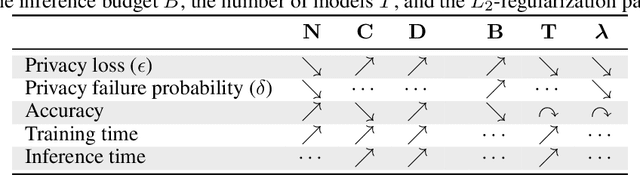
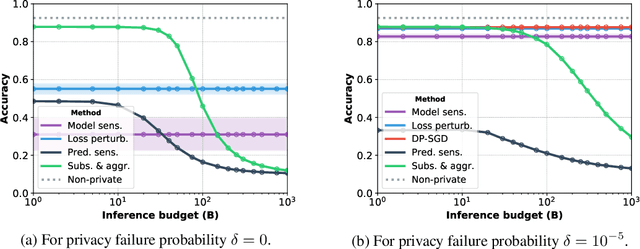
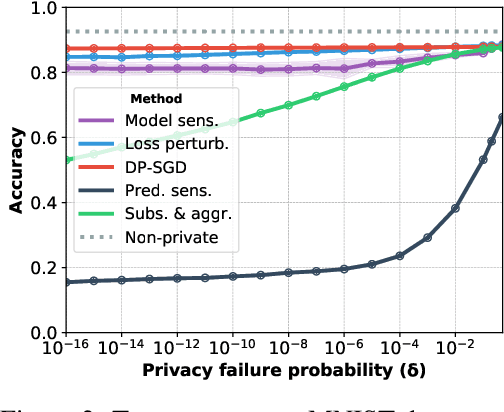
Machine learning models leak information about their training data every time they reveal a prediction. This is problematic when the training data needs to remain private. Private prediction methods limit how much information about the training data is leaked by each prediction. Private prediction can also be achieved using models that are trained by private training methods. In private prediction, both private training and private prediction methods exhibit trade-offs between privacy, privacy failure probability, amount of training data, and inference budget. Although these trade-offs are theoretically well-understood, they have hardly been studied empirically. This paper presents the first empirical study into the trade-offs of private prediction. Our study sheds light on which methods are best suited for which learning setting. Perhaps surprisingly, we find private training methods outperform private prediction methods in a wide range of private prediction settings.
Massively Multilingual ASR: 50 Languages, 1 Model, 1 Billion Parameters
Jul 08, 2020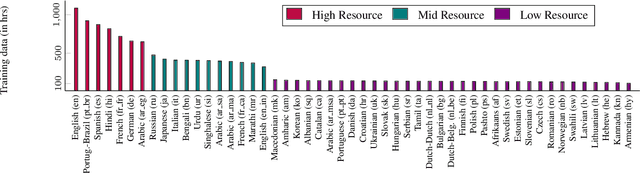
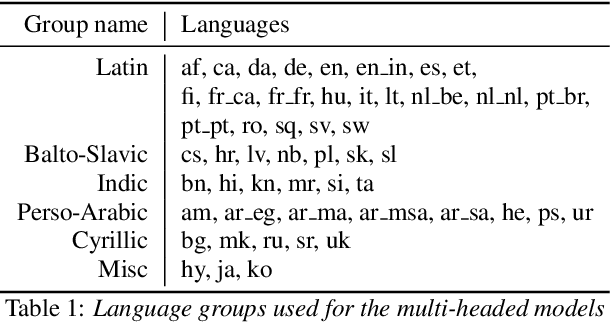
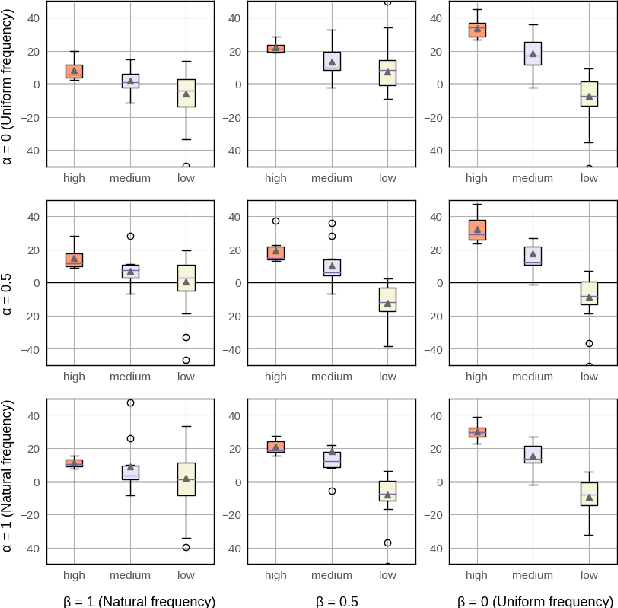
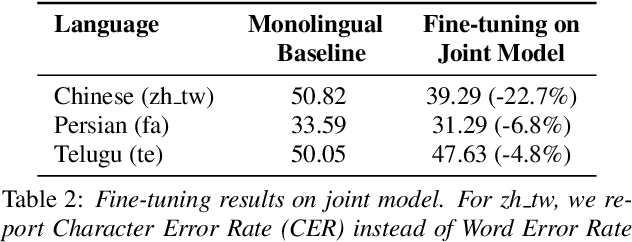
We study training a single acoustic model for multiple languages with the aim of improving automatic speech recognition (ASR) performance on low-resource languages, and over-all simplifying deployment of ASR systems that support diverse languages. We perform an extensive benchmark on 51 languages, with varying amount of training data by language(from 100 hours to 1100 hours). We compare three variants of multilingual training from a single joint model without knowing the input language, to using this information, to multiple heads (one per language cluster). We show that multilingual training of ASR models on several languages can improve recognition performance, in particular, on low resource languages. We see 20.9%, 23% and 28.8% average WER relative reduction compared to monolingual baselines on joint model, joint model with language input and multi head model respectively. To our knowledge, this is the first work studying multilingual ASR at massive scale, with more than 50 languages and more than 16,000 hours of audio across them.
Iterative Pseudo-Labeling for Speech Recognition
May 19, 2020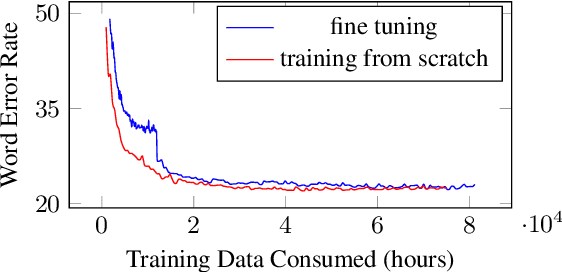
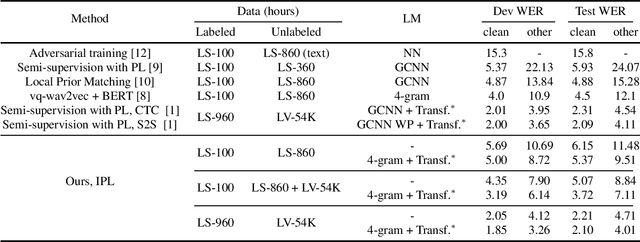
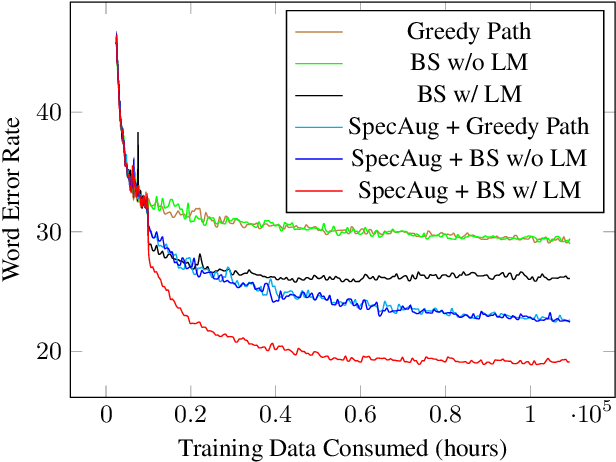

Pseudo-labeling has recently shown promise in end-to-end automatic speech recognition (ASR). We study Iterative Pseudo-Labeling (IPL), a semi-supervised algorithm which efficiently performs multiple iterations of pseudo-labeling on unlabeled data as the acoustic model evolves. In particular, IPL fine-tunes an existing model at each iteration using both labeled data and a subset of unlabeled data. We study the main components of IPL: decoding with a language model and data augmentation. We then demonstrate the effectiveness of IPL by achieving state-of-the-art word-error rate on the Librispeech test sets in both standard and low-resource setting. We also study the effect of language models trained on different corpora to show IPL can effectively utilize additional text. Finally, we release a new large in-domain text corpus which does not overlap with the Librispeech training transcriptions to foster research in low-resource, semi-supervised ASR
Semi-Supervised Speech Recognition via Local Prior Matching
Feb 24, 2020
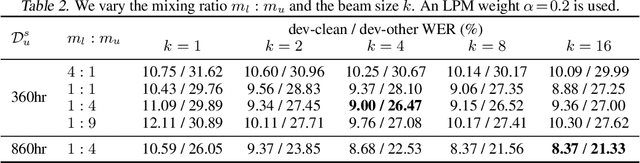
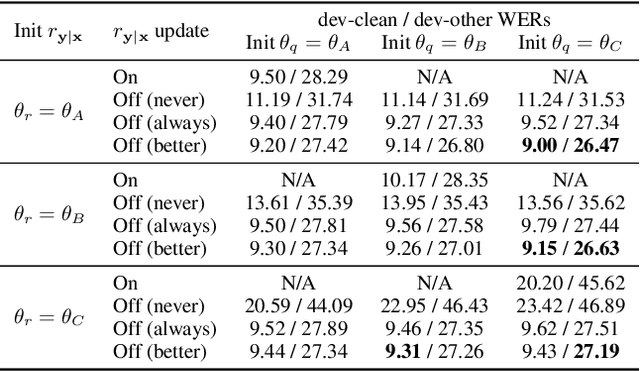
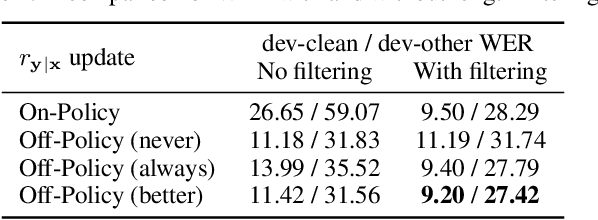
For sequence transduction tasks like speech recognition, a strong structured prior model encodes rich information about the target space, implicitly ruling out invalid sequences by assigning them low probability. In this work, we propose local prior matching (LPM), a semi-supervised objective that distills knowledge from a strong prior (e.g. a language model) to provide learning signal to a discriminative model trained on unlabeled speech. We demonstrate that LPM is theoretically well-motivated, simple to implement, and superior to existing knowledge distillation techniques under comparable settings. Starting from a baseline trained on 100 hours of labeled speech, with an additional 360 hours of unlabeled data, LPM recovers 54% and 73% of the word error rate on clean and noisy test sets relative to a fully supervised model on the same data.
Scaling Up Online Speech Recognition Using ConvNets
Jan 27, 2020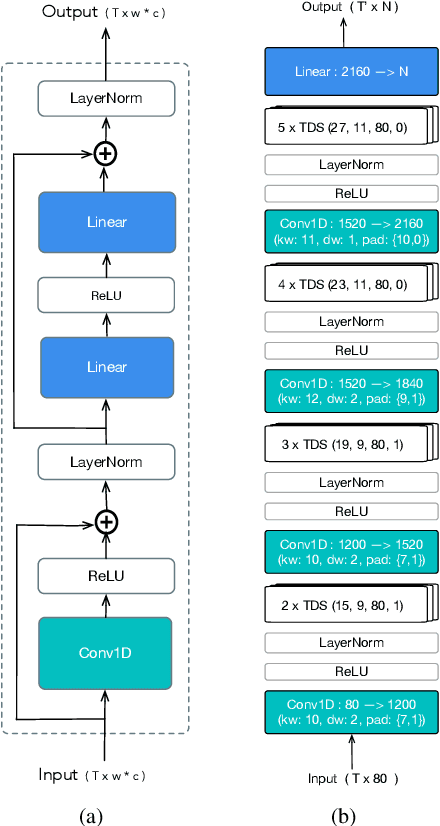
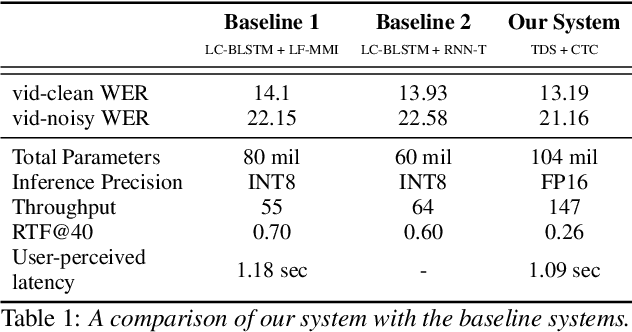

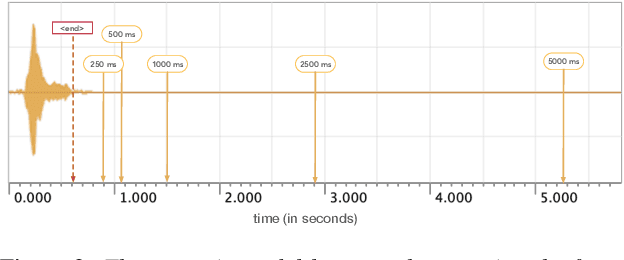
We design an online end-to-end speech recognition system based on Time-Depth Separable (TDS) convolutions and Connectionist Temporal Classification (CTC). We improve the core TDS architecture in order to limit the future context and hence reduce latency while maintaining accuracy. The system has almost three times the throughput of a well tuned hybrid ASR baseline while also having lower latency and a better word error rate. Also important to the efficiency of the recognizer is our highly optimized beam search decoder. To show the impact of our design choices, we analyze throughput, latency, accuracy, and discuss how these metrics can be tuned based on the user requirements.
Secure multiparty computations in floating-point arithmetic
Jan 09, 2020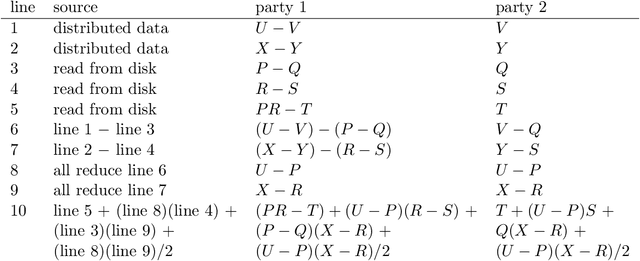
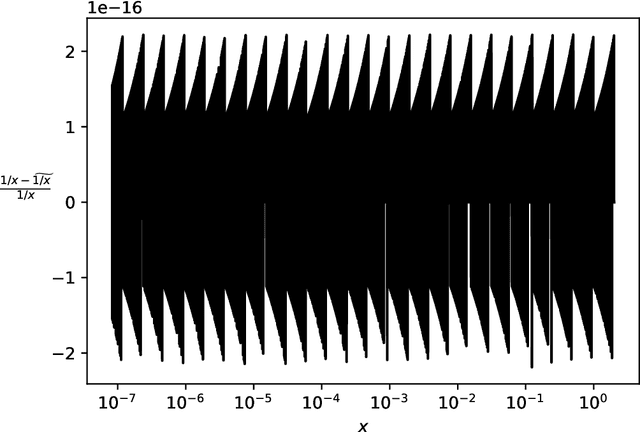
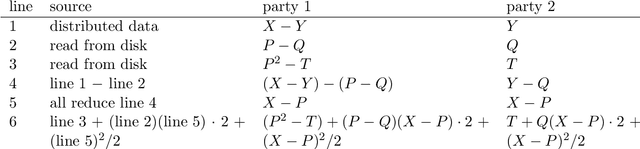
Secure multiparty computations enable the distribution of so-called shares of sensitive data to multiple parties such that the multiple parties can effectively process the data while being unable to glean much information about the data (at least not without collusion among all parties to put back together all the shares). Thus, the parties may conspire to send all their processed results to a trusted third party (perhaps the data provider) at the conclusion of the computations, with only the trusted third party being able to view the final results. Secure multiparty computations for privacy-preserving machine-learning turn out to be possible using solely standard floating-point arithmetic, at least with a carefully controlled leakage of information less than the loss of accuracy due to roundoff, all backed by rigorous mathematical proofs of worst-case bounds on information loss and numerical stability in finite-precision arithmetic. Numerical examples illustrate the high performance attained on commodity off-the-shelf hardware for generalized linear models, including ordinary linear least-squares regression, binary and multinomial logistic regression, probit regression, and Poisson regression.