 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Adversarial Training with Transferable Adversarial Examples
Dec 27, 2019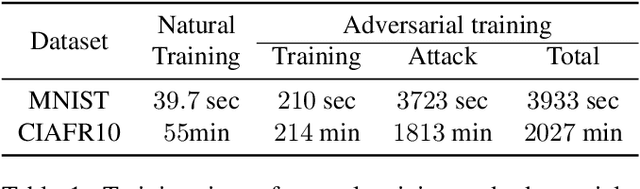
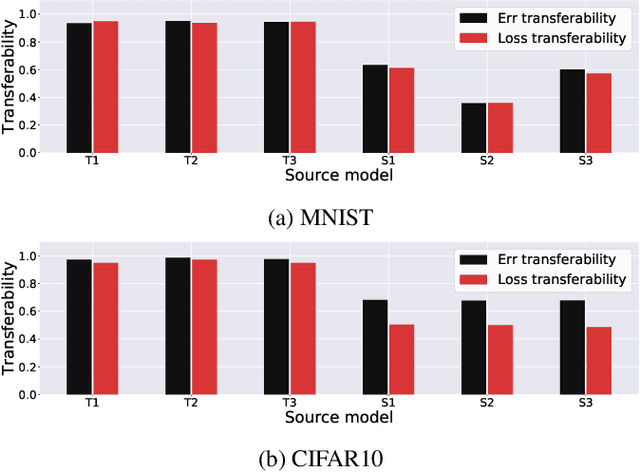
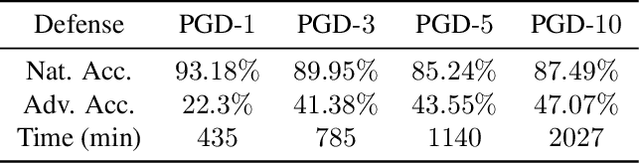
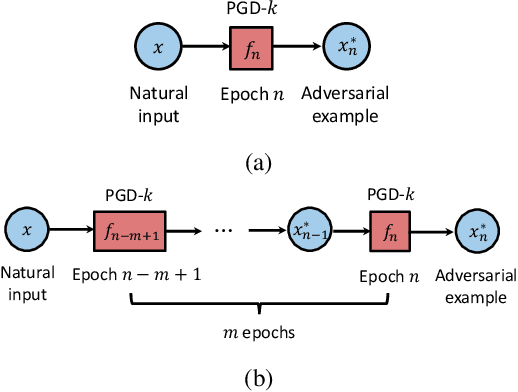
Adversarial training is an effective defense method to protect classification models against adversarial attacks. However, one limitation of this approach is that it can require orders of magnitude additional training time due to high cost of generating strong adversarial examples during training. In this paper, we first show that there is high transferability between models from neighboring epochs in the same training process, i.e., adversarial examples from one epoch continue to be adversarial in subsequent epochs. Leveraging this property, we propose a novel method, Adversarial Training with Transferable Adversarial Examples (ATTA), that can enhance the robustness of trained models and greatly improve the training efficiency by accumulating adversarial perturbations through epochs. Compared to state-of-the-art adversarial training methods, ATTA enhances adversarial accuracy by up to 7.2% on CIFAR10 and requires 12~14x less training time on MNIST and CIFAR10 datasets with comparable model robustness.
Can Attention Masks Improve Adversarial Robustness?
Dec 21, 2019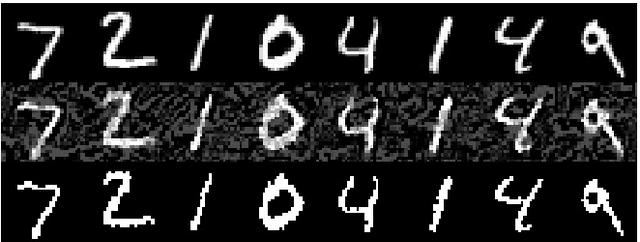


Deep Neural Networks (DNNs) are known to be susceptible to adversarial examples. Adversarial examples are maliciously crafted inputs that are designed to fool a model, but appear normal to human beings. Recent work has shown that pixel discretization can be used to make classifiers for MNIST highly robust to adversarial examples. However, pixel discretization fails to provide significant protection on more complex datasets. In this paper, we take the first step towards reconciling these contrary findings. Focusing on the observation that discrete pixelization in MNIST makes the background completely black and foreground completely white, we hypothesize that the important property for increasing robustness is the elimination of image background using attention masks before classifying an object. To examine this hypothesis, we create foreground attention masks for two different datasets, GTSRB and MS-COCO. Our initial results suggest that using attention mask leads to improved robustness. On the adversarially trained classifiers, we see an adversarial robustness increase of over 20% on MS-COCO.
Transferable Adversarial Robustness using Adversarially Trained Autoencoders
Sep 12, 2019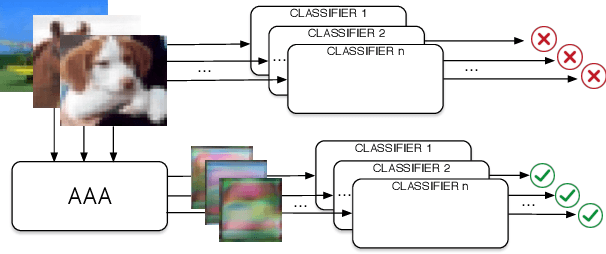
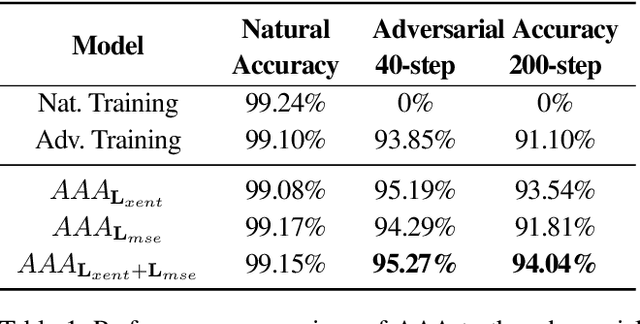
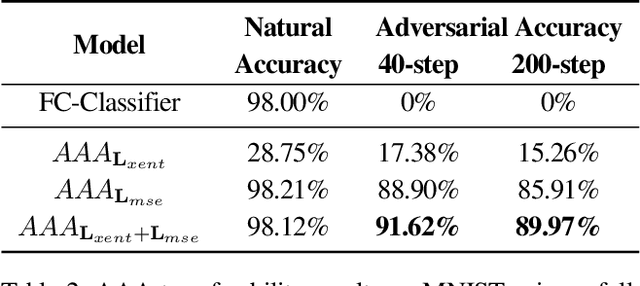
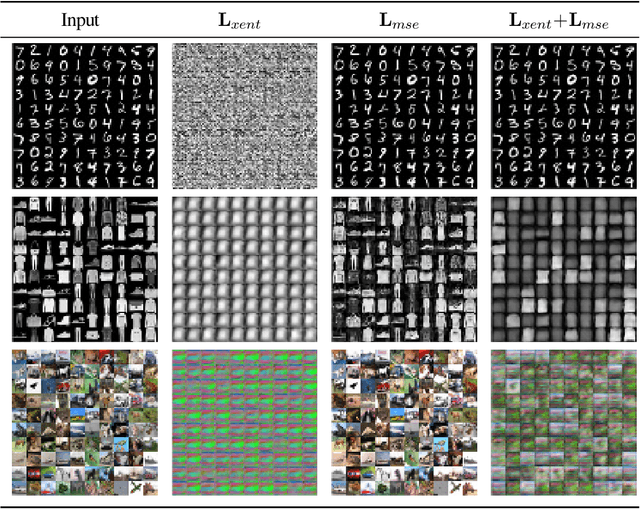
Machine learning has proven to be an extremely useful tool for solving complex problems in many application domains. This prevalence makes it an attractive target for malicious actors. Adversarial machine learning is a well-studied field of research in which an adversary seeks to cause predicable errors in a machine learning algorithm through careful manipulation of the input. In response, numerous techniques have been proposed to harden machine learning algorithms and mitigate the effect of adversarial attacks. Of these techniques, adversarial training, which augments the training data with adversarial inputs, has proven to be an effective defensive technique. However, adversarial training is computationally expensive and the improvements in adversarial performance are limited to a single model. In this paper, we propose Adversarially-Trained Autoencoder Augmentation, the first transferable adversarial defense that is robust to certain adaptive adversaries. We disentangle adversarial robustness from the classification pipeline by adversarially training an autoencoder with respect to the classification loss. We show that our approach achieves comparable results to state-of-the-art adversarially trained models on the MNIST, Fashion-MNIST, and CIFAR-10 datasets. Furthermore, we can transfer our approach to other vulnerable models and improve their adversarial performance without additional training. Finally, we combine our defense with ensemble methods and parallelize adversarial training across multiple vulnerable pre-trained models. In a single adversarial training session, the autoencoder can achieve adversarial performance on the vulnerable models that is comparable or better than standard adversarial training.
Robust Classification using Robust Feature Augmentation
May 31, 2019
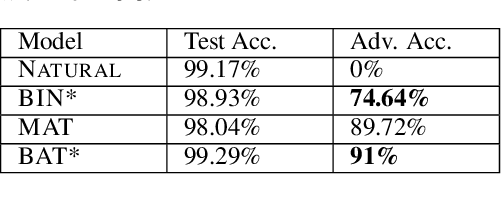
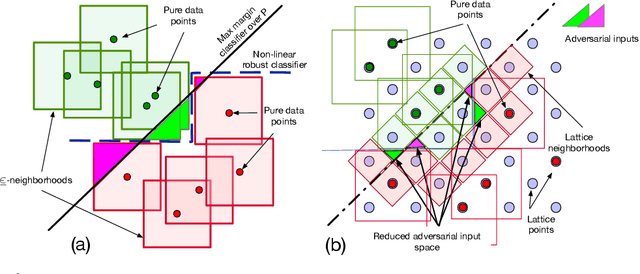

Existing deep neural networks, say for image classification, have been shown to be vulnerable to adversarial images that can cause a DNN misclassification, without any perceptible change to an image. In this work, we propose shock absorbing robust features such as binarization, e.g., rounding, and group extraction, e.g., color or shape, to augment the classification pipeline, resulting in more robust classifiers. Experimentally, we show that augmenting ML models with these techniques leads to improved overall robustness on adversarial inputs as well as significant improvements in training time. On the MNIST dataset, we achieved 14x speedup in training time to obtain 90% adversarial accuracy com-pared to the state-of-the-art adversarial training method of Madry et al., as well as retained higher adversarial accuracy over a broader range of attacks. We also find robustness improvements on traffic sign classification using robust feature augmentation. Finally, we give theoretical insights for why one can expect robust feature augmentation to reduce adversarial input space
Analyzing the Interpretability Robustness of Self-Explaining Models
May 27, 2019



Recently, interpretable models called self-explaining models (SEMs) have been proposed with the goal of providing interpretability robustness. We evaluate the interpretability robustness of SEMs and show that explanations provided by SEMs as currently proposed are not robust to adversarial inputs. Specifically, we successfully created adversarial inputs that do not change the model outputs but cause significant changes in the explanations. We find that even though current SEMs use stable co-efficients for mapping explanations to output labels, they do not consider the robustness of the first stage of the model that creates interpretable basis concepts from the input, leading to non-robust explanations. Our work makes a case for future work to start examining how to generate interpretable basis concepts in a robust way.
Designing Adversarially Resilient Classifiers using Resilient Feature Engineering
Dec 17, 2018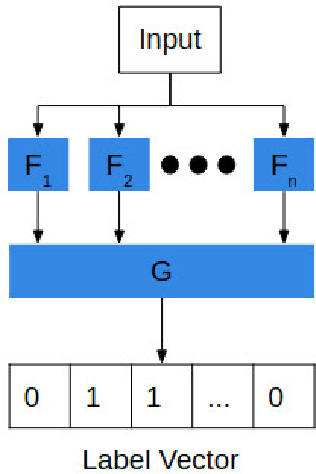
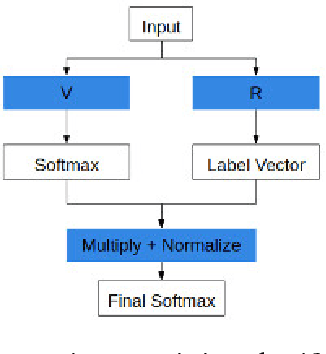
We provide a methodology, resilient feature engineering, for creating adversarially resilient classifiers. According to existing work, adversarial attacks identify weakly correlated or non-predictive features learned by the classifier during training and design the adversarial noise to utilize these features. Therefore, highly predictive features should be used first during classification in order to determine the set of possible output labels. Our methodology focuses the problem of designing resilient classifiers into a problem of designing resilient feature extractors for these highly predictive features. We provide two theorems, which support our methodology. The Serial Composition Resilience and Parallel Composition Resilience theorems show that the output of adversarially resilient feature extractors can be combined to create an equally resilient classifier. Based on our theoretical results, we outline the design of an adversarially resilient classifier.
Physical Adversarial Examples for Object Detectors
Oct 05, 2018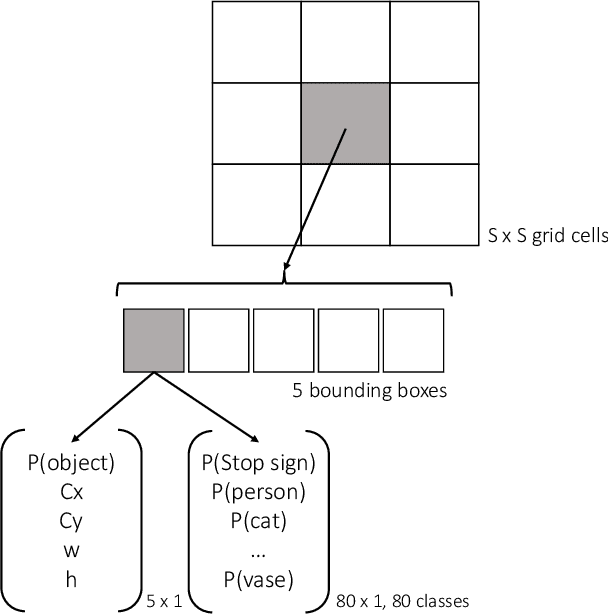
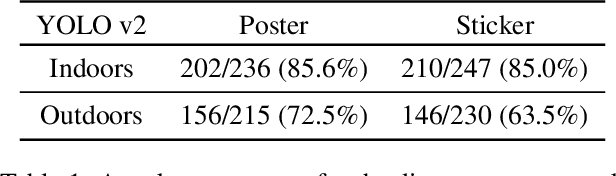

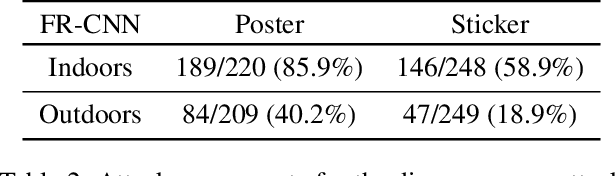
Deep neural networks (DNNs) are vulnerable to adversarial examples-maliciously crafted inputs that cause DNNs to make incorrect predictions. Recent work has shown that these attacks generalize to the physical domain, to create perturbations on physical objects that fool image classifiers under a variety of real-world conditions. Such attacks pose a risk to deep learning models used in safety-critical cyber-physical systems. In this work, we extend physical attacks to more challenging object detection models, a broader class of deep learning algorithms widely used to detect and label multiple objects within a scene. Improving upon a previous physical attack on image classifiers, we create perturbed physical objects that are either ignored or mislabeled by object detection models. We implement a Disappearance Attack, in which we cause a Stop sign to "disappear" according to the detector-either by covering thesign with an adversarial Stop sign poster, or by adding adversarial stickers onto the sign. In a video recorded in a controlled lab environment, the state-of-the-art YOLOv2 detector failed to recognize these adversarial Stop signs in over 85% of the video frames. In an outdoor experiment, YOLO was fooled by the poster and sticker attacks in 72.5% and 63.5% of the video frames respectively. We also use Faster R-CNN, a different object detection model, to demonstrate the transferability of our adversarial perturbations. The created poster perturbation is able to fool Faster R-CNN in 85.9% of the video frames in a controlled lab environment, and 40.2% of the video frames in an outdoor environment. Finally, we present preliminary results with a new Creation Attack, where in innocuous physical stickers fool a model into detecting nonexistent objects.
Note on Attacking Object Detectors with Adversarial Stickers
Jul 23, 2018


Deep learning has proven to be a powerful tool for computer vision and has seen widespread adoption for numerous tasks. However, deep learning algorithms are known to be vulnerable to adversarial examples. These adversarial inputs are created such that, when provided to a deep learning algorithm, they are very likely to be mislabeled. This can be problematic when deep learning is used to assist in safety critical decisions. Recent research has shown that classifiers can be attacked by physical adversarial examples under various physical conditions. Given the fact that state-of-the-art objection detection algorithms are harder to be fooled by the same set of adversarial examples, here we show that these detectors can also be attacked by physical adversarial examples. In this note, we briefly show both static and dynamic test results. We design an algorithm that produces physical adversarial inputs, which can fool the YOLO object detector and can also attack Faster-RCNN with relatively high success rate based on transferability. Furthermore, our algorithm can compress the size of the adversarial inputs to stickers that, when attached to the targeted object, result in the detector either mislabeling or not detecting the object a high percentage of the time. This note provides a small set of results. Our upcoming paper will contain a thorough evaluation on other object detectors, and will present the algorithm.
Robust Physical-World Attacks on Deep Learning Models
Apr 10, 2018

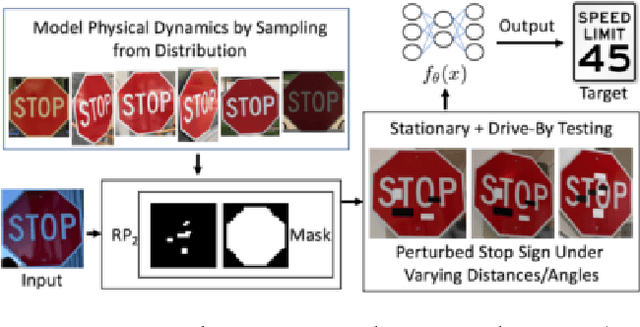
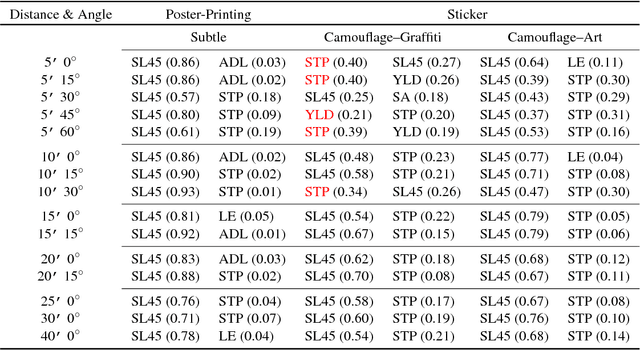
Recent studies show that the state-of-the-art deep neural networks (DNNs) are vulnerable to adversarial examples, resulting from small-magnitude perturbations added to the input. Given that that emerging physical systems are using DNNs in safety-critical situations, adversarial examples could mislead these systems and cause dangerous situations.Therefore, understanding adversarial examples in the physical world is an important step towards developing resilient learning algorithms. We propose a general attack algorithm,Robust Physical Perturbations (RP2), to generate robust visual adversarial perturbations under different physical conditions. Using the real-world case of road sign classification, we show that adversarial examples generated using RP2 achieve high targeted misclassification rates against standard-architecture road sign classifiers in the physical world under various environmental conditions, including viewpoints. Due to the current lack of a standardized testing method, we propose a two-stage evaluation methodology for robust physical adversarial examples consisting of lab and field tests. Using this methodology, we evaluate the efficacy of physical adversarial manipulations on real objects. Witha perturbation in the form of only black and white stickers,we attack a real stop sign, causing targeted misclassification in 100% of the images obtained in lab settings, and in 84.8%of the captured video frames obtained on a moving vehicle(field test) for the target classifier.