 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaking off the Rose-Tinted Glasses: A Critical Look at Adversarial ML Through the Lens of Evasion Attacks
Oct 15, 2024



The vulnerability of machine learning models in adversarial scenarios has garnered significant interest in the academic community over the past decade, resulting in a myriad of attacks and defenses. However, while the community appears to be overtly successful in devising new attacks across new contexts, the development of defenses has stalled. After a decade of research, we appear no closer to securing AI applications beyond additional training. Despite a lack of effective mitigations, AI development and its incorporation into existing systems charge full speed ahead with the rise of generative AI and large language models. Will our ineffectiveness in developing solutions to adversarial threats further extend to these new technologies? In this paper, we argue that overly permissive attack and overly restrictive defensive threat models have hampered defense development in the ML domain. Through the lens of adversarial evasion attacks against neural networks, we critically examine common attack assumptions, such as the ability to bypass any defense not explicitly built into the model. We argue that these flawed assumptions, seen as reasonable by the community based on paper acceptance, have encouraged the development of adversarial attacks that map poorly to real-world scenarios. In turn, new defenses evaluated against these very attacks are inadvertently required to be almost perfect and incorporated as part of the model. But do they need to? In practice, machine learning models are deployed as a small component of a larger system. We analyze adversarial machine learning from a system security perspective rather than an AI perspective and its implications for emerging AI paradigms.
Accelerating Certified Robustness Training via Knowledge Transfer
Oct 25, 2022Training deep neural network classifiers that are certifiably robust against adversarial attacks is critical to ensuring the security and reliability of AI-controlled systems. Although numerous state-of-the-art certified training methods have been developed, they are computationally expensive and scale poorly with respect to both dataset and network complexity. Widespread usage of certified training is further hindered by the fact that periodic retraining is necessary to incorporate new data and network improvements. In this paper, we propose Certified Robustness Transfer (CRT), a general-purpose framework for reducing the computational overhead of any certifiably robust training method through knowledge transfer. Given a robust teacher, our framework uses a novel training loss to transfer the teacher's robustness to the student. We provide theoretical and empirical validation of CRT. Our experiments on CIFAR-10 show that CRT speeds up certified robustness training by $8 \times$ on average across three different architecture generations while achieving comparable robustness to state-of-the-art methods. We also show that CRT can scale to large-scale datasets like ImageNet.
Ares: A System-Oriented Wargame Framework for Adversarial ML
Oct 24, 2022Since the discovery of adversarial attacks against machine learning models nearly a decade ago, research on adversarial machine learning has rapidly evolved into an eternal war between defenders, who seek to increase the robustness of ML models against adversarial attacks, and adversaries, who seek to develop better attacks capable of weakening or defeating these defenses. This domain, however, has found little buy-in from ML practitioners, who are neither overtly concerned about these attacks affecting their systems in the real world nor are willing to trade off the accuracy of their models in pursuit of robustness against these attacks. In this paper, we motivate the design and implementation of Ares, an evaluation framework for adversarial ML that allows researchers to explore attacks and defenses in a realistic wargame-like environment. Ares frames the conflict between the attacker and defender as two agents in a reinforcement learning environment with opposing objectives. This allows the introduction of system-level evaluation metrics such as time to failure and evaluation of complex strategies such as moving target defenses. We provide the results of our initial exploration involving a white-box attacker against an adversarially trained defender.
Transferring Adversarial Robustness Through Robust Representation Matching
Feb 21, 2022
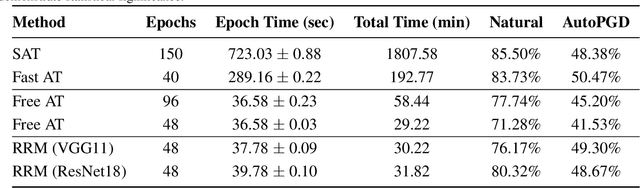
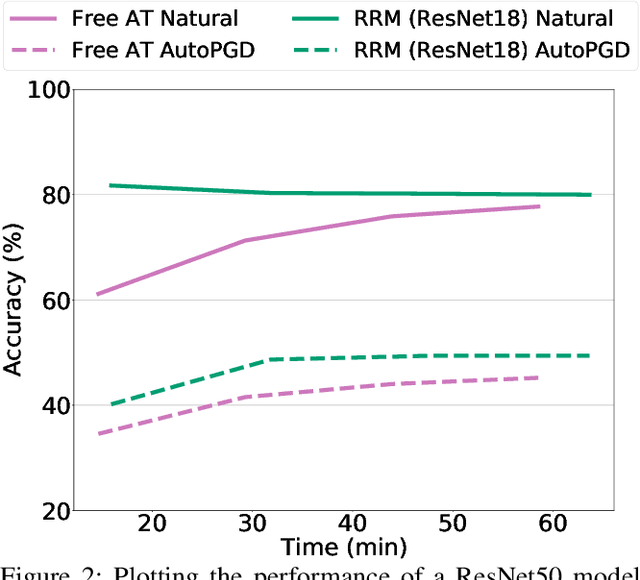
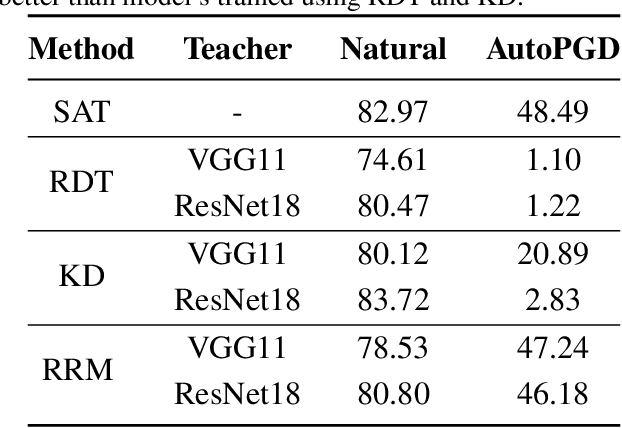
With the widespread use of machine learning, concerns over its security and reliability have become prevalent. As such, many have developed defenses to harden neural networks against adversarial examples, imperceptibly perturbed inputs that are reliably misclassified. Adversarial training in which adversarial examples are generated and used during training is one of the few known defenses able to reliably withstand such attacks against neural networks. However, adversarial training imposes a significant training overhead and scales poorly with model complexity and input dimension. In this paper, we propose Robust Representation Matching (RRM), a low-cost method to transfer the robustness of an adversarially trained model to a new model being trained for the same task irrespective of architectural differences. Inspired by student-teacher learning, our method introduces a novel training loss that encourages the student to learn the teacher's robust representations. Compared to prior works, RRM is superior with respect to both model performance and adversarial training time. On CIFAR-10, RRM trains a robust model $\sim 1.8\times$ faster than the state-of-the-art. Furthermore, RRM remains effective on higher-dimensional datasets. On Restricted-ImageNet, RRM trains a ResNet50 model $\sim 18\times$ faster than standard adversarial training.
Can Attention Masks Improve Adversarial Robustness?
Dec 21, 2019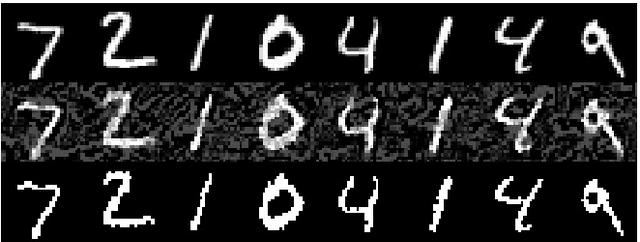


Deep Neural Networks (DNNs) are known to be susceptible to adversarial examples. Adversarial examples are maliciously crafted inputs that are designed to fool a model, but appear normal to human beings. Recent work has shown that pixel discretization can be used to make classifiers for MNIST highly robust to adversarial examples. However, pixel discretization fails to provide significant protection on more complex datasets. In this paper, we take the first step towards reconciling these contrary findings. Focusing on the observation that discrete pixelization in MNIST makes the background completely black and foreground completely white, we hypothesize that the important property for increasing robustness is the elimination of image background using attention masks before classifying an object. To examine this hypothesis, we create foreground attention masks for two different datasets, GTSRB and MS-COCO. Our initial results suggest that using attention mask leads to improved robustness. On the adversarially trained classifiers, we see an adversarial robustness increase of over 20% on MS-COCO.
Transferable Adversarial Robustness using Adversarially Trained Autoencoders
Sep 12, 2019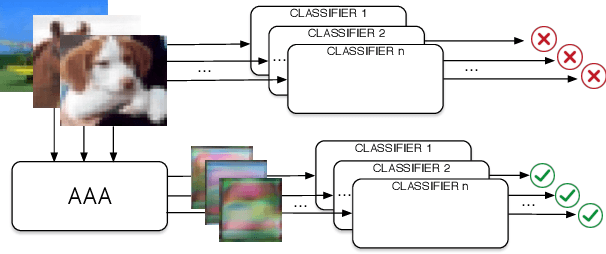
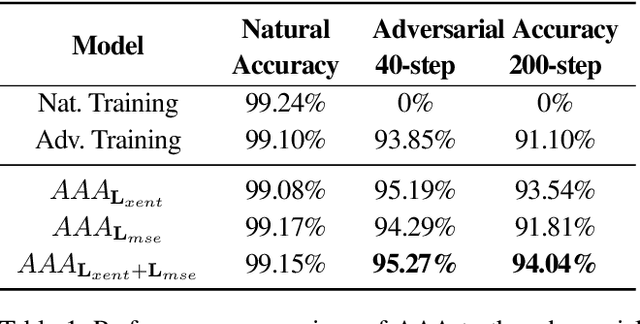
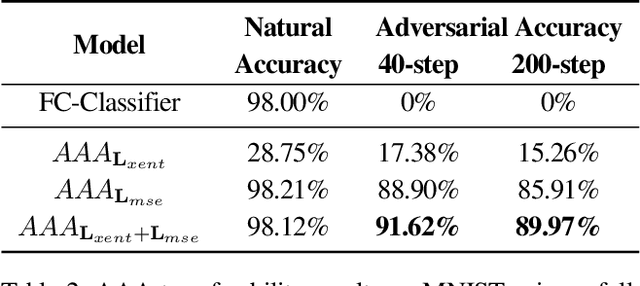
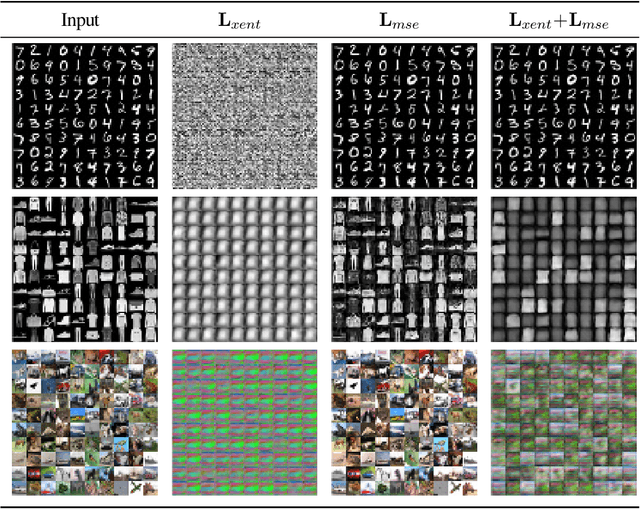
Machine learning has proven to be an extremely useful tool for solving complex problems in many application domains. This prevalence makes it an attractive target for malicious actors. Adversarial machine learning is a well-studied field of research in which an adversary seeks to cause predicable errors in a machine learning algorithm through careful manipulation of the input. In response, numerous techniques have been proposed to harden machine learning algorithms and mitigate the effect of adversarial attacks. Of these techniques, adversarial training, which augments the training data with adversarial inputs, has proven to be an effective defensive technique. However, adversarial training is computationally expensive and the improvements in adversarial performance are limited to a single model. In this paper, we propose Adversarially-Trained Autoencoder Augmentation, the first transferable adversarial defense that is robust to certain adaptive adversaries. We disentangle adversarial robustness from the classification pipeline by adversarially training an autoencoder with respect to the classification loss. We show that our approach achieves comparable results to state-of-the-art adversarially trained models on the MNIST, Fashion-MNIST, and CIFAR-10 datasets. Furthermore, we can transfer our approach to other vulnerable models and improve their adversarial performance without additional training. Finally, we combine our defense with ensemble methods and parallelize adversarial training across multiple vulnerable pre-trained models. In a single adversarial training session, the autoencoder can achieve adversarial performance on the vulnerable models that is comparable or better than standard adversarial training.