 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Variational Autoencoder using Random Fourier Transformation: An Aviation Safety Anomaly Detection Case-Study
Jan 03, 2026In this study, we focus on the training process and inference improvements of deep neural networks (DNNs), specifically Autoencoders (AEs) and Variational Autoencoders (VAEs), using Random Fourier Transformation (RFT). We further explore the role of RFT in model training behavior using Frequency Principle (F-Principle) analysis and show that models with RFT turn to learn low frequency and high frequency at the same time, whereas conventional DNNs start from low frequency and gradually learn (if successful) high-frequency features. We focus on reconstruction-based anomaly detection using autoencoder and variational autoencoder and investigate the RFT's role. We also introduced a trainable variant of RFT that uses the existing computation graph to train the expansion of RFT instead of it being random. We showcase our findings with two low-dimensional synthetic datasets for data representation, and an aviation safety dataset, called Dashlink, for high-dimensional reconstruction-based anomaly detection. The results indicate the superiority of models with Fourier transformation compared to the conventional counterpart and remain inconclusive regarding the benefits of using trainable Fourier transformation in contrast to the Random variant.
Sequential Reservoir Computing for Efficient High-Dimensional Spatiotemporal Forecasting
Jan 01, 2026Forecasting high-dimensional spatiotemporal systems remains computationally challenging for recurrent neural networks (RNNs) and long short-term memory (LSTM) models due to gradient-based training and memory bottlenecks. Reservoir Computing (RC) mitigates these challenges by replacing backpropagation with fixed recurrent layers and a convex readout optimization, yet conventional RC architectures still scale poorly with input dimensionality. We introduce a Sequential Reservoir Computing (Sequential RC) architecture that decomposes a large reservoir into a series of smaller, interconnected reservoirs. This design reduces memory and computational costs while preserving long-term temporal dependencies. Using both low-dimensional chaotic systems (Lorenz63) and high-dimensional physical simulations (2D vorticity and shallow-water equations), Sequential RC achieves 15-25% longer valid forecast horizons, 20-30% lower error metrics (SSIM, RMSE), and up to three orders of magnitude lower training cost compared to LSTM and standard RNN baselines. The results demonstrate that Sequential RC maintains the simplicity and efficiency of conventional RC while achieving superior scalability for high-dimensional dynamical systems. This approach provides a practical path toward real-time, energy-efficient forecasting in scientific and engineering applications.
Prithvi-EO-2.0: A Versatile Multi-Temporal Foundation Model for Earth Observation Applications
Dec 03, 2024



This technical report presents Prithvi-EO-2.0, a new geospatial foundation model that offers significant improvements over its predecessor, Prithvi-EO-1.0. Trained on 4.2M global time series samples from NASA's Harmonized Landsat and Sentinel-2 data archive at 30m resolution, the new 300M and 600M parameter models incorporate temporal and location embeddings for enhanced performance across various geospatial tasks. Through extensive benchmarking with GEO-Bench, the 600M version outperforms the previous Prithvi-EO model by 8\% across a range of tasks. It also outperforms six other geospatial foundation models when benchmarked on remote sensing tasks from different domains and resolutions (i.e. from 0.1m to 15m). The results demonstrate the versatility of the model in both classical earth observation and high-resolution applications. Early involvement of end-users and subject matter experts (SMEs) are among the key factors that contributed to the project's success. In particular, SME involvement allowed for constant feedback on model and dataset design, as well as successful customization for diverse SME-led applications in disaster response, land use and crop mapping, and ecosystem dynamics monitoring. Prithvi-EO-2.0 is available on Hugging Face and IBM terratorch, with additional resources on GitHub. The project exemplifies the Trusted Open Science approach embraced by all involved organizations.
Combinatorial Reasoning: Selecting Reasons in Generative AI Pipelines via Combinatorial Optimization
Jun 19, 2024



Recent Large Language Models (LLMs) have demonstrated impressive capabilities at tasks that require human intelligence and are a significant step towards human-like artificial intelligence (AI). Yet the performance of LLMs at reasoning tasks have been subpar and the reasoning capability of LLMs is a matter of significant debate. While it has been shown that the choice of the prompting technique to the LLM can alter its performance on a multitude of tasks, including reasoning, the best performing techniques require human-made prompts with the knowledge of the tasks at hand. We introduce a framework for what we call Combinatorial Reasoning (CR), a fully-automated prompting method, where reasons are sampled from an LLM pipeline and mapped into a Quadratic Unconstrained Binary Optimization (QUBO) problem. The framework investigates whether QUBO solutions can be profitably used to select a useful subset of the reasons to construct a Chain-of-Thought style prompt. We explore the acceleration of CR with specialized solvers. We also investigate the performance of simpler zero-shot strategies such as linear majority rule or random selection of reasons. Our preliminary study indicates that coupling a combinatorial solver to generative AI pipelines is an interesting avenue for AI reasoning and elucidates design principles for future CR methods.
Anomaly Detection in Aeronautics Data with Quantum-compatible Discrete Deep Generative Model
Mar 22, 2023Deep generative learning cannot only be used for generating new data with statistical characteristics derived from input data but also for anomaly detection, by separating nominal and anomalous instances based on their reconstruction quality. In this paper, we explore the performance of three unsupervised deep generative models -- variational autoencoders (VAEs) with Gaussian, Bernoulli, and Boltzmann priors -- in detecting anomalies in flight-operations data of commercial flights consisting of multivariate time series. We devised two VAE models with discrete latent variables (DVAEs), one with a factorized Bernoulli prior and one with a restricted Boltzmann machine (RBM) as prior, because of the demand for discrete-variable models in machine-learning applications and because the integration of quantum devices based on two-level quantum systems requires such models. The DVAE with RBM prior, using a relatively simple -- and classically or quantum-mechanically enhanceable -- sampling technique for the evolution of the RBM's negative phase, performed better than the Bernoulli DVAE and on par with the Gaussian model, which has a continuous latent space. Our studies demonstrate the competitiveness of a discrete deep generative model with its Gaussian counterpart on anomaly-detection tasks. Moreover, the DVAE model with RBM prior can be easily integrated with quantum sampling by outsourcing its generative process to measurements of quantum states obtained from a quantum annealer or gate-model device.
Deep Transfer Learning on Satellite Imagery Improves Air Quality Estimates in Developing Nations
Feb 17, 2022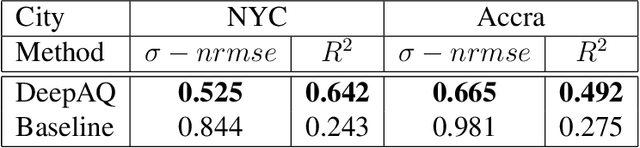
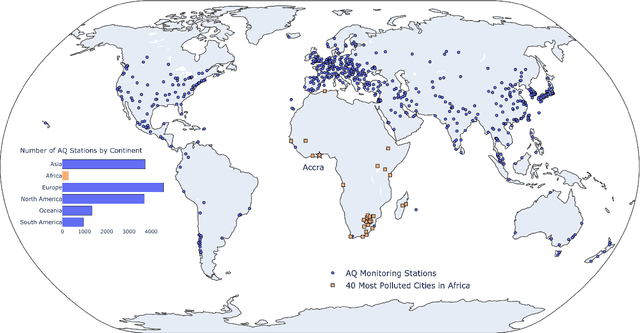
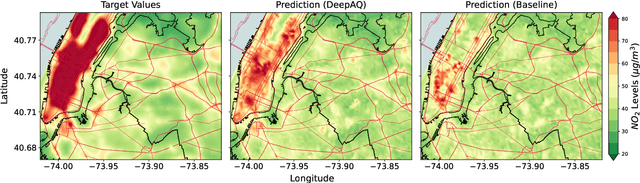
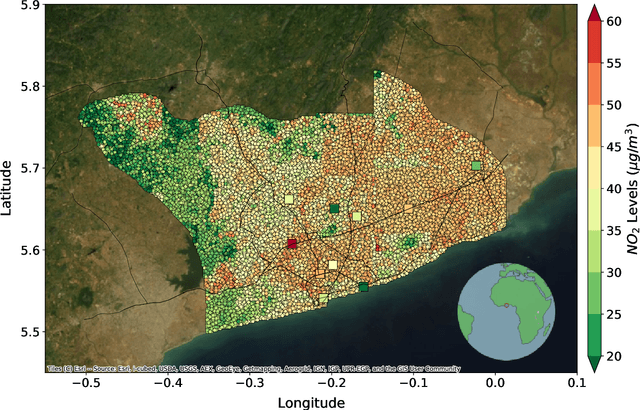
Urban air pollution is a public health challenge in low- and middle-income countries (LMICs). However, LMICs lack adequate air quality (AQ) monitoring infrastructure. A persistent challenge has been our inability to estimate AQ accurately in LMIC cities, which hinders emergency preparedness and risk mitigation. Deep learning-based models that map satellite imagery to AQ can be built for high-income countries (HICs) with adequate ground data. Here we demonstrate that a scalable approach that adapts deep transfer learning on satellite imagery for AQ can extract meaningful estimates and insights in LMIC cities based on spatiotemporal patterns learned in HIC cities. The approach is demonstrated for Accra in Ghana, Africa, with AQ patterns learned from two US cities, specifically Los Angeles and New York.