 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Reproducibility in Evolutionary Computation: A Case Study using Human- and LLM-based Assessment
Feb 05, 2026Reproducibility is an important requirement in evolutionary computation, where results largely depend on computational experiments. In practice, reproducibility relies on how algorithms, experimental protocols, and artifacts are documented and shared. Despite growing awareness, there is still limited empirical evidence on the actual reproducibility levels of published work in the field. In this paper, we study the reproducibility practices in papers published in the Evolutionary Combinatorial Optimization and Metaheuristics track of the Genetic and Evolutionary Computation Conference over a ten-year period. We introduce a structured reproducibility checklist and apply it through a systematic manual assessment of the selected corpus. In addition, we propose RECAP (REproducibility Checklist Automation Pipeline), an LLM-based system that automatically evaluates reproducibility signals from paper text and associated code repositories. Our analysis shows that papers achieve an average completeness score of 0.62, and that 36.90% of them provide additional material beyond the manuscript itself. We demonstrate that automated assessment is feasible: RECAP achieves substantial agreement with human evaluators (Cohen's k of 0.67). Together, these results highlight persistent gaps in reproducibility reporting and suggest that automated tools can effectively support large-scale, systematic monitoring of reproducibility practices.
Mirror Mode in Fire Emblem: Beating Players at their own Game with Imitation and Reinforcement Learning
Dec 10, 2025Enemy strategies in turn-based games should be surprising and unpredictable. This study introduces Mirror Mode, a new game mode where the enemy AI mimics the personal strategy of a player to challenge them to keep changing their gameplay. A simplified version of the Nintendo strategy video game Fire Emblem Heroes has been built in Unity, with a Standard Mode and a Mirror Mode. Our first set of experiments find a suitable model for the task to imitate player demonstrations, using Reinforcement Learning and Imitation Learning: combining Generative Adversarial Imitation Learning, Behavioral Cloning, and Proximal Policy Optimization. The second set of experiments evaluates the constructed model with player tests, where models are trained on demonstrations provided by participants. The gameplay of the participants indicates good imitation in defensive behavior, but not in offensive strategies. Participant's surveys indicated that they recognized their own retreating tactics, and resulted in an overall higher player-satisfaction for Mirror Mode. Refining the model further may improve imitation quality and increase player's satisfaction, especially when players face their own strategies. The full code and survey results are stored at: https://github.com/YannaSmid/MirrorMode
A Unified Framework for Zero-Shot Reinforcement Learning
Oct 23, 2025Zero-shot reinforcement learning (RL) has emerged as a setting for developing general agents in an unsupervised manner, capable of solving downstream tasks without additional training or planning at test-time. Unlike conventional RL, which optimizes policies for a fixed reward, zero-shot RL requires agents to encode representations rich enough to support immediate adaptation to any objective, drawing parallels to vision and language foundation models. Despite growing interest, the field lacks a common analytical lens. We present the first unified framework for zero-shot RL. Our formulation introduces a consistent notation and taxonomy that organizes existing approaches and allows direct comparison between them. Central to our framework is the classification of algorithms into two families: direct representations, which learn end-to-end mappings from rewards to policies, and compositional representations, which decompose the representation leveraging the substructure of the value function. Within this framework, we highlight shared principles and key differences across methods, and we derive an extended bound for successor-feature methods, offering a new perspective on their performance in the zero-shot regime. By consolidating existing work under a common lens, our framework provides a principled foundation for future research in zero-shot RL and outlines a clear path toward developing more general agents.
Analysis of Bluffing by DQN and CFR in Leduc Hold'em Poker
Sep 04, 2025
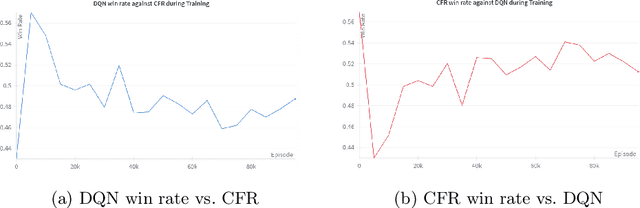
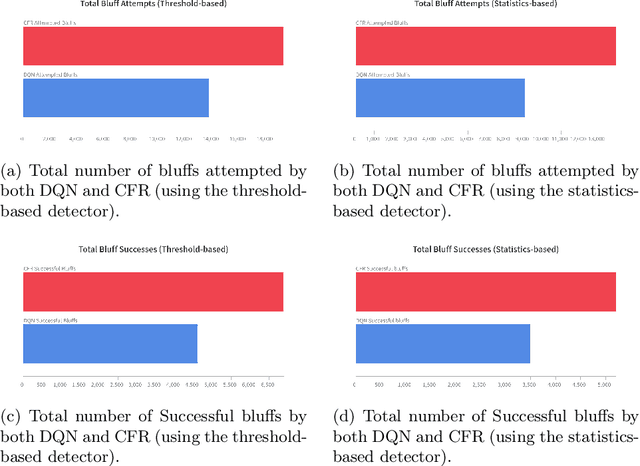
In the game of poker, being unpredictable, or bluffing, is an essential skill. When humans play poker, they bluff. However, most works on computer-poker focus on performance metrics such as win rates, while bluffing is overlooked. In this paper we study whether two popular algorithms, DQN (based on reinforcement learning) and CFR (based on game theory), exhibit bluffing behavior in Leduc Hold'em, a simplified version of poker. We designed an experiment where we let the DQN and CFR agent play against each other while we log their actions. We find that both DQN and CFR exhibit bluffing behavior, but they do so in different ways. Although both attempt to perform bluffs at different rates, the percentage of successful bluffs (where the opponent folds) is roughly the same. This suggests that bluffing is an essential aspect of the game, not of the algorithm. Future work should look at different bluffing styles and at the full game of poker. Code at https://github.com/TarikZ03/Bluffing-by-DQN-and-CFR-in-Leduc-Hold-em-Poker-Codebase.
Pluri-perspectivism in Human-robot Co-creativity with Older Adults
Jul 10, 2025



This position paper explores pluriperspectivism as a core element of human creative experience and its relevance to humanrobot cocreativity We propose a layered fivedimensional model to guide the design of cocreative behaviors and the analysis of interaction dynamics This model is based on literature and results from an interview study we conducted with 10 visual artists and 8 arts educators examining how pluriperspectivism supports creative practice The findings of this study provide insight in how robots could enhance human creativity through adaptive contextsensitive behavior demonstrating the potential of pluriperspectivism This paper outlines future directions for integrating pluriperspectivism with visionlanguage models VLMs to support context sensitivity in cocreative robots
Chargax: A JAX Accelerated EV Charging Simulator
Jul 02, 2025Deep Reinforcement Learning can play a key role in addressing sustainable energy challenges. For instance, many grid systems are heavily congested, highlighting the urgent need to enhance operational efficiency. However, reinforcement learning approaches have traditionally been slow due to the high sample complexity and expensive simulation requirements. While recent works have effectively used GPUs to accelerate data generation by converting environments to JAX, these works have largely focussed on classical toy problems. This paper introduces Chargax, a JAX-based environment for realistic simulation of electric vehicle charging stations designed for accelerated training of RL agents. We validate our environment in a variety of scenarios based on real data, comparing reinforcement learning agents against baselines. Chargax delivers substantial computational performance improvements of over 100x-1000x over existing environments. Additionally, Chargax' modular architecture enables the representation of diverse real-world charging station configurations.
Baba is LLM: Reasoning in a Game with Dynamic Rules
Jun 23, 2025



Large language models (LLMs) are known to perform well on language tasks, but struggle with reasoning tasks. This paper explores the ability of LLMs to play the 2D puzzle game Baba is You, in which players manipulate rules by rearranging text blocks that define object properties. Given that this rule-manipulation relies on language abilities and reasoning, it is a compelling challenge for LLMs. Six LLMs are evaluated using different prompt types, including (1) simple, (2) rule-extended and (3) action-extended prompts. In addition, two models (Mistral, OLMo) are finetuned using textual and structural data from the game. Results show that while larger models (particularly GPT-4o) perform better in reasoning and puzzle solving, smaller unadapted models struggle to recognize game mechanics or apply rule changes. Finetuning improves the ability to analyze the game levels, but does not significantly improve solution formulation. We conclude that even for state-of-the-art and finetuned LLMs, reasoning about dynamic rule changes is difficult (specifically, understanding the use-mention distinction). The results provide insights into the applicability of LLMs to complex problem-solving tasks and highlight the suitability of games with dynamically changing rules for testing reasoning and reflection by LLMs.
Towards a Deeper Understanding of Reasoning Capabilities in Large Language Models
May 15, 2025



While large language models demonstrate impressive performance on static benchmarks, the true potential of large language models as self-learning and reasoning agents in dynamic environments remains unclear. This study systematically evaluates the efficacy of self-reflection, heuristic mutation, and planning as prompting techniques to test the adaptive capabilities of agents. We conduct experiments with various open-source language models in dynamic environments and find that larger models generally outperform smaller ones, but that strategic prompting can close this performance gap. Second, a too-long prompt can negatively impact smaller models on basic reactive tasks, while larger models show more robust behaviour. Third, advanced prompting techniques primarily benefit smaller models on complex games, but offer less improvement for already high-performing large language models. Yet, we find that advanced reasoning methods yield highly variable outcomes: while capable of significantly improving performance when reasoning and decision-making align, they also introduce instability and can lead to big performance drops. Compared to human performance, our findings reveal little evidence of true emergent reasoning. Instead, large language model performance exhibits persistent limitations in crucial areas such as planning, reasoning, and spatial coordination, suggesting that current-generation large language models still suffer fundamental shortcomings that may not be fully overcome through self-reflective prompting alone. Reasoning is a multi-faceted task, and while reasoning methods like Chain of thought improves multi-step reasoning on math word problems, our findings using dynamic benchmarks highlight important shortcomings in general reasoning capabilities, indicating a need to move beyond static benchmarks to capture the complexity of reasoning.
Agentic Large Language Models, a survey
Mar 29, 2025



There is great interest in agentic LLMs, large language models that act as agents. We review the growing body of work in this area and provide a research agenda. Agentic LLMs are LLMs that (1) reason, (2) act, and (3) interact. We organize the literature according to these three categories. The research in the first category focuses on reasoning, reflection, and retrieval, aiming to improve decision making; the second category focuses on action models, robots, and tools, aiming for agents that act as useful assistants; the third category focuses on multi-agent systems, aiming for collaborative task solving and simulating interaction to study emergent social behavior. We find that works mutually benefit from results in other categories: retrieval enables tool use, reflection improves multi-agent collaboration, and reasoning benefits all categories. We discuss applications of agentic LLMs and provide an agenda for further research. Important applications are in medical diagnosis, logistics and financial market analysis. Meanwhile, self-reflective agents playing roles and interacting with one another augment the process of scientific research itself. Further, agentic LLMs may provide a solution for the problem of LLMs running out of training data: inference-time behavior generates new training states, such that LLMs can keep learning without needing ever larger datasets. We note that there is risk associated with LLM assistants taking action in the real world, while agentic LLMs are also likely to benefit society.
ACTIVA: Amortized Causal Effect Estimation without Graphs via Transformer-based Variational Autoencoder
Mar 03, 2025



Predicting the distribution of outcomes under hypothetical interventions is crucial in domains like healthcare, economics, and policy-making. Current methods often rely on strong assumptions, such as known causal graphs or parametric models, and lack amortization across problem instances, limiting their practicality. We propose a novel transformer-based conditional variational autoencoder architecture, named ACTIVA, that extends causal transformer encoders to predict causal effects as mixtures of Gaussians. Our method requires no causal graph and predicts interventional distributions given only observational data and a queried intervention. By amortizing over many simulated instances, it enables zero-shot generalization to novel datasets without retraining. Experiments demonstrate accurate predictions for synthetic and semi-synthetic data, showcasing the effectiveness of our graph-free, amortized causal inference approach.