 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMuMDR: Code-mixed Multi-modal Multi-domain corpus for Discourse paRsing in conversations
Paper and Code
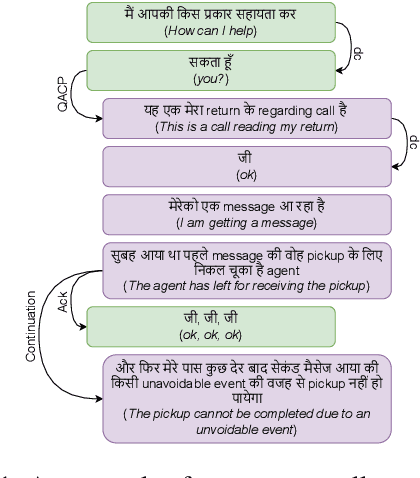



Discourse parsing is an important task useful for NLU applications such as summarization, machine comprehension, and emotion recognition. The current discourse parsing datasets based on conversations consists of written English dialogues restricted to a single domain. In this resource paper, we introduce CoMuMDR: Code-mixed Multi-modal Multi-domain corpus for Discourse paRsing in conversations. The corpus (code-mixed in Hindi and English) has both audio and transcribed text and is annotated with nine discourse relations. We experiment with various SoTA baseline models; the poor performance of SoTA models highlights the challenges of multi-domain code-mixed corpus, pointing towards the need for developing better models for such realistic settings.