 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQASC: A Dataset for Question Answering via Sentence Composition
Oct 25, 2019

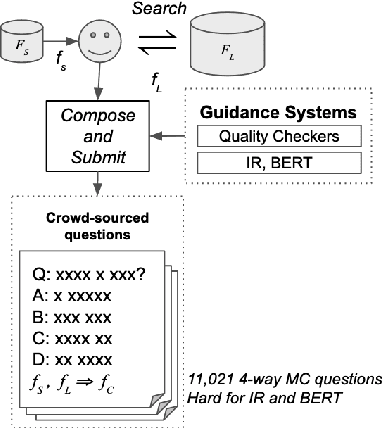

Composing knowledge from multiple pieces of texts is a key challenge in multi-hop question answering. We present a multi-hop reasoning dataset, Question Answering via Sentence Composition(QASC), that requires retrieving facts from a large corpus and composing them to answer a multiple-choice question. QASC is the first dataset to offer two desirable properties: (a) the facts to be composed are annotated in a large corpus, and (b) the decomposition into these facts is not evident from the question itself. The latter makes retrieval challenging as the system must introduce new concepts or relations in order to discover potential decompositions. Further, the reasoning model must then learn to identify valid compositions of these retrieved facts using common-sense reasoning. To help address these challenges, we provide annotation for supporting facts as well as their composition. Guided by these annotations, we present a two-step approach to mitigate the retrieval challenges. We use other multiple-choice datasets as additional training data to strengthen the reasoning model. Our proposed approach improves over current state-of-the-art language models by 11% (absolute). The reasoning and retrieval problems, however, remain unsolved as this model still lags by 20% behind human performance.
AdaWISH: Faster Discrete Integration via Adaptive Quantiles
Oct 13, 2019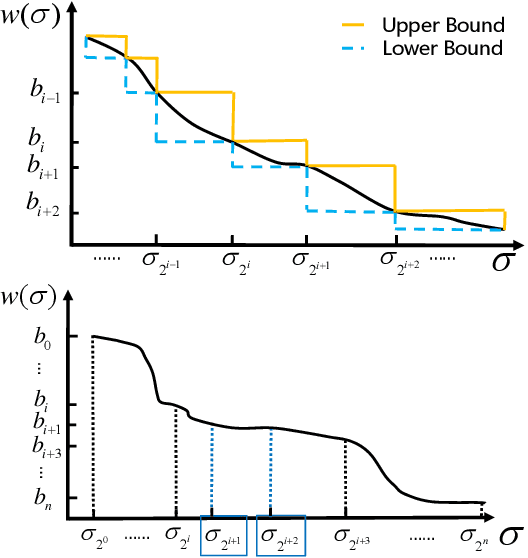
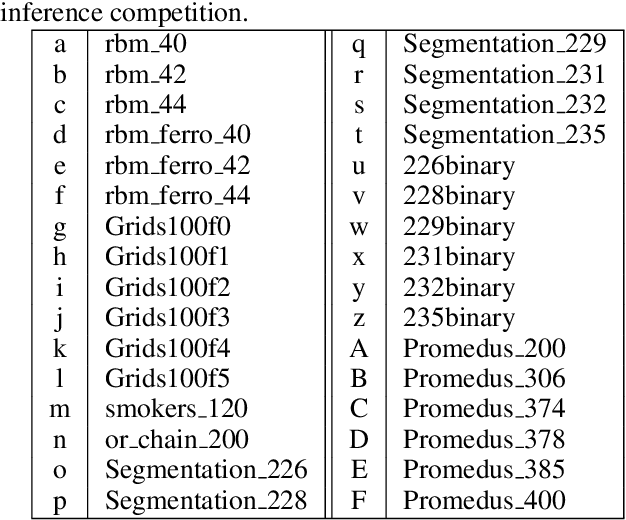
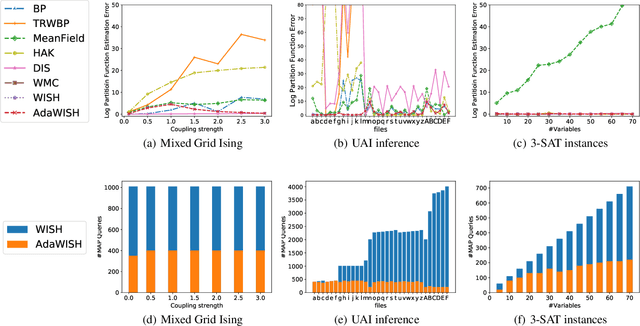
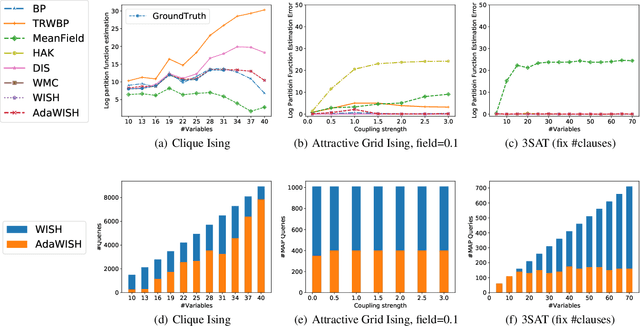
Discrete integration in a high dimensional space of $n$ variables poses fundamental challenges. The WISH algorithm reduces the intractable discrete integration problem into $n$ optimization queries subject to randomized constraints, obtaining a constant approximation guarantee. The optimization queries are expensive, which limits the applicability of WISH. We propose AdaWISH, which is able to obtain the same guarantee, but accesses only a small subset of queries of WISH. For example, when the number of function values is bounded by a constant, AdaWISH issues only $O(\log n)$ queries. The key idea is to query adaptively, taking advantage of the shape of the weight function. In general, we prove that AdaWISH has a regret of no more than $O(\log n)$ relative to an oracle that issues queries at data-dependent optimal points. Experimentally, AdaWISH gives precise estimates for discrete integration problems, of the same quality as that of WISH and better than several competing approaches, on a variety of probabilistic inference benchmarks, while saving substantially on the number of optimization queries compared to WISH. For example, it saves $81.5\%$ of WISH queries while retaining the quality of results on a suite of UAI inference challenge benchmarks.
What's Missing: A Knowledge Gap Guided Approach for Multi-hop Question Answering
Sep 19, 2019

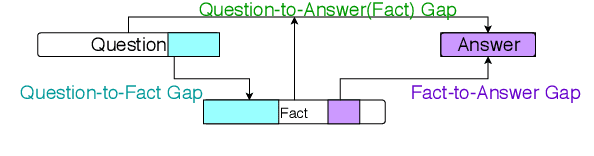
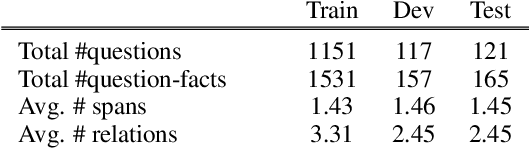
Multi-hop textual question answering requires combining information from multiple sentences. We focus on a natural setting where, unlike typical reading comprehension, only partial information is provided with each question. The model must retrieve and use additional knowledge to correctly answer the question. To tackle this challenge, we develop a novel approach that explicitly identifies the knowledge gap between a key span in the provided knowledge and the answer choices. The model, GapQA, learns to fill this gap by determining the relationship between the span and an answer choice, based on retrieved knowledge targeting this gap. We propose jointly training a model to simultaneously fill this knowledge gap and compose it with the provided partial knowledge. On the OpenBookQA dataset, given partial knowledge, explicitly identifying what's missing substantially outperforms previous approaches.
Probing Natural Language Inference Models through Semantic Fragments
Sep 16, 2019
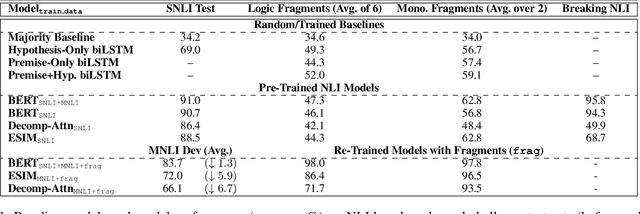
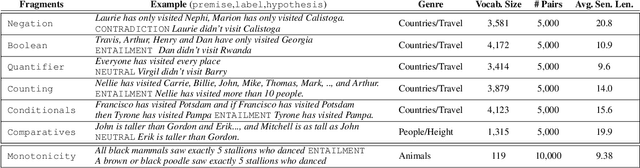

Do state-of-the-art models for language understanding already have, or can they easily learn, abilities such as boolean coordination, quantification, conditionals, comparatives, and monotonicity reasoning (i.e., reasoning about word substitutions in sentential contexts)? While such phenomena are involved in natural language inference (NLI) and go beyond basic linguistic understanding, it is unclear the extent to which they are captured in existing NLI benchmarks and effectively learned by models. To investigate this, we propose the use of semantic fragments---systematically generated datasets that each target a different semantic phenomenon---for probing, and efficiently improving, such capabilities of linguistic models. This approach to creating challenge datasets allows direct control over the semantic diversity and complexity of the targeted linguistic phenomena, and results in a more precise characterization of a model's linguistic behavior. Our experiments, using a library of 8 such semantic fragments, reveal two remarkable findings: (a) State-of-the-art models, including BERT, that are pre-trained on existing NLI benchmark datasets perform poorly on these new fragments, even though the phenomena probed here are central to the NLI task. (b) On the other hand, with only a few minutes of additional fine-tuning---with a carefully selected learning rate and a novel variation of "inoculation"---a BERT-based model can master all of these logic and monotonicity fragments while retaining its performance on established NLI benchmarks.
From 'F' to 'A' on the N.Y. Regents Science Exams: An Overview of the Aristo Project
Sep 11, 2019
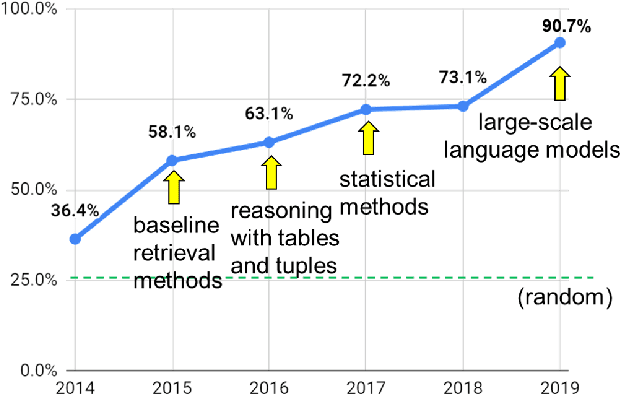


AI has achieved remarkable mastery over games such as Chess, Go, and Poker, and even Jeopardy, but the rich variety of standardized exams has remained a landmark challenge. Even in 2016, the best AI system achieved merely 59.3% on an 8th Grade science exam challenge. This paper reports unprecedented success on the Grade 8 New York Regents Science Exam, where for the first time a system scores more than 90% on the exam's non-diagram, multiple choice (NDMC) questions. In addition, our Aristo system, building upon the success of recent language models, exceeded 83% on the corresponding Grade 12 Science Exam NDMC questions. The results, on unseen test questions, are robust across different test years and different variations of this kind of test. They demonstrate that modern NLP methods can result in mastery on this task. While not a full solution to general question-answering (the questions are multiple choice, and the domain is restricted to 8th Grade science), it represents a significant milestone for the field.
Question Answering as Global Reasoning over Semantic Abstractions
Jun 09, 2019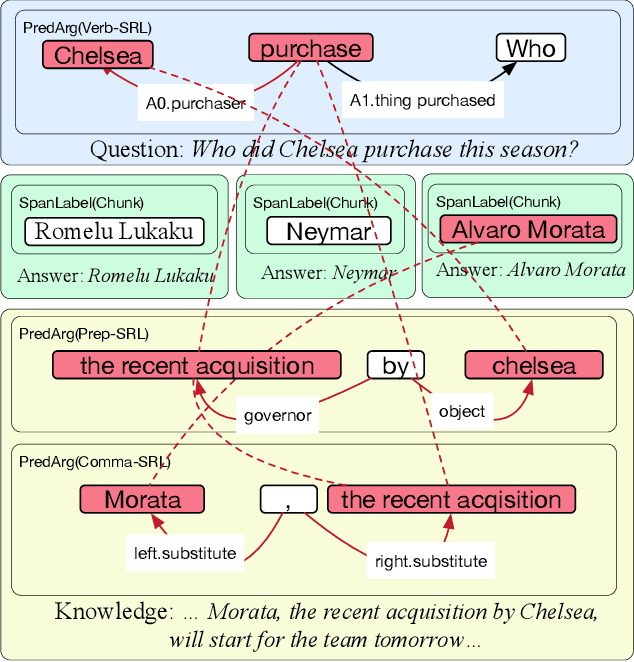

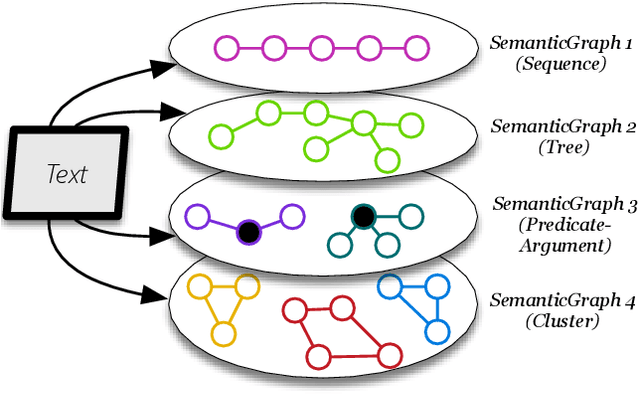

We propose a novel method for exploiting the semantic structure of text to answer multiple-choice questions. The approach is especially suitable for domains that require reasoning over a diverse set of linguistic constructs but have limited training data. To address these challenges, we present the first system, to the best of our knowledge, that reasons over a wide range of semantic abstractions of the text, which are derived using off-the-shelf, general-purpose, pre-trained natural language modules such as semantic role labelers, coreference resolvers, and dependency parsers. Representing multiple abstractions as a family of graphs, we translate question answering (QA) into a search for an optimal subgraph that satisfies certain global and local properties. This formulation generalizes several prior structured QA systems. Our system, SEMANTICILP, demonstrates strong performance on two domains simultaneously. In particular, on a collection of challenging science QA datasets, it outperforms various state-of-the-art approaches, including neural models, broad coverage information retrieval, and specialized techniques using structured knowledge bases, by 2%-6%.
Repurposing Entailment for Multi-Hop Question Answering Tasks
Apr 20, 2019
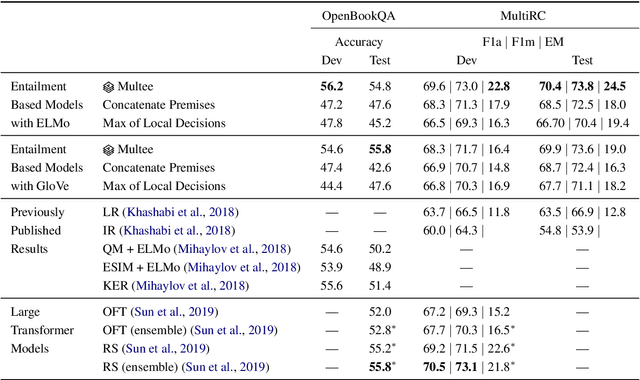
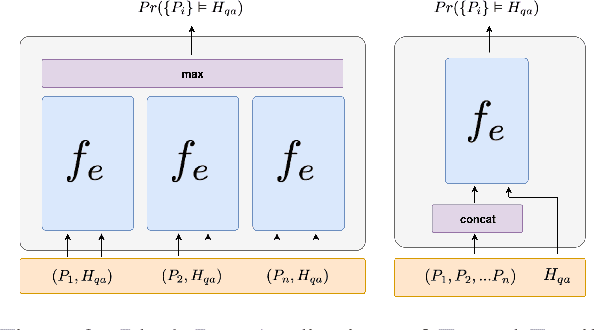

Question Answering (QA) naturally reduces to an entailment problem, namely, verifying whether some text entails the answer to a question. However, for multi-hop QA tasks, which require reasoning with multiple sentences, it remains unclear how best to utilize entailment models pre-trained on large scale datasets such as SNLI, which are based on sentence pairs. We introduce Multee, a general architecture that can effectively use entailment models for multi-hop QA tasks. Multee uses (i) a local module that helps locate important sentences, thereby avoiding distracting information, and (ii) a global module that aggregates information by effectively incorporating importance weights. Importantly, we show that both modules can use entailment functions pre-trained on a large scale NLI datasets. We evaluate performance on MultiRC and OpenBookQA, two multihop QA datasets. When using an entailment function pre-trained on NLI datasets, Multee outperforms QA models trained only on the target QA datasets and the OpenAI transformer models. The code is available at https://github.com/StonyBrookNLP/multee.
On the Capabilities and Limitations of Reasoning for Natural Language Understanding
Jan 08, 2019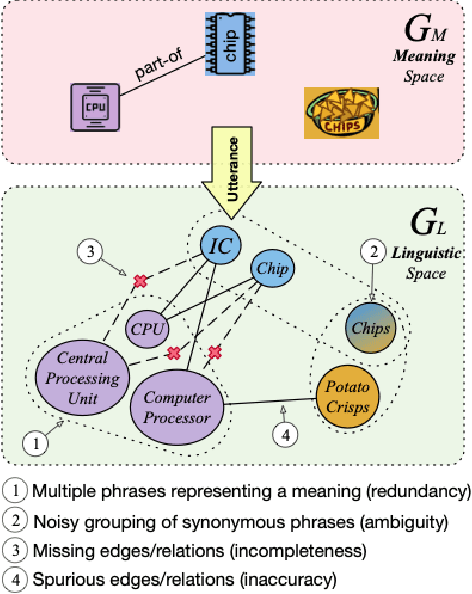
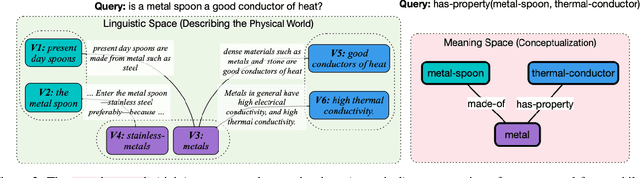
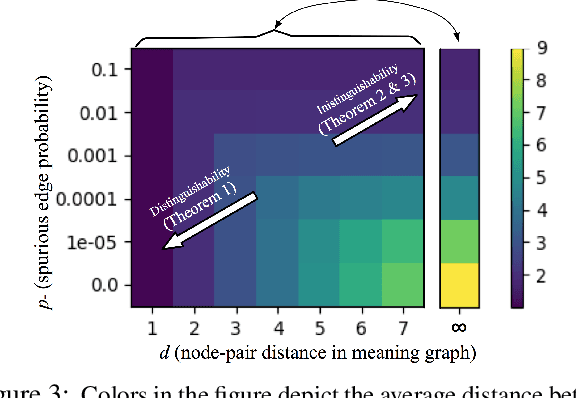
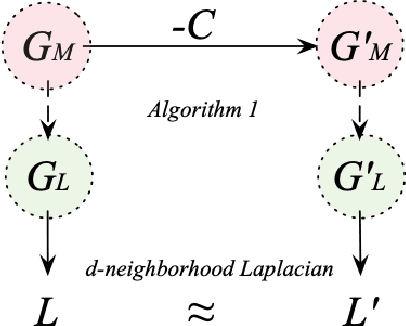
Recent systems for natural language understanding are strong at overcoming linguistic variability for lookup style reasoning. Yet, their accuracy drops dramatically as the number of reasoning steps increases. We present the first formal framework to study such empirical observations, addressing the ambiguity, redundancy, incompleteness, and inaccuracy that the use of language introduces when representing a hidden conceptual space. Our formal model uses two interrelated spaces: a conceptual meaning space that is unambiguous and complete but hidden, and a linguistic symbol space that captures a noisy grounding of the meaning space in the symbols or words of a language. We apply this framework to study the connectivity problem in undirected graphs---a core reasoning problem that forms the basis for more complex multi-hop reasoning. We show that it is indeed possible to construct a high-quality algorithm for detecting connectivity in the (latent) meaning graph, based on an observed noisy symbol graph, as long as the noise is below our quantified noise level and only a few hops are needed. On the other hand, we also prove an impossibility result: if a query requires a large number (specifically, logarithmic in the size of the meaning graph) of hops, no reasoning system operating over the symbol graph is likely to recover any useful property of the meaning graph. This highlights a fundamental barrier for a class of reasoning problems and systems, and suggests the need to limit the distance between the two spaces, rather than investing in multi-hop reasoning with "many" hops.
QuaRel: A Dataset and Models for Answering Questions about Qualitative Relationships
Nov 20, 2018

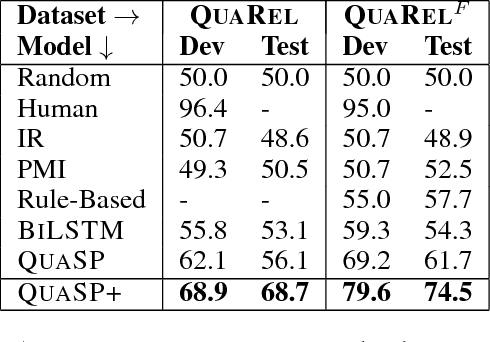
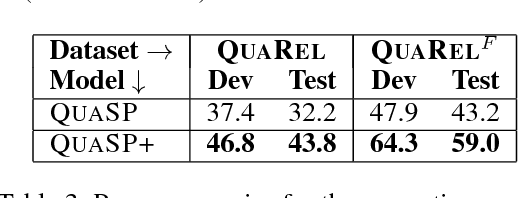
Many natural language questions require recognizing and reasoning with qualitative relationships (e.g., in science, economics, and medicine), but are challenging to answer with corpus-based methods. Qualitative modeling provides tools that support such reasoning, but the semantic parsing task of mapping questions into those models has formidable challenges. We present QuaRel, a dataset of diverse story questions involving qualitative relationships that characterize these challenges, and techniques that begin to address them. The dataset has 2771 questions relating 19 different types of quantities. For example, "Jenny observes that the robot vacuum cleaner moves slower on the living room carpet than on the bedroom carpet. Which carpet has more friction?" We contribute (1) a simple and flexible conceptual framework for representing these kinds of questions; (2) the QuaRel dataset, including logical forms, exemplifying the parsing challenges; and (3) two novel models for this task, built as extensions of type-constrained semantic parsing. The first of these models (called QuaSP+) significantly outperforms off-the-shelf tools on QuaRel. The second (QuaSP+Zero) demonstrates zero-shot capability, i.e., the ability to handle new qualitative relationships without requiring additional training data, something not possible with previous models. This work thus makes inroads into answering complex, qualitative questions that require reasoning, and scaling to new relationships at low cost. The dataset and models are available at http://data.allenai.org/quarel.
Exploiting Explicit Paths for Multi-hop Reading Comprehension
Nov 02, 2018
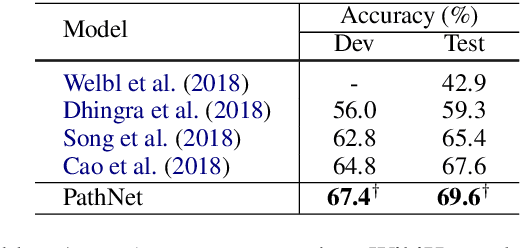
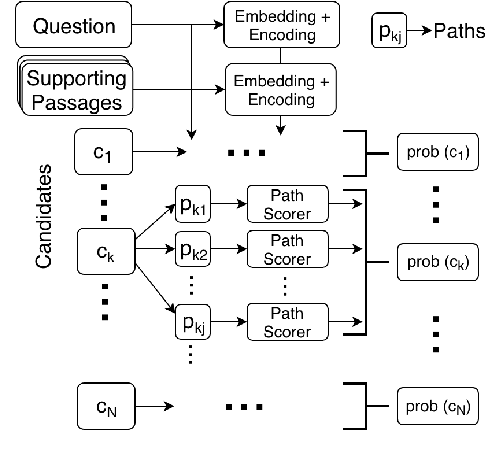
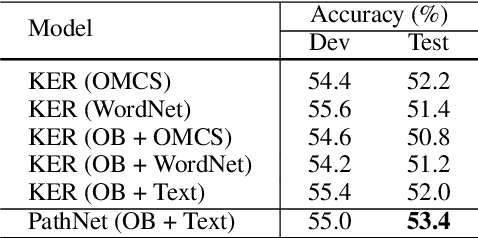
We focus on the task of multi-hop reading comprehension where a system is required to reason over a chain of multiple facts, distributed across multiple passages, to answer a question. Inspired by graph-based reasoning, we present a path-based reasoning approach for textual reading comprehension. It operates by generating potential paths across multiple passages, extracting implicit relations along this path, and composing them to encode each path. The proposed model achieves a 2.3% gain on the WikiHop Dev set as compared to previous state-of-the-art and, as a side-effect, is also able to explain its reasoning through explicit paths of sentences.