 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeds Don't Lie: An Adaptive Watermarking Framework for Computer Vision Models
Nov 24, 2022



In recent years, various watermarking methods were suggested to detect computer vision models obtained illegitimately from their owners, however they fail to demonstrate satisfactory robustness against model extraction attacks. In this paper, we present an adaptive framework to watermark a protected model, leveraging the unique behavior present in the model due to a unique random seed initialized during the model training. This watermark is used to detect extracted models, which have the same unique behavior, indicating an unauthorized usage of the protected model's intellectual property (IP). First, we show how an initial seed for random number generation as part of model training produces distinct characteristics in the model's decision boundaries, which are inherited by extracted models and present in their decision boundaries, but aren't present in non-extracted models trained on the same data-set with a different seed. Based on our findings, we suggest the Robust Adaptive Watermarking (RAW) Framework, which utilizes the unique behavior present in the protected and extracted models to generate a watermark key-set and verification model. We show that the framework is robust to (1) unseen model extraction attacks, and (2) extracted models which undergo a blurring method (e.g., weight pruning). We evaluate the framework's robustness against a naive attacker (unaware that the model is watermarked), and an informed attacker (who employs blurring strategies to remove watermarked behavior from an extracted model), and achieve outstanding (i.e., >0.9) AUC values. Finally, we show that the framework is robust to model extraction attacks with different structure and/or architecture than the protected model.
Attacking Object Detector Using A Universal Targeted Label-Switch Patch
Nov 16, 2022Adversarial attacks against deep learning-based object detectors (ODs) have been studied extensively in the past few years. These attacks cause the model to make incorrect predictions by placing a patch containing an adversarial pattern on the target object or anywhere within the frame. However, none of prior research proposed a misclassification attack on ODs, in which the patch is applied on the target object. In this study, we propose a novel, universal, targeted, label-switch attack against the state-of-the-art object detector, YOLO. In our attack, we use (i) a tailored projection function to enable the placement of the adversarial patch on multiple target objects in the image (e.g., cars), each of which may be located a different distance away from the camera or have a different view angle relative to the camera, and (ii) a unique loss function capable of changing the label of the attacked objects. The proposed universal patch, which is trained in the digital domain, is transferable to the physical domain. We performed an extensive evaluation using different types of object detectors, different video streams captured by different cameras, and various target classes, and evaluated different configurations of the adversarial patch in the physical domain.
Improving Interpretability via Regularization of Neural Activation Sensitivity
Nov 16, 2022



State-of-the-art deep neural networks (DNNs) are highly effective at tackling many real-world tasks. However, their wide adoption in mission-critical contexts is hampered by two major weaknesses - their susceptibility to adversarial attacks and their opaqueness. The former raises concerns about the security and generalization of DNNs in real-world conditions, whereas the latter impedes users' trust in their output. In this research, we (1) examine the effect of adversarial robustness on interpretability and (2) present a novel approach for improving the interpretability of DNNs that is based on regularization of neural activation sensitivity. We evaluate the interpretability of models trained using our method to that of standard models and models trained using state-of-the-art adversarial robustness techniques. Our results show that adversarially robust models are superior to standard models and that models trained using our proposed method are even better than adversarially robust models in terms of interpretability.
A Transferable and Automatic Tuning of Deep Reinforcement Learning for Cost Effective Phishing Detection
Sep 19, 2022
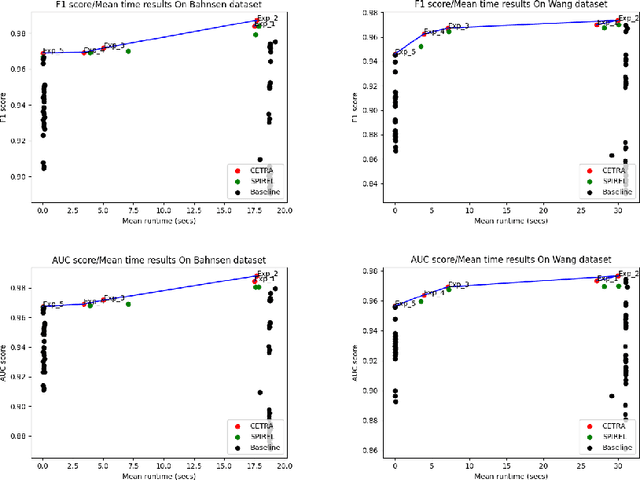
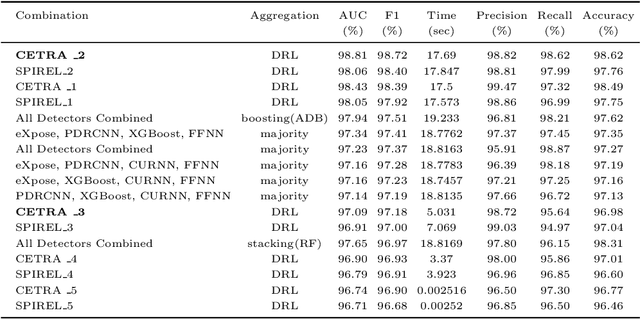
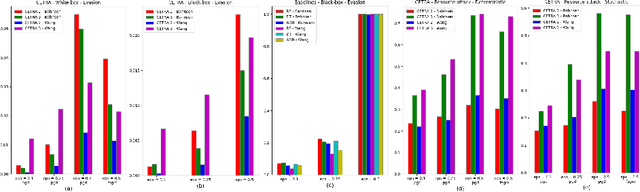
Many challenging real-world problems require the deployment of ensembles multiple complementary learning models to reach acceptable performance levels. While effective, applying the entire ensemble to every sample is costly and often unnecessary. Deep Reinforcement Learning (DRL) offers a cost-effective alternative, where detectors are dynamically chosen based on the output of their predecessors, with their usefulness weighted against their computational cost. Despite their potential, DRL-based solutions are not widely used in this capacity, partly due to the difficulties in configuring the reward function for each new task, the unpredictable reactions of the DRL agent to changes in the data, and the inability to use common performance metrics (e.g., TPR/FPR) to guide the algorithm's performance. In this study we propose methods for fine-tuning and calibrating DRL-based policies so that they can meet multiple performance goals. Moreover, we present a method for transferring effective security policies from one dataset to another. Finally, we demonstrate that our approach is highly robust against adversarial attacks.
Denial-of-Service Attack on Object Detection Model Using Universal Adversarial Perturbation
May 26, 2022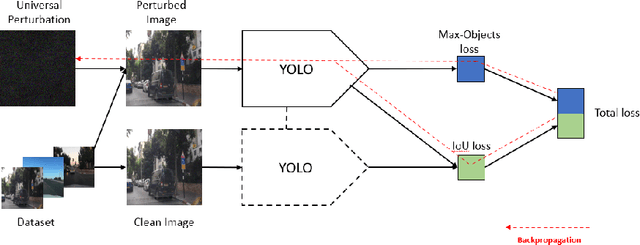
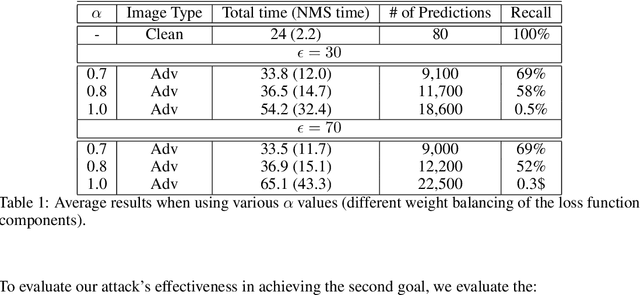
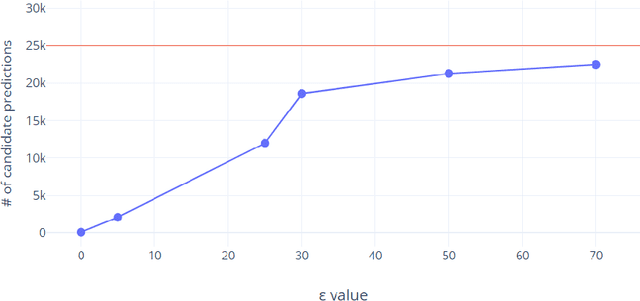
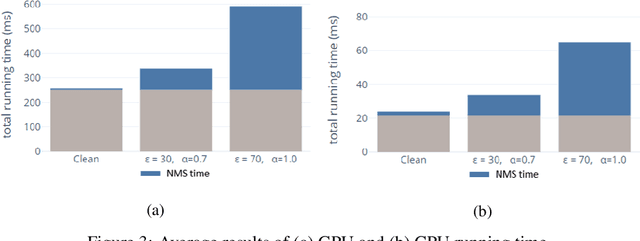
Adversarial attacks against deep learning-based object detectors have been studied extensively in the past few years. The proposed attacks aimed solely at compromising the models' integrity (i.e., trustworthiness of the model's prediction), while adversarial attacks targeting the models' availability, a critical aspect in safety-critical domains such as autonomous driving, have not been explored by the machine learning research community. In this paper, we propose NMS-Sponge, a novel approach that negatively affects the decision latency of YOLO, a state-of-the-art object detector, and compromises the model's availability by applying a universal adversarial perturbation (UAP). In our experiments, we demonstrate that the proposed UAP is able to increase the processing time of individual frames by adding "phantom" objects while preserving the detection of the original objects.
Adversarial Machine Learning Threat Analysis in Open Radio Access Networks
Jan 16, 2022
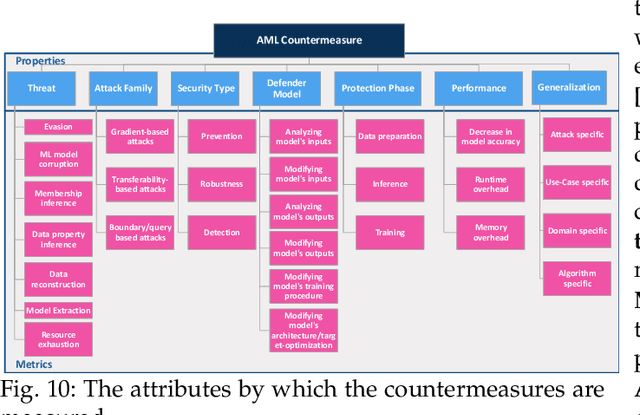

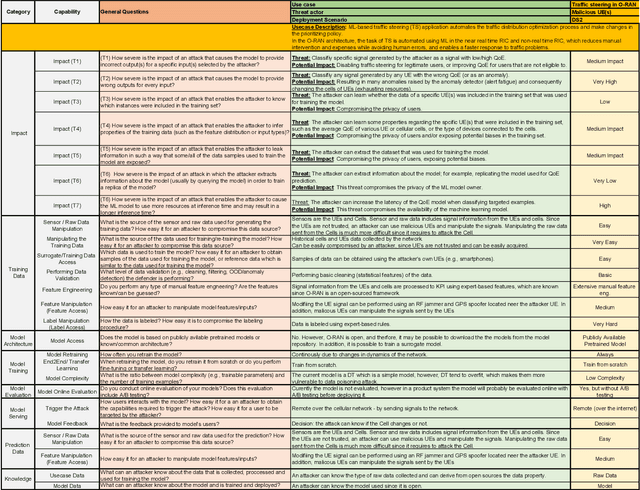
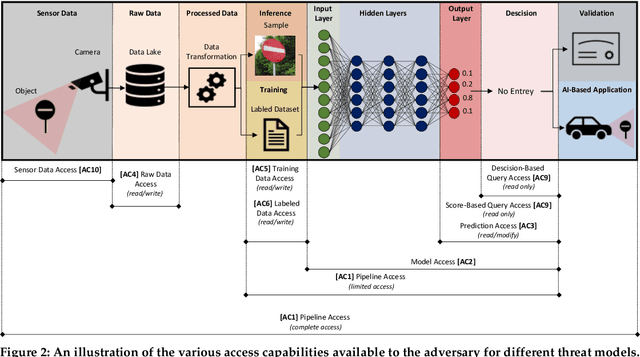
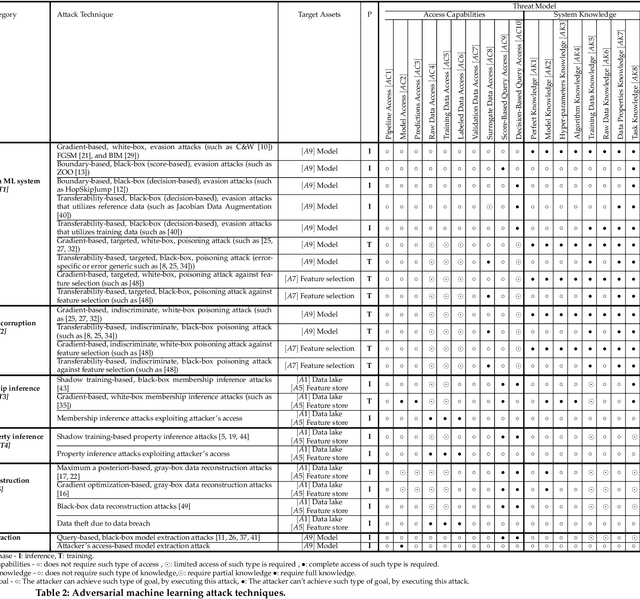
The Open Radio Access Network (O-RAN) is a new, open, adaptive, and intelligent RAN architecture. Motivated by the success of artificial intelligence in other domains, O-RAN strives to leverage machine learning (ML) to automatically and efficiently manage network resources in diverse use cases such as traffic steering, quality of experience prediction, and anomaly detection. Unfortunately, ML-based systems are not free of vulnerabilities; specifically, they suffer from a special type of logical vulnerabilities that stem from the inherent limitations of the learning algorithms. To exploit these vulnerabilities, an adversary can utilize an attack technique referred to as adversarial machine learning (AML). These special type of attacks has already been demonstrated in recent researches. In this paper, we present a systematic AML threat analysis for the O-RAN. We start by reviewing relevant ML use cases and analyzing the different ML workflow deployment scenarios in O-RAN. Then, we define the threat model, identifying potential adversaries, enumerating their adversarial capabilities, and analyzing their main goals. Finally, we explore the various AML threats in the O-RAN and review a large number of attacks that can be performed to materialize these threats and demonstrate an AML attack on a traffic steering model.
Adversarial Mask: Real-World Adversarial Attack Against Face Recognition Models
Nov 21, 2021
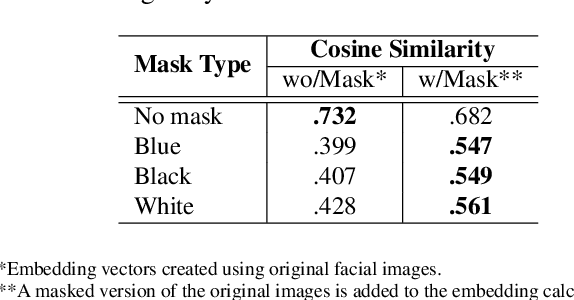
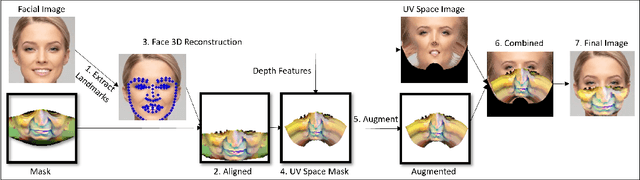
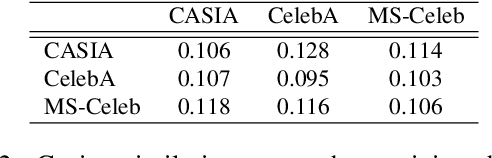
Deep learning-based facial recognition (FR) models have demonstrated state-of-the-art performance in the past few years, even when wearing protective medical face masks became commonplace during the COVID-19 pandemic. Given the outstanding performance of these models, the machine learning research community has shown increasing interest in challenging their robustness. Initially, researchers presented adversarial attacks in the digital domain, and later the attacks were transferred to the physical domain. However, in many cases, attacks in the physical domain are conspicuous, requiring, for example, the placement of a sticker on the face, and thus may raise suspicion in real-world environments (e.g., airports). In this paper, we propose Adversarial Mask, a physical adversarial universal perturbation (UAP) against state-of-the-art FR models that is applied on face masks in the form of a carefully crafted pattern. In our experiments, we examined the transferability of our adversarial mask to a wide range of FR model architectures and datasets. In addition, we validated our adversarial mask effectiveness in real-world experiments by printing the adversarial pattern on a fabric medical face mask, causing the FR system to identify only 3.34% of the participants wearing the mask (compared to a minimum of 83.34% with other evaluated masks).
Dodging Attack Using Carefully Crafted Natural Makeup
Sep 14, 2021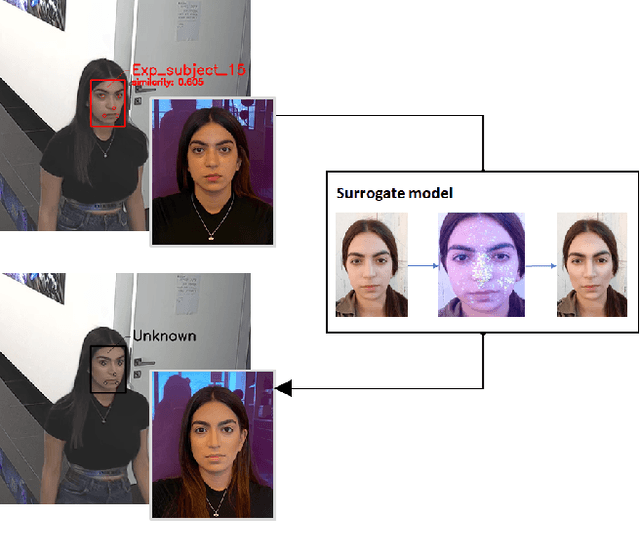

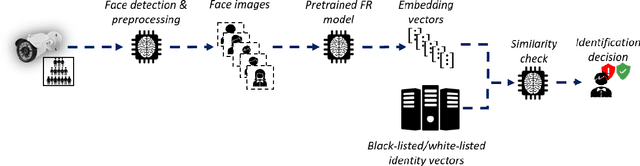
Deep learning face recognition models are used by state-of-the-art surveillance systems to identify individuals passing through public areas (e.g., airports). Previous studies have demonstrated the use of adversarial machine learning (AML) attacks to successfully evade identification by such systems, both in the digital and physical domains. Attacks in the physical domain, however, require significant manipulation to the human participant's face, which can raise suspicion by human observers (e.g. airport security officers). In this study, we present a novel black-box AML attack which carefully crafts natural makeup, which, when applied on a human participant, prevents the participant from being identified by facial recognition models. We evaluated our proposed attack against the ArcFace face recognition model, with 20 participants in a real-world setup that includes two cameras, different shooting angles, and different lighting conditions. The evaluation results show that in the digital domain, the face recognition system was unable to identify all of the participants, while in the physical domain, the face recognition system was able to identify the participants in only 1.22% of the frames (compared to 47.57% without makeup and 33.73% with random natural makeup), which is below a reasonable threshold of a realistic operational environment.
A Framework for Evaluating the Cybersecurity Risk of Real World, Machine Learning Production Systems
Jul 05, 2021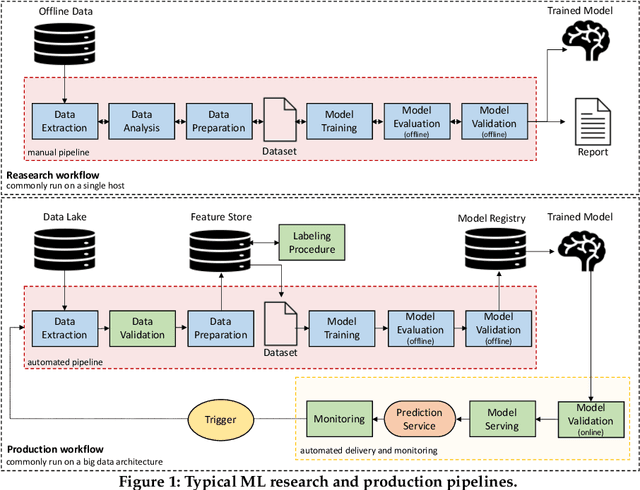

Although cyberattacks on machine learning (ML) production systems can be destructive, many industry practitioners are ill equipped, lacking tactical and strategic tools that would allow them to analyze, detect, protect against, and respond to cyberattacks targeting their ML-based systems. In this paper, we take a significant step toward securing ML production systems by integrating these systems and their vulnerabilities into cybersecurity risk assessment frameworks. Specifically, we performed a comprehensive threat analysis of ML production systems and developed an extension to the MulVAL attack graph generation and analysis framework to incorporate cyberattacks on ML production systems. Using the proposed extension, security practitioners can apply attack graph analysis methods in environments that include ML components, thus providing security experts with a practical tool for evaluating the impact and quantifying the risk of a cyberattack targeting an ML production system.
CAN-LOC: Spoofing Detection and Physical Intrusion Localization on an In-Vehicle CAN Bus Based on Deep Features of Voltage Signals
Jun 15, 2021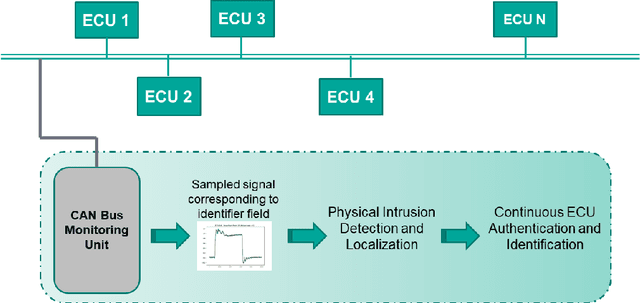

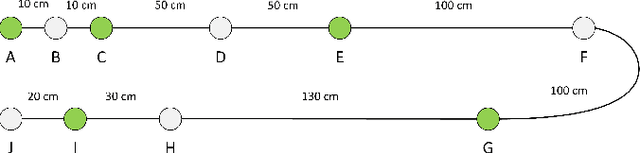
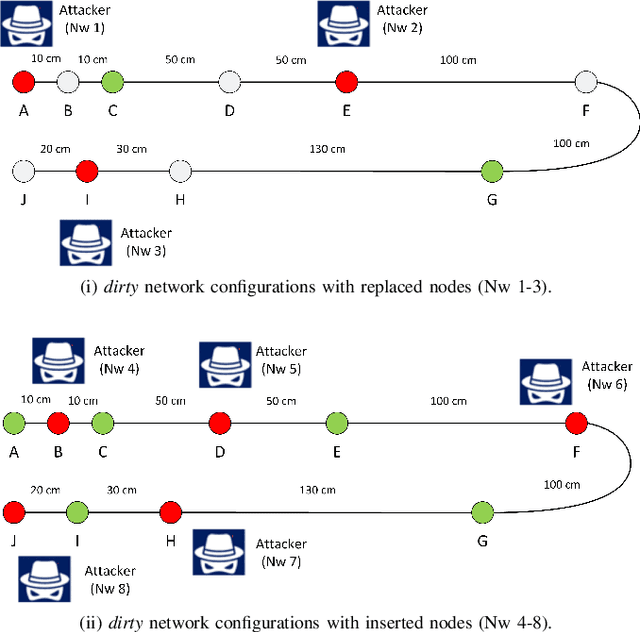
The Controller Area Network (CAN) is used for communication between in-vehicle devices. The CAN bus has been shown to be vulnerable to remote attacks. To harden vehicles against such attacks, vehicle manufacturers have divided in-vehicle networks into sub-networks, logically isolating critical devices. However, attackers may still have physical access to various sub-networks where they can connect a malicious device. This threat has not been adequately addressed, as methods proposed to determine physical intrusion points have shown weak results, emphasizing the need to develop more advanced techniques. To address this type of threat, we propose a security hardening system for in-vehicle networks. The proposed system includes two mechanisms that process deep features extracted from voltage signals measured on the CAN bus. The first mechanism uses data augmentation and deep learning to detect and locate physical intrusions when the vehicle starts; this mechanism can detect and locate intrusions, even when the connected malicious devices are silent. This mechanism's effectiveness (100% accuracy) is demonstrated in a wide variety of insertion scenarios on a CAN bus prototype. The second mechanism is a continuous device authentication mechanism, which is also based on deep learning; this mechanism's robustness (99.8% accuracy) is demonstrated on a real moving vehicle.