 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-domain Image Translative Diffusion StyleGAN for Iris Presentation Attack Detection
Oct 16, 2025An iris biometric system can be compromised by presentation attacks (PAs) where artifacts such as artificial eyes, printed eye images, or cosmetic contact lenses are presented to the system. To counteract this, several presentation attack detection (PAD) methods have been developed. However, there is a scarcity of datasets for training and evaluating iris PAD techniques due to the implicit difficulties in constructing and imaging PAs. To address this, we introduce the Multi-domain Image Translative Diffusion StyleGAN (MID-StyleGAN), a new framework for generating synthetic ocular images that captures the PA and bonafide characteristics in multiple domains such as bonafide, printed eyes and cosmetic contact lens. MID-StyleGAN combines the strengths of diffusion models and generative adversarial networks (GANs) to produce realistic and diverse synthetic data. Our approach utilizes a multi-domain architecture that enables the translation between bonafide ocular images and different PA domains. The model employs an adaptive loss function tailored for ocular data to maintain domain consistency. Extensive experiments demonstrate that MID-StyleGAN outperforms existing methods in generating high-quality synthetic ocular images. The generated data was used to significantly enhance the performance of PAD systems, providing a scalable solution to the data scarcity problem in iris and ocular biometrics. For example, on the LivDet2020 dataset, the true detect rate at 1% false detect rate improved from 93.41% to 98.72%, showcasing the impact of the proposed method.
Impact of Phonetics on Speaker Identity in Adversarial Voice Attack
Sep 18, 2025Adversarial perturbations in speech pose a serious threat to automatic speech recognition (ASR) and speaker verification by introducing subtle waveform modifications that remain imperceptible to humans but can significantly alter system outputs. While targeted attacks on end-to-end ASR models have been widely studied, the phonetic basis of these perturbations and their effect on speaker identity remain underexplored. In this work, we analyze adversarial audio at the phonetic level and show that perturbations exploit systematic confusions such as vowel centralization and consonant substitutions. These distortions not only mislead transcription but also degrade phonetic cues critical for speaker verification, leading to identity drift. Using DeepSpeech as our ASR target, we generate targeted adversarial examples and evaluate their impact on speaker embeddings across genuine and impostor samples. Results across 16 phonetically diverse target phrases demonstrate that adversarial audio induces both transcription errors and identity drift, highlighting the need for phonetic-aware defenses to ensure the robustness of ASR and speaker recognition systems.
Benchmarking Foundation Models for Zero-Shot Biometric Tasks
May 30, 2025The advent of foundation models, particularly Vision-Language Models (VLMs) and Multi-modal Large Language Models (MLLMs), has redefined the frontiers of artificial intelligence, enabling remarkable generalization across diverse tasks with minimal or no supervision. Yet, their potential in biometric recognition and analysis remains relatively underexplored. In this work, we introduce a comprehensive benchmark that evaluates the zero-shot and few-shot performance of state-of-the-art publicly available VLMs and MLLMs across six biometric tasks spanning the face and iris modalities: face verification, soft biometric attribute prediction (gender and race), iris recognition, presentation attack detection (PAD), and face manipulation detection (morphs and deepfakes). A total of 41 VLMs were used in this evaluation. Experiments show that embeddings from these foundation models can be used for diverse biometric tasks with varying degrees of success. For example, in the case of face verification, a True Match Rate (TMR) of 96.77 percent was obtained at a False Match Rate (FMR) of 1 percent on the Labeled Face in the Wild (LFW) dataset, without any fine-tuning. In the case of iris recognition, the TMR at 1 percent FMR on the IITD-R-Full dataset was 97.55 percent without any fine-tuning. Further, we show that applying a simple classifier head to these embeddings can help perform DeepFake detection for faces, Presentation Attack Detection (PAD) for irides, and extract soft biometric attributes like gender and ethnicity from faces with reasonably high accuracy. This work reiterates the potential of pretrained models in achieving the long-term vision of Artificial General Intelligence.
diffDemorph: Extending Reference-Free Demorphing to Unseen Faces
May 20, 2025A face morph is created by combining two (or more) face images corresponding to two (or more) identities to produce a composite that successfully matches the constituent identities. Reference-free (RF) demorphing reverses this process using only the morph image, without the need for additional reference images. Previous RF demorphing methods were overly constrained, as they rely on assumptions about the distributions of training and testing morphs such as the morphing technique used, face style, and images used to create the morph. In this paper, we introduce a novel diffusion-based approach that effectively disentangles component images from a composite morph image with high visual fidelity. Our method is the first to generalize across morph techniques and face styles, beating the current state of the art by $\geq 59.46\%$ under a common training protocol across all datasets tested. We train our method on morphs created using synthetically generated face images and test on real morphs, thereby enhancing the practicality of the technique. Experiments on six datasets and two face matchers establish the utility and efficacy of our method.
Person Recognition at Altitude and Range: Fusion of Face, Body Shape and Gait
May 07, 2025
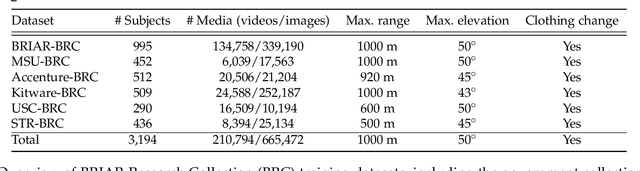

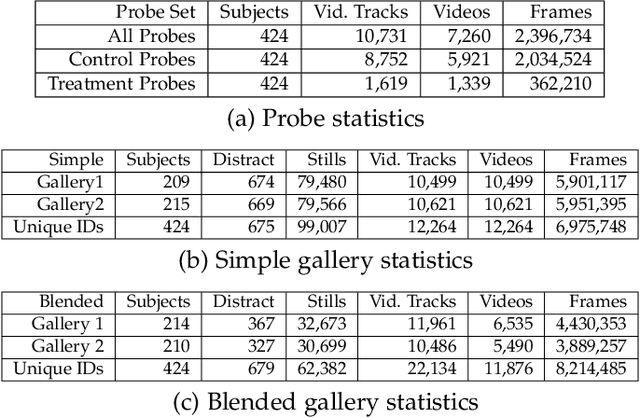
We address the problem of whole-body person recognition in unconstrained environments. This problem arises in surveillance scenarios such as those in the IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) program, where biometric data is captured at long standoff distances, elevated viewing angles, and under adverse atmospheric conditions (e.g., turbulence and high wind velocity). To this end, we propose FarSight, a unified end-to-end system for person recognition that integrates complementary biometric cues across face, gait, and body shape modalities. FarSight incorporates novel algorithms across four core modules: multi-subject detection and tracking, recognition-aware video restoration, modality-specific biometric feature encoding, and quality-guided multi-modal fusion. These components are designed to work cohesively under degraded image conditions, large pose and scale variations, and cross-domain gaps. Extensive experiments on the BRIAR dataset, one of the most comprehensive benchmarks for long-range, multi-modal biometric recognition, demonstrate the effectiveness of FarSight. Compared to our preliminary system, this system achieves a 34.1% absolute gain in 1:1 verification accuracy (TAR@0.1% FAR), a 17.8% increase in closed-set identification (Rank-20), and a 34.3% reduction in open-set identification errors (FNIR@1% FPIR). Furthermore, FarSight was evaluated in the 2025 NIST RTE Face in Video Evaluation (FIVE), which conducts standardized face recognition testing on the BRIAR dataset. These results establish FarSight as a state-of-the-art solution for operational biometric recognition in challenging real-world conditions.
Task-conditioned Ensemble of Expert Models for Continuous Learning
Apr 14, 2025



One of the major challenges in machine learning is maintaining the accuracy of the deployed model (e.g., a classifier) in a non-stationary environment. The non-stationary environment results in distribution shifts and, consequently, a degradation in accuracy. Continuous learning of the deployed model with new data could be one remedy. However, the question arises as to how we should update the model with new training data so that it retains its accuracy on the old data while adapting to the new data. In this work, we propose a task-conditioned ensemble of models to maintain the performance of the existing model. The method involves an ensemble of expert models based on task membership information. The in-domain models-based on the local outlier concept (different from the expert models) provide task membership information dynamically at run-time to each probe sample. To evaluate the proposed method, we experiment with three setups: the first represents distribution shift between tasks (LivDet-Iris-2017), the second represents distribution shift both between and within tasks (LivDet-Iris-2020), and the third represents disjoint distribution between tasks (Split MNIST). The experiments highlight the benefits of the proposed method. The source code is available at https://github.com/iPRoBe-lab/Continuous_Learning_FE_DM.
Metric for Evaluating Performance of Reference-Free Demorphing Methods
Jan 21, 2025A facial morph is an image created by combining two (or more) face images pertaining to two (or more) distinct identities. Reference-free face demorphing inverts the process and tries to recover the face images constituting a facial morph without using any other information. However, there is no consensus on the evaluation metrics to be used to evaluate and compare such demorphing techniques. In this paper, we first analyze the shortcomings of the demorphing metrics currently used in the literature. We then propose a new metric called biometrically cross-weighted IQA that overcomes these issues and extensively benchmark current methods on the proposed metric to show its efficacy. Experiments on three existing demorphing methods and six datasets on two commonly used face matchers validate the efficacy of our proposed metric.
A Parametric Approach to Adversarial Augmentation for Cross-Domain Iris Presentation Attack Detection
Dec 10, 2024Iris-based biometric systems are vulnerable to presentation attacks (PAs), where adversaries present physical artifacts (e.g., printed iris images, textured contact lenses) to defeat the system. This has led to the development of various presentation attack detection (PAD) algorithms, which typically perform well in intra-domain settings. However, they often struggle to generalize effectively in cross-domain scenarios, where training and testing employ different sensors, PA instruments, and datasets. In this work, we use adversarial training samples of both bonafide irides and PAs to improve the cross-domain performance of a PAD classifier. The novelty of our approach lies in leveraging transformation parameters from classical data augmentation schemes (e.g., translation, rotation) to generate adversarial samples. We achieve this through a convolutional autoencoder, ADV-GEN, that inputs original training samples along with a set of geometric and photometric transformations. The transformation parameters act as regularization variables, guiding ADV-GEN to generate adversarial samples in a constrained search space. Experiments conducted on the LivDet-Iris 2017 database, comprising four datasets, and the LivDet-Iris 2020 dataset, demonstrate the efficacy of our proposed method. The code is available at https://github.com/iPRoBe-lab/ADV-GEN-IrisPAD.
dc-GAN: Dual-Conditioned GAN for Face Demorphing From a Single Morph
Nov 20, 2024



A facial morph is an image created by combining two face images pertaining to two distinct identities. Face demorphing inverts the process and tries to recover the original images constituting a facial morph. While morph attack detection (MAD) techniques can be used to flag morph images, they do not divulge any visual information about the faces used to create them. Demorphing helps address this problem. Existing demorphing techniques are either very restrictive (assume identities during testing) or produce feeble outputs (both outputs look very similar). In this paper, we overcome these issues by proposing dc-GAN, a novel GAN-based demorphing method conditioned on the morph images. Our method overcomes morph-replication and produces high quality reconstructions of the bonafide images used to create the morphs. Moreover, our method is highly generalizable across demorphing paradigms (differential/reference-free). We conduct experiments on AMSL, FRLL-Morphs and MorDiff datasets to showcase the efficacy of our method.
On Missing Scores in Evolving Multibiometric Systems
Aug 21, 2024



The use of multiple modalities (e.g., face and fingerprint) or multiple algorithms (e.g., three face comparators) has shown to improve the recognition accuracy of an operational biometric system. Over time a biometric system may evolve to add new modalities, retire old modalities, or be merged with other biometric systems. This can lead to scenarios where there are missing scores corresponding to the input probe set. Previous work on this topic has focused on either the verification or identification tasks, but not both. Further, the proportion of missing data considered has been less than 50%. In this work, we study the impact of missing score data for both the verification and identification tasks. We show that the application of various score imputation methods along with simple sum fusion can improve recognition accuracy, even when the proportion of missing scores increases to 90%. Experiments show that fusion after score imputation outperforms fusion with no imputation. Specifically, iterative imputation with K nearest neighbors consistently surpasses other imputation methods in both the verification and identification tasks, regardless of the amount of scores missing, and provides imputed values that are consistent with the ground truth complete dataset.