 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Mean Embedding Approach for Back-door and Front-door Adjustment
Oct 12, 2022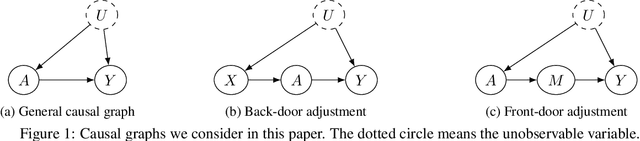
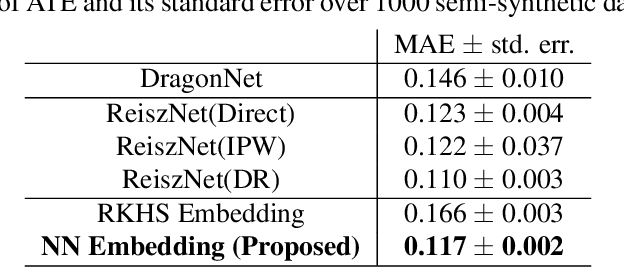
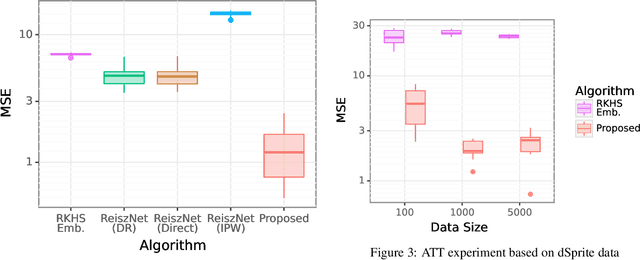
We consider the estimation of average and counterfactual treatment effects, under two settings: back-door adjustment and front-door adjustment. The goal in both cases is to recover the treatment effect without having an access to a hidden confounder. This objective is attained by first estimating the conditional mean of the desired outcome variable given relevant covariates (the "first stage" regression), and then taking the (conditional) expectation of this function as a "second stage" procedure. We propose to compute these conditional expectations directly using a regression function to the learned input features of the first stage, thus avoiding the need for sampling or density estimation. All functions and features (and in particular, the output features in the second stage) are neural networks learned adaptively from data, with the sole requirement that the final layer of the first stage should be linear. The proposed method is shown to converge to the true causal parameter, and outperforms the recent state-of-the-art methods on challenging causal benchmarks, including settings involving high-dimensional image data.
Optimal Rates for Regularized Conditional Mean Embedding Learning
Aug 02, 2022We address the consistency of a kernel ridge regression estimate of the conditional mean embedding (CME), which is an embedding of the conditional distribution of $Y$ given $X$ into a target reproducing kernel Hilbert space $\mathcal{H}_Y$. The CME allows us to take conditional expectations of target RKHS functions, and has been employed in nonparametric causal and Bayesian inference. We address the misspecified setting, where the target CME is in the space of Hilbert-Schmidt operators acting from an input interpolation space between $\mathcal{H}_X$ and $L_2$, to $\mathcal{H}_Y$. This space of operators is shown to be isomorphic to a newly defined vector-valued interpolation space. Using this isomorphism, we derive a novel and adaptive statistical learning rate for the empirical CME estimator under the misspecified setting. Our analysis reveals that our rates match the optimal $O(\log n / n)$ rates without assuming $\mathcal{H}_Y$ to be finite dimensional. We further establish a lower bound on the learning rate, which shows that the obtained upper bound is optimal.
Discussion of `Multiscale Fisher's Independence Test for Multivariate Dependence'
Jun 22, 2022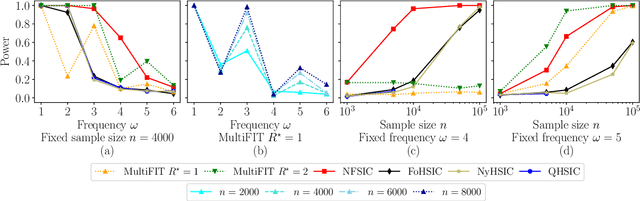
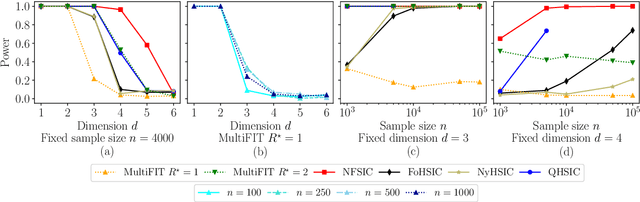
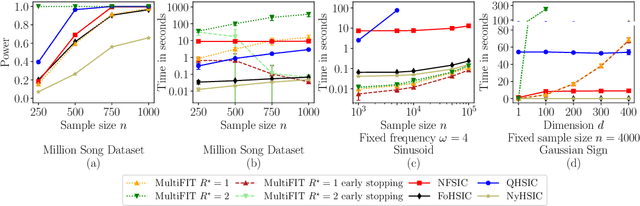
We discuss how MultiFIT, the Multiscale Fisher's Independence Test for Multivariate Dependence proposed by Gorsky and Ma (2022), compares to existing linear-time kernel tests based on the Hilbert-Schmidt independence criterion (HSIC). We highlight the fact that the levels of the kernel tests at any finite sample size can be controlled exactly, as it is the case with the level of MultiFIT. In our experiments, we observe some of the performance limitations of MultiFIT in terms of test power.
Efficient Aggregated Kernel Tests using Incomplete $U$-statistics
Jun 18, 2022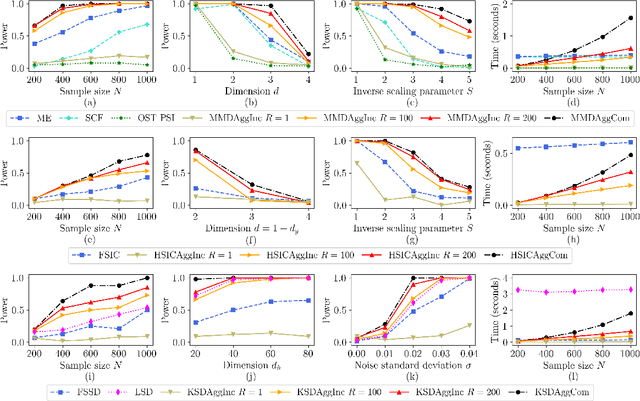
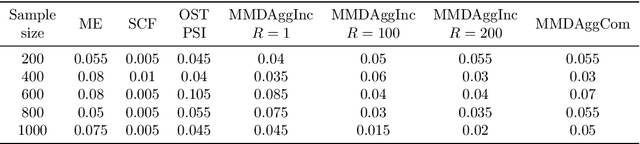


We propose a series of computationally efficient, nonparametric tests for the two-sample, independence and goodness-of-fit problems, using the Maximum Mean Discrepancy (MMD), Hilbert Schmidt Independence Criterion (HSIC), and Kernel Stein Discrepancy (KSD), respectively. Our test statistics are incomplete $U$-statistics, with a computational cost that interpolates between linear time in the number of samples, and quadratic time, as associated with classical $U$-statistic tests. The three proposed tests aggregate over several kernel bandwidths to detect departures from the null on various scales: we call the resulting tests MMDAggInc, HSICAggInc and KSDAggInc. For the test thresholds, we derive a quantile bound for wild bootstrapped incomplete $U$- statistics, which is of independent interest. We derive uniform separation rates for MMDAggInc and HSICAggInc, and quantify exactly the trade-off between computational efficiency and the attainable rates: this result is novel for tests based on incomplete $U$-statistics, to our knowledge. We further show that in the quadratic-time case, the wild bootstrap incurs no penalty to test power over more widespread permutation-based approaches, since both attain the same minimax optimal rates (which in turn match the rates that use oracle quantiles). We support our claims with numerical experiments on the trade-off between computational efficiency and test power. In the three testing frameworks, we observe that our proposed linear-time aggregated tests obtain higher power than current state-of-the-art linear-time kernel tests.
Causal Inference with Treatment Measurement Error: A Nonparametric Instrumental Variable Approach
Jun 18, 2022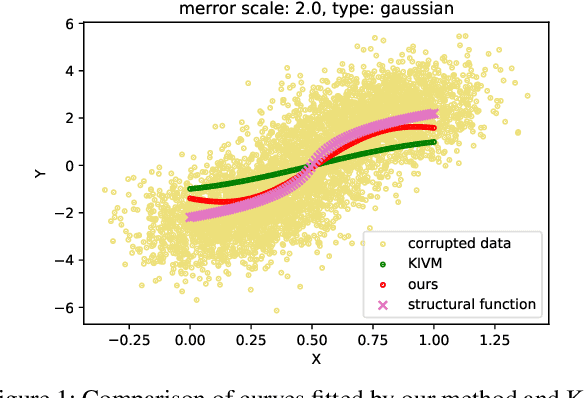
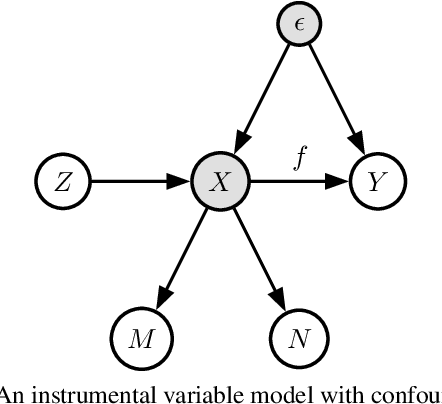
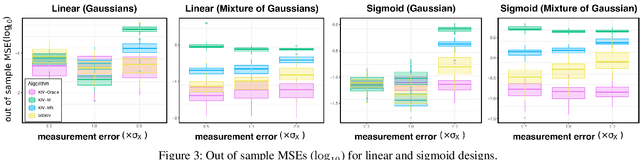
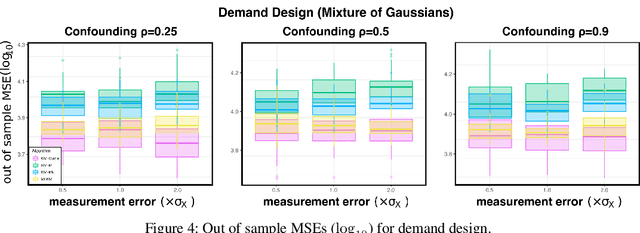
We propose a kernel-based nonparametric estimator for the causal effect when the cause is corrupted by error. We do so by generalizing estimation in the instrumental variable setting. Despite significant work on regression with measurement error, additionally handling unobserved confounding in the continuous setting is non-trivial: we have seen little prior work. As a by-product of our investigation, we clarify a connection between mean embeddings and characteristic functions, and how learning one simultaneously allows one to learn the other. This opens the way for kernel method research to leverage existing results in characteristic function estimation. Finally, we empirically show that our proposed method, MEKIV, improves over baselines and is robust under changes in the strength of measurement error and to the type of error distributions.
Deep Layer-wise Networks Have Closed-Form Weights
Feb 07, 2022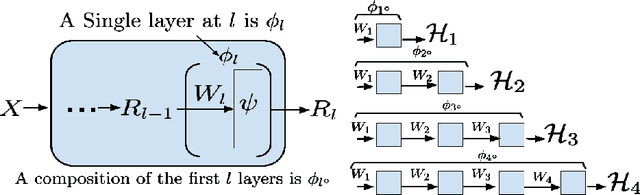
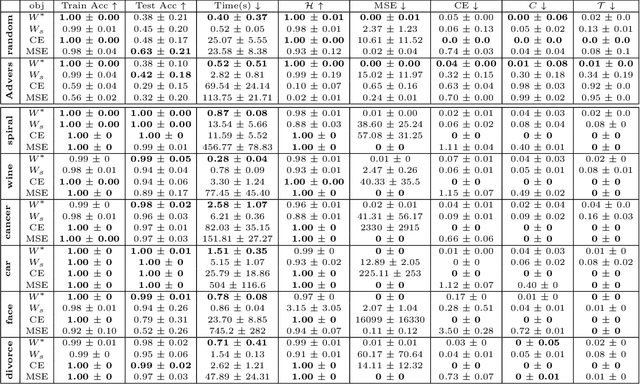
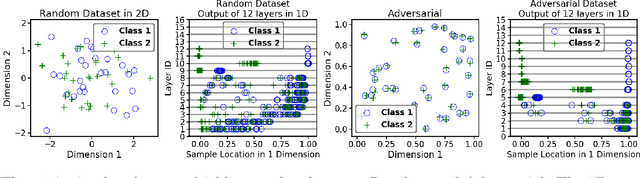
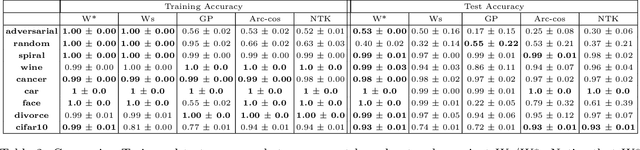
There is currently a debate within the neuroscience community over the likelihood of the brain performing backpropagation (BP). To better mimic the brain, training a network \textit{one layer at a time} with only a "single forward pass" has been proposed as an alternative to bypass BP; we refer to these networks as "layer-wise" networks. We continue the work on layer-wise networks by answering two outstanding questions. First, $\textit{do they have a closed-form solution?}$ Second, $\textit{how do we know when to stop adding more layers?}$ This work proves that the Kernel Mean Embedding is the closed-form weight that achieves the network global optimum while driving these networks to converge towards a highly desirable kernel for classification; we call it the $\textit{Neural Indicator Kernel}$.
* Since this version is similar to an older version, I should have updated the older version instead of creating a new version. I will now retract this version, and update a previous version to this. See arXiv:2006.08539
Importance Weighting Approach in Kernel Bayes' Rule
Feb 05, 2022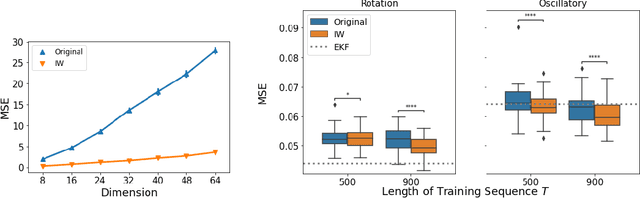
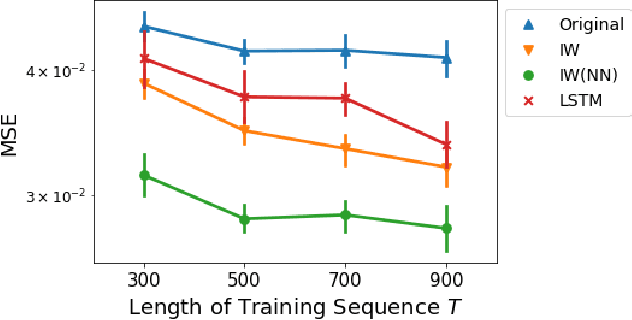
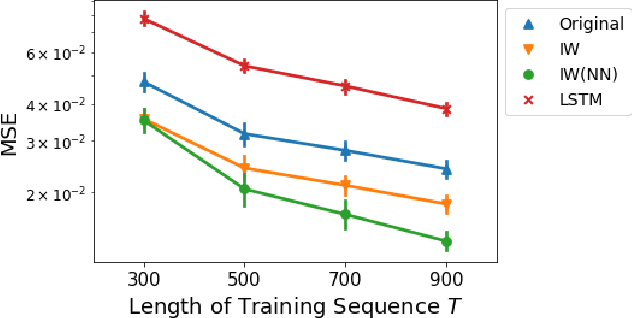
We study a nonparametric approach to Bayesian computation via feature means, where the expectation of prior features is updated to yield expected posterior features, based on regression from kernel or neural net features of the observations. All quantities involved in the Bayesian update are learned from observed data, making the method entirely model-free. The resulting algorithm is a novel instance of a kernel Bayes' rule (KBR). Our approach is based on importance weighting, which results in superior numerical stability to the existing approach to KBR, which requires operator inversion. We show the convergence of the estimator using a novel consistency analysis on the importance weighting estimator in the infinity norm. We evaluate our KBR on challenging synthetic benchmarks, including a filtering problem with a state-space model involving high dimensional image observations. The proposed method yields uniformly better empirical performance than the existing KBR, and competitive performance with other competing methods.
KSD Aggregated Goodness-of-fit Test
Feb 03, 2022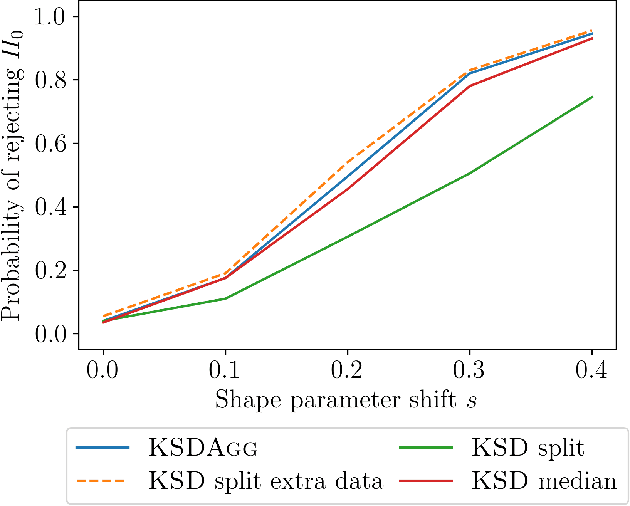
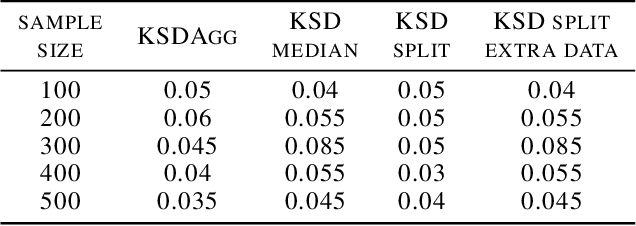
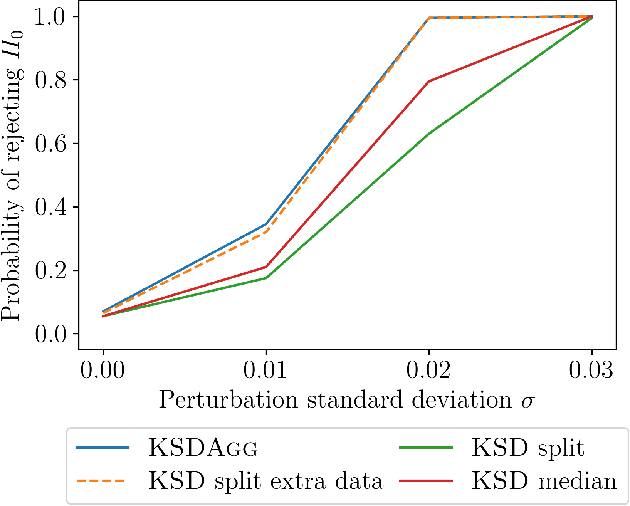

We investigate properties of goodness-of-fit tests based on the Kernel Stein Discrepancy (KSD). We introduce a strategy to construct a test, called KSDAgg, which aggregates multiple tests with different kernels. KSDAgg avoids splitting the data to perform kernel selection (which leads to a loss in test power), and rather maximises the test power over a collection of kernels. We provide theoretical guarantees on the power of KSDAgg: we show it achieves the smallest uniform separation rate of the collection, up to a logarithmic term. KSDAgg can be computed exactly in practice as it relies either on a parametric bootstrap or on a wild bootstrap to estimate the quantiles and the level corrections. In particular, for the crucial choice of bandwidth of a fixed kernel, it avoids resorting to arbitrary heuristics (such as median or standard deviation) or to data splitting. We find on both synthetic and real-world data that KSDAgg outperforms other state-of-the-art adaptive KSD-based goodness-of-fit testing procedures.
Composite Goodness-of-fit Tests with Kernels
Nov 19, 2021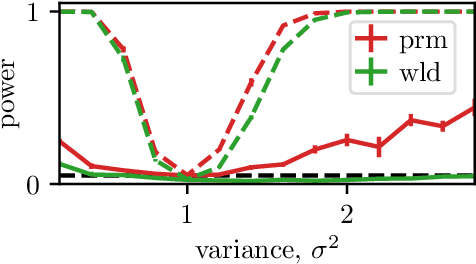
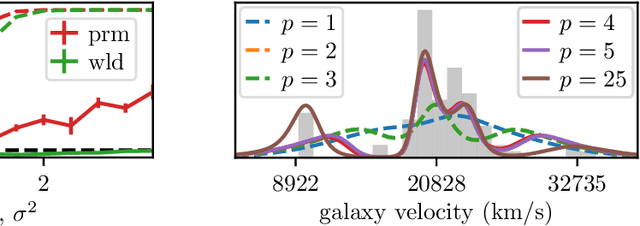
Model misspecification can create significant challenges for the implementation of probabilistic models, and this has led to development of a range of inference methods which directly account for this issue. However, whether these more involved methods are required will depend on whether the model is really misspecified, and there is a lack of generally applicable methods to answer this question. One set of tools which can help are goodness-of-fit tests, where we test whether a dataset could have been generated by a fixed distribution. Kernel-based tests have been developed to for this problem, and these are popular due to their flexibility, strong theoretical guarantees and ease of implementation in a wide range of scenarios. In this paper, we extend this line of work to the more challenging composite goodness-of-fit problem, where we are instead interested in whether the data comes from any distribution in some parametric family. This is equivalent to testing whether a parametric model is well-specified for the data.
Kernel Methods for Multistage Causal Inference: Mediation Analysis and Dynamic Treatment Effects
Nov 06, 2021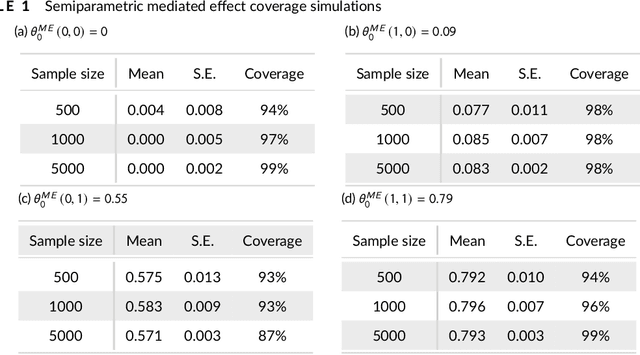
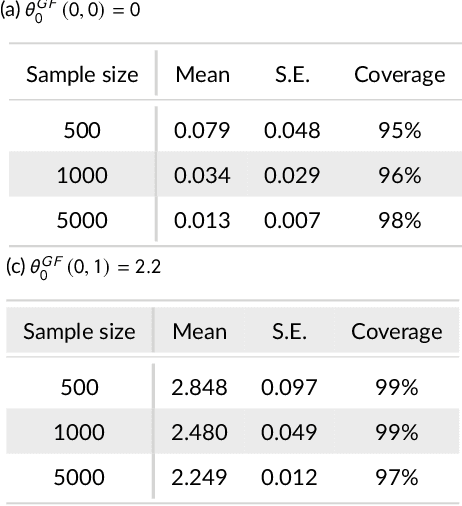
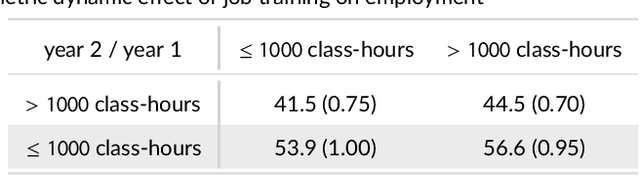
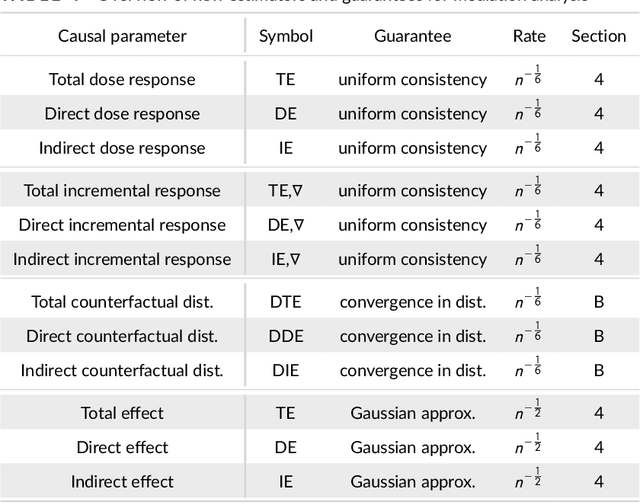
We propose kernel ridge regression estimators for mediation analysis and dynamic treatment effects over short horizons. We allow treatments, covariates, and mediators to be discrete or continuous, and low, high, or infinite dimensional. We propose estimators of means, increments, and distributions of counterfactual outcomes with closed form solutions in terms of kernel matrix operations. For the continuous treatment case, we prove uniform consistency with finite sample rates. For the discrete treatment case, we prove root-n consistency, Gaussian approximation, and semiparametric efficiency. We conduct simulations then estimate mediated and dynamic treatment effects of the US Job Corps program for disadvantaged youth.