 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMITI Minimum Information guidelines for highly multiplexed tissue images
Aug 21, 2021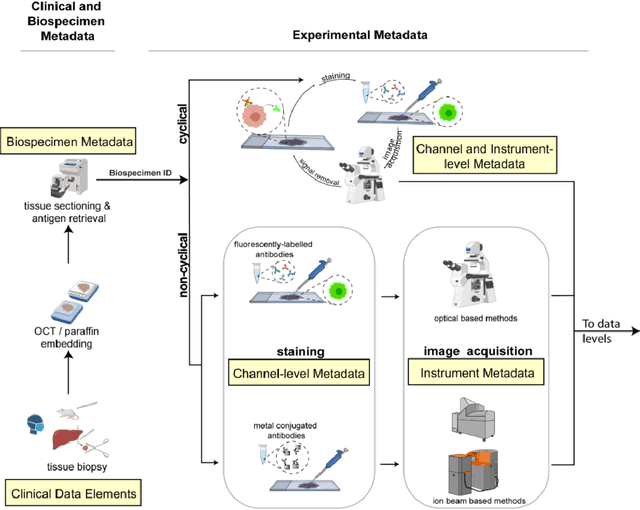
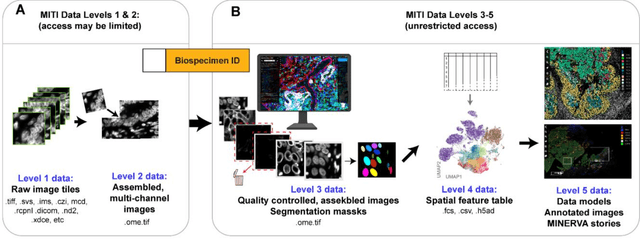
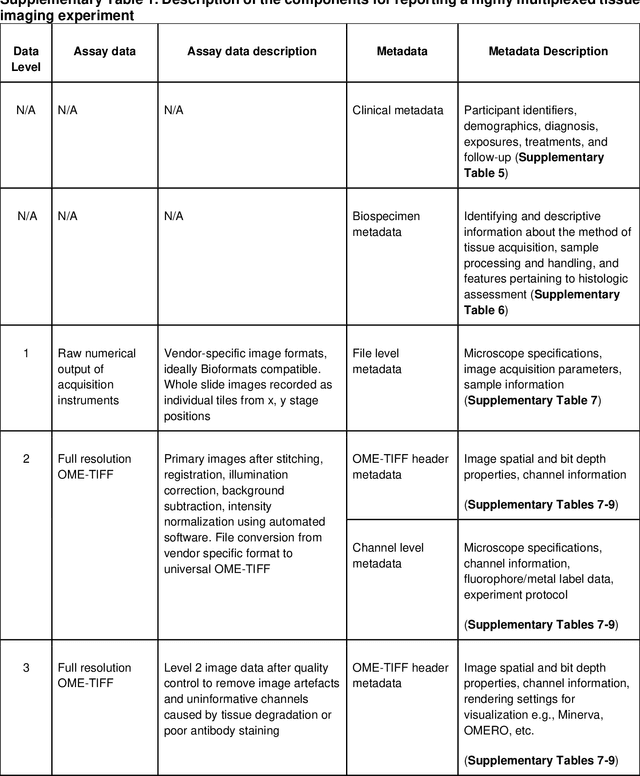
The imminent release of atlases combining highly multiplexed tissue imaging with single cell sequencing and other omics data from human tissues and tumors creates an urgent need for data and metadata standards compliant with emerging and traditional approaches to histology. We describe the development of a Minimum Information about highly multiplexed Tissue Imaging (MITI) standard that draws on best practices from genomics and microscopy of cultured cells and model organisms.
On the Impact of Word Error Rate on Acoustic-Linguistic Speech Emotion Recognition: An Update for the Deep Learning Era
Apr 20, 2021
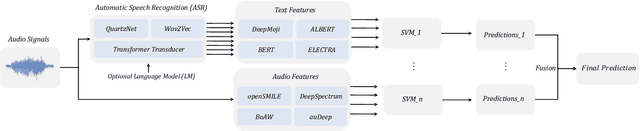
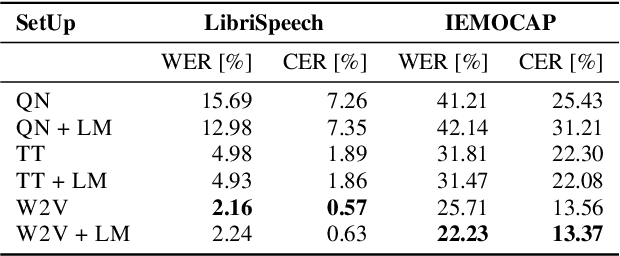

Text encodings from automatic speech recognition (ASR) transcripts and audio representations have shown promise in speech emotion recognition (SER) ever since. Yet, it is challenging to explain the effect of each information stream on the SER systems. Further, more clarification is required for analysing the impact of ASR's word error rate (WER) on linguistic emotion recognition per se and in the context of fusion with acoustic information exploitation in the age of deep ASR systems. In order to tackle the above issues, we create transcripts from the original speech by applying three modern ASR systems, including an end-to-end model trained with recurrent neural network-transducer loss, a model with connectionist temporal classification loss, and a wav2vec framework for self-supervised learning. Afterwards, we use pre-trained textual models to extract text representations from the ASR outputs and the gold standard. For extraction and learning of acoustic speech features, we utilise openSMILE, openXBoW, DeepSpectrum, and auDeep. Finally, we conduct decision-level fusion on both information streams -- acoustics and linguistics. Using the best development configuration, we achieve state-of-the-art unweighted average recall values of $73.6\,\%$ and $73.8\,\%$ on the speaker-independent development and test partitions of IEMOCAP, respectively.
Real-time Streaming Wave-U-Net with Temporal Convolutions for Multichannel Speech Enhancement
Apr 05, 2021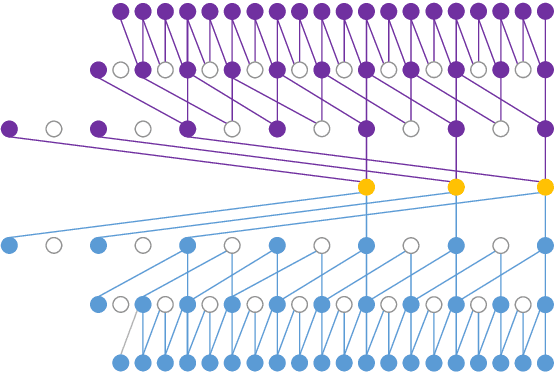
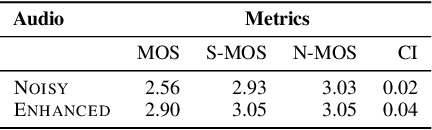
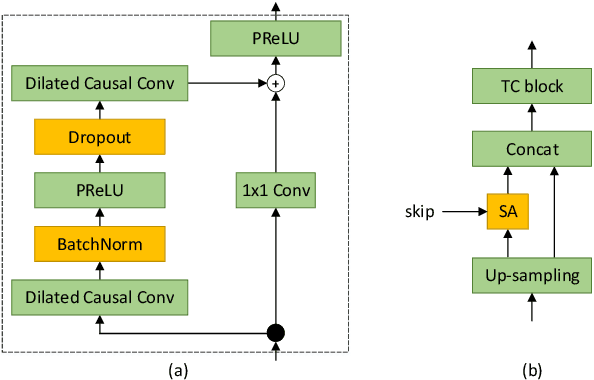

In this paper, we describe the work that we have done to participate in Task1 of the ConferencingSpeech2021 challenge. This task set a goal to develop the solution for multi-channel speech enhancement in a real-time manner. We propose a novel system for streaming speech enhancement. We employ Wave-U-Net architecture with temporal convolutions in encoder and decoder. We incorporate self-attention in the decoder to apply attention mask retrieved from skip-connection on features from down-blocks. We explore history cache mechanisms that work like hidden states in recurrent networks and implemented them in proposal solution. It helps us to run an inference with chunks length 40ms and Real-Time Factor 0.4 with the same precision.
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Mar 22, 2021
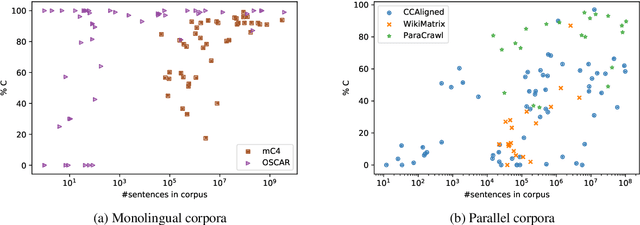

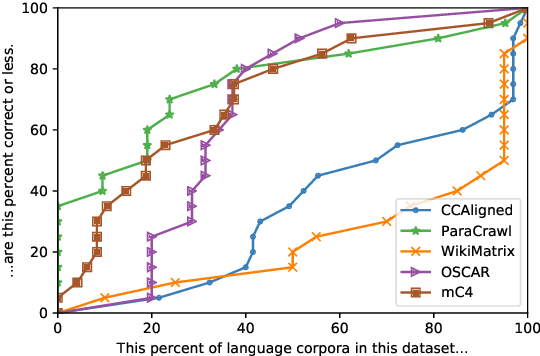
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.
Sparse Perturbations for Improved Convergence in Stochastic Zeroth-Order Optimization
Jun 29, 2020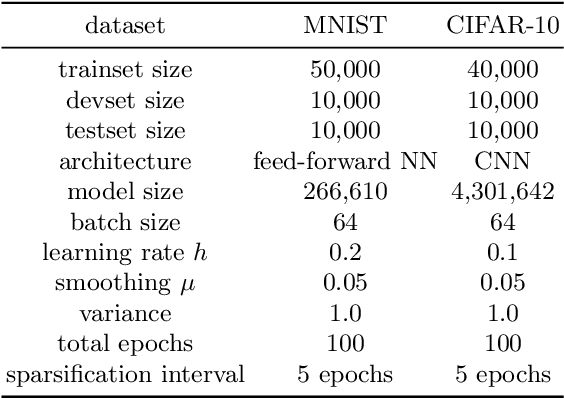
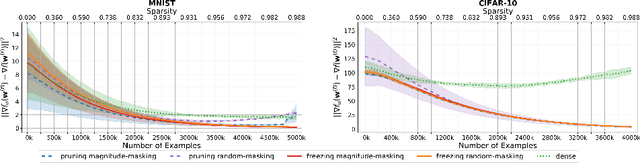
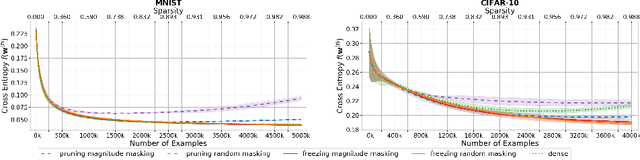
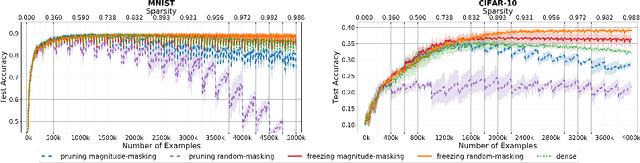
Interest in stochastic zeroth-order (SZO) methods has recently been revived in black-box optimization scenarios such as adversarial black-box attacks to deep neural networks. SZO methods only require the ability to evaluate the objective function at random input points, however, their weakness is the dependency of their convergence speed on the dimensionality of the function to be evaluated. We present a sparse SZO optimization method that reduces this factor to the expected dimensionality of the random perturbation during learning. We give a proof that justifies this reduction for sparse SZO optimization for non-convex functions without making any assumptions on sparsity of objective function or gradient. Furthermore, we present experimental results for neural networks on MNIST and CIFAR that show faster convergence in training loss and test accuracy, and a smaller distance of the gradient approximation to the true gradient in sparse SZO compared to dense SZO.
Learning to Segment Inputs for NMT Favors Character-Level Processing
Nov 05, 2018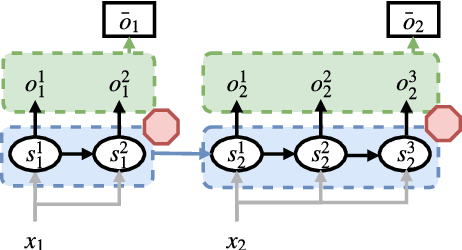
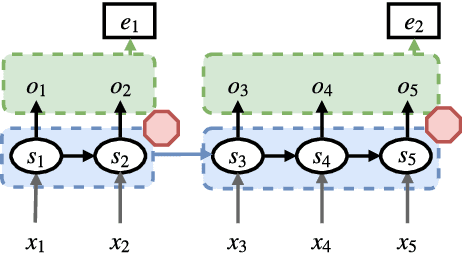
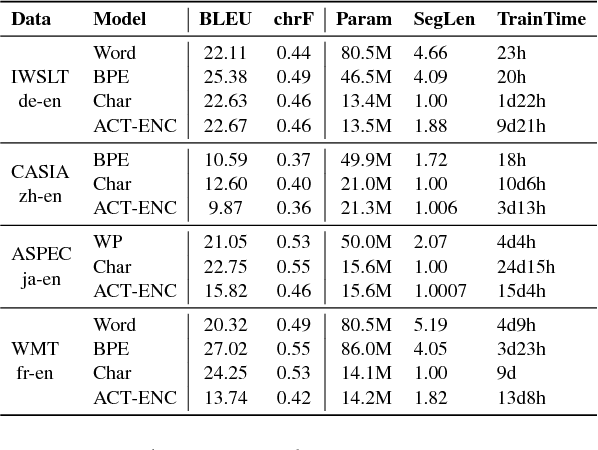
Most modern neural machine translation (NMT) systems rely on presegmented inputs. Segmentation granularity importantly determines the input and output sequence lengths, hence the modeling depth, and source and target vocabularies, which in turn determine model size, computational costs of softmax normalization, and handling of out-of-vocabulary words. However, the current practice is to use static, heuristic-based segmentations that are fixed before NMT training. This begs the question whether the chosen segmentation is optimal for the translation task. To overcome suboptimal segmentation choices, we present an algorithm for dynamic segmentation based on the Adaptative Computation Time algorithm (Graves 2016), that is trainable end-to-end and driven by the NMT objective. In an evaluation on four translation tasks we found that, given the freedom to navigate between different segmentation levels, the model prefers to operate on (almost) character level, providing support for purely character-level NMT models from a novel angle.
Sparse Stochastic Zeroth-Order Optimization with an Application to Bandit Structured Prediction
Jul 31, 2018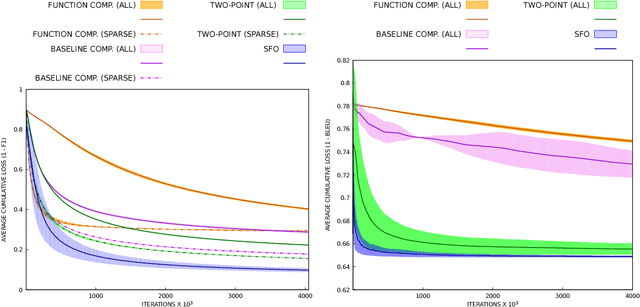
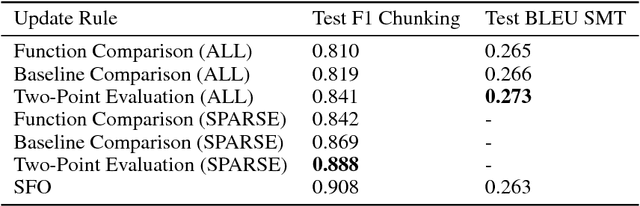
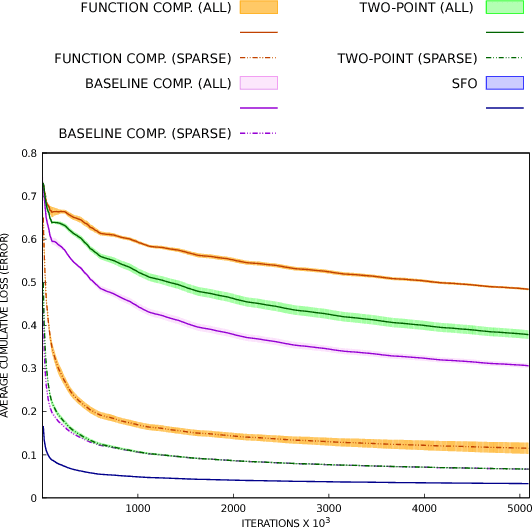
Stochastic zeroth-order (SZO), or gradient-free, optimization allows to optimize arbitrary functions by relying only on function evaluations under parameter perturbations, however, the iteration complexity of SZO methods suffers a factor proportional to the dimensionality of the perturbed function. We show that in scenarios with natural sparsity patterns as in structured prediction applications, this factor can be reduced to the expected number of active features over input-output pairs. We give a general proof that applies sparse SZO optimization to Lipschitz-continuous, nonconvex, stochastic objectives, and present an experimental evaluation on linear bandit structured prediction tasks with sparse word-based feature representations that confirm our theoretical results.
Sockeye: A Toolkit for Neural Machine Translation
Jun 01, 2018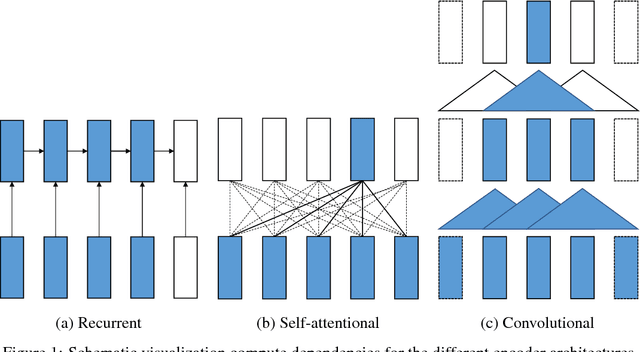
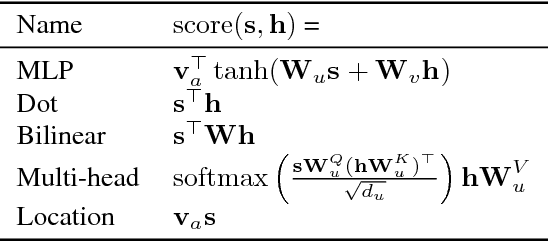

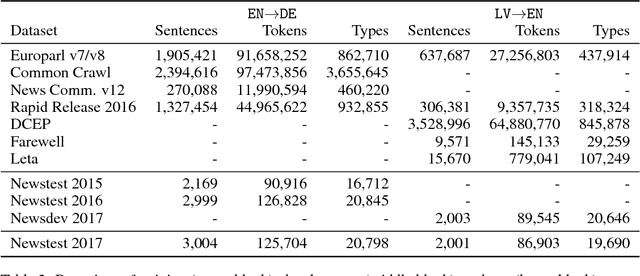
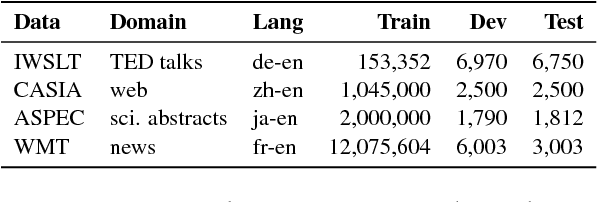
We describe Sockeye (version 1.12), an open-source sequence-to-sequence toolkit for Neural Machine Translation (NMT). Sockeye is a production-ready framework for training and applying models as well as an experimental platform for researchers. Written in Python and built on MXNet, the toolkit offers scalable training and inference for the three most prominent encoder-decoder architectures: attentional recurrent neural networks, self-attentional transformers, and fully convolutional networks. Sockeye also supports a wide range of optimizers, normalization and regularization techniques, and inference improvements from current NMT literature. Users can easily run standard training recipes, explore different model settings, and incorporate new ideas. In this paper, we highlight Sockeye's features and benchmark it against other NMT toolkits on two language arcs from the 2017 Conference on Machine Translation (WMT): English-German and Latvian-English. We report competitive BLEU scores across all three architectures, including an overall best score for Sockeye's transformer implementation. To facilitate further comparison, we release all system outputs and training scripts used in our experiments. The Sockeye toolkit is free software released under the Apache 2.0 license.
Counterfactual Learning from Bandit Feedback under Deterministic Logging: A Case Study in Statistical Machine Translation
Dec 14, 2017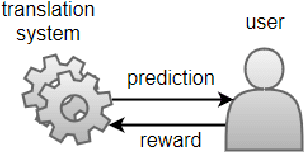
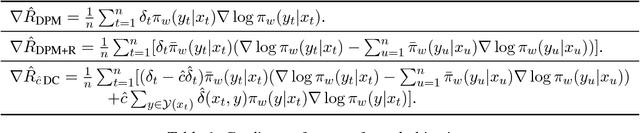
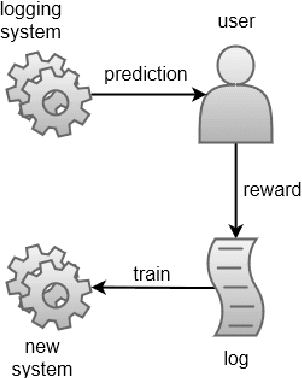

The goal of counterfactual learning for statistical machine translation (SMT) is to optimize a target SMT system from logged data that consist of user feedback to translations that were predicted by another, historic SMT system. A challenge arises by the fact that risk-averse commercial SMT systems deterministically log the most probable translation. The lack of sufficient exploration of the SMT output space seemingly contradicts the theoretical requirements for counterfactual learning. We show that counterfactual learning from deterministic bandit logs is possible nevertheless by smoothing out deterministic components in learning. This can be achieved by additive and multiplicative control variates that avoid degenerate behavior in empirical risk minimization. Our simulation experiments show improvements of up to 2 BLEU points by counterfactual learning from deterministic bandit feedback.
A Shared Task on Bandit Learning for Machine Translation
Jul 27, 2017
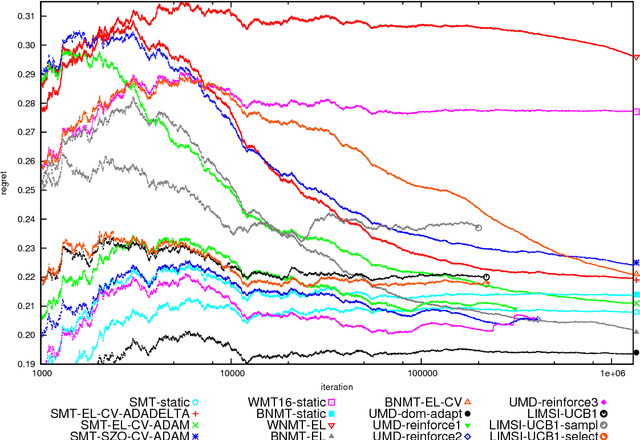

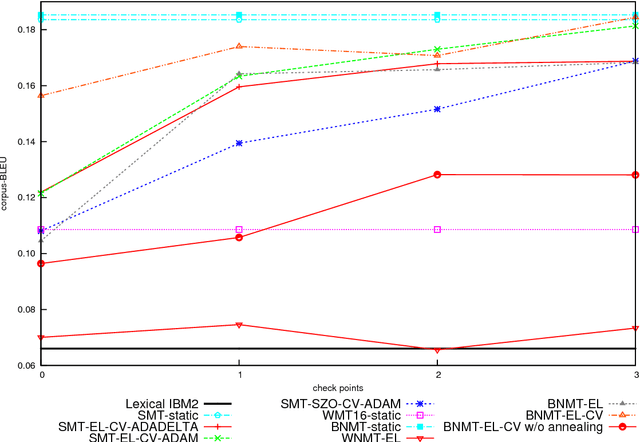
We introduce and describe the results of a novel shared task on bandit learning for machine translation. The task was organized jointly by Amazon and Heidelberg University for the first time at the Second Conference on Machine Translation (WMT 2017). The goal of the task is to encourage research on learning machine translation from weak user feedback instead of human references or post-edits. On each of a sequence of rounds, a machine translation system is required to propose a translation for an input, and receives a real-valued estimate of the quality of the proposed translation for learning. This paper describes the shared task's learning and evaluation setup, using services hosted on Amazon Web Services (AWS), the data and evaluation metrics, and the results of various machine translation architectures and learning protocols.