 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating Verbalized Probabilities for Large Language Models
Oct 09, 2024



Calibrating verbalized probabilities presents a novel approach for reliably assessing and leveraging outputs from black-box Large Language Models (LLMs). Recent methods have demonstrated improved calibration by applying techniques like Platt scaling or temperature scaling to the confidence scores generated by LLMs. In this paper, we explore the calibration of verbalized probability distributions for discriminative tasks. First, we investigate the capability of LLMs to generate probability distributions over categorical labels. We theoretically and empirically identify the issue of re-softmax arising from the scaling of verbalized probabilities, and propose using the invert softmax trick to approximate the "logit" by inverting verbalized probabilities. Through extensive evaluation on three public datasets, we demonstrate: (1) the robust capability of LLMs in generating class distributions, and (2) the effectiveness of the invert softmax trick in estimating logits, which, in turn, facilitates post-calibration adjustments.
Deploying a Retrieval based Response Model for Task Oriented Dialogues
Oct 25, 2022



Task-oriented dialogue systems in industry settings need to have high conversational capability, be easily adaptable to changing situations and conform to business constraints. This paper describes a 3-step procedure to develop a conversational model that satisfies these criteria and can efficiently scale to rank a large set of response candidates. First, we provide a simple algorithm to semi-automatically create a high-coverage template set from historic conversations without any annotation. Second, we propose a neural architecture that encodes the dialogue context and applicable business constraints as profile features for ranking the next turn. Third, we describe a two-stage learning strategy with self-supervised training, followed by supervised fine-tuning on limited data collected through a human-in-the-loop platform. Finally, we describe offline experiments and present results of deploying our model with human-in-the-loop to converse with live customers online.
A Shared Task on Bandit Learning for Machine Translation
Jul 27, 2017
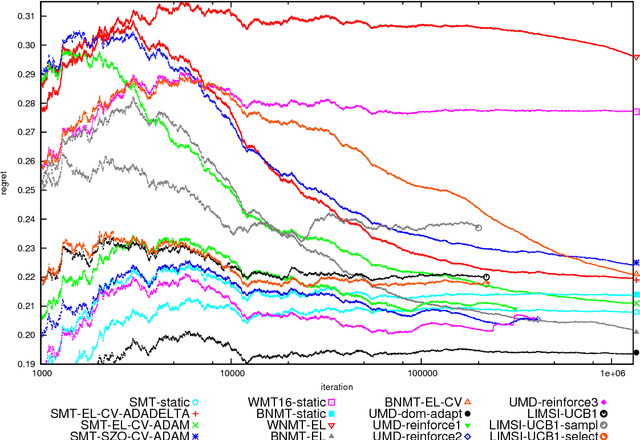

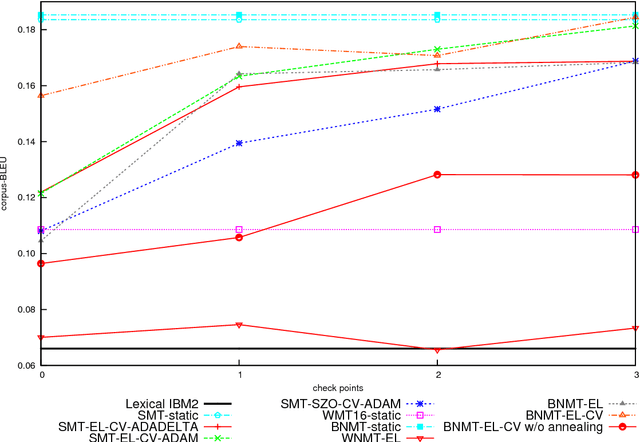
We introduce and describe the results of a novel shared task on bandit learning for machine translation. The task was organized jointly by Amazon and Heidelberg University for the first time at the Second Conference on Machine Translation (WMT 2017). The goal of the task is to encourage research on learning machine translation from weak user feedback instead of human references or post-edits. On each of a sequence of rounds, a machine translation system is required to propose a translation for an input, and receives a real-valued estimate of the quality of the proposed translation for learning. This paper describes the shared task's learning and evaluation setup, using services hosted on Amazon Web Services (AWS), the data and evaluation metrics, and the results of various machine translation architectures and learning protocols.