 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVATAR: Unconstrained Audiovisual Speech Recognition
Jun 15, 2022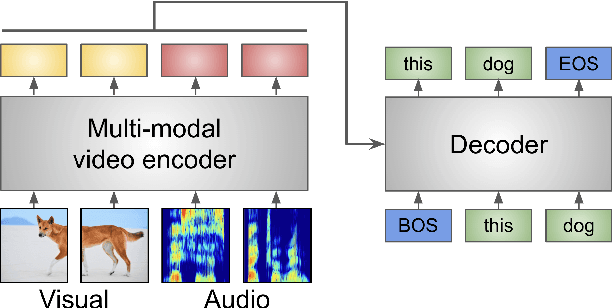
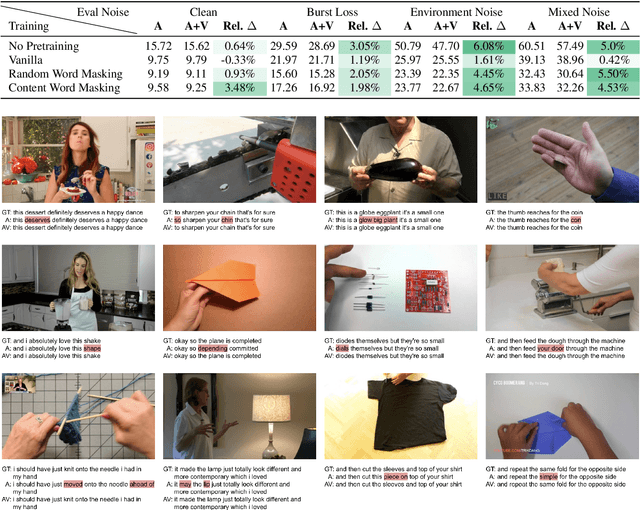
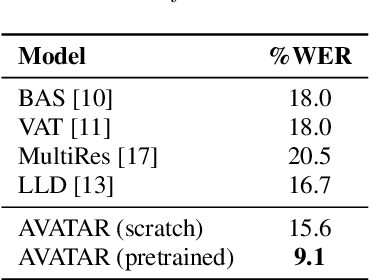
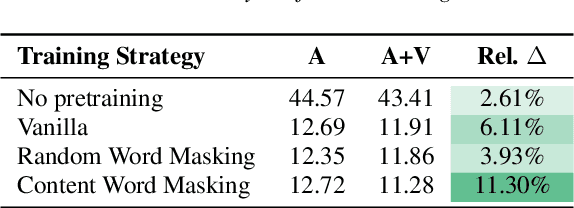
Audio-visual automatic speech recognition (AV-ASR) is an extension of ASR that incorporates visual cues, often from the movements of a speaker's mouth. Unlike works that simply focus on the lip motion, we investigate the contribution of entire visual frames (visual actions, objects, background etc.). This is particularly useful for unconstrained videos, where the speaker is not necessarily visible. To solve this task, we propose a new sequence-to-sequence AudioVisual ASR TrAnsformeR (AVATAR) which is trained end-to-end from spectrograms and full-frame RGB. To prevent the audio stream from dominating training, we propose different word-masking strategies, thereby encouraging our model to pay attention to the visual stream. We demonstrate the contribution of the visual modality on the How2 AV-ASR benchmark, especially in the presence of simulated noise, and show that our model outperforms all other prior work by a large margin. Finally, we also create a new, real-world test bed for AV-ASR called VisSpeech, which demonstrates the contribution of the visual modality under challenging audio conditions.
A CLIP-Hitchhiker's Guide to Long Video Retrieval
May 17, 2022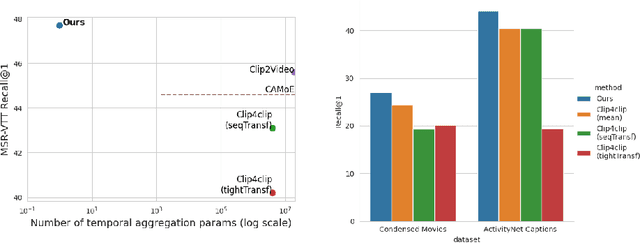

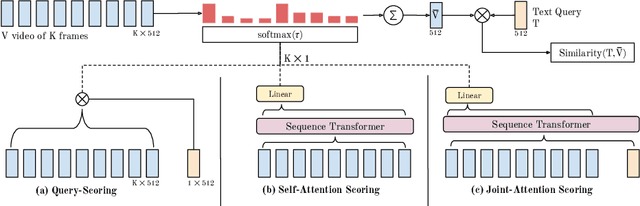
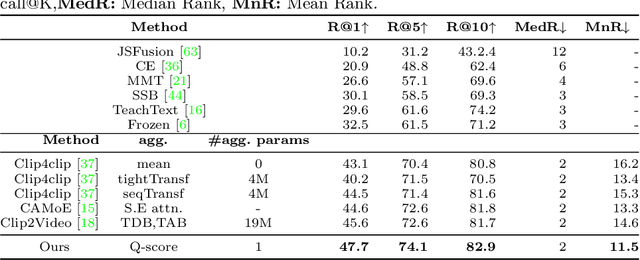
Our goal in this paper is the adaptation of image-text models for long video retrieval. Recent works have demonstrated state-of-the-art performance in video retrieval by adopting CLIP, effectively hitchhiking on the image-text representation for video tasks. However, there has been limited success in learning temporal aggregation that outperform mean-pooling the image-level representations extracted per frame by CLIP. We find that the simple yet effective baseline of weighted-mean of frame embeddings via query-scoring is a significant improvement above all prior temporal modelling attempts and mean-pooling. In doing so, we provide an improved baseline for others to compare to and demonstrate state-of-the-art performance of this simple baseline on a suite of long video retrieval benchmarks.
Learning Audio-Video Modalities from Image Captions
Apr 01, 2022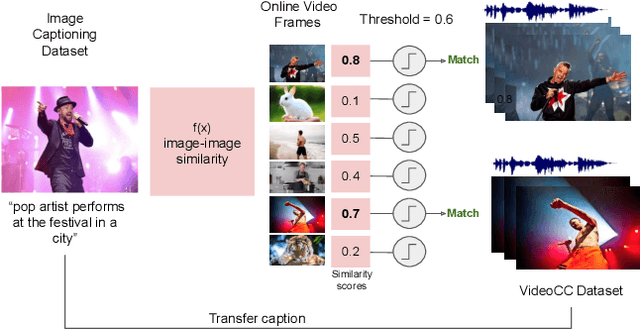
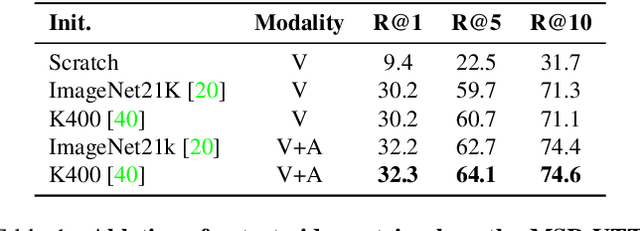

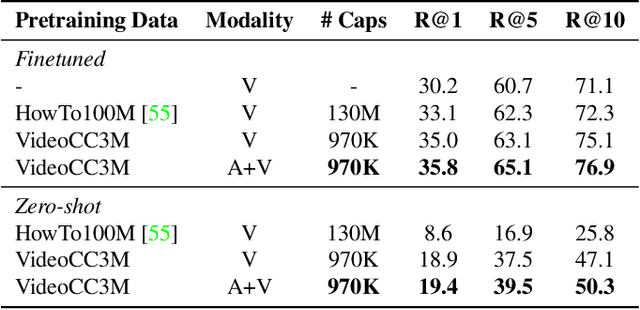
A major challenge in text-video and text-audio retrieval is the lack of large-scale training data. This is unlike image-captioning, where datasets are in the order of millions of samples. To close this gap we propose a new video mining pipeline which involves transferring captions from image captioning datasets to video clips with no additional manual effort. Using this pipeline, we create a new large-scale, weakly labelled audio-video captioning dataset consisting of millions of paired clips and captions. We show that training a multimodal transformed based model on this data achieves competitive performance on video retrieval and video captioning, matching or even outperforming HowTo100M pretraining with 20x fewer clips. We also show that our mined clips are suitable for text-audio pretraining, and achieve state of the art results for the task of audio retrieval.
End-to-end Generative Pretraining for Multimodal Video Captioning
Jan 20, 2022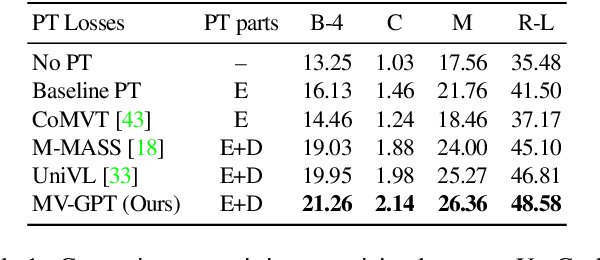
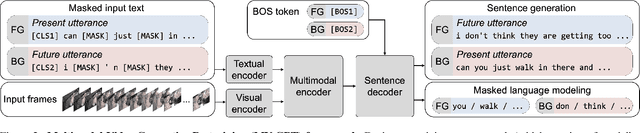
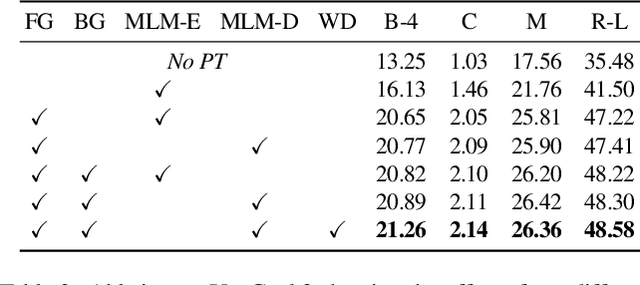
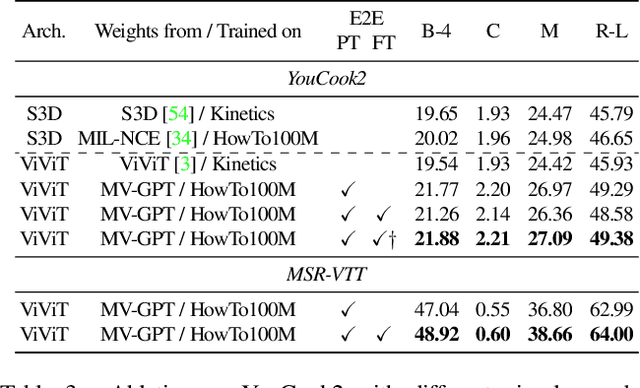
Recent video and language pretraining frameworks lack the ability to generate sentences. We present Multimodal Video Generative Pretraining (MV-GPT), a new pretraining framework for learning from unlabelled videos which can be effectively used for generative tasks such as multimodal video captioning. Unlike recent video-language pretraining frameworks, our framework trains both a multimodal video encoder and a sentence decoder jointly. To overcome the lack of captions in unlabelled videos, we leverage the future utterance as an additional text source and propose a bidirectional generation objective -- we generate future utterances given the present mulitmodal context, and also the present utterance given future observations. With this objective, we train an encoder-decoder model end-to-end to generate a caption from raw pixels and transcribed speech directly. Our model achieves state-of-the-art performance for multimodal video captioning on four standard benchmarks, as well as for other video understanding tasks such as VideoQA, video retrieval and action classification.
VoxSRC 2021: The Third VoxCeleb Speaker Recognition Challenge
Jan 12, 2022
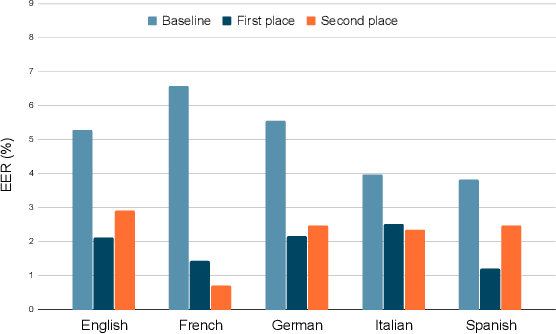
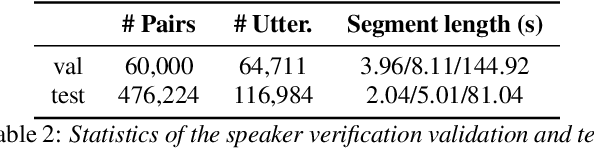
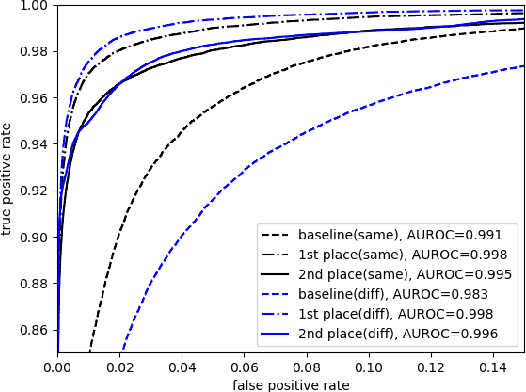
The third instalment of the VoxCeleb Speaker Recognition Challenge was held in conjunction with Interspeech 2021. The aim of this challenge was to assess how well current speaker recognition technology is able to diarise and recognise speakers in unconstrained or `in the wild' data. The challenge consisted of: (i) the provision of publicly available speaker recognition and diarisation data from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a virtual public challenge and workshop held at Interspeech 2021. This paper outlines the challenge, and describes the baselines, methods and results. We conclude with a discussion on the new multi-lingual focus of VoxSRC 2021, and on the progression of the challenge since the previous two editions.
Audio-Visual Synchronisation in the wild
Dec 08, 2021

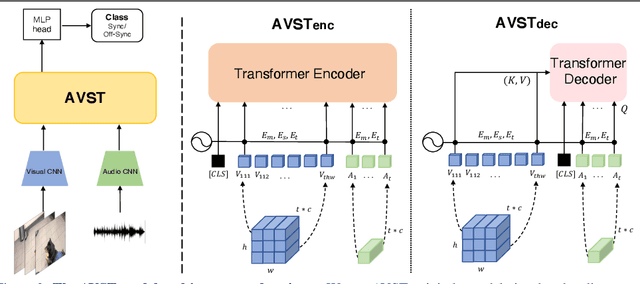
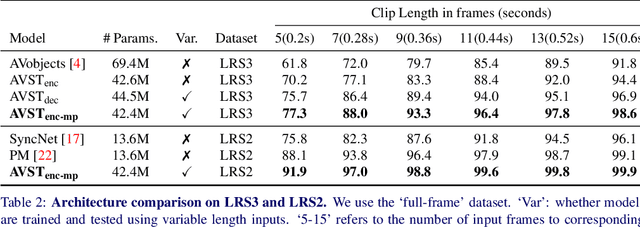
In this paper, we consider the problem of audio-visual synchronisation applied to videos `in-the-wild' (ie of general classes beyond speech). As a new task, we identify and curate a test set with high audio-visual correlation, namely VGG-Sound Sync. We compare a number of transformer-based architectural variants specifically designed to model audio and visual signals of arbitrary length, while significantly reducing memory requirements during training. We further conduct an in-depth analysis on the curated dataset and define an evaluation metric for open domain audio-visual synchronisation. We apply our method on standard lip reading speech benchmarks, LRS2 and LRS3, with ablations on various aspects. Finally, we set the first benchmark for general audio-visual synchronisation with over 160 diverse classes in the new VGG-Sound Sync video dataset. In all cases, our proposed model outperforms the previous state-of-the-art by a significant margin.
Masking Modalities for Cross-modal Video Retrieval
Nov 03, 2021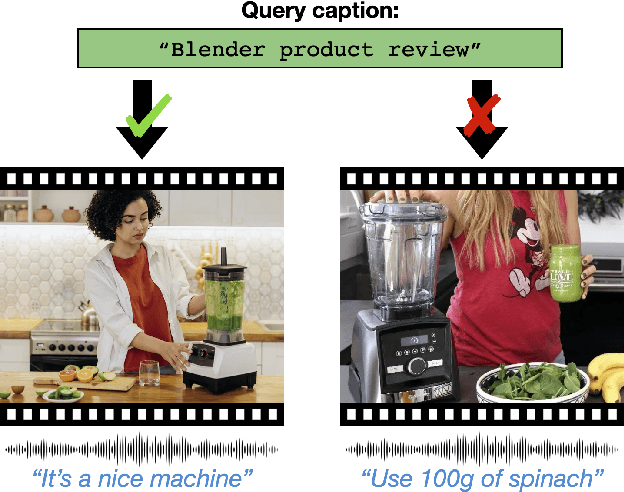
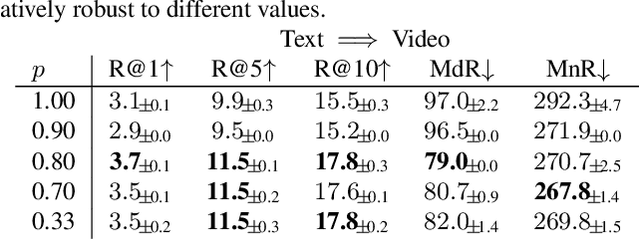
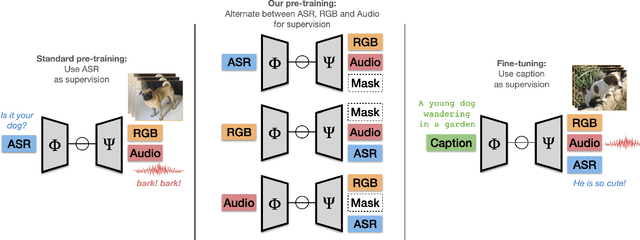

Pre-training on large scale unlabelled datasets has shown impressive performance improvements in the fields of computer vision and natural language processing. Given the advent of large-scale instructional video datasets, a common strategy for pre-training video encoders is to use the accompanying speech as weak supervision. However, as speech is used to supervise the pre-training, it is never seen by the video encoder, which does not learn to process that modality. We address this drawback of current pre-training methods, which fail to exploit the rich cues in spoken language. Our proposal is to pre-train a video encoder using all the available video modalities as supervision, namely, appearance, sound, and transcribed speech. We mask an entire modality in the input and predict it using the other two modalities. This encourages each modality to collaborate with the others, and our video encoder learns to process appearance and audio as well as speech. We show the superior performance of our "modality masking" pre-training approach for video retrieval on the How2R, YouCook2 and Condensed Movies datasets.
With a Little Help from my Temporal Context: Multimodal Egocentric Action Recognition
Nov 01, 2021
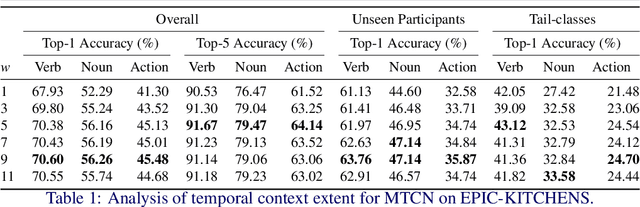

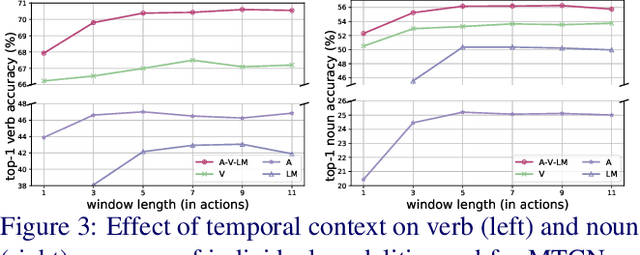
In egocentric videos, actions occur in quick succession. We capitalise on the action's temporal context and propose a method that learns to attend to surrounding actions in order to improve recognition performance. To incorporate the temporal context, we propose a transformer-based multimodal model that ingests video and audio as input modalities, with an explicit language model providing action sequence context to enhance the predictions. We test our approach on EPIC-KITCHENS and EGTEA datasets reporting state-of-the-art performance. Our ablations showcase the advantage of utilising temporal context as well as incorporating audio input modality and language model to rescore predictions. Code and models at: https://github.com/ekazakos/MTCN.
Attention Bottlenecks for Multimodal Fusion
Jun 30, 2021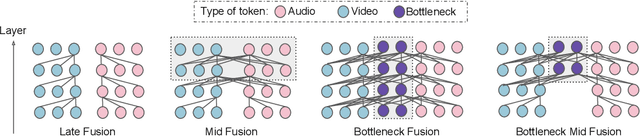
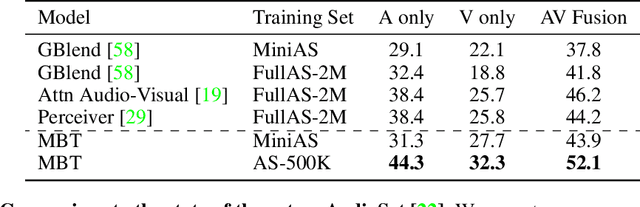
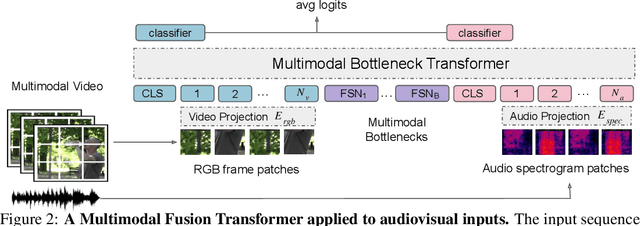
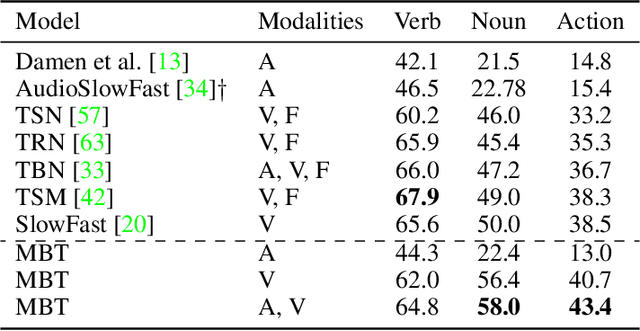
Humans perceive the world by concurrently processing and fusing high-dimensional inputs from multiple modalities such as vision and audio. Machine perception models, in stark contrast, are typically modality-specific and optimised for unimodal benchmarks, and hence late-stage fusion of final representations or predictions from each modality (`late-fusion') is still a dominant paradigm for multimodal video classification. Instead, we introduce a novel transformer based architecture that uses `fusion bottlenecks' for modality fusion at multiple layers. Compared to traditional pairwise self-attention, our model forces information between different modalities to pass through a small number of bottleneck latents, requiring the model to collate and condense the most relevant information in each modality and only share what is necessary. We find that such a strategy improves fusion performance, at the same time reducing computational cost. We conduct thorough ablation studies, and achieve state-of-the-art results on multiple audio-visual classification benchmarks including Audioset, Epic-Kitchens and VGGSound. All code and models will be released.
Localizing Visual Sounds the Hard Way
Apr 06, 2021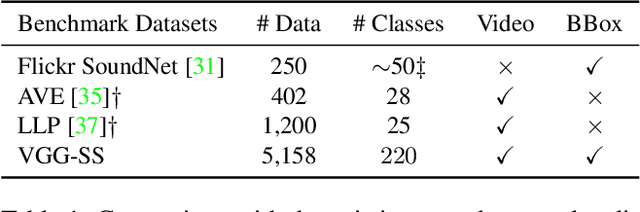
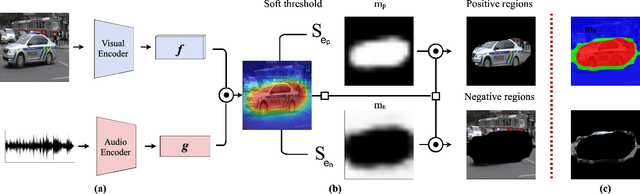

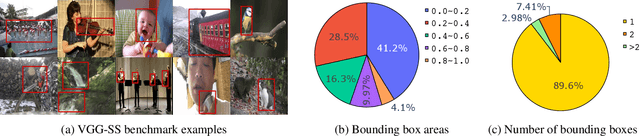
The objective of this work is to localize sound sources that are visible in a video without using manual annotations. Our key technical contribution is to show that, by training the network to explicitly discriminate challenging image fragments, even for images that do contain the object emitting the sound, we can significantly boost the localization performance. We do so elegantly by introducing a mechanism to mine hard samples and add them to a contrastive learning formulation automatically. We show that our algorithm achieves state-of-the-art performance on the popular Flickr SoundNet dataset. Furthermore, we introduce the VGG-Sound Source (VGG-SS) benchmark, a new set of annotations for the recently-introduced VGG-Sound dataset, where the sound sources visible in each video clip are explicitly marked with bounding box annotations. This dataset is 20 times larger than analogous existing ones, contains 5K videos spanning over 200 categories, and, differently from Flickr SoundNet, is video-based. On VGG-SS, we also show that our algorithm achieves state-of-the-art performance against several baselines.