 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Quantifying Individual Agent Importance in Cooperative MARL
Dec 13, 2023Measuring the contribution of individual agents is challenging in cooperative multi-agent reinforcement learning (MARL). In cooperative MARL, team performance is typically inferred from a single shared global reward. Arguably, among the best current approaches to effectively measure individual agent contributions is to use Shapley values. However, calculating these values is expensive as the computational complexity grows exponentially with respect to the number of agents. In this paper, we adapt difference rewards into an efficient method for quantifying the contribution of individual agents, referred to as Agent Importance, offering a linear computational complexity relative to the number of agents. We show empirically that the computed values are strongly correlated with the true Shapley values, as well as the true underlying individual agent rewards, used as the ground truth in environments where these are available. We demonstrate how Agent Importance can be used to help study MARL systems by diagnosing algorithmic failures discovered in prior MARL benchmarking work. Our analysis illustrates Agent Importance as a valuable explainability component for future MARL benchmarks.
How much can change in a year? Revisiting Evaluation in Multi-Agent Reinforcement Learning
Dec 13, 2023Establishing sound experimental standards and rigour is important in any growing field of research. Deep Multi-Agent Reinforcement Learning (MARL) is one such nascent field. Although exciting progress has been made, MARL has recently come under scrutiny for replicability issues and a lack of standardised evaluation methodology, specifically in the cooperative setting. Although protocols have been proposed to help alleviate the issue, it remains important to actively monitor the health of the field. In this work, we extend the database of evaluation methodology previously published by containing meta-data on MARL publications from top-rated conferences and compare the findings extracted from this updated database to the trends identified in their work. Our analysis shows that many of the worrying trends in performance reporting remain. This includes the omission of uncertainty quantification, not reporting all relevant evaluation details and a narrowing of algorithmic development classes. Promisingly, we do observe a trend towards more difficult scenarios in SMAC-v1, which if continued into SMAC-v2 will encourage novel algorithmic development. Our data indicate that replicability needs to be approached more proactively by the MARL community to ensure trust in the field as we move towards exciting new frontiers.
Generalisable Agents for Neural Network Optimisation
Nov 30, 2023



Optimising deep neural networks is a challenging task due to complex training dynamics, high computational requirements, and long training times. To address this difficulty, we propose the framework of Generalisable Agents for Neural Network Optimisation (GANNO) -- a multi-agent reinforcement learning (MARL) approach that learns to improve neural network optimisation by dynamically and responsively scheduling hyperparameters during training. GANNO utilises an agent per layer that observes localised network dynamics and accordingly takes actions to adjust these dynamics at a layerwise level to collectively improve global performance. In this paper, we use GANNO to control the layerwise learning rate and show that the framework can yield useful and responsive schedules that are competitive with handcrafted heuristics. Furthermore, GANNO is shown to perform robustly across a wide variety of unseen initial conditions, and can successfully generalise to harder problems than it was trained on. Our work presents an overview of the opportunities that this paradigm offers for training neural networks, along with key challenges that remain to be overcome.
Are we going MAD? Benchmarking Multi-Agent Debate between Language Models for Medical Q&A
Nov 29, 2023Recent advancements in large language models (LLMs) underscore their potential for responding to medical inquiries. However, ensuring that generative agents provide accurate and reliable answers remains an ongoing challenge. In this context, multi-agent debate (MAD) has emerged as a prominent strategy for enhancing the truthfulness of LLMs. In this work, we provide a comprehensive benchmark of MAD strategies for medical Q&A, along with open-source implementations. This explores the effective utilization of various strategies including the trade-offs between cost, time, and accuracy. We build upon these insights to provide a novel debate-prompting strategy based on agent agreement that outperforms previously published strategies on medical Q&A tasks.
Combinatorial Optimization with Policy Adaptation using Latent Space Search
Nov 13, 2023Combinatorial Optimization underpins many real-world applications and yet, designing performant algorithms to solve these complex, typically NP-hard, problems remains a significant research challenge. Reinforcement Learning (RL) provides a versatile framework for designing heuristics across a broad spectrum of problem domains. However, despite notable progress, RL has not yet supplanted industrial solvers as the go-to solution. Current approaches emphasize pre-training heuristics that construct solutions but often rely on search procedures with limited variance, such as stochastically sampling numerous solutions from a single policy or employing computationally expensive fine-tuning of the policy on individual problem instances. Building on the intuition that performant search at inference time should be anticipated during pre-training, we propose COMPASS, a novel RL approach that parameterizes a distribution of diverse and specialized policies conditioned on a continuous latent space. We evaluate COMPASS across three canonical problems - Travelling Salesman, Capacitated Vehicle Routing, and Job-Shop Scheduling - and demonstrate that our search strategy (i) outperforms state-of-the-art approaches on 11 standard benchmarking tasks and (ii) generalizes better, surpassing all other approaches on a set of 18 procedurally transformed instance distributions.
Jumanji: a Diverse Suite of Scalable Reinforcement Learning Environments in JAX
Jun 16, 2023Open-source reinforcement learning (RL) environments have played a crucial role in driving progress in the development of AI algorithms. In modern RL research, there is a need for simulated environments that are performant, scalable, and modular to enable their utilization in a wider range of potential real-world applications. Therefore, we present Jumanji, a suite of diverse RL environments specifically designed to be fast, flexible, and scalable. Jumanji provides a suite of environments focusing on combinatorial problems frequently encountered in industry, as well as challenging general decision-making tasks. By leveraging the efficiency of JAX and hardware accelerators like GPUs and TPUs, Jumanji enables rapid iteration of research ideas and large-scale experimentation, ultimately empowering more capable agents. Unlike existing RL environment suites, Jumanji is highly customizable, allowing users to tailor the initial state distribution and problem complexity to their needs. Furthermore, we provide actor-critic baselines for each environment, accompanied by preliminary findings on scaling and generalization scenarios. Jumanji aims to set a new standard for speed, adaptability, and scalability of RL environments.
Reduce, Reuse, Recycle: Selective Reincarnation in Multi-Agent Reinforcement Learning
Mar 31, 2023'Reincarnation' in reinforcement learning has been proposed as a formalisation of reusing prior computation from past experiments when training an agent in an environment. In this paper, we present a brief foray into the paradigm of reincarnation in the multi-agent (MA) context. We consider the case where only some agents are reincarnated, whereas the others are trained from scratch -- selective reincarnation. In the fully-cooperative MA setting with heterogeneous agents, we demonstrate that selective reincarnation can lead to higher returns than training fully from scratch, and faster convergence than training with full reincarnation. However, the choice of which agents to reincarnate in a heterogeneous system is vitally important to the outcome of the training -- in fact, a poor choice can lead to considerably worse results than the alternatives. We argue that a rich field of work exists here, and we hope that our effort catalyses further energy in bringing the topic of reincarnation to the multi-agent realm.
Off-the-Grid MARL: a Framework for Dataset Generation with Baselines for Cooperative Offline Multi-Agent Reinforcement Learning
Feb 01, 2023



Being able to harness the power of large, static datasets for developing autonomous multi-agent systems could unlock enormous value for real-world applications. Many important industrial systems are multi-agent in nature and are difficult to model using bespoke simulators. However, in industry, distributed system processes can often be recorded during operation, and large quantities of demonstrative data can be stored. Offline multi-agent reinforcement learning (MARL) provides a promising paradigm for building effective online controllers from static datasets. However, offline MARL is still in its infancy, and, therefore, lacks standardised benchmarks, baselines and evaluation protocols typically found in more mature subfields of RL. This deficiency makes it difficult for the community to sensibly measure progress. In this work, we aim to fill this gap by releasing \emph{off-the-grid MARL (OG-MARL)}: a framework for generating offline MARL datasets and algorithms. We release an initial set of datasets and baselines for cooperative offline MARL, created using the framework, along with a standardised evaluation protocol. Our datasets provide settings that are characteristic of real-world systems, including complex dynamics, non-stationarity, partial observability, suboptimality and sparse rewards, and are generated from popular online MARL benchmarks. We hope that OG-MARL will serve the community and help steer progress in offline MARL, while also providing an easy entry point for researchers new to the field.
Towards a Standardised Performance Evaluation Protocol for Cooperative MARL
Sep 21, 2022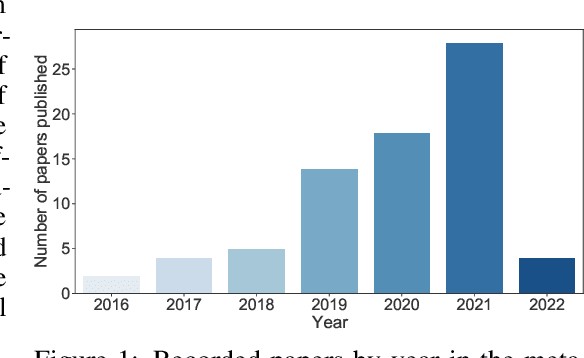

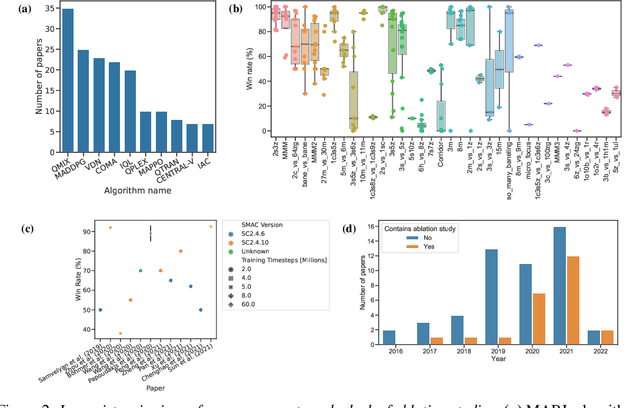

Multi-agent reinforcement learning (MARL) has emerged as a useful approach to solving decentralised decision-making problems at scale. Research in the field has been growing steadily with many breakthrough algorithms proposed in recent years. In this work, we take a closer look at this rapid development with a focus on evaluation methodologies employed across a large body of research in cooperative MARL. By conducting a detailed meta-analysis of prior work, spanning 75 papers accepted for publication from 2016 to 2022, we bring to light worrying trends that put into question the true rate of progress. We further consider these trends in a wider context and take inspiration from single-agent RL literature on similar issues with recommendations that remain applicable to MARL. Combining these recommendations, with novel insights from our analysis, we propose a standardised performance evaluation protocol for cooperative MARL. We argue that such a standard protocol, if widely adopted, would greatly improve the validity and credibility of future research, make replication and reproducibility easier, as well as improve the ability of the field to accurately gauge the rate of progress over time by being able to make sound comparisons across different works. Finally, we release our meta-analysis data publicly on our project website for future research on evaluation: https://sites.google.com/view/marl-standard-protocol
Universally Expressive Communication in Multi-Agent Reinforcement Learning
Jun 14, 2022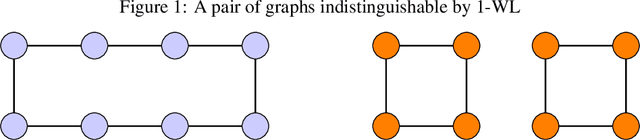
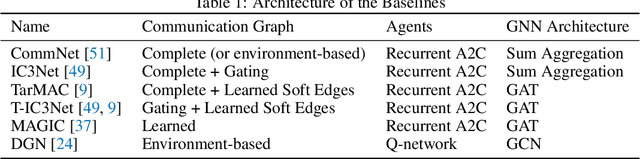

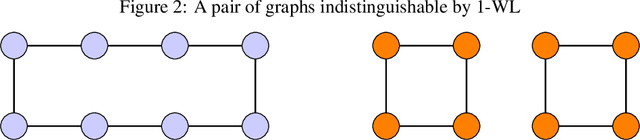
Allowing agents to share information through communication is crucial for solving complex tasks in multi-agent reinforcement learning. In this work, we consider the question of whether a given communication protocol can express an arbitrary policy. By observing that many existing protocols can be viewed as instances of graph neural networks (GNNs), we demonstrate the equivalence of joint action selection to node labelling. With standard GNN approaches provably limited in their expressive capacity, we draw from existing GNN literature and consider augmenting agent observations with: (1) unique agent IDs and (2) random noise. We provide a theoretical analysis as to how these approaches yield universally expressive communication, and also prove them capable of targeting arbitrary sets of actions for identical agents. Empirically, these augmentations are found to improve performance on tasks where expressive communication is required, whilst, in general, the optimal communication protocol is found to be task-dependent.