 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Based Program Synthesis with Neurally Interpreted Languages
Apr 20, 2026A central challenge in program induction has long been the trade-off between symbolic and neural approaches. Symbolic methods offer compositional generalisation and data efficiency, yet their scalability is constrained by formalisms such as domain-specific languages (DSLs), which are labour-intensive to create and may not transfer to new domains. In contrast, neural networks flexibly learn from data but tend to generalise poorly in compositional and out-of-distribution settings. We bridge this divide with an instance of a Latent Adaptation Network architecture named Neural Language Interpreter (NLI), which learns its own discrete, symbolic-like programming language end-to-end. NLI autonomously discovers a vocabulary of primitive operations and uses a novel differentiable neural executor to interpret variable-length sequences of these primitives. This allows NLI to represent programs that are not bound to a constant number of computation steps, enabling it to solve more complex problems than those seen during training. To make these discrete, compositional program structures amenable to gradient-based optimisation, we employ the Gumbel-Softmax relaxation, enabling the entire model to be trained end-to-end. Crucially, this same differentiability enables powerful test-time adaptation. At inference, NLI's program inductor provides an initial program guess. This guess is then refined via gradient descent through the neural executor, enabling efficient search for the neural program that best explains the given data. We demonstrate that NLI outperforms in-context learning, test-time training, and continuous latent program networks on tasks that require combinatorial generalisation and rapid adaptation to unseen tasks. Our results establish a new path toward models that combine the compositionality of discrete languages with the gradient-based search and end-to-end learning of neural networks.
Searching Latent Program Spaces
Nov 13, 2024Program synthesis methods aim to automatically generate programs restricted to a language that can explain a given specification of input-output pairs. While purely symbolic approaches suffer from a combinatorial search space, recent methods leverage neural networks to learn distributions over program structures to narrow this search space significantly, enabling more efficient search. However, for challenging problems, it remains difficult to train models to perform program synthesis in one shot, making test-time search essential. Most neural methods lack structured search mechanisms during inference, relying instead on stochastic sampling or gradient updates, which can be inefficient. In this work, we propose the Latent Program Network (LPN), a general algorithm for program induction that learns a distribution over latent programs in a continuous space, enabling efficient search and test-time adaptation. We explore how to train these networks to optimize for test-time computation and demonstrate the use of gradient-based search both during training and at test time. We evaluate LPN on ARC-AGI, a program synthesis benchmark that evaluates performance by generalizing programs to new inputs rather than explaining the underlying specification. We show that LPN can generalize beyond its training distribution and adapt to unseen tasks by utilizing test-time computation, outperforming algorithms without test-time adaptation mechanisms.
Jumanji: a Diverse Suite of Scalable Reinforcement Learning Environments in JAX
Jun 16, 2023Open-source reinforcement learning (RL) environments have played a crucial role in driving progress in the development of AI algorithms. In modern RL research, there is a need for simulated environments that are performant, scalable, and modular to enable their utilization in a wider range of potential real-world applications. Therefore, we present Jumanji, a suite of diverse RL environments specifically designed to be fast, flexible, and scalable. Jumanji provides a suite of environments focusing on combinatorial problems frequently encountered in industry, as well as challenging general decision-making tasks. By leveraging the efficiency of JAX and hardware accelerators like GPUs and TPUs, Jumanji enables rapid iteration of research ideas and large-scale experimentation, ultimately empowering more capable agents. Unlike existing RL environment suites, Jumanji is highly customizable, allowing users to tailor the initial state distribution and problem complexity to their needs. Furthermore, we provide actor-critic baselines for each environment, accompanied by preliminary findings on scaling and generalization scenarios. Jumanji aims to set a new standard for speed, adaptability, and scalability of RL environments.
Debiasing Meta-Gradient Reinforcement Learning by Learning the Outer Value Function
Nov 19, 2022



Meta-gradient Reinforcement Learning (RL) allows agents to self-tune their hyper-parameters in an online fashion during training. In this paper, we identify a bias in the meta-gradient of current meta-gradient RL approaches. This bias comes from using the critic that is trained using the meta-learned discount factor for the advantage estimation in the outer objective which requires a different discount factor. Because the meta-learned discount factor is typically lower than the one used in the outer objective, the resulting bias can cause the meta-gradient to favor myopic policies. We propose a simple solution to this issue: we eliminate this bias by using an alternative, \emph{outer} value function in the estimation of the outer loss. To obtain this outer value function we add a second head to the critic network and train it alongside the classic critic, using the outer loss discount factor. On an illustrative toy problem, we show that the bias can cause catastrophic failure of current meta-gradient RL approaches, and show that our proposed solution fixes it. We then apply our method to a more complex environment and demonstrate that fixing the meta-gradient bias can significantly improve performance.
One Step at a Time: Pros and Cons of Multi-Step Meta-Gradient Reinforcement Learning
Oct 30, 2021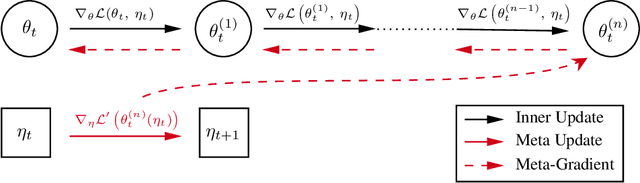

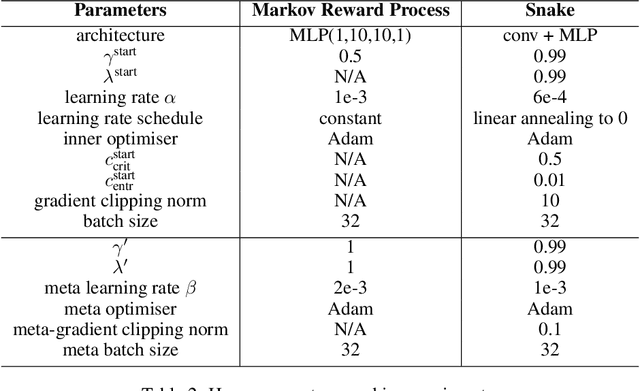
Self-tuning algorithms that adapt the learning process online encourage more effective and robust learning. Among all the methods available, meta-gradients have emerged as a promising approach. They leverage the differentiability of the learning rule with respect to some hyper-parameters to adapt them in an online fashion. Although meta-gradients can be accumulated over multiple learning steps to avoid myopic updates, this is rarely used in practice. In this work, we demonstrate that whilst multi-step meta-gradients do provide a better learning signal in expectation, this comes at the cost of a significant increase in variance, hindering performance. In the light of this analysis, we introduce a novel method mixing multiple inner steps that enjoys a more accurate and robust meta-gradient signal, essentially trading off bias and variance in meta-gradient estimation. When applied to the Snake game, the mixing meta-gradient algorithm can cut the variance by a factor of 3 while achieving similar or higher performance.