 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful Knowledge Graph Explanations for Commonsense Reasoning
Oct 07, 2023



While fusing language models (LMs) and knowledge graphs (KGs) has become common in commonsense question answering research, enabling faithful chain-of-thought explanations in these models remains an open problem. One major weakness of current KG-based explanation techniques is that they overlook the faithfulness of generated explanations during evaluation. To address this gap, we make two main contributions: (1) We propose and validate two quantitative metrics - graph consistency and graph fidelity - to measure the faithfulness of KG-based explanations. (2) We introduce Consistent GNN (CGNN), a novel training method that adds a consistency regularization term to improve explanation faithfulness. Our analysis shows that predictions from KG often diverge from original model predictions. The proposed CGNN approach boosts consistency and fidelity, demonstrating its potential for producing more faithful explanations. Our work emphasises the importance of explicitly evaluating suggest a path forward for developing architectures for faithful graph-based explanations.
PANACEA: An Automated Misinformation Detection System on COVID-19
Feb 28, 2023In this demo, we introduce a web-based misinformation detection system PANACEA on COVID-19 related claims, which has two modules, fact-checking and rumour detection. Our fact-checking module, which is supported by novel natural language inference methods with a self-attention network, outperforms state-of-the-art approaches. It is also able to give automated veracity assessment and ranked supporting evidence with the stance towards the claim to be checked. In addition, PANACEA adapts the bi-directional graph convolutional networks model, which is able to detect rumours based on comment networks of related tweets, instead of relying on the knowledge base. This rumour detection module assists by warning the users in the early stages when a knowledge base may not be available.
NUAA-QMUL-AIIT at Memotion 3: Multi-modal Fusion with Squeeze-and-Excitation for Internet Meme Emotion Analysis
Feb 16, 2023This paper describes the participation of our NUAA-QMUL-AIIT team in the Memotion 3 shared task on meme emotion analysis. We propose a novel multi-modal fusion method, Squeeze-and-Excitation Fusion (SEFusion), and embed it into our system for emotion classification in memes. SEFusion is a simple fusion method that employs fully connected layers, reshaping, and matrix multiplication. SEFusion learns a weight for each modality and then applies it to its own modality feature. We evaluate the performance of our system on the three Memotion 3 sub-tasks. Among all participating systems in this Memotion 3 shared task, our system ranked first on task A, fifth on task B, and second on task C. Our proposed SEFusion provides the flexibility to fuse any features from different modalities. The source code for our method is published on https://github.com/xxxxxxxxy/memotion3-SEFusion.
Cluster-based Deep Ensemble Learning for Emotion Classification in Internet Memes
Feb 16, 2023Memes have gained popularity as a means to share visual ideas through the Internet and social media by mixing text, images and videos, often for humorous purposes. Research enabling automated analysis of memes has gained attention in recent years, including among others the task of classifying the emotion expressed in memes. In this paper, we propose a novel model, cluster-based deep ensemble learning (CDEL), for emotion classification in memes. CDEL is a hybrid model that leverages the benefits of a deep learning model in combination with a clustering algorithm, which enhances the model with additional information after clustering memes with similar facial features. We evaluate the performance of CDEL on a benchmark dataset for emotion classification, proving its effectiveness by outperforming a wide range of baseline models and achieving state-of-the-art performance. Further evaluation through ablated models demonstrates the effectiveness of the different components of CDEL.
Few-shot Learning for Cross-Target Stance Detection by Aggregating Multimodal Embeddings
Jan 11, 2023Despite the increasing popularity of the stance detection task, existing approaches are predominantly limited to using the textual content of social media posts for the classification, overlooking the social nature of the task. The stance detection task becomes particularly challenging in cross-target classification scenarios, where even in few-shot training settings the model needs to predict the stance towards new targets for which the model has only seen few relevant samples during training. To address the cross-target stance detection in social media by leveraging the social nature of the task, we introduce CT-TN, a novel model that aggregates multimodal embeddings derived from both textual and network features of the data. We conduct experiments in a few-shot cross-target scenario on six different combinations of source-destination target pairs. By comparing CT-TN with state-of-the-art cross-target stance detection models, we demonstrate the effectiveness of our model by achieving average performance improvements ranging from 11% to 21% across different baseline models. Experiments with different numbers of shots show that CT-TN can outperform other models after seeing 300 instances of the destination target. Further, ablation experiments demonstrate the positive contribution of each of the components of CT-TN towards the final performance. We further analyse the network interactions between social media users, which reveal the potential of using social features for cross-target stance detection.
AnnoBERT: Effectively Representing Multiple Annotators' Label Choices to Improve Hate Speech Detection
Jan 10, 2023



Supervised approaches generally rely on majority-based labels. However, it is hard to achieve high agreement among annotators in subjective tasks such as hate speech detection. Existing neural network models principally regard labels as categorical variables, while ignoring the semantic information in diverse label texts. In this paper, we propose AnnoBERT, a first-of-its-kind architecture integrating annotator characteristics and label text with a transformer-based model to detect hate speech, with unique representations based on each annotator's characteristics via Collaborative Topic Regression (CTR) and integrate label text to enrich textual representations. During training, the model associates annotators with their label choices given a piece of text; during evaluation, when label information is not available, the model predicts the aggregated label given by the participating annotators by utilising the learnt association. The proposed approach displayed an advantage in detecting hate speech, especially in the minority class and edge cases with annotator disagreement. Improvement in the overall performance is the largest when the dataset is more label-imbalanced, suggesting its practical value in identifying real-world hate speech, as the volume of hate speech in-the-wild is extremely small on social media, when compared with normal (non-hate) speech. Through ablation studies, we show the relative contributions of annotator embeddings and label text to the model performance, and tested a range of alternative annotator embeddings and label text combinations.
* accepted at ICWSM 2023
Check-worthy Claim Detection across Topics for Automated Fact-checking
Dec 16, 2022An important component of an automated fact-checking system is the claim check-worthiness detection system, which ranks sentences by prioritising them based on their need to be checked. Despite a body of research tackling the task, previous research has overlooked the challenging nature of identifying check-worthy claims across different topics. In this paper, we assess and quantify the challenge of detecting check-worthy claims for new, unseen topics. After highlighting the problem, we propose the AraCWA model to mitigate the performance deterioration when detecting check-worthy claims across topics. The AraCWA model enables boosting the performance for new topics by incorporating two components for few-shot learning and data augmentation. Using a publicly available dataset of Arabic tweets consisting of 14 different topics, we demonstrate that our proposed data augmentation strategy achieves substantial improvements across topics overall, where the extent of the improvement varies across topics. Further, we analyse the semantic similarities between topics, suggesting that the similarity metric could be used as a proxy to determine the difficulty level of an unseen topic prior to undertaking the task of labelling the underlying sentences.
SexWEs: Domain-Aware Word Embeddings via Cross-lingual Semantic Specialisation for Chinese Sexism Detection in Social Media
Nov 17, 2022



The goal of sexism detection is to mitigate negative online content targeting certain gender groups of people. However, the limited availability of labeled sexism-related datasets makes it problematic to identify online sexism for low-resource languages. In this paper, we address the task of automatic sexism detection in social media for one low-resource language -- Chinese. Rather than collecting new sexism data or building cross-lingual transfer learning models, we develop a cross-lingual domain-aware semantic specialisation system in order to make the most of existing data. Semantic specialisation is a technique for retrofitting pre-trained distributional word vectors by integrating external linguistic knowledge (such as lexico-semantic relations) into the specialised feature space. To do this, we leverage semantic resources for sexism from a high-resource language (English) to specialise pre-trained word vectors in the target language (Chinese) to inject domain knowledge. We demonstrate the benefit of our sexist word embeddings (SexWEs) specialised by our framework via intrinsic evaluation of word similarity and extrinsic evaluation of sexism detection. Compared with other specialisation approaches and Chinese baseline word vectors, our SexWEs shows an average score improvement of 0.033 and 0.064 in both intrinsic and extrinsic evaluations, respectively. The ablative results and visualisation of SexWEs also prove the effectiveness of our framework on retrofitting word vectors in low-resource languages. Our code and sexism-related word vectors will be publicly available.
Active PETs: Active Data Annotation Prioritisation for Few-Shot Claim Verification with Pattern Exploiting Training
Aug 18, 2022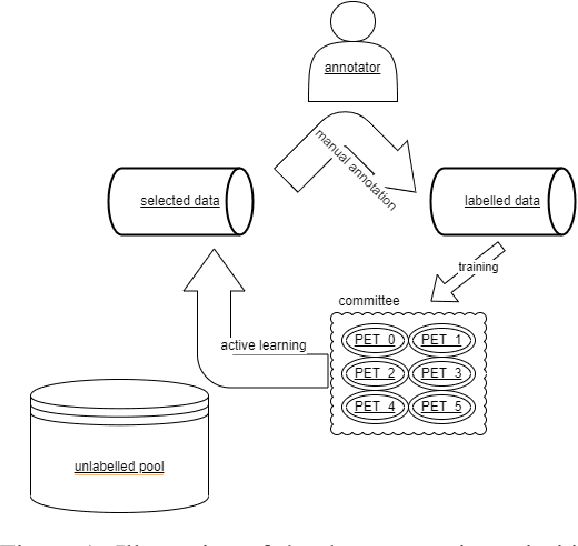
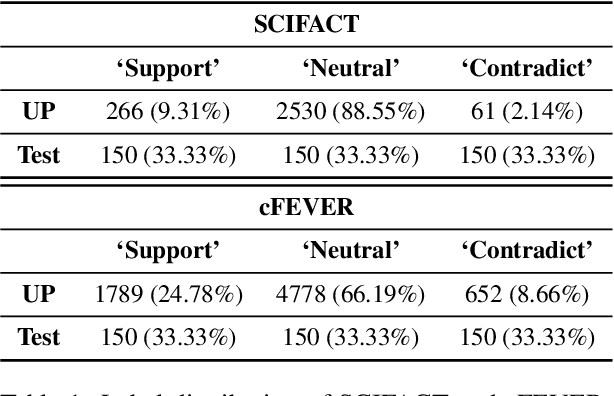
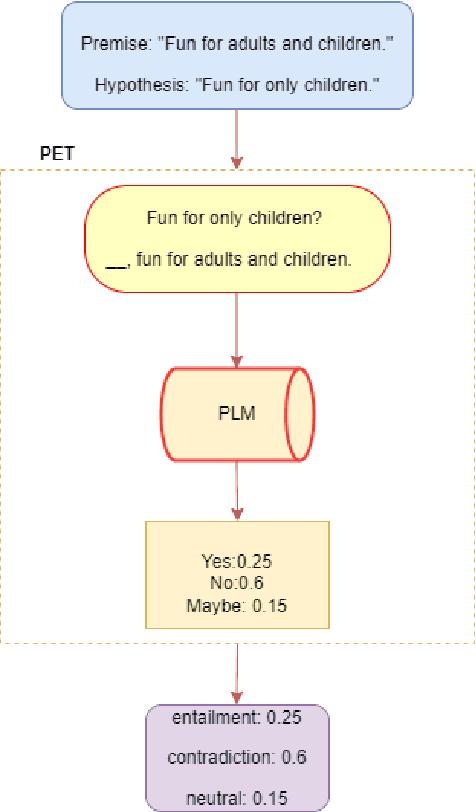
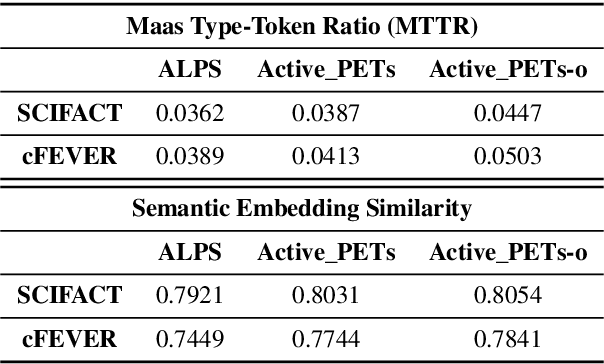
To mitigate the impact of data scarcity on fact-checking systems, we focus on few-shot claim verification. Despite recent work on few-shot classification by proposing advanced language models, there is a dearth of research in data annotation prioritisation that improves the selection of the few shots to be labelled for optimal model performance. We propose Active PETs, a novel weighted approach that utilises an ensemble of Pattern Exploiting Training (PET) models based on various language models, to actively select unlabelled data as candidates for annotation. Using Active PETs for data selection shows consistent improvement over the state-of-the-art active learning method, on two technical fact-checking datasets and using six different pretrained language models. We show further improvement with Active PETs-o, which further integrates an oversampling strategy. Our approach enables effective selection of instances to be labelled where unlabelled data is abundant but resources for labelling are limited, leading to consistently improved few-shot claim verification performance. Our code will be available upon publication.
Session-based Cyberbullying Detection in Social Media: A Survey
Jul 14, 2022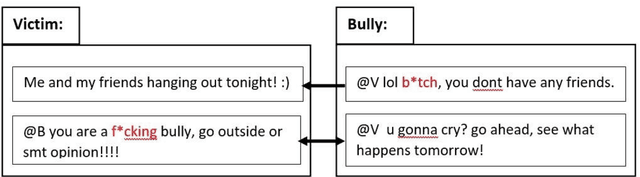
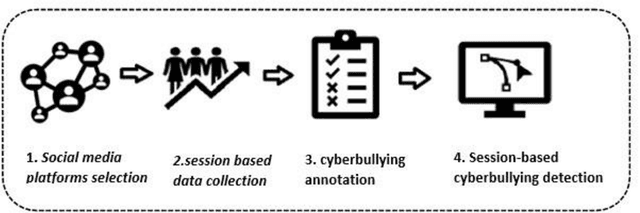

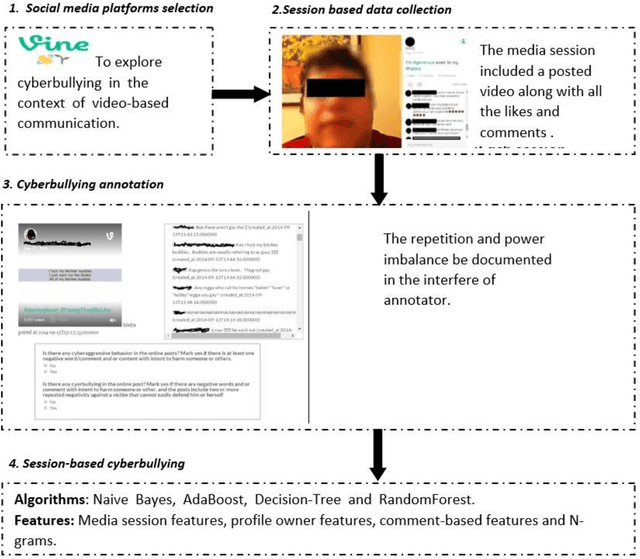
Cyberbullying is a pervasive problem in online social media, where a bully abuses a victim through a social media session. By investigating cyberbullying perpetrated through social media sessions, recent research has looked into mining patterns and features for modeling and understanding the two defining characteristics of cyberbullying: repetitive behavior and power imbalance. In this survey paper, we define the Session-based Cyberbullying Detection framework that encapsulates the different steps and challenges of the problem. Based on this framework, we provide a comprehensive overview of session-based cyberbullying detection in social media, delving into existing efforts from a data and methodological perspective. Our review leads us to propose evidence-based criteria for a set of best practices to create session-based cyberbullying datasets. In addition, we perform benchmark experiments comparing the performance of state-of-the-art session-based cyberbullying detection models as well as large pre-trained language models across two different datasets. Through our review, we also put forth a set of open challenges as future research directions.