 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIrony Detection, Reasoning and Understanding in Zero-shot Learning
Jan 28, 2025



Irony is a powerful figurative language (FL) on social media that can potentially mislead various NLP tasks, such as recommendation systems, misinformation checks, and sentiment analysis. Understanding the implicit meaning of this kind of subtle language is essential to mitigate irony's negative impact on NLP tasks. However, building models to understand irony presents a unique set of challenges, because irony is a complex form of language that often relies on context, tone, and subtle cues to convey meaning that is opposite or different from the literal interpretation. Large language models, such as ChatGPT, are increasingly able to capture implicit and contextual information. In this study, we investigate the generalization, reasoning and understanding ability of ChatGPT on irony detection across six different genre irony detection datasets. Our findings suggest that ChatGPT appears to show an enhanced language understanding and reasoning ability. But it needs to be very careful in prompt engineering design. Thus, we propose a prompt engineering design framework IDADP to achieve higher irony detection accuracy, improved understanding of irony, and more effective explanations compared to other state-of-the-art ChatGPT zero-shot approaches. And ascertain via experiments that the practice generated under the framework is likely to be the promised solution to resolve the generalization issues of LLMs.
Detecting harassment and defamation in cyberbullying with emotion-adaptive training
Jan 28, 2025



Existing research on detecting cyberbullying incidents on social media has primarily concentrated on harassment and is typically approached as a binary classification task. However, cyberbullying encompasses various forms, such as denigration and harassment, which celebrities frequently face. Furthermore, suitable training data for these diverse forms of cyberbullying remains scarce. In this study, we first develop a celebrity cyberbullying dataset that encompasses two distinct types of incidents: harassment and defamation. We investigate various types of transformer-based models, namely masked (RoBERTa, Bert and DistilBert), replacing(Electra), autoregressive (XLnet), masked&permuted (Mpnet), text-text (T5) and large language models (Llama2 and Llama3) under low source settings. We find that they perform competitively on explicit harassment binary detection. However, their performance is substantially lower on harassment and denigration multi-classification tasks. Therefore, we propose an emotion-adaptive training framework (EAT) that helps transfer knowledge from the domain of emotion detection to the domain of cyberbullying detection to help detect indirect cyberbullying events. EAT consistently improves the average macro F1, precision and recall by 20% in cyberbullying detection tasks across nine transformer-based models under low-resource settings. Our claims are supported by intuitive theoretical insights and extensive experiments.
ID-XCB: Data-independent Debiasing for Fair and Accurate Transformer-based Cyberbullying Detection
Feb 27, 2024



Swear words are a common proxy to collect datasets with cyberbullying incidents. Our focus is on measuring and mitigating biases derived from spurious associations between swear words and incidents occurring as a result of such data collection strategies. After demonstrating and quantifying these biases, we introduce ID-XCB, the first data-independent debiasing technique that combines adversarial training, bias constraints and debias fine-tuning approach aimed at alleviating model attention to bias-inducing words without impacting overall model performance. We explore ID-XCB on two popular session-based cyberbullying datasets along with comprehensive ablation and generalisation studies. We show that ID-XCB learns robust cyberbullying detection capabilities while mitigating biases, outperforming state-of-the-art debiasing methods in both performance and bias mitigation. Our quantitative and qualitative analyses demonstrate its generalisability to unseen data.
Session-based Cyberbullying Detection in Social Media: A Survey
Jul 14, 2022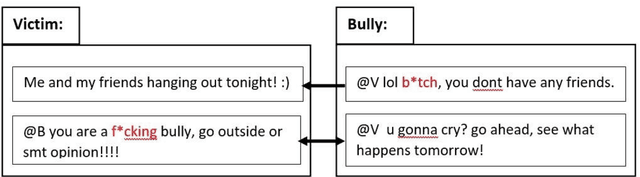
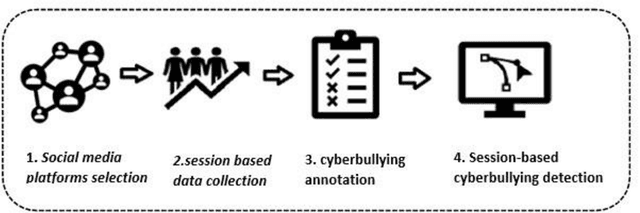

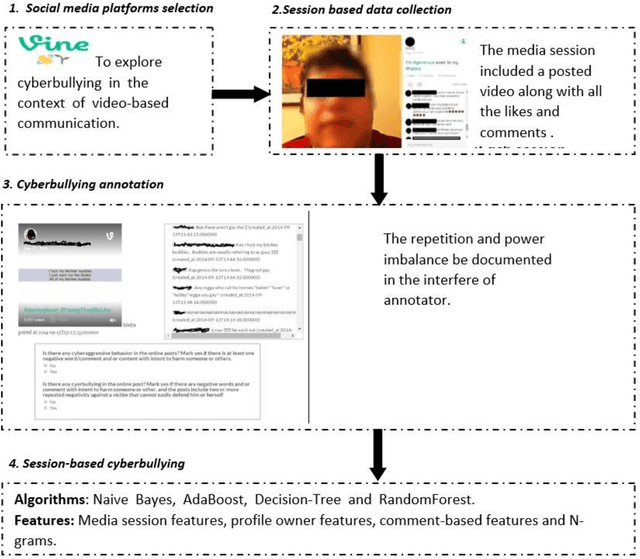
Cyberbullying is a pervasive problem in online social media, where a bully abuses a victim through a social media session. By investigating cyberbullying perpetrated through social media sessions, recent research has looked into mining patterns and features for modeling and understanding the two defining characteristics of cyberbullying: repetitive behavior and power imbalance. In this survey paper, we define the Session-based Cyberbullying Detection framework that encapsulates the different steps and challenges of the problem. Based on this framework, we provide a comprehensive overview of session-based cyberbullying detection in social media, delving into existing efforts from a data and methodological perspective. Our review leads us to propose evidence-based criteria for a set of best practices to create session-based cyberbullying datasets. In addition, we perform benchmark experiments comparing the performance of state-of-the-art session-based cyberbullying detection models as well as large pre-trained language models across two different datasets. Through our review, we also put forth a set of open challenges as future research directions.
Cyberbullying detection across social media platforms via platform-aware adversarial encoding
Apr 01, 2022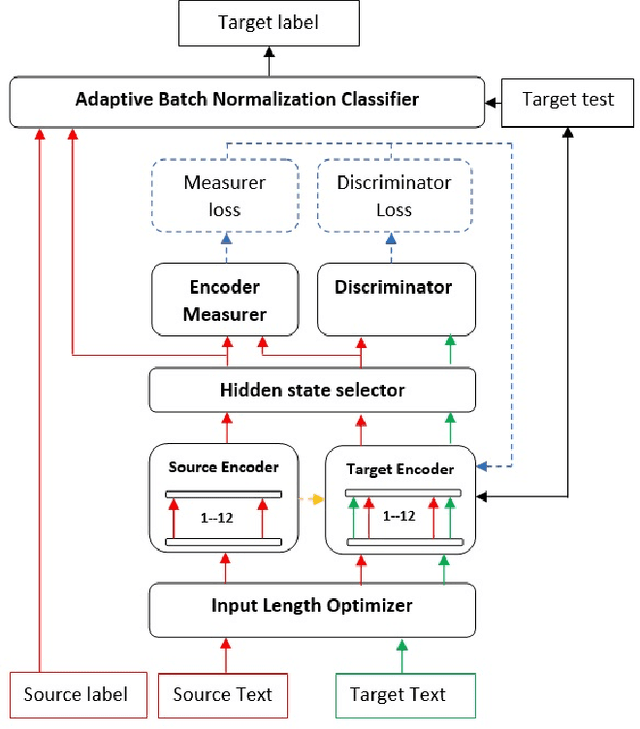

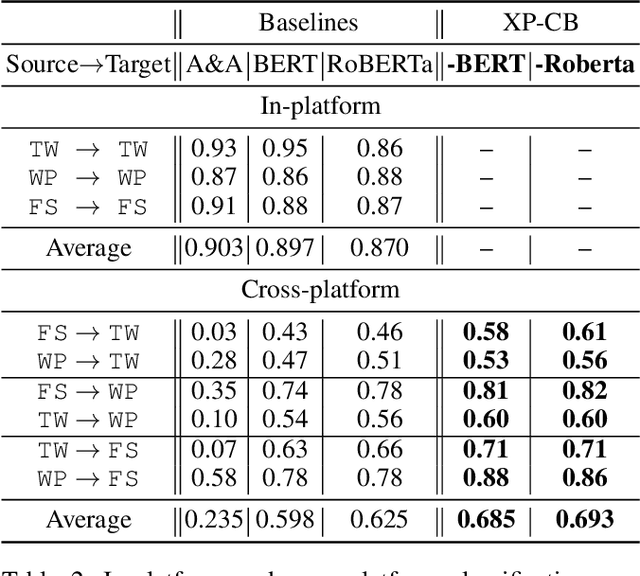

Despite the increasing interest in cyberbullying detection, existing efforts have largely been limited to experiments on a single platform and their generalisability across different social media platforms have received less attention. We propose XP-CB, a novel cross-platform framework based on Transformers and adversarial learning. XP-CB can enhance a Transformer leveraging unlabelled data from the source and target platforms to come up with a common representation while preventing platform-specific training. To validate our proposed framework, we experiment on cyberbullying datasets from three different platforms through six cross-platform configurations, showing its effectiveness with both BERT and RoBERTa as the underlying Transformer models.
Weakly Supervised Cross-platform Teenager Detection with Adversarial BERT
Aug 24, 2021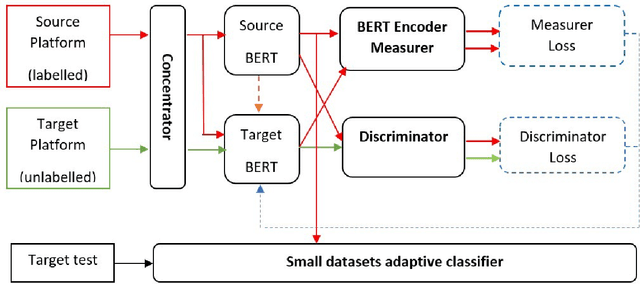
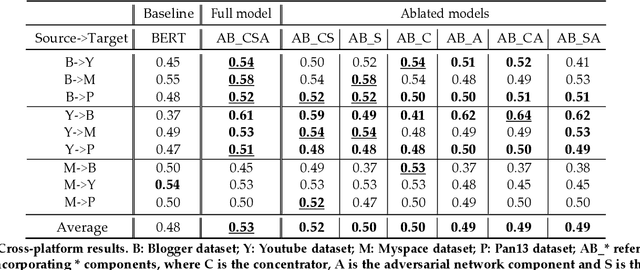
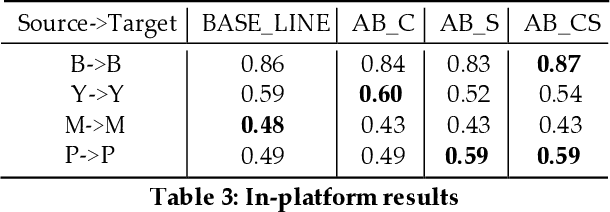
Teenager detection is an important case of the age detection task in social media, which aims to detect teenage users to protect them from negative influences. The teenager detection task suffers from the scarcity of labelled data, which exacerbates the ability to perform well across social media platforms. To further research in teenager detection in settings where no labelled data is available for a platform, we propose a novel cross-platform framework based on Adversarial BERT. Our framework can operate with a limited amount of labelled instances from the source platform and with no labelled data from the target platform, transferring knowledge from the source to the target social media. We experiment on four publicly available datasets, obtaining results demonstrating that our framework can significantly improve over competitive baseline models on the cross-platform teenager detection task.