 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Roadmap for Multilingual, Multimodal Domain Independent Deception Detection
May 07, 2024

Deception, a prevalent aspect of human communication, has undergone a significant transformation in the digital age. With the globalization of online interactions, individuals are communicating in multiple languages and mixing languages on social media, with varied data becoming available in each language and dialect. At the same time, the techniques for detecting deception are similar across the board. Recent studies have shown the possibility of the existence of universal linguistic cues to deception across domains within the English language; however, the existence of such cues in other languages remains unknown. Furthermore, the practical task of deception detection in low-resource languages is not a well-studied problem due to the lack of labeled data. Another dimension of deception is multimodality. For example, a picture with an altered caption in fake news or disinformation may exist. This paper calls for a comprehensive investigation into the complexities of deceptive language across linguistic boundaries and modalities within the realm of computer security and natural language processing and the possibility of using multilingual transformer models and labeled data in various languages to universally address the task of deception detection.
* 6 pages, 1 figure, shorter version in SIAM International Conference on Data Mining (SDM) 2024
Domain-Independent Deception: A New Taxonomy and Linguistic Analysis
Feb 01, 2024Internet-based economies and societies are drowning in deceptive attacks. These attacks take many forms, such as fake news, phishing, and job scams, which we call ``domains of deception.'' Machine-learning and natural-language-processing researchers have been attempting to ameliorate this precarious situation by designing domain-specific detectors. Only a few recent works have considered domain-independent deception. We collect these disparate threads of research and investigate domain-independent deception. First, we provide a new computational definition of deception and break down deception into a new taxonomy. Then, we analyze the debate on linguistic cues for deception and supply guidelines for systematic reviews. Finally, we investigate common linguistic features and give evidence for knowledge transfer across different forms of deception.
Improving Authorship Verification using Linguistic Divergence
Mar 12, 2021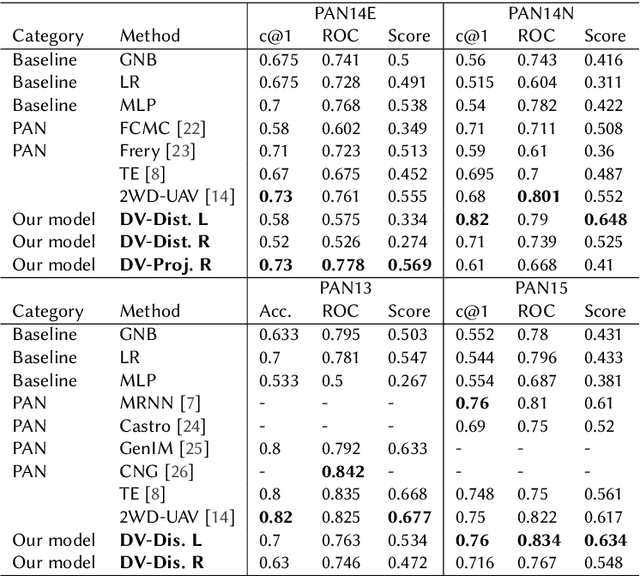
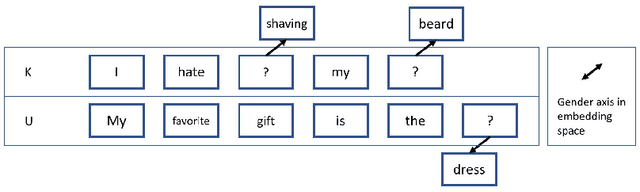
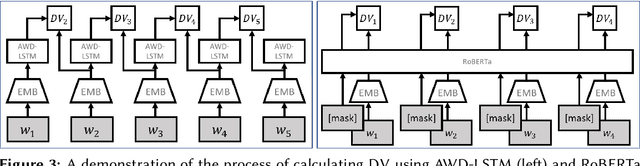
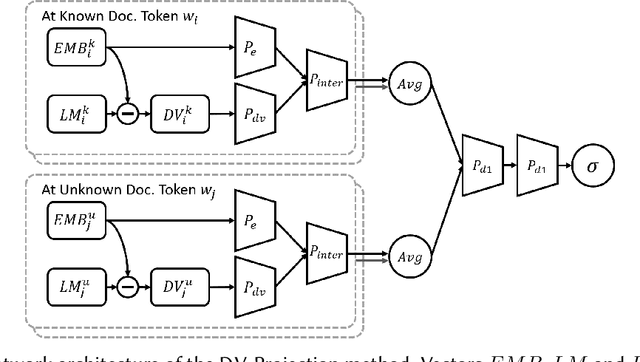
We propose an unsupervised solution to the Authorship Verification task that utilizes pre-trained deep language models to compute a new metric called DV-Distance. The proposed metric is a measure of the difference between the two authors comparing against pre-trained language models. Our design addresses the problem of non-comparability in authorship verification, frequently encountered in small or cross-domain corpora. To the best of our knowledge, this paper is the first one to introduce a method designed with non-comparability in mind from the ground up, rather than indirectly. It is also one of the first to use Deep Language Models in this setting. The approach is intuitive, and it is easy to understand and interpret through visualization. Experiments on four datasets show our methods matching or surpassing current state-of-the-art and strong baselines in most tasks.
A General Approach to Domain Adaptation with Applications in Astronomy
Dec 20, 2018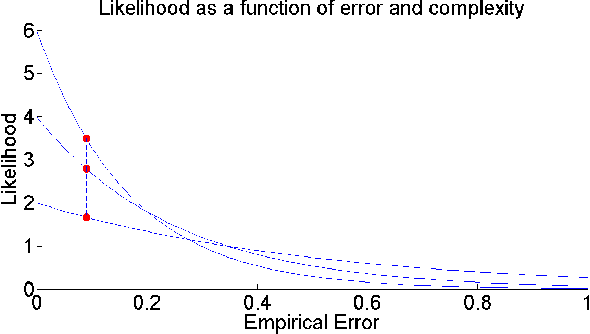
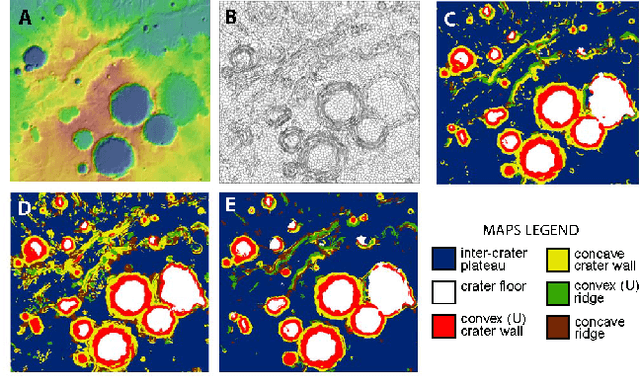
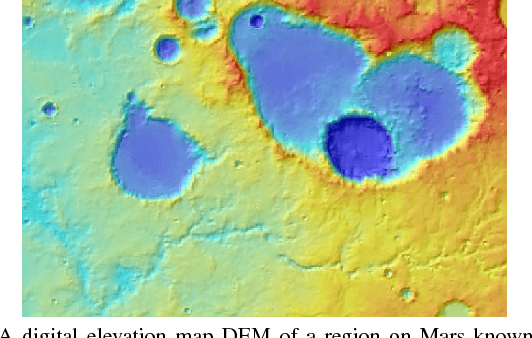
The ability to build a model on a source task and subsequently adapt such model on a new target task is a pervasive need in many astronomical applications. The problem is generally known as transfer learning in machine learning, where domain adaptation is a popular scenario. An example is to build a predictive model on spectroscopic data to identify Supernovae IA, while subsequently trying to adapt such model on photometric data. In this paper we propose a new general approach to domain adaptation that does not rely on the proximity of source and target distributions. Instead we simply assume a strong similarity in model complexity across domains, and use active learning to mitigate the dependency on source examples. Our work leads to a new formulation for the likelihood as a function of empirical error using a theoretical learning bound; the result is a novel mapping from generalization error to a likelihood estimation. Results using two real astronomical problems, Supernova Ia classification and identification of Mars landforms, show two main advantages with our approach: increased accuracy performance and substantial savings in computational cost.