 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan It Edit? Evaluating the Ability of Large Language Models to Follow Code Editing Instructions
Dec 29, 2023A significant amount of research is focused on developing and evaluating large language models for a variety of code synthesis tasks. These include synthesizing code from natural language instructions, synthesizing tests from code, and synthesizing explanations of code. In contrast, the behavior of instructional code editing with LLMs is understudied. These are tasks in which the model is instructed to update a block of code provided in a prompt. The editing instruction may ask for a feature to added or removed, describe a bug and ask for a fix, ask for a different kind of solution, or many other common code editing tasks. We introduce a carefully crafted benchmark of code editing tasks and use it evaluate several cutting edge LLMs. Our evaluation exposes a significant gap between the capabilities of state-of-the-art open and closed models. For example, even GPT-3.5-Turbo is 8.8% better than the best open model at editing code. We also introduce a new, carefully curated, permissively licensed training set of code edits coupled with natural language instructions. Using this training set, we show that we can fine-tune open Code LLMs to significantly improve their code editing capabilities.
Deploying and Evaluating LLMs to Program Service Mobile Robots
Nov 18, 2023



Recent advancements in large language models (LLMs) have spurred interest in using them for generating robot programs from natural language, with promising initial results. We investigate the use of LLMs to generate programs for service mobile robots leveraging mobility, perception, and human interaction skills, and where accurate sequencing and ordering of actions is crucial for success. We contribute CodeBotler, an open-source robot-agnostic tool to program service mobile robots from natural language, and RoboEval, a benchmark for evaluating LLMs' capabilities of generating programs to complete service robot tasks. CodeBotler performs program generation via few-shot prompting of LLMs with an embedded domain-specific language (eDSL) in Python, and leverages skill abstractions to deploy generated programs on any general-purpose mobile robot. RoboEval evaluates the correctness of generated programs by checking execution traces starting with multiple initial states, and checking whether the traces satisfy temporal logic properties that encode correctness for each task. RoboEval also includes multiple prompts per task to test for the robustness of program generation. We evaluate several popular state-of-the-art LLMs with the RoboEval benchmark, and perform a thorough analysis of the modes of failures, resulting in a taxonomy that highlights common pitfalls of LLMs at generating robot programs. We release our code and benchmark at https://amrl.cs.utexas.edu/codebotler/.
Knowledge Transfer from High-Resource to Low-Resource Programming Languages for Code LLMs
Aug 22, 2023



Over the past few years, Large Language Models of Code (Code LLMs) have started to have a significant impact on programming practice. Code LLMs are also emerging as a building block for research in programming languages and software engineering. However, the quality of code produced by a Code LLM varies significantly by programming languages. Code LLMs produce impressive results on programming languages that are well represented in their training data (e.g., Java, Python, or JavaScript), but struggle with low-resource languages, like OCaml and Racket. This paper presents an effective approach for boosting the performance of Code LLMs on low-resource languages using semi-synthetic data. Our approach generates high-quality datasets for low-resource languages, which can then be used to fine-tune any pretrained Code LLM. Our approach, called MultiPL-T, translates training data from high-resource languages into training data for low-resource languages. We apply our approach to generate tens of thousands of new, validated training items for Racket, OCaml, and Lua from Python. Moreover, we use an open dataset (The Stack) and model (StarCoderBase), which allow us to decontaminate benchmarks and train models on this data without violating the model license. With MultiPL-T generated data, we present fine-tuned versions of StarCoderBase that achieve state-of-the-art performance for Racket, OCaml, and Lua on benchmark problems. For Lua, our fine-tuned model achieves the same performance as StarCoderBase as Python -- a very high-resource language -- on the MultiPL-E benchmarks. For Racket and OCaml, we double their performance on MultiPL-E, bringing their performance close to higher-resource languages such as Ruby and C#.
StudentEval: A Benchmark of Student-Written Prompts for Large Language Models of Code
Jun 07, 2023



Code LLMs are being rapidly deployed and there is evidence that they can make professional programmers more productive. Current benchmarks for code generation measure whether models generate correct programs given an expert prompt. In this paper, we present a new benchmark containing multiple prompts per problem, written by a specific population of non-expert prompters: beginning programmers. StudentEval contains 1,749 prompts for 48 problems, written by 80 students who have only completed one semester of Python programming. Our students wrote these prompts while working interactively with a Code LLM, and we observed very mixed success rates. We use StudentEval to evaluate 5 Code LLMs and find that StudentEval is a better discriminator of model performance than existing benchmarks. We analyze the prompts and find significant variation in students' prompting techniques. We also find that nondeterministic LLM sampling could mislead students into thinking that their prompts are more (or less) effective than they actually are, which has implications for how to teach with Code LLMs.
Type Prediction With Program Decomposition and Fill-in-the-Type Training
May 25, 2023



TypeScript and Python are two programming languages that support optional type annotations, which are useful but tedious to introduce and maintain. This has motivated automated type prediction: given an untyped program, produce a well-typed output program. Large language models (LLMs) are promising for type prediction, but there are challenges: fill-in-the-middle performs poorly, programs may not fit into the context window, generated types may not type check, and it is difficult to measure how well-typed the output program is. We address these challenges by building OpenTau, a search-based approach for type prediction that leverages large language models. We propose a new metric for type prediction quality, give a tree-based program decomposition that searches a space of generated types, and present fill-in-the-type fine-tuning for LLMs. We evaluate our work with a new dataset for TypeScript type prediction, and show that 47.4% of files type check (14.5% absolute improvement) with an overall rate of 3.3 type errors per file. All code, data, and models are available at: https://github.com/GammaTauAI/opentau.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
SantaCoder: don't reach for the stars!
Jan 09, 2023



The BigCode project is an open-scientific collaboration working on the responsible development of large language models for code. This tech report describes the progress of the collaboration until December 2022, outlining the current state of the Personally Identifiable Information (PII) redaction pipeline, the experiments conducted to de-risk the model architecture, and the experiments investigating better preprocessing methods for the training data. We train 1.1B parameter models on the Java, JavaScript, and Python subsets of The Stack and evaluate them on the MultiPL-E text-to-code benchmark. We find that more aggressive filtering of near-duplicates can further boost performance and, surprisingly, that selecting files from repositories with 5+ GitHub stars deteriorates performance significantly. Our best model outperforms previous open-source multilingual code generation models (InCoder-6.7B and CodeGen-Multi-2.7B) in both left-to-right generation and infilling on the Java, JavaScript, and Python portions of MultiPL-E, despite being a substantially smaller model. All models are released under an OpenRAIL license at https://hf.co/bigcode.
A Scalable and Extensible Approach to Benchmarking NL2Code for 18 Programming Languages
Aug 19, 2022
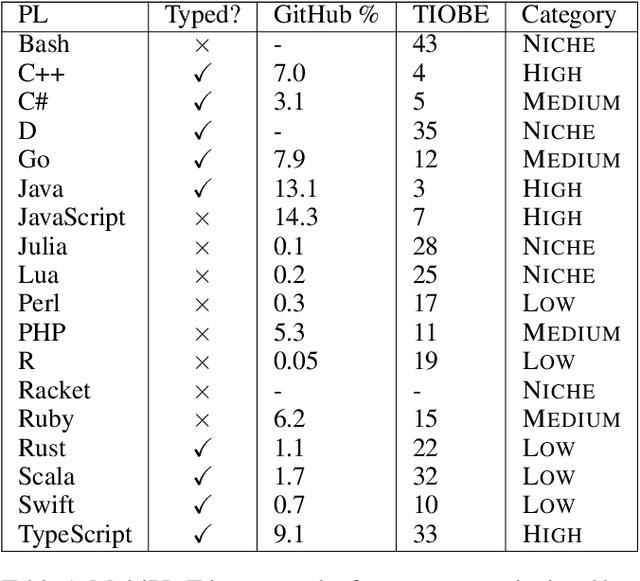

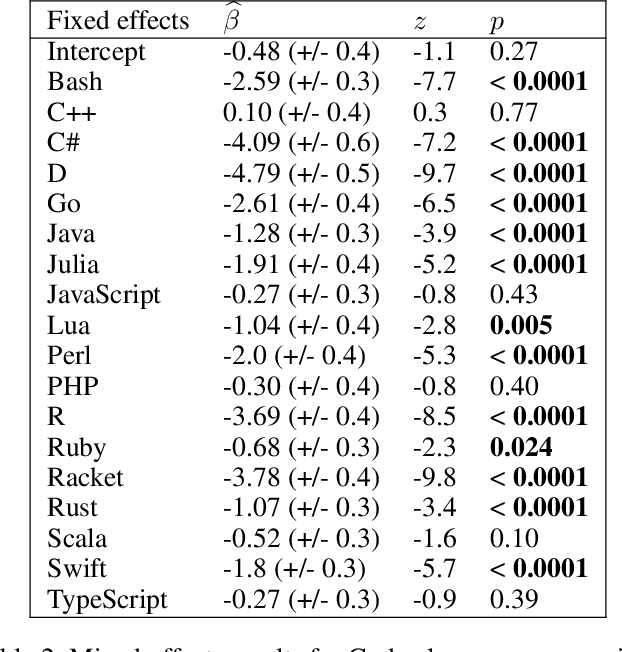
Large language models have demonstrated the ability to condition on and generate both natural language and programming language text. Such models open up the possibility of multi-language code generation: could code generation models generalize knowledge from one language to another? Although contemporary code generation models can generate semantically correct Python code, little is known about their abilities with other languages. We facilitate the exploration of this topic by proposing MultiPL-E, the first multi-language parallel benchmark for natural-language-to-code-generation. MultiPL-E extends the HumanEval benchmark (Chen et al, 2021) to support 18 more programming languages, encompassing a range of programming paradigms and popularity. We evaluate two state-of-the-art code generation models on MultiPL-E: Codex and InCoder. We find that on several languages, Codex matches and even exceeds its performance on Python. The range of programming languages represented in MultiPL-E allow us to explore the impact of language frequency and language features on model performance. Finally, the MultiPL-E approach of compiling code generation benchmarks to new programming languages is both scalable and extensible. We describe a general approach for easily adding support for new benchmarks and languages to MultiPL-E.
Iterative Program Synthesis for Adaptable Social Navigation
Mar 08, 2021

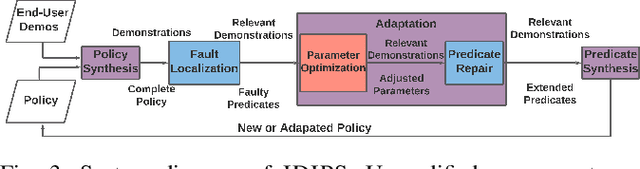

Robot social navigation is influenced by human preferences and environment-specific scenarios such as elevators and doors, thus necessitating end-user adaptability. State-of-the-art approaches to social navigation fall into two categories: model-based social constraints and learning-based approaches. While effective, these approaches have fundamental limitations -- model-based approaches require constraint and parameter tuning to adapt to preferences and new scenarios, while learning-based approaches require reward functions, significant training data, and are hard to adapt to new social scenarios or new domains with limited demonstrations. In this work, we propose Iterative Dimension Informed Program Synthesis (IDIPS) to address these limitations by learning and adapting social navigation in the form of human-readable symbolic programs. IDIPS works by combining program synthesis, parameter optimization, predicate repair, and iterative human demonstration to learn and adapt model-free action selection policies from orders of magnitude less data than learning-based approaches. We introduce a novel predicate repair technique that can accommodate previously unseen social scenarios or preferences by growing existing policies. We present experimental results showing that IDIPS: 1) synthesizes effective policies that model user preference, 2) can adapt existing policies to changing preferences, 3) can extend policies to handle novel social scenarios such as locked doors, and 4) generates policies that can be transferred from simulation to real-world robots with minimal effort.
NextDoor: GPU-Based Graph Sampling for Graph Machine Learning
Sep 17, 2020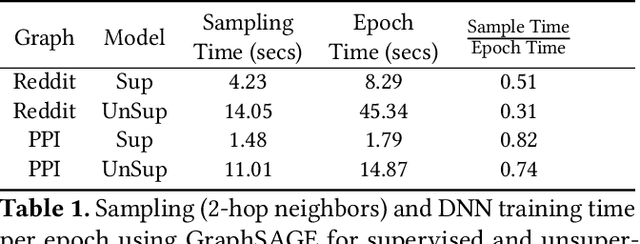
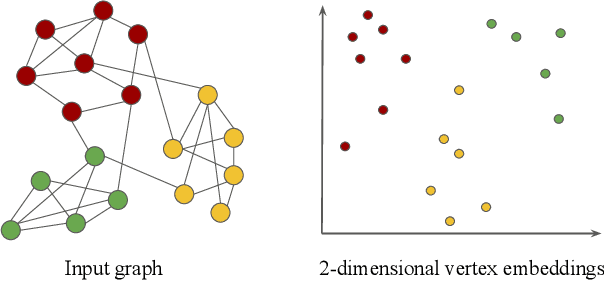
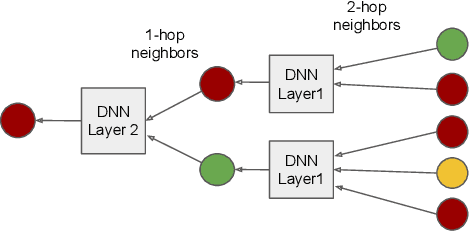
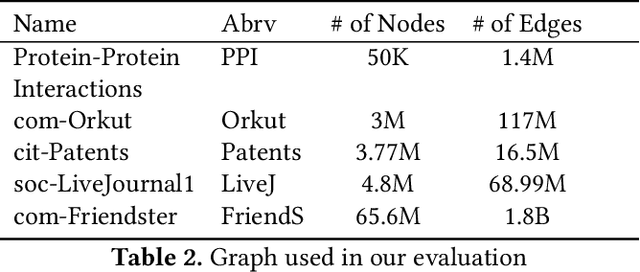
Representation learning is a fundamental task in machine learning. It consists of learning the features of data items automatically, typically using a deep neural network (DNN), instead of selecting hand-engineered features that typically have worse performance. Graph data requires specific algorithms for representation learning such as DeepWalk, node2vec, and GraphSAGE. These algorithms first sample the input graph and then train a DNN based on the samples. It is common to use GPUs for training, but graph sampling on GPUs is challenging. Sampling is an embarrassingly parallel task since each sample can be generated independently. However, the irregularity of graphs makes it hard to use GPU resources effectively. Existing graph processing, mining, and representation learning systems do not effectively parallelize sampling and this negatively impacts the end-to-end performance of representation learning. In this paper, we present NextDoor, the first system specifically designed to perform graph sampling on GPUs. NextDoor introduces a high-level API based on a novel paradigm for parallel graph sampling called transit-parallelism. We implement several graph sampling applications, and show that NextDoor runs them orders of magnitude faster than existing systems