 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing External Off-Policy Speech-To-Text Mappings in Contextual End-To-End Automated Speech Recognition
Jan 06, 2023Despite improvements to the generalization performance of automated speech recognition (ASR) models, specializing ASR models for downstream tasks remains a challenging task, primarily due to reduced data availability (necessitating increased data collection), and rapidly shifting data distributions (requiring more frequent model fine-tuning). In this work, we investigate the potential of leveraging external knowledge, particularly through off-policy key-value stores generated with text-to-speech methods, to allow for flexible post-training adaptation to new data distributions. In our approach, audio embeddings captured from text-to-speech, along with semantic text embeddings, are used to bias ASR via an approximate k-nearest-neighbor (KNN) based attentive fusion step. Our experiments on LibiriSpeech and in-house voice assistant/search datasets show that the proposed approach can reduce domain adaptation time by up to 1K GPU-hours while providing up to 3% WER improvement compared to a fine-tuning baseline, suggesting a promising approach for adapting production ASR systems in challenging zero and few-shot scenarios.
ILASR: Privacy-Preserving Incremental Learning for Automatic Speech Recognition at Production Scale
Jul 22, 2022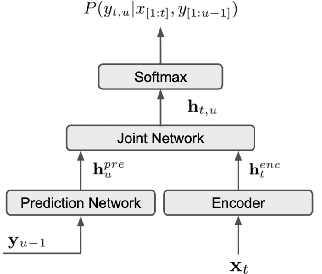
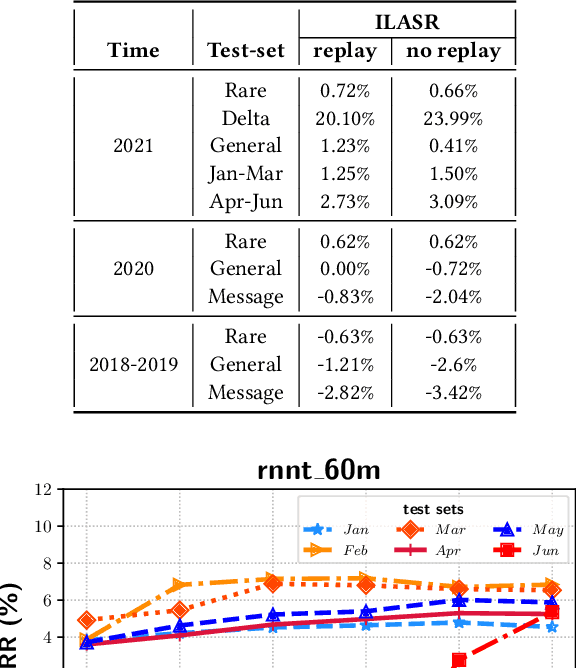
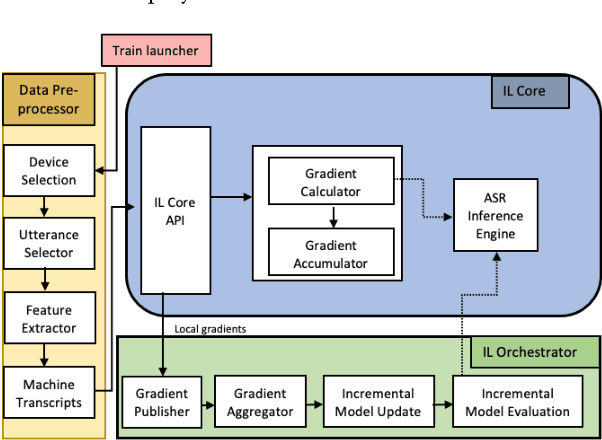
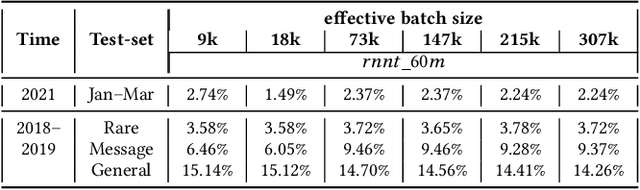
Incremental learning is one paradigm to enable model building and updating at scale with streaming data. For end-to-end automatic speech recognition (ASR) tasks, the absence of human annotated labels along with the need for privacy preserving policies for model building makes it a daunting challenge. Motivated by these challenges, in this paper we use a cloud based framework for production systems to demonstrate insights from privacy preserving incremental learning for automatic speech recognition (ILASR). By privacy preserving, we mean, usage of ephemeral data which are not human annotated. This system is a step forward for production levelASR models for incremental/continual learning that offers near real-time test-bed for experimentation in the cloud for end-to-end ASR, while adhering to privacy-preserving policies. We show that the proposed system can improve the production models significantly(3%) over a new time period of six months even in the absence of human annotated labels with varying levels of weak supervision and large batch sizes in incremental learning. This improvement is 20% over test sets with new words and phrases in the new time period. We demonstrate the effectiveness of model building in a privacy-preserving incremental fashion for ASR while further exploring the utility of having an effective teacher model and use of large batch sizes.
Compute Cost Amortized Transformer for Streaming ASR
Jul 05, 2022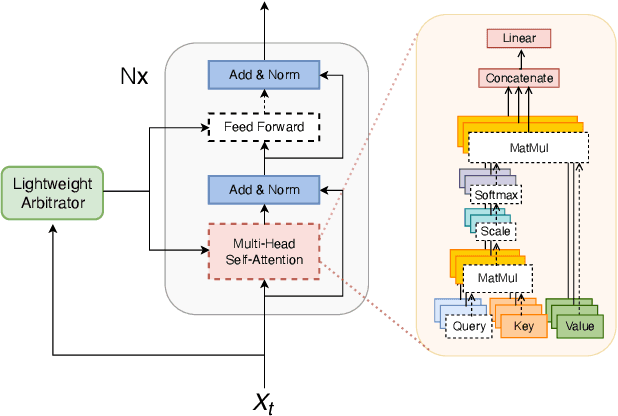
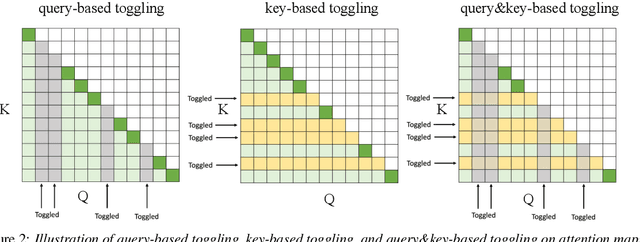
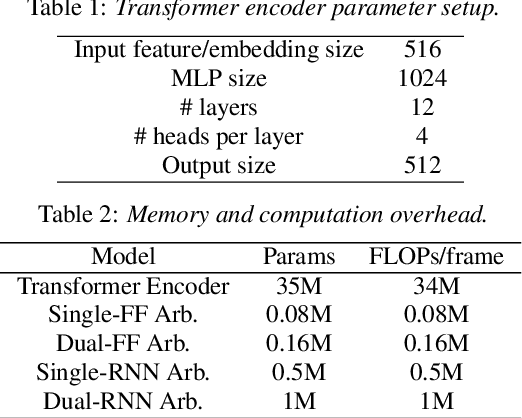
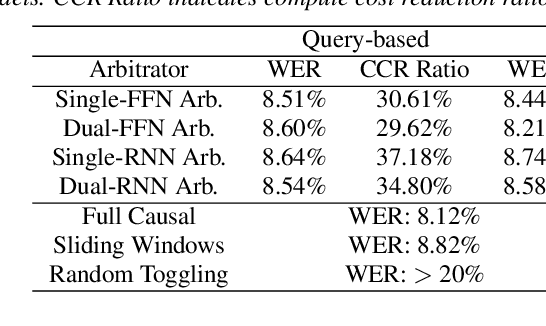
We present a streaming, Transformer-based end-to-end automatic speech recognition (ASR) architecture which achieves efficient neural inference through compute cost amortization. Our architecture creates sparse computation pathways dynamically at inference time, resulting in selective use of compute resources throughout decoding, enabling significant reductions in compute with minimal impact on accuracy. The fully differentiable architecture is trained end-to-end with an accompanying lightweight arbitrator mechanism operating at the frame-level to make dynamic decisions on each input while a tunable loss function is used to regularize the overall level of compute against predictive performance. We report empirical results from experiments using the compute amortized Transformer-Transducer (T-T) model conducted on LibriSpeech data. Our best model can achieve a 60% compute cost reduction with only a 3% relative word error rate (WER) increase.
Sub-8-Bit Quantization Aware Training for 8-Bit Neural Network Accelerator with On-Device Speech Recognition
Jun 30, 2022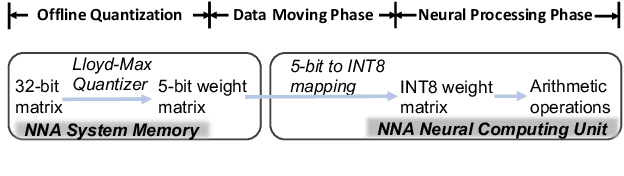
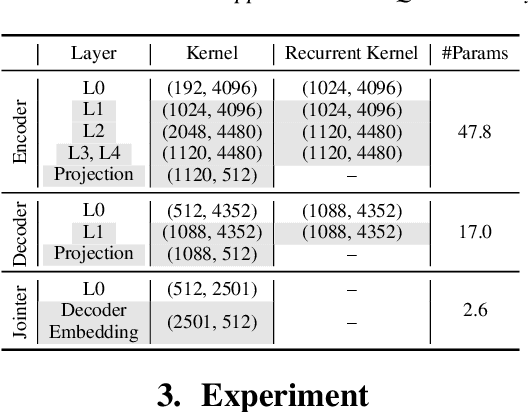
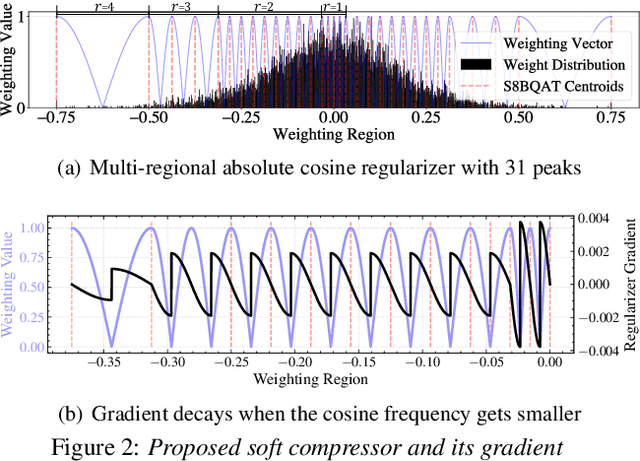
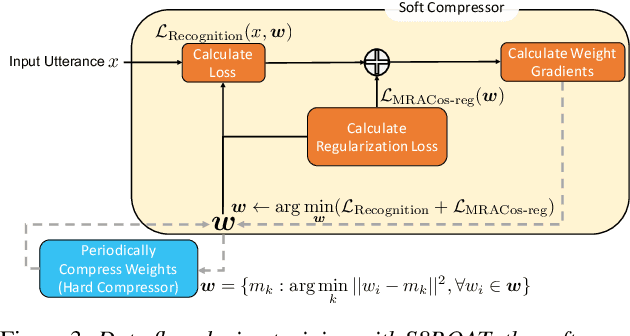
We present a novel sub-8-bit quantization-aware training (S8BQAT) scheme for 8-bit neural network accelerators. Our method is inspired from Lloyd-Max compression theory with practical adaptations for a feasible computational overhead during training. With the quantization centroids derived from a 32-bit baseline, we augment training loss with a Multi-Regional Absolute Cosine (MRACos) regularizer that aggregates weights towards their nearest centroid, effectively acting as a pseudo compressor. Additionally, a periodically invoked hard compressor is introduced to improve the convergence rate by emulating runtime model weight quantization. We apply S8BQAT on speech recognition tasks using Recurrent Neural NetworkTransducer (RNN-T) architecture. With S8BQAT, we are able to increase the model parameter size to reduce the word error rate by 4-16% relatively, while still improving latency by 5%.
RescoreBERT: Discriminative Speech Recognition Rescoring with BERT
Feb 07, 2022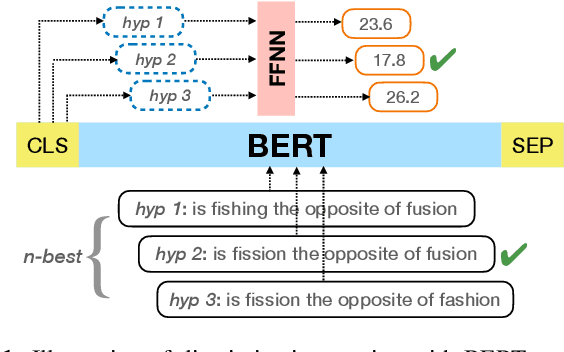
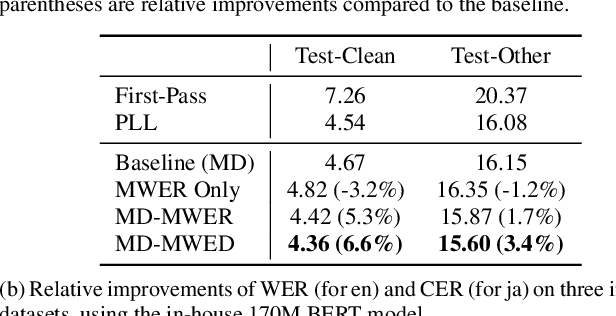

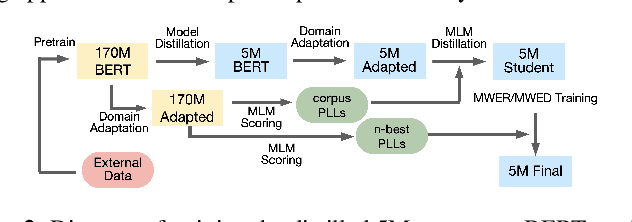
Second-pass rescoring is an important component in automatic speech recognition (ASR) systems that is used to improve the outputs from a first-pass decoder by implementing a lattice rescoring or $n$-best re-ranking. While pretraining with a masked language model (MLM) objective has received great success in various natural language understanding (NLU) tasks, it has not gained traction as a rescoring model for ASR. Specifically, training a bidirectional model like BERT on a discriminative objective such as minimum WER (MWER) has not been explored. Here we show how to train a BERT-based rescoring model with MWER loss, to incorporate the improvements of a discriminative loss into fine-tuning of deep bidirectional pretrained models for ASR. Specifically, we propose a fusion strategy that incorporates the MLM into the discriminative training process to effectively distill knowledge from a pretrained model. We further propose an alternative discriminative loss. We name this approach RescoreBERT. On the LibriSpeech corpus, it reduces WER by 6.6%/3.4% relative on clean/other test sets over a BERT baseline without discriminative objective. We also evaluate our method on an internal dataset from a conversational agent and find that it reduces both latency and WER (by 3 to 8% relative) over an LSTM rescoring model.
Attentive Contextual Carryover for Multi-Turn End-to-End Spoken Language Understanding
Dec 13, 2021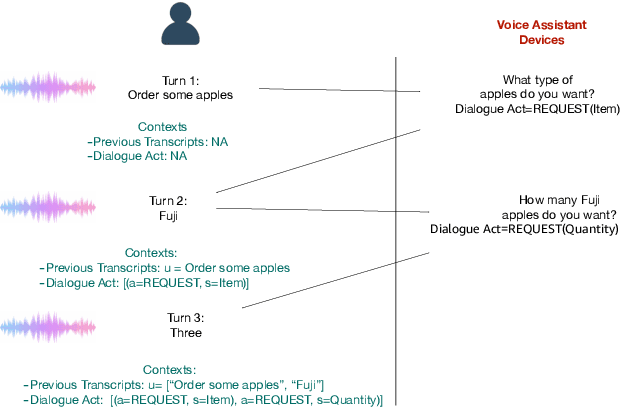
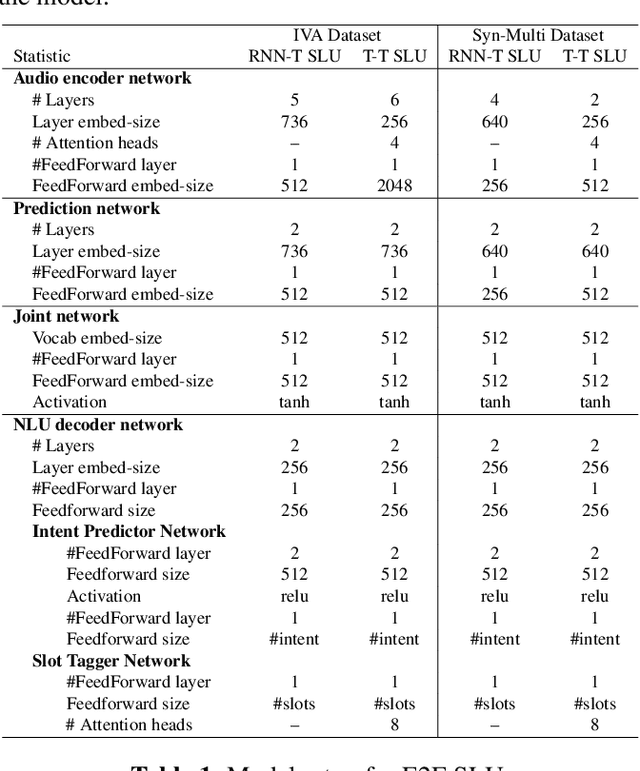
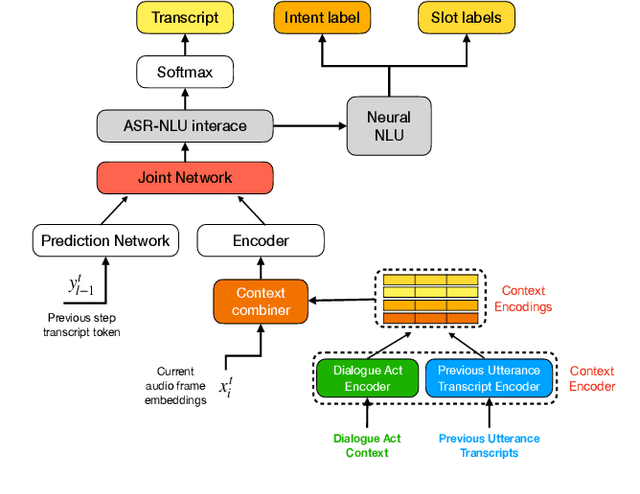
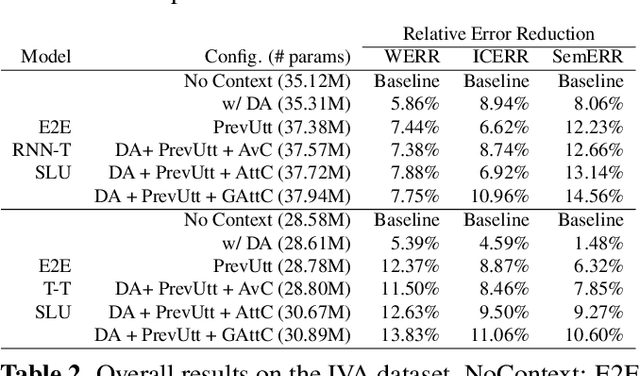
Recent years have seen significant advances in end-to-end (E2E) spoken language understanding (SLU) systems, which directly predict intents and slots from spoken audio. While dialogue history has been exploited to improve conventional text-based natural language understanding systems, current E2E SLU approaches have not yet incorporated such critical contextual signals in multi-turn and task-oriented dialogues. In this work, we propose a contextual E2E SLU model architecture that uses a multi-head attention mechanism over encoded previous utterances and dialogue acts (actions taken by the voice assistant) of a multi-turn dialogue. We detail alternative methods to integrate these contexts into the state-ofthe-art recurrent and transformer-based models. When applied to a large de-identified dataset of utterances collected by a voice assistant, our method reduces average word and semantic error rates by 10.8% and 12.6%, respectively. We also present results on a publicly available dataset and show that our method significantly improves performance over a noncontextual baseline
Context-Aware Transformer Transducer for Speech Recognition
Nov 05, 2021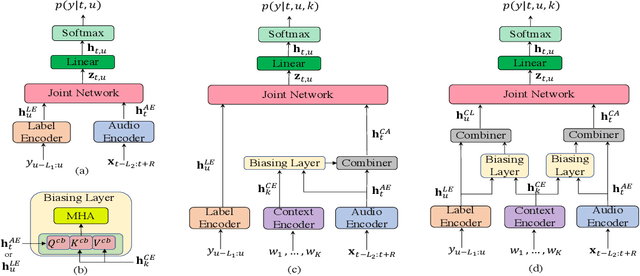

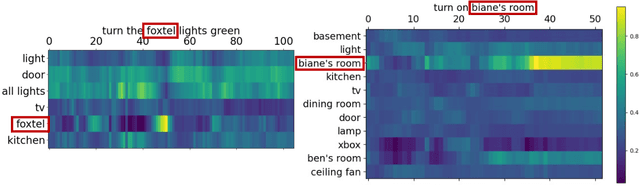
End-to-end (E2E) automatic speech recognition (ASR) systems often have difficulty recognizing uncommon words, that appear infrequently in the training data. One promising method, to improve the recognition accuracy on such rare words, is to latch onto personalized/contextual information at inference. In this work, we present a novel context-aware transformer transducer (CATT) network that improves the state-of-the-art transformer-based ASR system by taking advantage of such contextual signals. Specifically, we propose a multi-head attention-based context-biasing network, which is jointly trained with the rest of the ASR sub-networks. We explore different techniques to encode contextual data and to create the final attention context vectors. We also leverage both BLSTM and pretrained BERT based models to encode contextual data and guide the network training. Using an in-house far-field dataset, we show that CATT, using a BERT based context encoder, improves the word error rate of the baseline transformer transducer and outperforms an existing deep contextual model by 24.2% and 19.4% respectively.
FANS: Fusing ASR and NLU for on-device SLU
Oct 31, 2021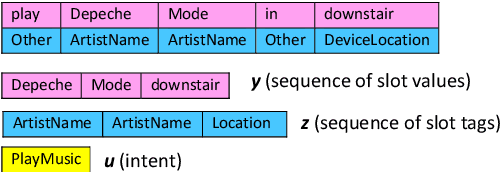
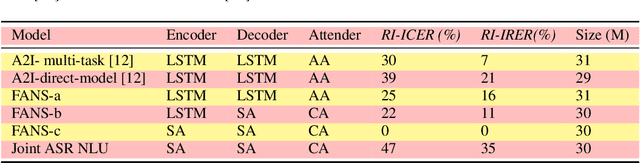
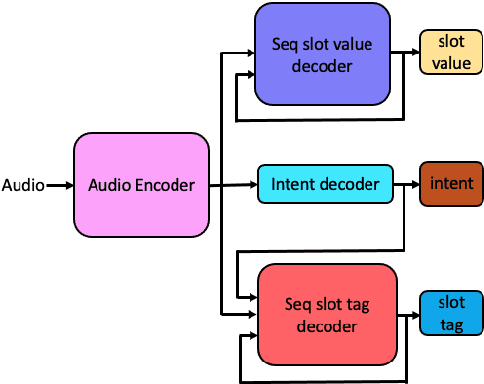
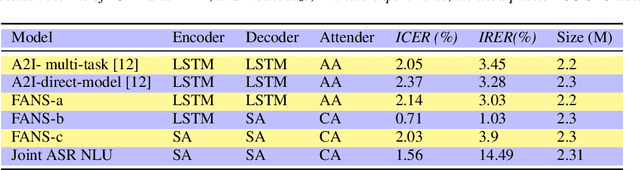
Spoken language understanding (SLU) systems translate voice input commands to semantics which are encoded as an intent and pairs of slot tags and values. Most current SLU systems deploy a cascade of two neural models where the first one maps the input audio to a transcript (ASR) and the second predicts the intent and slots from the transcript (NLU). In this paper, we introduce FANS, a new end-to-end SLU model that fuses an ASR audio encoder to a multi-task NLU decoder to infer the intent, slot tags, and slot values directly from a given input audio, obviating the need for transcription. FANS consists of a shared audio encoder and three decoders, two of which are seq-to-seq decoders that predict non null slot tags and slot values in parallel and in an auto-regressive manner. FANS neural encoder and decoders architectures are flexible which allows us to leverage different combinations of LSTM, self-attention, and attenders. Our experiments show compared to the state-of-the-art end-to-end SLU models, FANS reduces ICER and IRER errors relatively by 30 % and 7 %, respectively, when tested on an in-house SLU dataset and by 0.86 % and 2 % absolute when tested on a public SLU dataset.
Learning a Neural Diff for Speech Models
Aug 17, 2021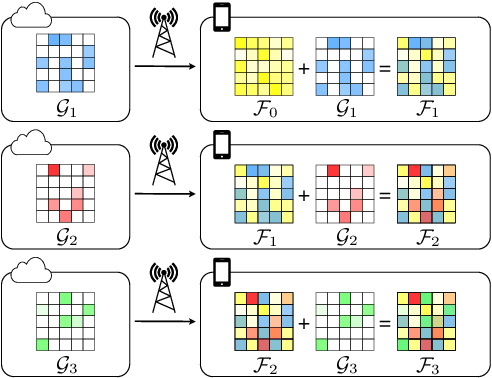
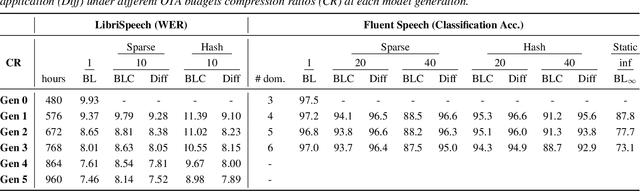
As more speech processing applications execute locally on edge devices, a set of resource constraints must be considered. In this work we address one of these constraints, namely over-the-network data budgets for transferring models from server to device. We present neural update approaches for release of subsequent speech model generations abiding by a data budget. We detail two architecture-agnostic methods which learn compact representations for transmission to devices. We experimentally validate our techniques with results on two tasks (automatic speech recognition and spoken language understanding) on open source data sets by demonstrating when applied in succession, our budgeted updates outperform comparable model compression baselines by significant margins.
Bifocal Neural ASR: Exploiting Keyword Spotting for Inference Optimization
Aug 03, 2021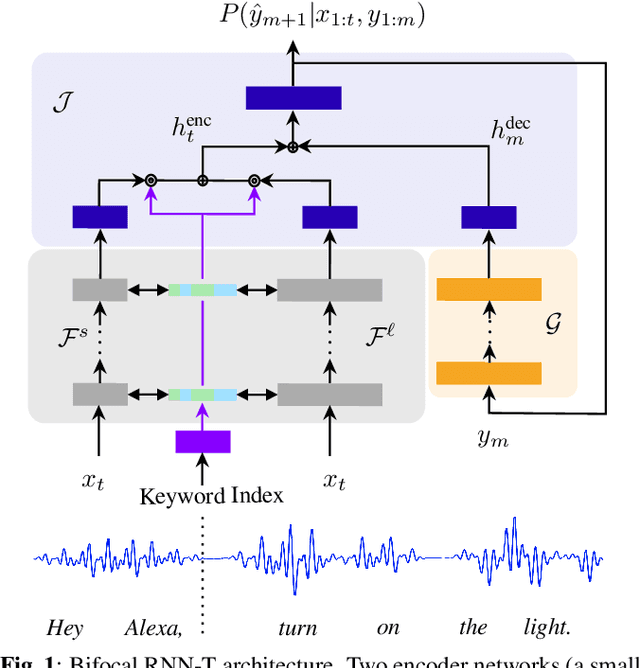
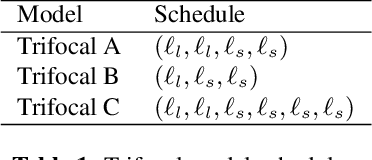
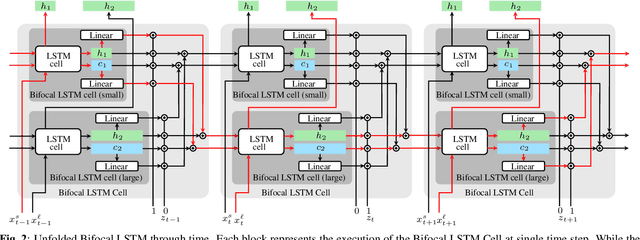
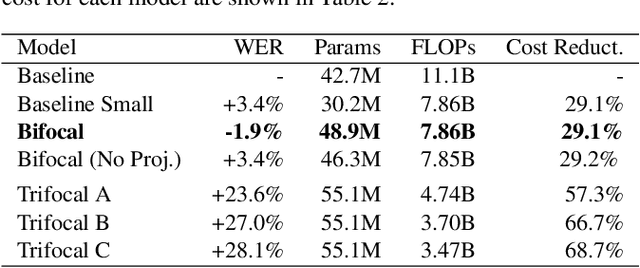
We present Bifocal RNN-T, a new variant of the Recurrent Neural Network Transducer (RNN-T) architecture designed for improved inference time latency on speech recognition tasks. The architecture enables a dynamic pivot for its runtime compute pathway, namely taking advantage of keyword spotting to select which component of the network to execute for a given audio frame. To accomplish this, we leverage a recurrent cell we call the Bifocal LSTM (BFLSTM), which we detail in the paper. The architecture is compatible with other optimization strategies such as quantization, sparsification, and applying time-reduction layers, making it especially applicable for deployed, real-time speech recognition settings. We present the architecture and report comparative experimental results on voice-assistant speech recognition tasks. Specifically, we show our proposed Bifocal RNN-T can improve inference cost by 29.1% with matching word error rates and only a minor increase in memory size.