 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoincidence, Categorization, and Consolidation: Learning to Recognize Sounds with Minimal Supervision
Nov 14, 2019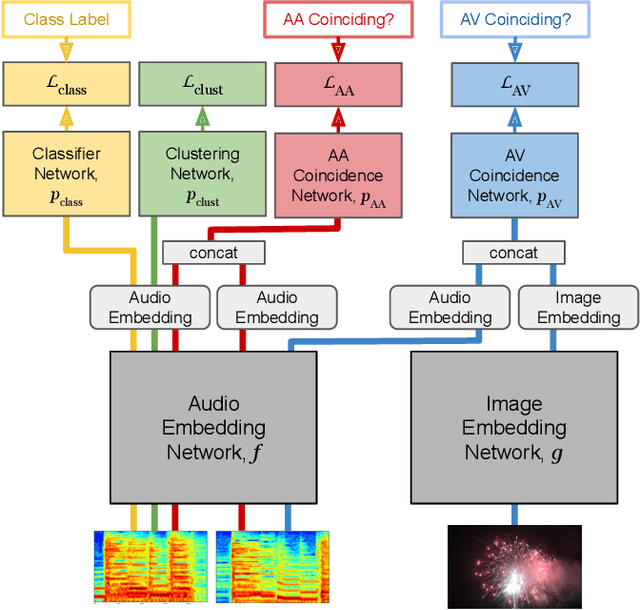
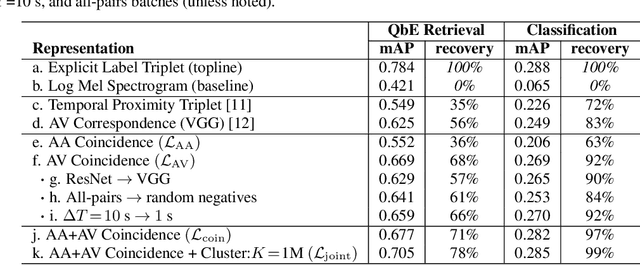
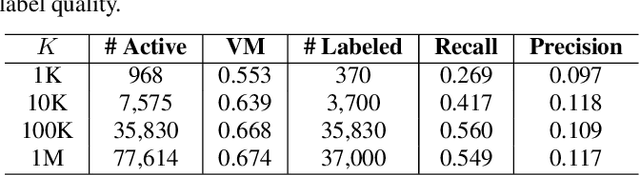
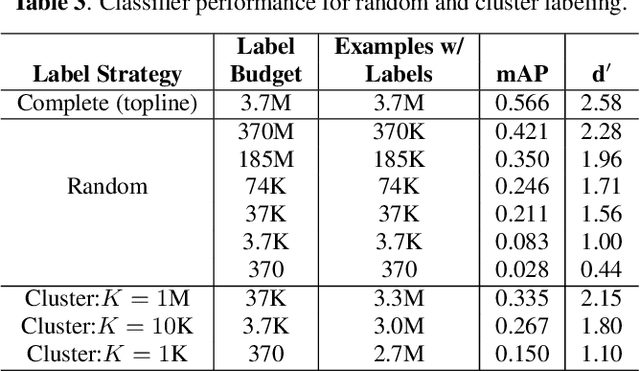
Humans do not acquire perceptual abilities in the way we train machines. While machine learning algorithms typically operate on large collections of randomly-chosen, explicitly-labeled examples, human acquisition relies more heavily on multimodal unsupervised learning (as infants) and active learning (as children). With this motivation, we present a learning framework for sound representation and recognition that combines (i) a self-supervised objective based on a general notion of unimodal and cross-modal coincidence, (ii) a clustering objective that reflects our need to impose categorical structure on our experiences, and (iii) a cluster-based active learning procedure that solicits targeted weak supervision to consolidate categories into relevant semantic classes. By training a combined sound embedding/clustering/classification network according to these criteria, we achieve a new state-of-the-art unsupervised audio representation and demonstrate up to a 20-fold reduction in the number of labels required to reach a desired classification performance.
Unsupervised Learning of Semantic Audio Representations
Nov 06, 2017
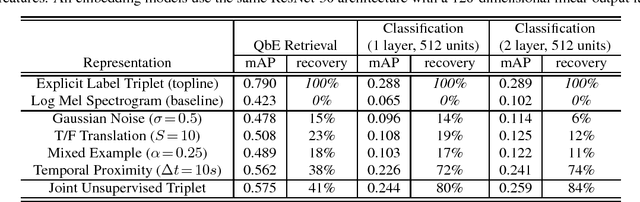
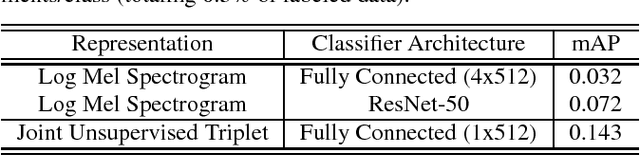
Even in the absence of any explicit semantic annotation, vast collections of audio recordings provide valuable information for learning the categorical structure of sounds. We consider several class-agnostic semantic constraints that apply to unlabeled nonspeech audio: (i) noise and translations in time do not change the underlying sound category, (ii) a mixture of two sound events inherits the categories of the constituents, and (iii) the categories of events in close temporal proximity are likely to be the same or related. Without labels to ground them, these constraints are incompatible with classification loss functions. However, they may still be leveraged to identify geometric inequalities needed for triplet loss-based training of convolutional neural networks. The result is low-dimensional embeddings of the input spectrograms that recover 41% and 84% of the performance of their fully-supervised counterparts when applied to downstream query-by-example sound retrieval and sound event classification tasks, respectively. Moreover, in limited-supervision settings, our unsupervised embeddings double the state-of-the-art classification performance.
A segmental framework for fully-unsupervised large-vocabulary speech recognition
Sep 16, 2017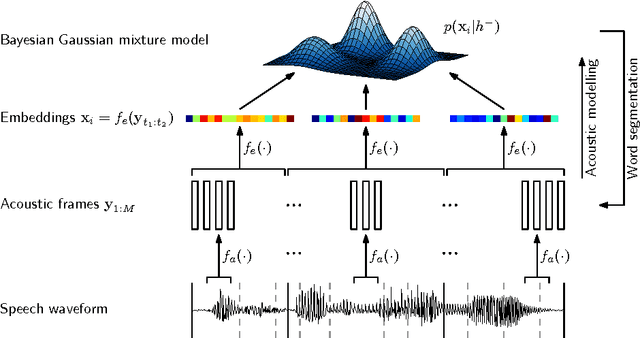
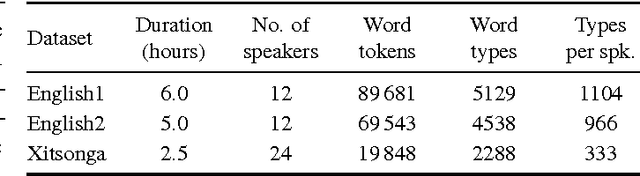
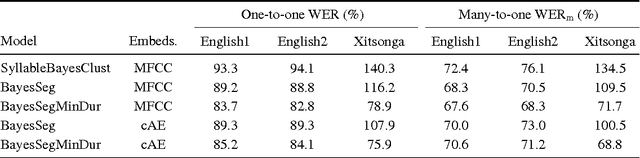
Zero-resource speech technology is a growing research area that aims to develop methods for speech processing in the absence of transcriptions, lexicons, or language modelling text. Early term discovery systems focused on identifying isolated recurring patterns in a corpus, while more recent full-coverage systems attempt to completely segment and cluster the audio into word-like units---effectively performing unsupervised speech recognition. This article presents the first attempt we are aware of to apply such a system to large-vocabulary multi-speaker data. Our system uses a Bayesian modelling framework with segmental word representations: each word segment is represented as a fixed-dimensional acoustic embedding obtained by mapping the sequence of feature frames to a single embedding vector. We compare our system on English and Xitsonga datasets to state-of-the-art baselines, using a variety of measures including word error rate (obtained by mapping the unsupervised output to ground truth transcriptions). Very high word error rates are reported---in the order of 70--80% for speaker-dependent and 80--95% for speaker-independent systems---highlighting the difficulty of this task. Nevertheless, in terms of cluster quality and word segmentation metrics, we show that by imposing a consistent top-down segmentation while also using bottom-up knowledge from detected syllable boundaries, both single-speaker and multi-speaker versions of our system outperform a purely bottom-up single-speaker syllable-based approach. We also show that the discovered clusters can be made less speaker- and gender-specific by using an unsupervised autoencoder-like feature extractor to learn better frame-level features (prior to embedding). Our system's discovered clusters are still less pure than those of unsupervised term discovery systems, but provide far greater coverage.
* 15 pages, 6 figures, 8 tables
CNN Architectures for Large-Scale Audio Classification
Jan 10, 2017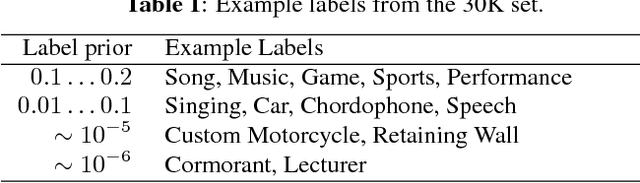
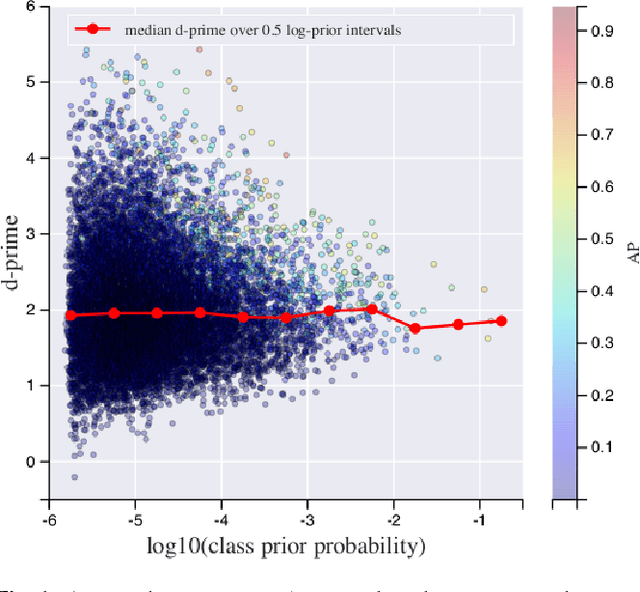
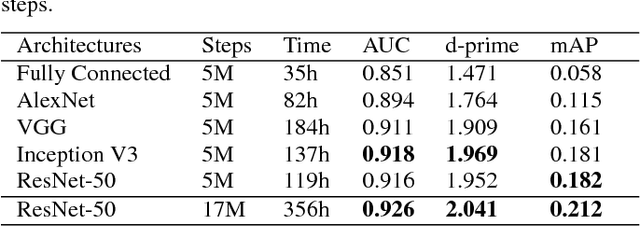
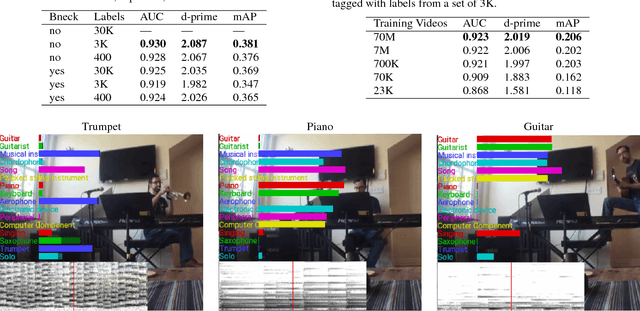
Convolutional Neural Networks (CNNs) have proven very effective in image classification and show promise for audio. We use various CNN architectures to classify the soundtracks of a dataset of 70M training videos (5.24 million hours) with 30,871 video-level labels. We examine fully connected Deep Neural Networks (DNNs), AlexNet [1], VGG [2], Inception [3], and ResNet [4]. We investigate varying the size of both training set and label vocabulary, finding that analogs of the CNNs used in image classification do well on our audio classification task, and larger training and label sets help up to a point. A model using embeddings from these classifiers does much better than raw features on the Audio Set [5] Acoustic Event Detection (AED) classification task.
Scalable Out-of-Sample Extension of Graph Embeddings Using Deep Neural Networks
Jun 14, 2016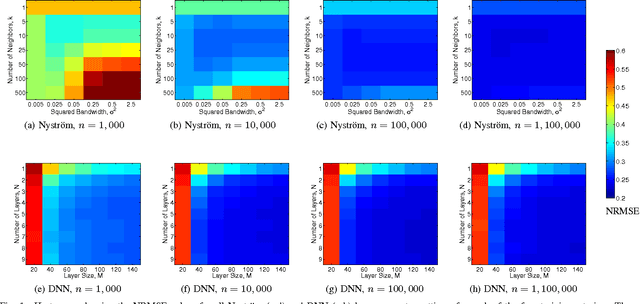
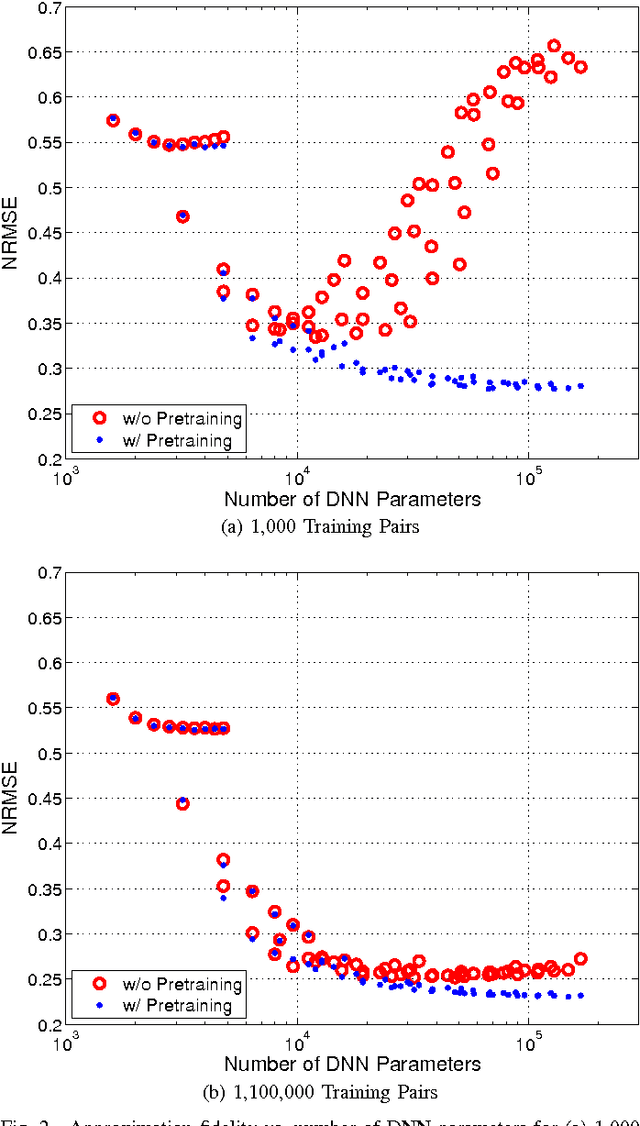
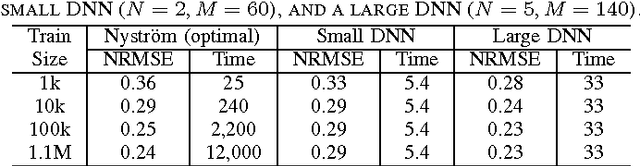
Several popular graph embedding techniques for representation learning and dimensionality reduction rely on performing computationally expensive eigendecompositions to derive a nonlinear transformation of the input data space. The resulting eigenvectors encode the embedding coordinates for the training samples only, and so the embedding of novel data samples requires further costly computation. In this paper, we present a method for the out-of-sample extension of graph embeddings using deep neural networks (DNN) to parametrically approximate these nonlinear maps. Compared with traditional nonparametric out-of-sample extension methods, we demonstrate that the DNNs can generalize with equal or better fidelity and require orders of magnitude less computation at test time. Moreover, we find that unsupervised pretraining of the DNNs improves optimization for larger network sizes, thus removing sensitivity to model selection.
Unsupervised word segmentation and lexicon discovery using acoustic word embeddings
Mar 09, 2016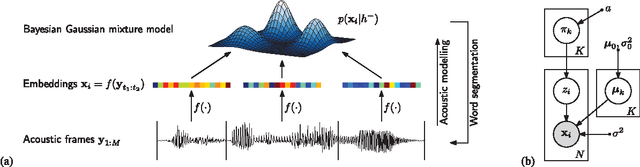

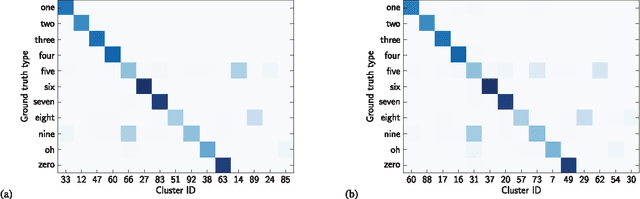
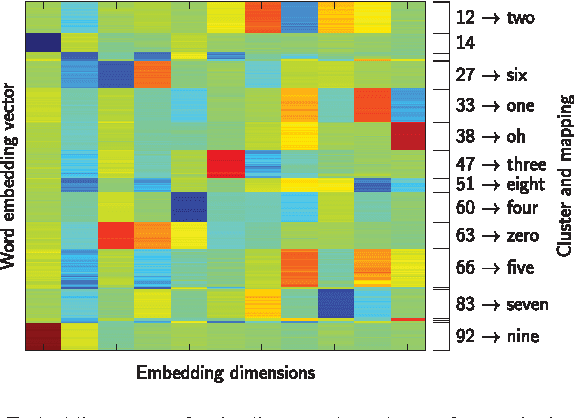
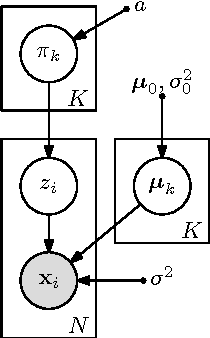
In settings where only unlabelled speech data is available, speech technology needs to be developed without transcriptions, pronunciation dictionaries, or language modelling text. A similar problem is faced when modelling infant language acquisition. In these cases, categorical linguistic structure needs to be discovered directly from speech audio. We present a novel unsupervised Bayesian model that segments unlabelled speech and clusters the segments into hypothesized word groupings. The result is a complete unsupervised tokenization of the input speech in terms of discovered word types. In our approach, a potential word segment (of arbitrary length) is embedded in a fixed-dimensional acoustic vector space. The model, implemented as a Gibbs sampler, then builds a whole-word acoustic model in this space while jointly performing segmentation. We report word error rates in a small-vocabulary connected digit recognition task by mapping the unsupervised decoded output to ground truth transcriptions. The model achieves around 20% error rate, outperforming a previous HMM-based system by about 10% absolute. Moreover, in contrast to the baseline, our model does not require a pre-specified vocabulary size.
* 11 pages, 8 figures; Accepted to the IEEE/ACM Transactions on Audio, Speech, and Language Processing