 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Assisted Digital Twin Creation for mmWave Beam Management
Jan 31, 2024



In the context of communication networks, digital twin technology provides a means to replicate the radio frequency (RF) propagation environment as well as the system behaviour, allowing for a way to optimize the performance of a deployed system based on simulations. One of the key challenges in the application of Digital Twin technology to mmWave systems is the prevalent channel simulators' stringent requirements on the accuracy of the 3D Digital Twin, reducing the feasibility of the technology in real applications. We propose a practical Digital Twin creation pipeline and a channel simulator, that relies only on a single mounted camera and position information. We demonstrate the performance benefits compared to methods that do not explicitly model the 3D environment, on downstream sub-tasks in beam acquisition, using the real-world dataset of the DeepSense6G challenge
Algebraic Topological Networks via the Persistent Local Homology Sheaf
Nov 16, 2023In this work, we introduce a novel approach based on algebraic topology to enhance graph convolution and attention modules by incorporating local topological properties of the data. To do so, we consider the framework of sheaf neural networks, which has been previously leveraged to incorporate additional structure into graph neural networks' features and construct more expressive, non-isotropic messages. Specifically, given an input simplicial complex (e.g. generated by the cliques of a graph or the neighbors in a point cloud), we construct its local homology sheaf, which assigns to each node the vector space of its local homology. The intermediate features of our networks live in these vector spaces and we leverage the associated sheaf Laplacian to construct more complex linear messages between them. Moreover, we extend this approach by considering the persistent version of local homology associated with a weighted simplicial complex (e.g., built from pairwise distances of nodes embeddings). This i) solves the problem of the lack of a natural choice of basis for the local homology vector spaces and ii) makes the sheaf itself differentiable, which enables our models to directly optimize the topology of their intermediate features.
Neural Lattice Reduction: A Self-Supervised Geometric Deep Learning Approach
Nov 14, 2023Lattice reduction is a combinatorial optimization problem aimed at finding the most orthogonal basis in a given lattice. In this work, we address lattice reduction via deep learning methods. We design a deep neural model outputting factorized unimodular matrices and train it in a self-supervised manner by penalizing non-orthogonal lattice bases. We incorporate the symmetries of lattice reduction into the model by making it invariant and equivariant with respect to appropriate continuous and discrete groups.
Transformer-Based Neural Surrogate for Link-Level Path Loss Prediction from Variable-Sized Maps
Oct 10, 2023Estimating path loss for a transmitter-receiver location is key to many use-cases including network planning and handover. Machine learning has become a popular tool to predict wireless channel properties based on map data. In this work, we present a transformer-based neural network architecture that enables predicting link-level properties from maps of various dimensions and from sparse measurements. The map contains information about buildings and foliage. The transformer model attends to the regions that are relevant for path loss prediction and, therefore, scales efficiently to maps of different size. Further, our approach works with continuous transmitter and receiver coordinates without relying on discretization. In experiments, we show that the proposed model is able to efficiently learn dominant path losses from sparse training data and generalizes well when tested on novel maps.
Pruning vs Quantization: Which is Better?
Jul 06, 2023Neural network pruning and quantization techniques are almost as old as neural networks themselves. However, to date only ad-hoc comparisons between the two have been published. In this paper, we set out to answer the question on which is better: neural network quantization or pruning? By answering this question, we hope to inform design decisions made on neural network hardware going forward. We provide an extensive comparison between the two techniques for compressing deep neural networks. First, we give an analytical comparison of expected quantization and pruning error for general data distributions. Then, we provide lower bounds for the per-layer pruning and quantization error in trained networks, and compare these to empirical error after optimization. Finally, we provide an extensive experimental comparison for training 8 large-scale models on 3 tasks. Our results show that in most cases quantization outperforms pruning. Only in some scenarios with very high compression ratio, pruning might be beneficial from an accuracy standpoint.
Beyond Codebook-Based Analog Beamforming at mmWave: Compressed Sensing and Machine Learning Methods
Nov 03, 2022



Analog beamforming is the predominant approach for millimeter wave (mmWave) communication given its favorable characteristics for limited-resource devices. In this work, we aim at reducing the spectral efficiency gap between analog and digital beamforming methods. We propose a method for refined beam selection based on the estimated raw channel. The channel estimation, an underdetermined problem, is solved using compressed sensing (CS) methods leveraging angular domain sparsity of the channel. To reduce the complexity of CS methods, we propose dictionary learning iterative soft-thresholding algorithm, which jointly learns the sparsifying dictionary and signal reconstruction. We evaluate the proposed method on a realistic mmWave setup and show considerable performance improvement with respect to code-book based analog beamforming approaches.
A PAC-Bayesian Generalization Bound for Equivariant Networks
Oct 24, 2022Equivariant networks capture the inductive bias about the symmetry of the learning task by building those symmetries into the model. In this paper, we study how equivariance relates to generalization error utilizing PAC Bayesian analysis for equivariant networks, where the transformation laws of feature spaces are determined by group representations. By using perturbation analysis of equivariant networks in Fourier domain for each layer, we derive norm-based PAC-Bayesian generalization bounds. The bound characterizes the impact of group size, and multiplicity and degree of irreducible representations on the generalization error and thereby provide a guideline for selecting them. In general, the bound indicates that using larger group size in the model improves the generalization error substantiated by extensive numerical experiments.
Multi-Modal Beam Prediction Challenge 2022: Towards Generalization
Sep 15, 2022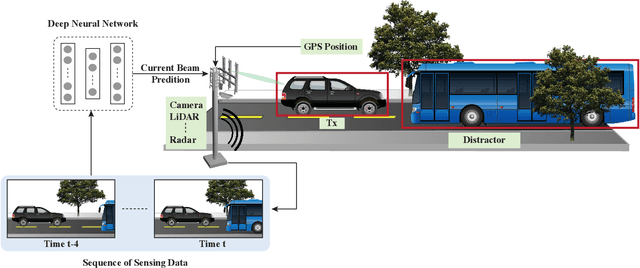
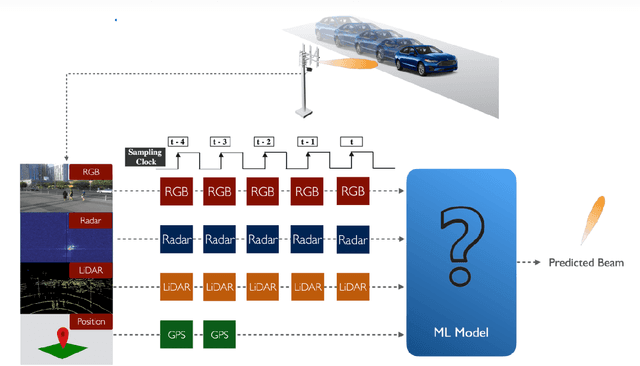

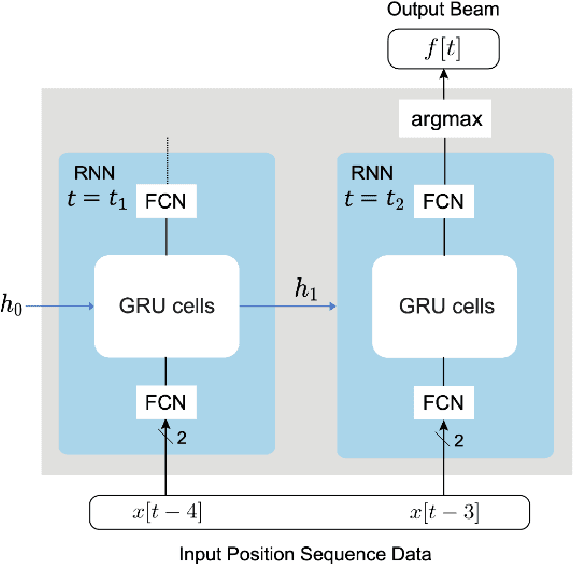
Beam management is a challenging task for millimeter wave (mmWave) and sub-terahertz communication systems, especially in scenarios with highly-mobile users. Leveraging external sensing modalities such as vision, LiDAR, radar, position, or a combination of them, to address this beam management challenge has recently attracted increasing interest from both academia and industry. This is mainly motivated by the dependency of the beam direction decision on the user location and the geometry of the surrounding environment -- information that can be acquired from the sensory data. To realize the promised beam management gains, such as the significant reduction in beam alignment overhead, in practice, however, these solutions need to account for important aspects. For example, these multi-modal sensing aided beam selection approaches should be able to generalize their learning to unseen scenarios and should be able to operate in realistic dense deployments. The "Multi-Modal Beam Prediction Challenge 2022: Towards Generalization" competition is offered to provide a platform for investigating these critical questions. In order to facilitate the generalizability study, the competition offers a large-scale multi-modal dataset with co-existing communication and sensing data collected across multiple real-world locations and different times of the day. In this paper, along with the detailed descriptions of the problem statement and the development dataset, we provide a baseline solution that utilizes the user position data to predict the optimal beam indices. The objective of this challenge is to go beyond a simple feasibility study and enable necessary research in this direction, paving the way towards generalizable multi-modal sensing-aided beam management for real-world future communication systems.
Quantized Sparse Weight Decomposition for Neural Network Compression
Jul 22, 2022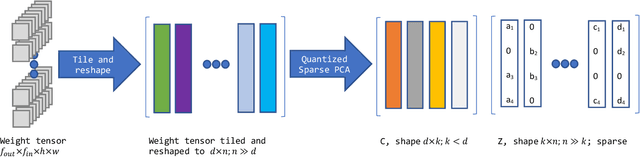
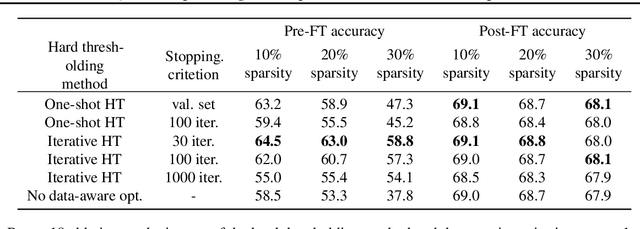
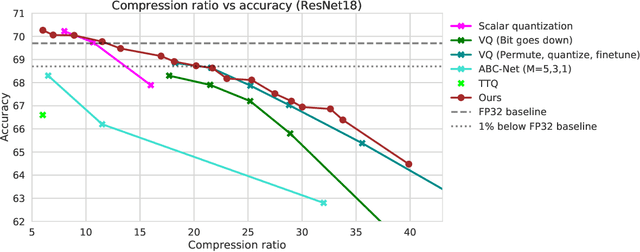
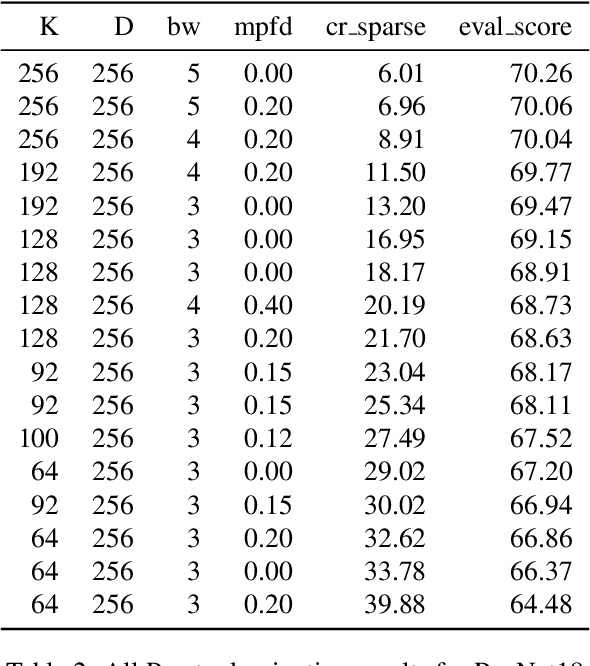
In this paper, we introduce a novel method of neural network weight compression. In our method, we store weight tensors as sparse, quantized matrix factors, whose product is computed on the fly during inference to generate the target model's weights. We use projected gradient descent methods to find quantized and sparse factorization of the weight tensors. We show that this approach can be seen as a unification of weight SVD, vector quantization, and sparse PCA. Combined with end-to-end fine-tuning our method exceeds or is on par with previous state-of-the-art methods in terms of the trade-off between accuracy and model size. Our method is applicable to both moderate compression regimes, unlike vector quantization, and extreme compression regimes.
Equivariant Priors for Compressed Sensing with Unknown Orientation
Jun 28, 2022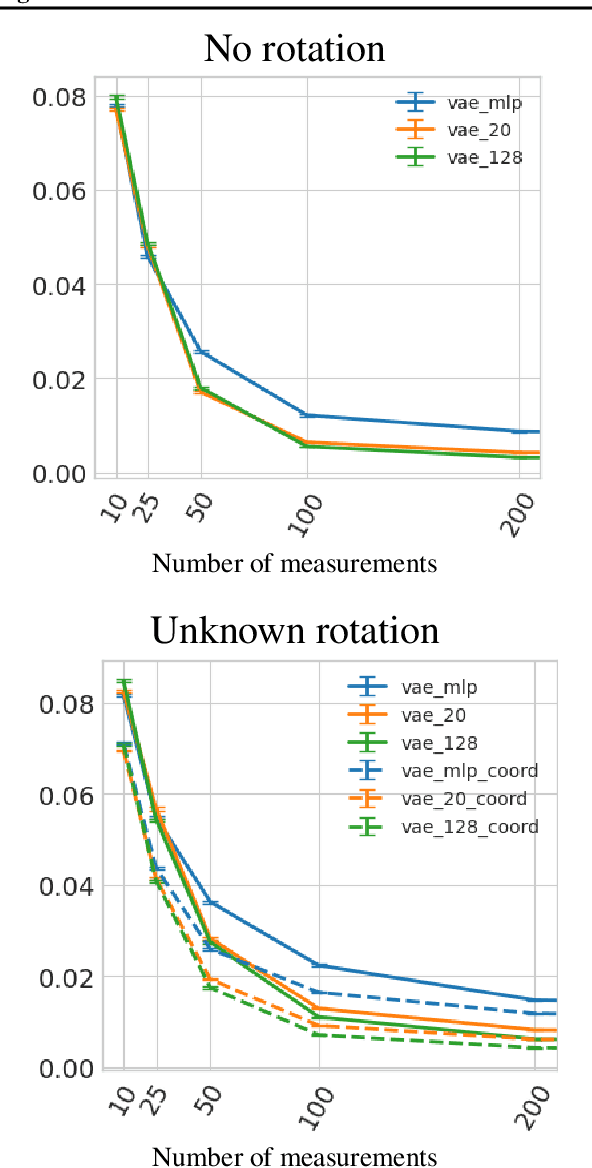
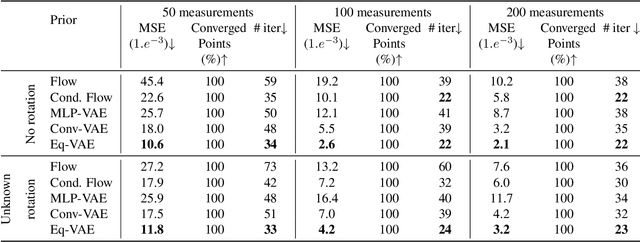
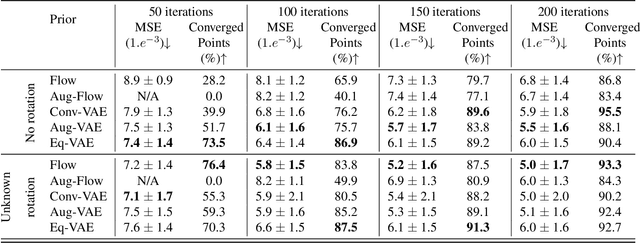
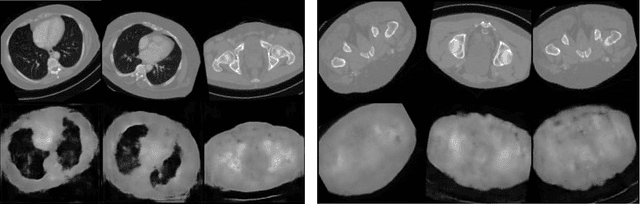
In compressed sensing, the goal is to reconstruct the signal from an underdetermined system of linear measurements. Thus, prior knowledge about the signal of interest and its structure is required. Additionally, in many scenarios, the signal has an unknown orientation prior to measurements. To address such recovery problems, we propose using equivariant generative models as a prior, which encapsulate orientation information in their latent space. Thereby, we show that signals with unknown orientations can be recovered with iterative gradient descent on the latent space of these models and provide additional theoretical recovery guarantees. We construct an equivariant variational autoencoder and use the decoder as generative prior for compressed sensing. We discuss additional potential gains of the proposed approach in terms of convergence and latency.