 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reasoning on the Edge
Mar 17, 2026Large language models (LLMs) with chain-of-thought reasoning achieve state-of-the-art performance across complex problem-solving tasks, but their verbose reasoning traces and large context requirements make them impractical for edge deployment. These challenges include high token generation costs, large KV-cache footprints, and inefficiencies when distilling reasoning capabilities into smaller models for mobile devices. Existing approaches often rely on distilling reasoning traces from larger models into smaller models, which are verbose and stylistically redundant, undesirable for on-device inference. In this work, we propose a lightweight approach to enable reasoning in small LLMs using LoRA adapters combined with supervised fine-tuning. We further introduce budget forcing via reinforcement learning on these adapters, significantly reducing response length with minimal accuracy loss. To address memory-bound decoding, we exploit parallel test-time scaling, improving accuracy at minor latency increase. Finally, we present a dynamic adapter-switching mechanism that activates reasoning only when needed and a KV-cache sharing strategy during prompt encoding, reducing time-to-first-token for on-device inference. Experiments on Qwen2.5-7B demonstrate that our method achieves efficient, accurate reasoning under strict resource constraints, making LLM reasoning practical for mobile scenarios. Videos demonstrating our solution running on mobile devices are available on our project page.
Reasoning as Compression: Unifying Budget Forcing via the Conditional Information Bottleneck
Mar 09, 2026Chain-of-Thought (CoT) prompting improves LLM accuracy on complex tasks but often increases token usage and inference cost. Existing "Budget Forcing" methods reducing cost via fine-tuning with heuristic length penalties, suppress both essential reasoning and redundant filler. We recast efficient reasoning as a lossy compression problem under the Information Bottleneck (IB) principle, and identify a key theoretical gap when applying naive IB to transformers: attention violates the Markov property between prompt, reasoning trace, and response. To resolve this issue, we model CoT generation under the Conditional Information Bottleneck (CIB) principle, where the reasoning trace Z acts as a computational bridge that contains only the information about the response Y that is not directly accessible from the prompt X. This yields a general Reinforcement Learning objective: maximize task reward while compressing completions under a prior over reasoning traces, subsuming common heuristics (e.g., length penalties) as special cases (e.g., uniform priors). In contrast to naive token-counting-based approaches, we introduce a semantic prior that measures token cost by surprisal under a language model prior. Empirically, our CIB objective prunes cognitive bloat while preserving fluency and logic, improving accuracy at moderate compression and enabling aggressive compression with minimal accuracy drop.
LUMINA: Long-horizon Understanding for Multi-turn Interactive Agents
Jan 23, 2026Large language models can perform well on many isolated tasks, yet they continue to struggle on multi-turn, long-horizon agentic problems that require skills such as planning, state tracking, and long context processing. In this work, we aim to better understand the relative importance of advancing these underlying capabilities for success on such tasks. We develop an oracle counterfactual framework for multi-turn problems that asks: how would an agent perform if it could leverage an oracle to perfectly perform a specific task? The change in the agent's performance due to this oracle assistance allows us to measure the criticality of such oracle skill in the future advancement of AI agents. We introduce a suite of procedurally generated, game-like tasks with tunable complexity. These controlled environments allow us to provide precise oracle interventions, such as perfect planning or flawless state tracking, and make it possible to isolate the contribution of each oracle without confounding effects present in real-world benchmarks. Our results show that while some interventions (e.g., planning) consistently improve performance across settings, the usefulness of other skills is dependent on the properties of the environment and language model. Our work sheds light on the challenges of multi-turn agentic environments to guide the future efforts in the development of AI agents and language models.
Fundamental bounds on efficiency-confidence trade-off for transductive conformal prediction
Sep 04, 2025Transductive conformal prediction addresses the simultaneous prediction for multiple data points. Given a desired confidence level, the objective is to construct a prediction set that includes the true outcomes with the prescribed confidence. We demonstrate a fundamental trade-off between confidence and efficiency in transductive methods, where efficiency is measured by the size of the prediction sets. Specifically, we derive a strict finite-sample bound showing that any non-trivial confidence level leads to exponential growth in prediction set size for data with inherent uncertainty. The exponent scales linearly with the number of samples and is proportional to the conditional entropy of the data. Additionally, the bound includes a second-order term, dispersion, defined as the variance of the log conditional probability distribution. We show that this bound is achievable in an idealized setting. Finally, we examine a special case of transductive prediction where all test data points share the same label. We show that this scenario reduces to the hypothesis testing problem with empirically observed statistics and provide an asymptotically optimal confidence predictor, along with an analysis of the error exponent.
Reinforcement Learning of Adaptive Acquisition Policies for Inverse Problems
Jul 10, 2024



A promising way to mitigate the expensive process of obtaining a high-dimensional signal is to acquire a limited number of low-dimensional measurements and solve an under-determined inverse problem by utilizing the structural prior about the signal. In this paper, we focus on adaptive acquisition schemes to save further the number of measurements. To this end, we propose a reinforcement learning-based approach that sequentially collects measurements to better recover the underlying signal by acquiring fewer measurements. Our approach applies to general inverse problems with continuous action spaces and jointly learns the recovery algorithm. Using insights obtained from theoretical analysis, we also provide a probabilistic design for our methods using variational formulation. We evaluate our approach on multiple datasets and with two measurement spaces (Gaussian, Radon). Our results confirm the benefits of adaptive strategies in low-acquisition horizon settings.
Variational Learning ISTA
Jul 09, 2024Compressed sensing combines the power of convex optimization techniques with a sparsity-inducing prior on the signal space to solve an underdetermined system of equations. For many problems, the sparsifying dictionary is not directly given, nor its existence can be assumed. Besides, the sensing matrix can change across different scenarios. Addressing these issues requires solving a sparse representation learning problem, namely dictionary learning, taking into account the epistemic uncertainty of the learned dictionaries and, finally, jointly learning sparse representations and reconstructions under varying sensing matrix conditions. We address both concerns by proposing a variant of the LISTA architecture. First, we introduce Augmented Dictionary Learning ISTA (A-DLISTA), which incorporates an augmentation module to adapt parameters to the current measurement setup. Then, we propose to learn a distribution over dictionaries via a variational approach, dubbed Variational Learning ISTA (VLISTA). VLISTA exploits A-DLISTA as the likelihood model and approximates a posterior distribution over the dictionaries as part of an unfolded LISTA-based recovery algorithm. As a result, VLISTA provides a probabilistic way to jointly learn the dictionary distribution and the reconstruction algorithm with varying sensing matrices. We provide theoretical and experimental support for our architecture and show that our model learns calibrated uncertainties.
Simulating, Fast and Slow: Learning Policies for Black-Box Optimization
Jun 06, 2024



In recent years, solving optimization problems involving black-box simulators has become a point of focus for the machine learning community due to their ubiquity in science and engineering. The simulators describe a forward process $f_{\mathrm{sim}}: (\psi, x) \rightarrow y$ from simulation parameters $\psi$ and input data $x$ to observations $y$, and the goal of the optimization problem is to find parameters $\psi$ that minimize a desired loss function. Sophisticated optimization algorithms typically require gradient information regarding the forward process, $f_{\mathrm{sim}}$, with respect to the parameters $\psi$. However, obtaining gradients from black-box simulators can often be prohibitively expensive or, in some cases, impossible. Furthermore, in many applications, practitioners aim to solve a set of related problems. Thus, starting the optimization ``ab initio", i.e. from scratch, each time might be inefficient if the forward model is expensive to evaluate. To address those challenges, this paper introduces a novel method for solving classes of similar black-box optimization problems by learning an active learning policy that guides a differentiable surrogate's training and uses the surrogate's gradients to optimize the simulation parameters with gradient descent. After training the policy, downstream optimization of problems involving black-box simulators requires up to $\sim$90\% fewer expensive simulator calls compared to baselines such as local surrogate-based approaches, numerical optimization, and Bayesian methods.
Vision-Assisted Digital Twin Creation for mmWave Beam Management
Jan 31, 2024



In the context of communication networks, digital twin technology provides a means to replicate the radio frequency (RF) propagation environment as well as the system behaviour, allowing for a way to optimize the performance of a deployed system based on simulations. One of the key challenges in the application of Digital Twin technology to mmWave systems is the prevalent channel simulators' stringent requirements on the accuracy of the 3D Digital Twin, reducing the feasibility of the technology in real applications. We propose a practical Digital Twin creation pipeline and a channel simulator, that relies only on a single mounted camera and position information. We demonstrate the performance benefits compared to methods that do not explicitly model the 3D environment, on downstream sub-tasks in beam acquisition, using the real-world dataset of the DeepSense6G challenge
Beyond Codebook-Based Analog Beamforming at mmWave: Compressed Sensing and Machine Learning Methods
Nov 03, 2022



Analog beamforming is the predominant approach for millimeter wave (mmWave) communication given its favorable characteristics for limited-resource devices. In this work, we aim at reducing the spectral efficiency gap between analog and digital beamforming methods. We propose a method for refined beam selection based on the estimated raw channel. The channel estimation, an underdetermined problem, is solved using compressed sensing (CS) methods leveraging angular domain sparsity of the channel. To reduce the complexity of CS methods, we propose dictionary learning iterative soft-thresholding algorithm, which jointly learns the sparsifying dictionary and signal reconstruction. We evaluate the proposed method on a realistic mmWave setup and show considerable performance improvement with respect to code-book based analog beamforming approaches.
Equivariant Priors for Compressed Sensing with Unknown Orientation
Jun 28, 2022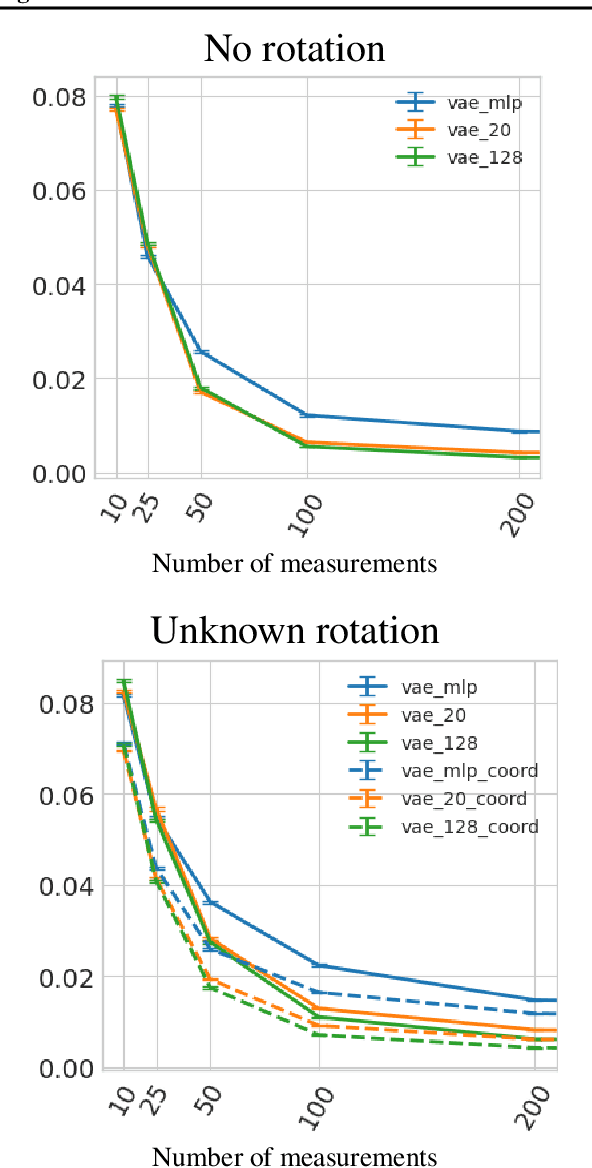
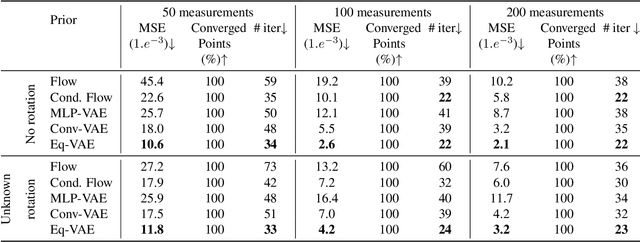
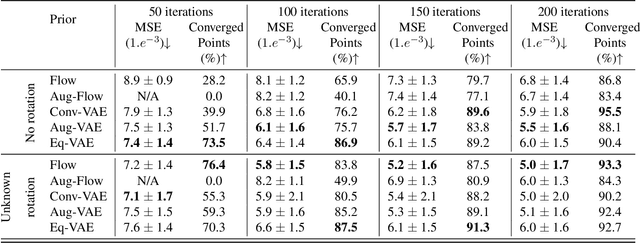
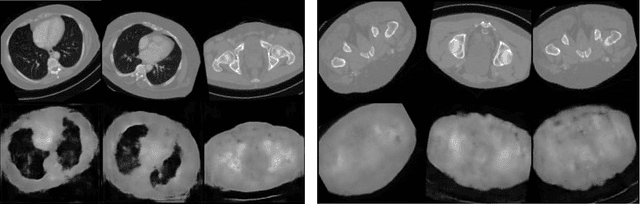
In compressed sensing, the goal is to reconstruct the signal from an underdetermined system of linear measurements. Thus, prior knowledge about the signal of interest and its structure is required. Additionally, in many scenarios, the signal has an unknown orientation prior to measurements. To address such recovery problems, we propose using equivariant generative models as a prior, which encapsulate orientation information in their latent space. Thereby, we show that signals with unknown orientations can be recovered with iterative gradient descent on the latent space of these models and provide additional theoretical recovery guarantees. We construct an equivariant variational autoencoder and use the decoder as generative prior for compressed sensing. We discuss additional potential gains of the proposed approach in terms of convergence and latency.