 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Question Answering: A Survey of Methods and Datasets
Jul 20, 2016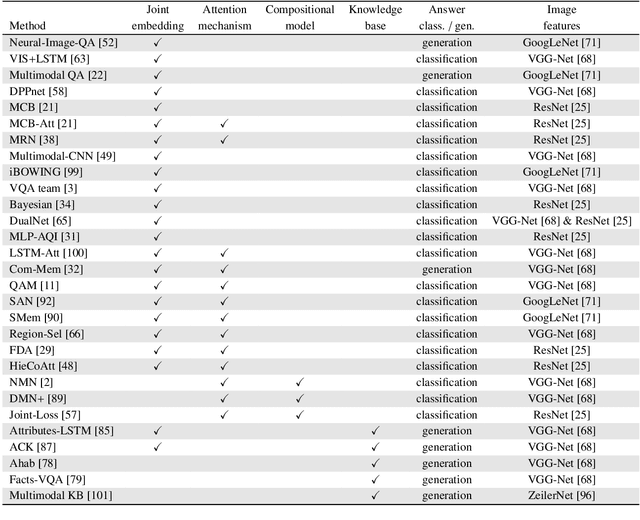
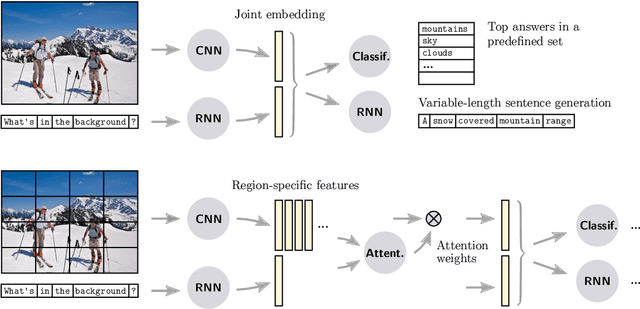
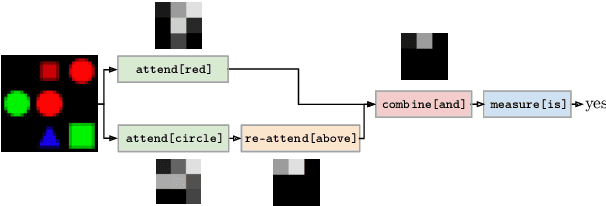
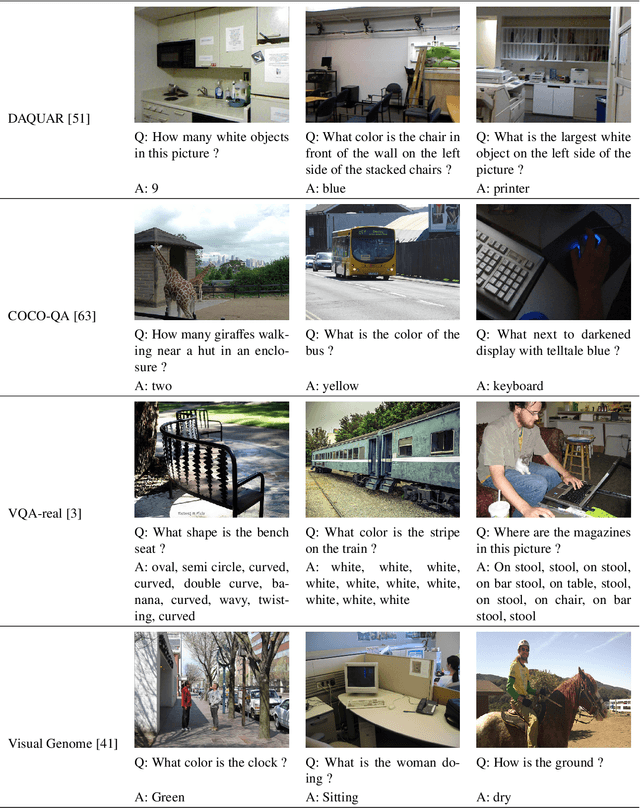
Visual Question Answering (VQA) is a challenging task that has received increasing attention from both the computer vision and the natural language processing communities. Given an image and a question in natural language, it requires reasoning over visual elements of the image and general knowledge to infer the correct answer. In the first part of this survey, we examine the state of the art by comparing modern approaches to the problem. We classify methods by their mechanism to connect the visual and textual modalities. In particular, we examine the common approach of combining convolutional and recurrent neural networks to map images and questions to a common feature space. We also discuss memory-augmented and modular architectures that interface with structured knowledge bases. In the second part of this survey, we review the datasets available for training and evaluating VQA systems. The various datatsets contain questions at different levels of complexity, which require different capabilities and types of reasoning. We examine in depth the question/answer pairs from the Visual Genome project, and evaluate the relevance of the structured annotations of images with scene graphs for VQA. Finally, we discuss promising future directions for the field, in particular the connection to structured knowledge bases and the use of natural language processing models.
PersonNet: Person Re-identification with Deep Convolutional Neural Networks
Jun 20, 2016
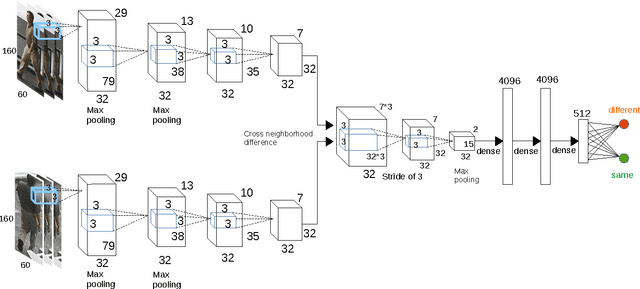
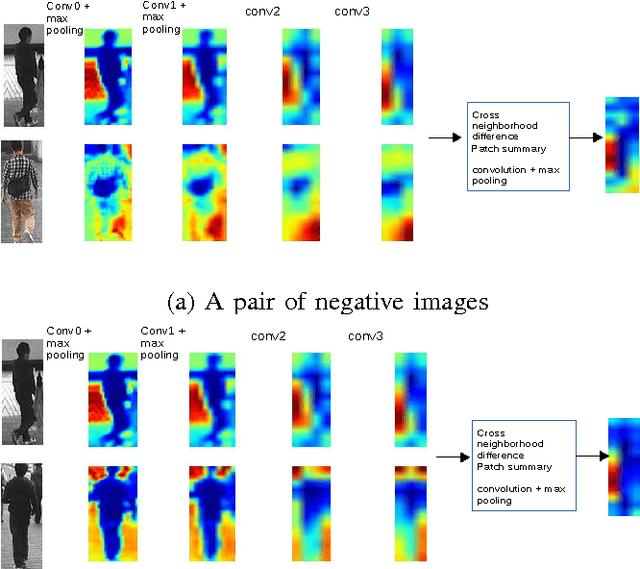
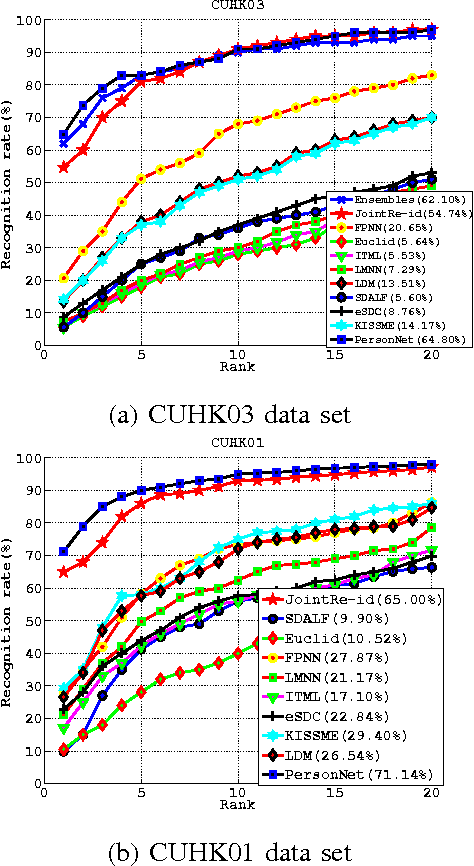
In this paper, we propose a deep end-to-end neu- ral network to simultaneously learn high-level features and a corresponding similarity metric for person re-identification. The network takes a pair of raw RGB images as input, and outputs a similarity value indicating whether the two input images depict the same person. A layer of computing neighborhood range differences across two input images is employed to capture local relationship between patches. This operation is to seek a robust feature from input images. By increasing the depth to 10 weight layers and using very small (3$\times$3) convolution filters, our architecture achieves a remarkable improvement on the prior-art configurations. Meanwhile, an adaptive Root- Mean-Square (RMSProp) gradient decent algorithm is integrated into our architecture, which is beneficial to deep nets. Our method consistently outperforms state-of-the-art on two large datasets (CUHK03 and Market-1501), and a medium-sized data set (CUHK01).
Deep Recurrent Convolutional Networks for Video-based Person Re-identification: An End-to-End Approach
Jun 12, 2016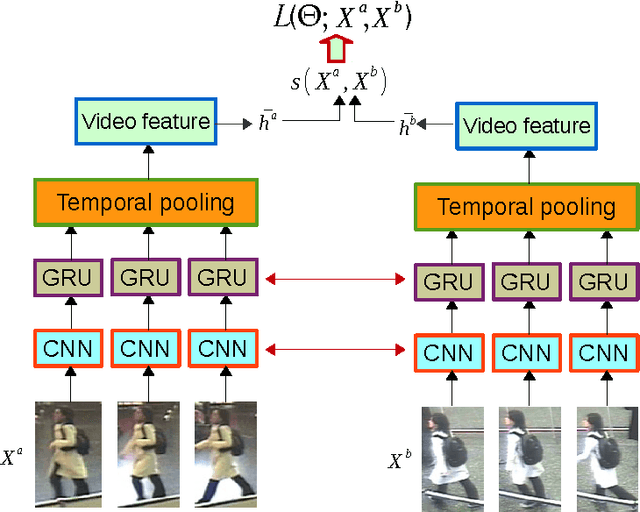
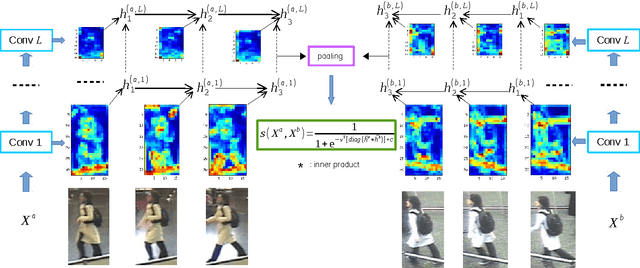
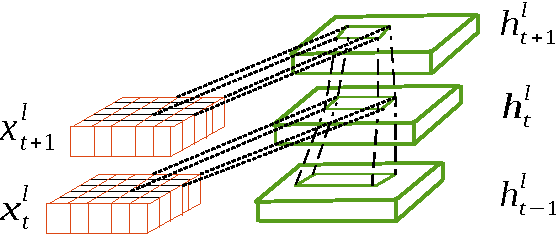
In this paper, we present an end-to-end approach to simultaneously learn spatio-temporal features and corresponding similarity metric for video-based person re-identification. Given the video sequence of a person, features from each frame that are extracted from all levels of a deep convolutional network can preserve a higher spatial resolution from which we can model finer motion patterns. These low-level visual percepts are leveraged into a variant of recurrent model to characterize the temporal variation between time-steps. Features from all time-steps are then summarized using temporal pooling to produce an overall feature representation for the complete sequence. The deep convolutional network, recurrent layer, and the temporal pooling are jointly trained to extract comparable hidden-unit representations from input pair of time series to compute their corresponding similarity value. The proposed framework combines time series modeling and metric learning to jointly learn relevant features and a good similarity measure between time sequences of person. Experiments demonstrate that our approach achieves the state-of-the-art performance for video-based person re-identification on iLIDS-VID and PRID 2011, the two primary public datasets for this purpose.
Pushing the Limits of Deep CNNs for Pedestrian Detection
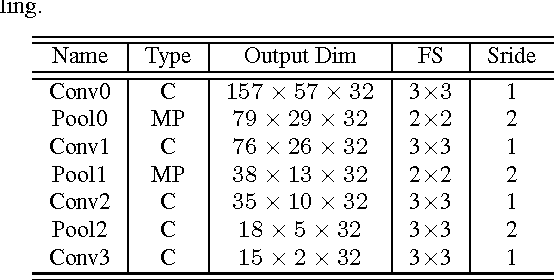
Jun 06, 2016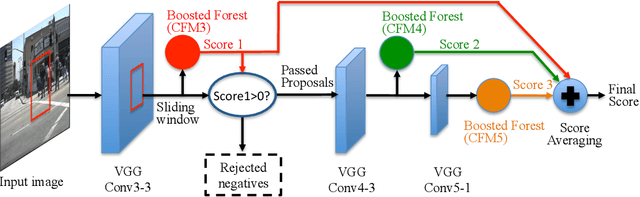
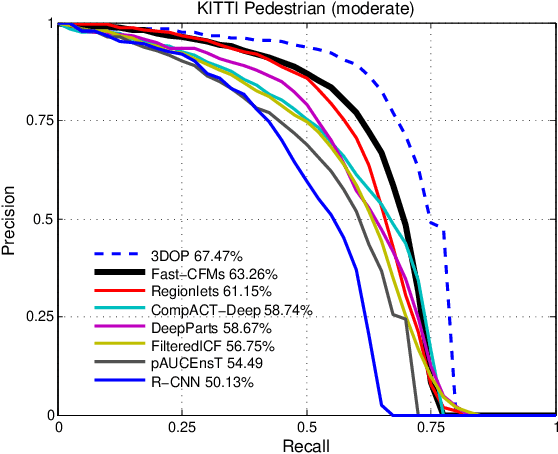
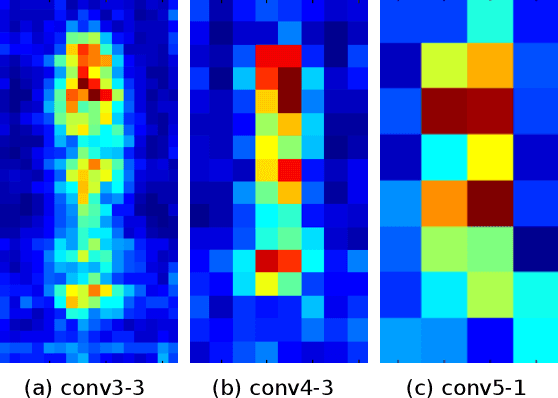
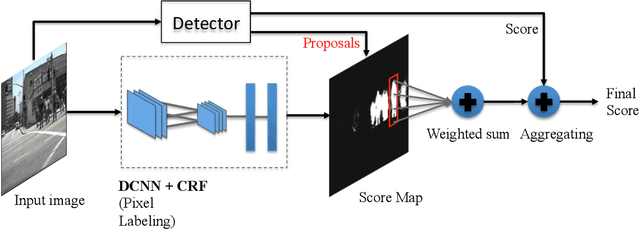
Compared to other applications in computer vision, convolutional neural networks have under-performed on pedestrian detection. A breakthrough was made very recently by using sophisticated deep CNN models, with a number of hand-crafted features, or explicit occlusion handling mechanism. In this work, we show that by re-using the convolutional feature maps (CFMs) of a deep convolutional neural network (DCNN) model as image features to train an ensemble of boosted decision models, we are able to achieve the best reported accuracy without using specially designed learning algorithms. We empirically identify and disclose important implementation details. We also show that pixel labelling may be simply combined with a detector to boost the detection performance. By adding complementary hand-crafted features such as optical flow, the DCNN based detector can be further improved. We set a new record on the Caltech pedestrian dataset, lowering the log-average miss rate from $11.7\%$ to $8.9\%$, a relative improvement of $24\%$. We also achieve a comparable result to the state-of-the-art approaches on the KITTI dataset.
Deep Linear Discriminant Analysis on Fisher Networks: A Hybrid Architecture for Person Re-identification
Jun 06, 2016
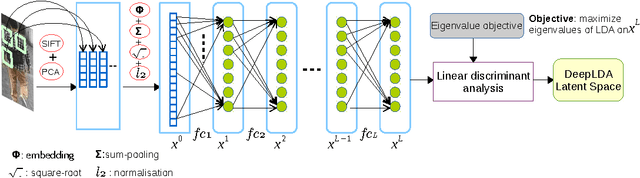
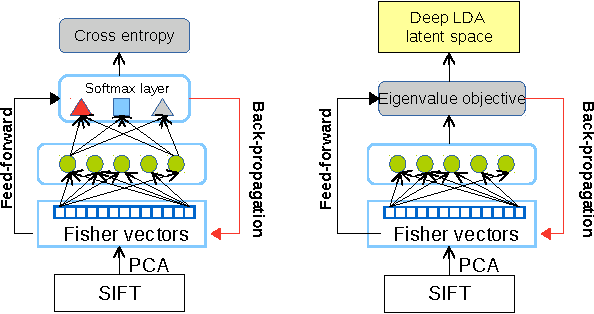
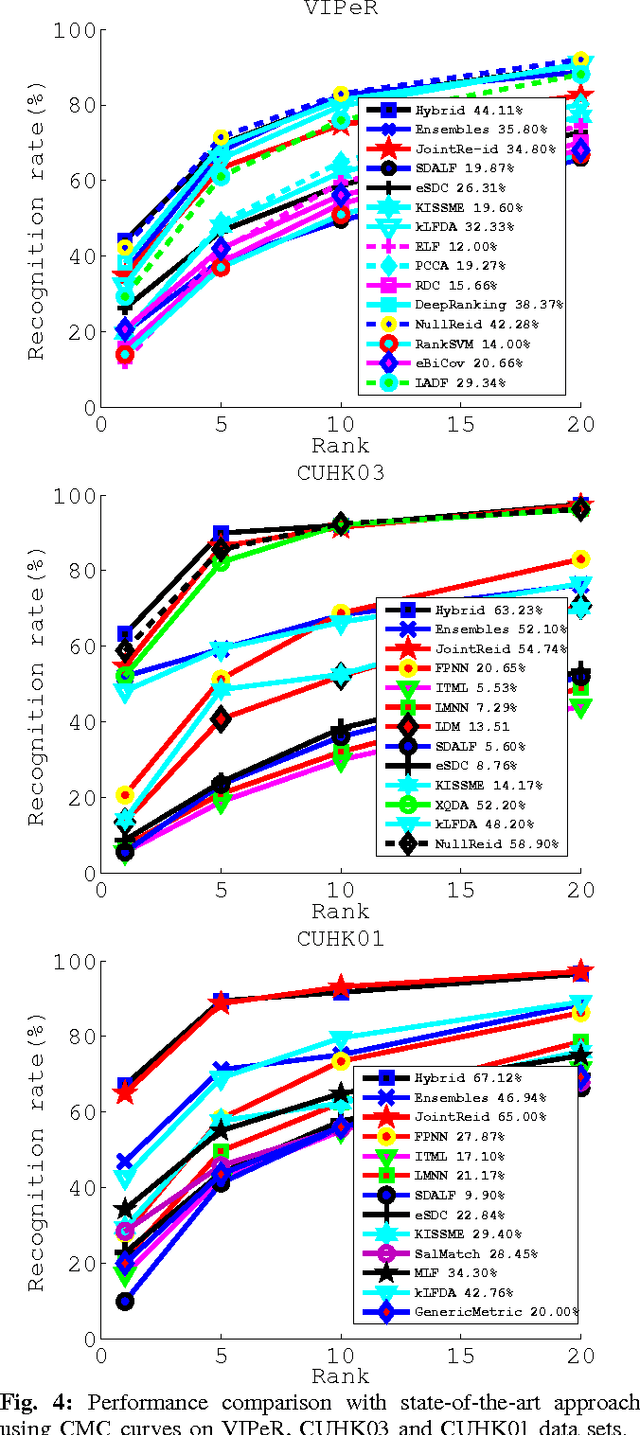
Person re-identification is to seek a correct match for a person of interest across views among a large number of imposters. It typically involves two procedures of non-linear feature extractions against dramatic appearance changes, and subsequent discriminative analysis in order to reduce intra- personal variations while enlarging inter-personal differences. In this paper, we introduce a hybrid architecture which combines Fisher vectors and deep neural networks to learn non-linear representations of person images to a space where data can be linearly separable. We reinforce a Linear Discriminant Analysis (LDA) on top of the deep neural network such that linearly separable latent representations can be learnt in an end-to-end fashion. By optimizing an objective function modified from LDA, the network is enforced to produce feature distributions which have a low variance within the same class and high variance between classes. The objective is essentially derived from the general LDA eigenvalue problem and allows to train the network with stochastic gradient descent and back-propagate LDA gradients to compute the gradients involved in Fisher vector encoding. For evaluation we test our approach on four benchmark data sets in person re-identification (VIPeR [1], CUHK03 [2], CUHK01 [3], and Market1501 [4]). Extensive experiments on these benchmarks show that our model can achieve state-of-the-art results.
Mining Mid-level Visual Patterns with Deep CNN Activations
May 29, 2016
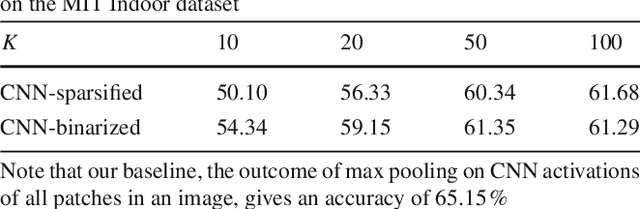
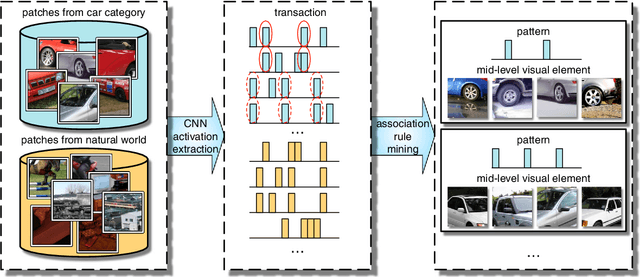
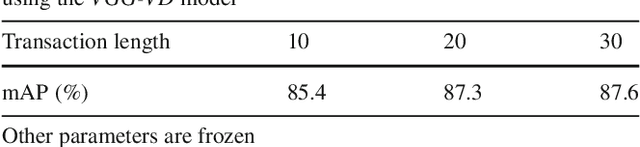
The purpose of mid-level visual element discovery is to find clusters of image patches that are both representative and discriminative. Here we study this problem from the prospective of pattern mining while relying on the recently popularized Convolutional Neural Networks (CNNs). We observe that a fully-connected CNN activation extracted from an image patch typically possesses two appealing properties that enable its seamless integration with pattern mining techniques. The marriage between CNN activations and association rule mining, a well-known pattern mining technique in the literature, leads to fast and effective discovery of representative and discriminative patterns from a huge number of image patches. When we retrieve and visualize image patches with the same pattern, surprisingly, they are not only visually similar but also semantically consistent, and thus give rise to a mid-level visual element in our work. Given the patterns and retrieved mid-level visual elements, we propose two methods to generate image feature representations for each. The first method is to use the patterns as codewords in a dictionary, similar to the Bag-of-Visual-Words model, we compute a Bag-of-Patterns representation. The second one relies on the retrieved mid-level visual elements to construct a Bag-of-Elements representation. We evaluate the two encoding methods on scene and object classification tasks, and demonstrate that our approach outperforms or matches recent works using CNN activations for these tasks.
Structured learning of metric ensembles with application to person re-identification
May 24, 2016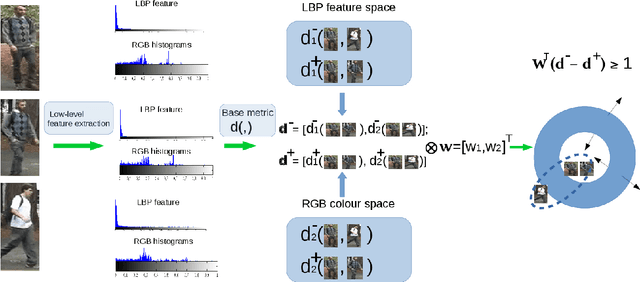
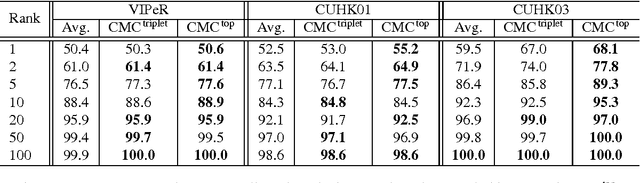
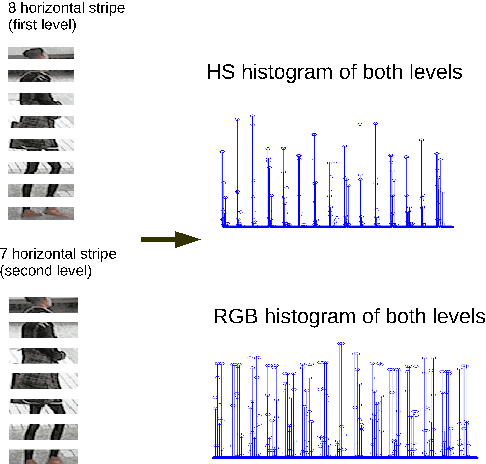
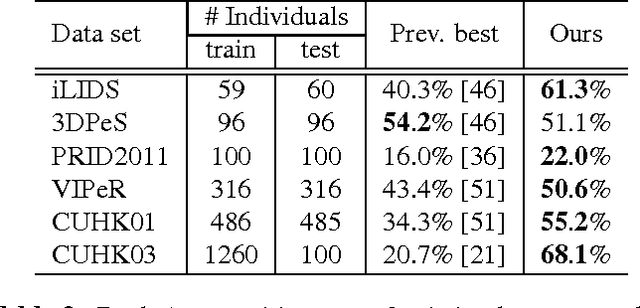
Matching individuals across non-overlapping camera networks, known as person re-identification, is a fundamentally challenging problem due to the large visual appearance changes caused by variations of viewpoints, lighting, and occlusion. Approaches in literature can be categoried into two streams: The first stream is to develop reliable features against realistic conditions by combining several visual features in a pre-defined way; the second stream is to learn a metric from training data to ensure strong inter-class differences and intra-class similarities. However, seeking an optimal combination of visual features which is generic yet adaptive to different benchmarks is a unsoved problem, and metric learning models easily get over-fitted due to the scarcity of training data in person re-identification. In this paper, we propose two effective structured learning based approaches which explore the adaptive effects of visual features in recognizing persons in different benchmark data sets. Our framework is built on the basis of multiple low-level visual features with an optimal ensemble of their metrics. We formulate two optimization algorithms, CMCtriplet and CMCstruct, which directly optimize evaluation measures commonly used in person re-identification, also known as the Cumulative Matching Characteristic (CMC) curve.
Bridging Category-level and Instance-level Semantic Image Segmentation
May 23, 2016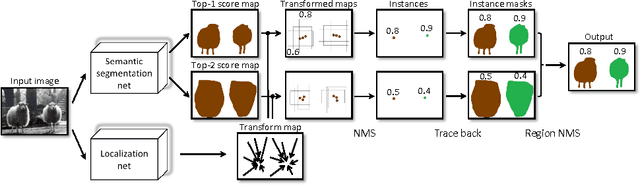
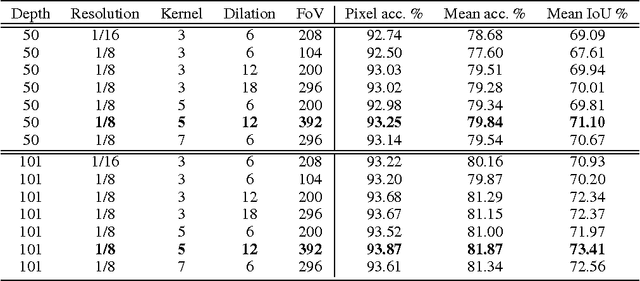
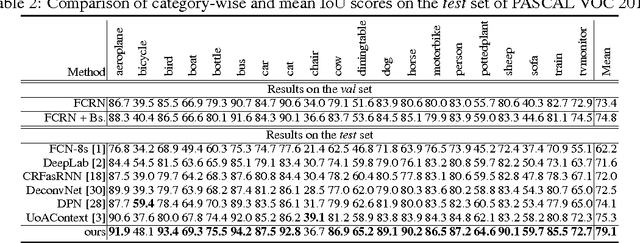

We propose an approach to instance-level image segmentation that is built on top of category-level segmentation. Specifically, for each pixel in a semantic category mask, its corresponding instance bounding box is predicted using a deep fully convolutional regression network. Thus it follows a different pipeline to the popular detect-then-segment approaches that first predict instances' bounding boxes, which are the current state-of-the-art in instance segmentation. We show that, by leveraging the strength of our state-of-the-art semantic segmentation models, the proposed method can achieve comparable or even better results to detect-then-segment approaches. We make the following contributions. (i) First, we propose a simple yet effective approach to semantic instance segmentation. (ii) Second, we propose an online bootstrapping method during training, which is critically important for achieving good performance for both semantic category segmentation and instance-level segmentation. (iii) As the performance of semantic category segmentation has a significant impact on the instance-level segmentation, which is the second step of our approach, we train fully convolutional residual networks to achieve the best semantic category segmentation accuracy. On the PASCAL VOC 2012 dataset, we obtain the currently best mean intersection-over-union score of 79.1%. (iv) We also achieve state-of-the-art results for instance-level segmentation.
Large-scale Binary Quadratic Optimization Using Semidefinite Relaxation and Applications
May 02, 2016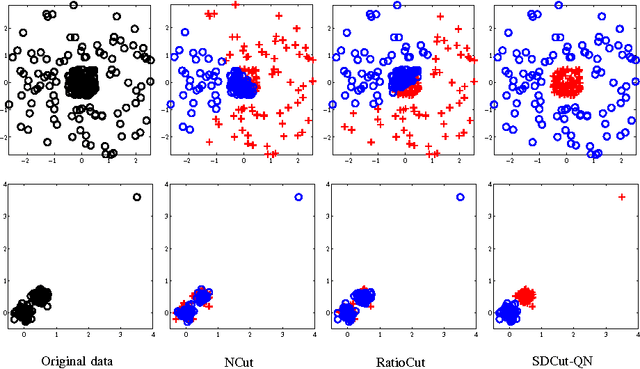
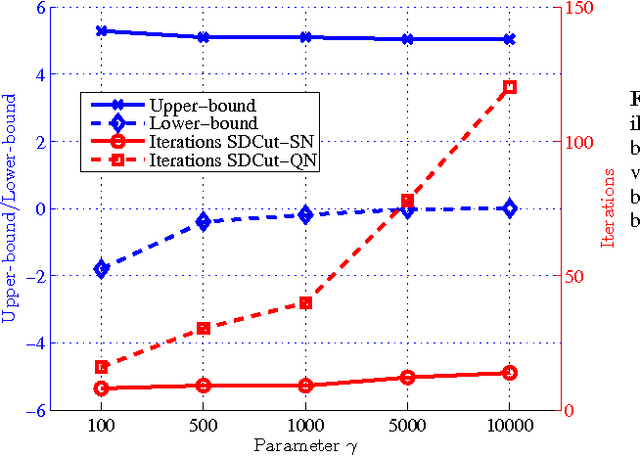
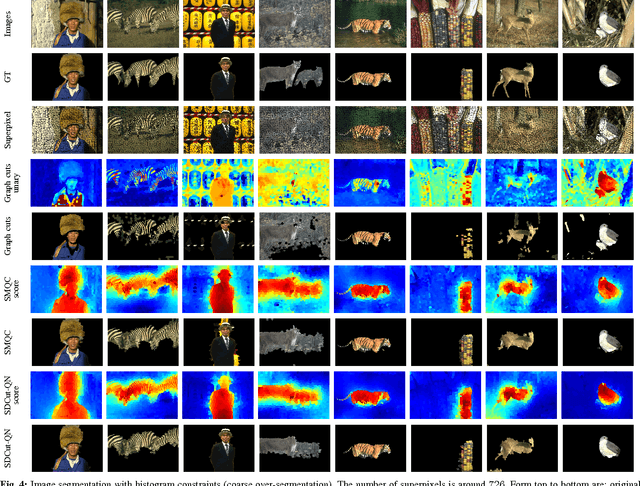

In computer vision, many problems such as image segmentation, pixel labelling, and scene parsing can be formulated as binary quadratic programs (BQPs). For submodular problems, cuts based methods can be employed to efficiently solve large-scale problems. However, general nonsubmodular problems are significantly more challenging to solve. Finding a solution when the problem is of large size to be of practical interest, however, typically requires relaxation. Two standard relaxation methods are widely used for solving general BQPs--spectral methods and semidefinite programming (SDP), each with their own advantages and disadvantages. Spectral relaxation is simple and easy to implement, but its bound is loose. Semidefinite relaxation has a tighter bound, but its computational complexity is high, especially for large scale problems. In this work, we present a new SDP formulation for BQPs, with two desirable properties. First, it has a similar relaxation bound to conventional SDP formulations. Second, compared with conventional SDP methods, the new SDP formulation leads to a significantly more efficient and scalable dual optimization approach, which has the same degree of complexity as spectral methods. We then propose two solvers, namely, quasi-Newton and smoothing Newton methods, for the dual problem. Both of them are significantly more efficiently than standard interior-point methods. In practice, the smoothing Newton solver is faster than the quasi-Newton solver for dense or medium-sized problems, while the quasi-Newton solver is preferable for large sparse/structured problems. Our experiments on a few computer vision applications including clustering, image segmentation, co-segmentation and registration show the potential of our SDP formulation for solving large-scale BQPs.
What value do explicit high level concepts have in vision to language problems?
Apr 28, 2016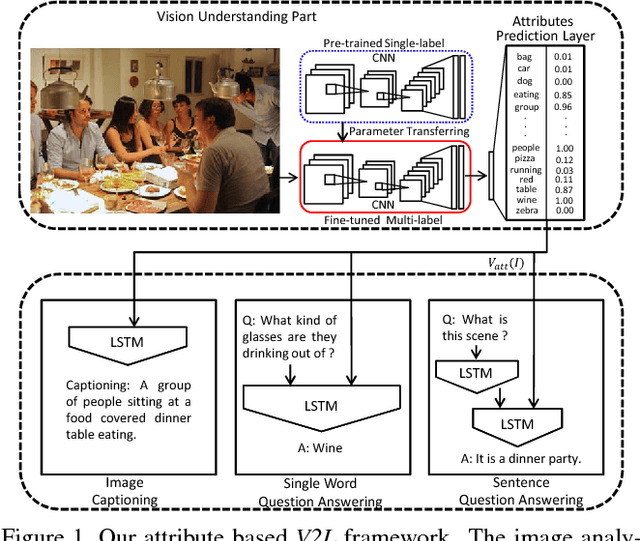
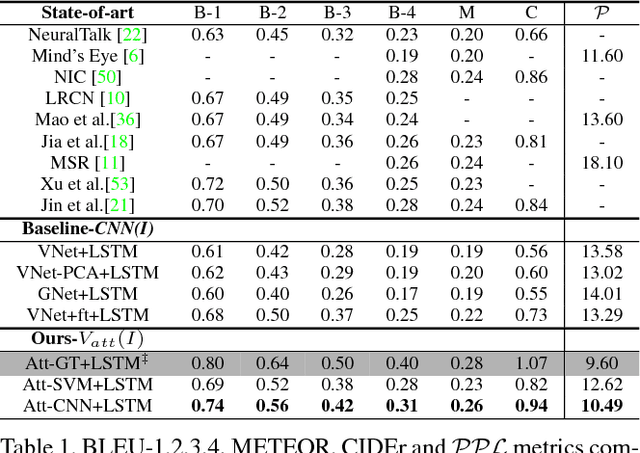
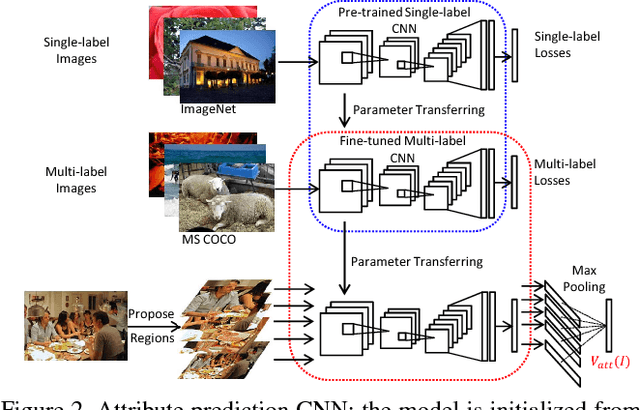
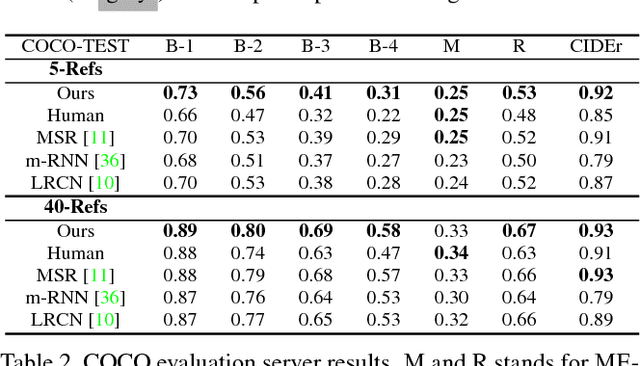
Much of the recent progress in Vision-to-Language (V2L) problems has been achieved through a combination of Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). This approach does not explicitly represent high-level semantic concepts, but rather seeks to progress directly from image features to text. We propose here a method of incorporating high-level concepts into the very successful CNN-RNN approach, and show that it achieves a significant improvement on the state-of-the-art performance in both image captioning and visual question answering. We also show that the same mechanism can be used to introduce external semantic information and that doing so further improves performance. In doing so we provide an analysis of the value of high level semantic information in V2L problems.