 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhase transition for detecting a small community in a large network
Mar 09, 2023



How to detect a small community in a large network is an interesting problem, including clique detection as a special case, where a naive degree-based $\chi^2$-test was shown to be powerful in the presence of an Erd\H{o}s-Renyi background. Using Sinkhorn's theorem, we show that the signal captured by the $\chi^2$-test may be a modeling artifact, and it may disappear once we replace the Erd\H{o}s-Renyi model by a broader network model. We show that the recent SgnQ test is more appropriate for such a setting. The test is optimal in detecting communities with sizes comparable to the whole network, but has never been studied for our setting, which is substantially different and more challenging. Using a degree-corrected block model (DCBM), we establish phase transitions of this testing problem concerning the size of the small community and the edge densities in small and large communities. When the size of the small community is larger than $\sqrt{n}$, the SgnQ test is optimal for it attains the computational lower bound (CLB), the information lower bound for methods allowing polynomial computation time. When the size of the small community is smaller than $\sqrt{n}$, we establish the parameter regime where the SgnQ test has full power and make some conjectures of the CLB. We also study the classical information lower bound (LB) and show that there is always a gap between the CLB and LB in our range of interest.
Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions
Oct 04, 2022We provide theoretical convergence guarantees for score-based generative models (SGMs) such as denoising diffusion probabilistic models (DDPMs), which constitute the backbone of large-scale real-world generative models such as DALL$\cdot$E 2. Our main result is that, assuming accurate score estimates, such SGMs can efficiently sample from essentially any realistic data distribution. In contrast to prior works, our results (1) hold for an $L^2$-accurate score estimate (rather than $L^\infty$-accurate); (2) do not require restrictive functional inequality conditions that preclude substantial non-log-concavity; (3) scale polynomially in all relevant problem parameters; and (4) match state-of-the-art complexity guarantees for discretization of the Langevin diffusion, provided that the score error is sufficiently small. We view this as strong theoretical justification for the empirical success of SGMs. We also examine SGMs based on the critically damped Langevin diffusion (CLD). Contrary to conventional wisdom, we provide evidence that the use of the CLD does not reduce the complexity of SGMs.
Self-supervised Denoising via Low-rank Tensor Approximated Convolutional Neural Network
Sep 26, 2022
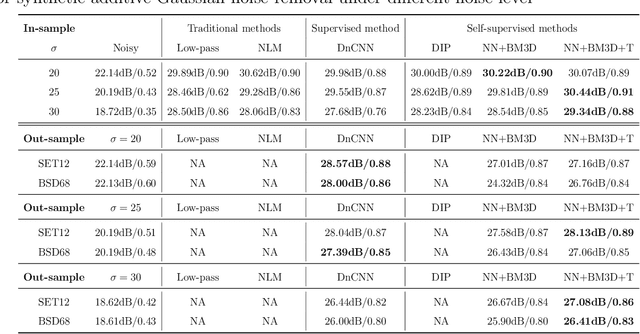
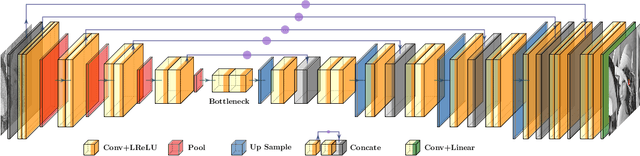
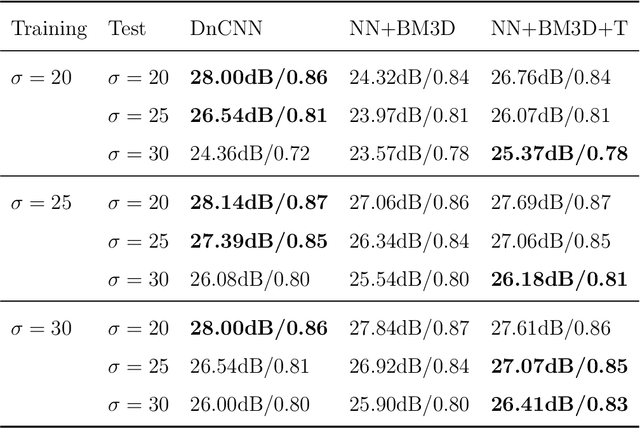
Noise is ubiquitous during image acquisition. Sufficient denoising is often an important first step for image processing. In recent decades, deep neural networks (DNNs) have been widely used for image denoising. Most DNN-based image denoising methods require a large-scale dataset or focus on supervised settings, in which single/pairs of clean images or a set of noisy images are required. This poses a significant burden on the image acquisition process. Moreover, denoisers trained on datasets of limited scale may incur over-fitting. To mitigate these issues, we introduce a new self-supervised framework for image denoising based on the Tucker low-rank tensor approximation. With the proposed design, we are able to characterize our denoiser with fewer parameters and train it based on a single image, which considerably improves the model generalizability and reduces the cost of data acquisition. Extensive experiments on both synthetic and real-world noisy images have been conducted. Empirical results show that our proposed method outperforms existing non-learning-based methods (e.g., low-pass filter, non-local mean), single-image unsupervised denoisers (e.g., DIP, NN+BM3D) evaluated on both in-sample and out-sample datasets. The proposed method even achieves comparable performances with some supervised methods (e.g., DnCNN).
Tensor-on-Tensor Regression: Riemannian Optimization, Over-parameterization, Statistical-computational Gap, and Their Interplay
Jun 17, 2022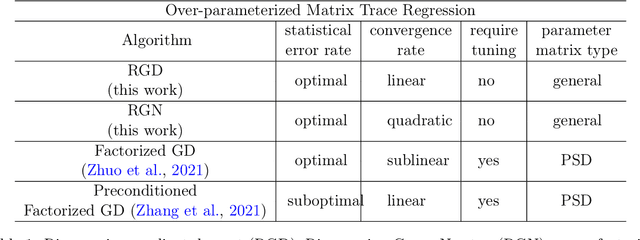
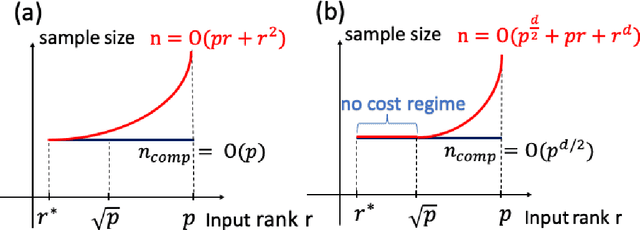
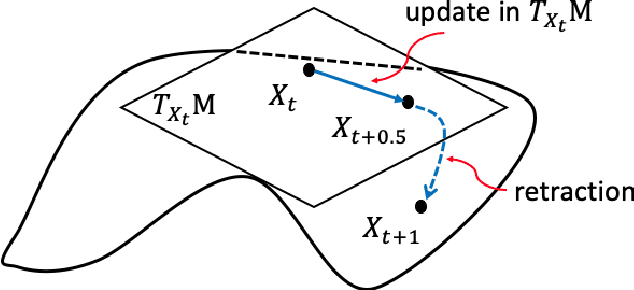
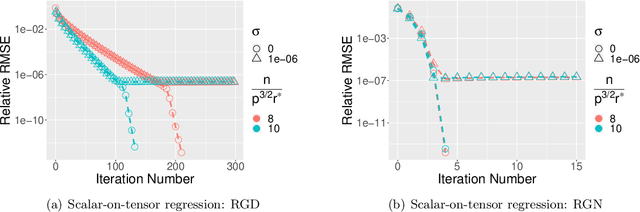
We study the tensor-on-tensor regression, where the goal is to connect tensor responses to tensor covariates with a low Tucker rank parameter tensor/matrix without the prior knowledge of its intrinsic rank. We propose the Riemannian gradient descent (RGD) and Riemannian Gauss-Newton (RGN) methods and cope with the challenge of unknown rank by studying the effect of rank over-parameterization. We provide the first convergence guarantee for the general tensor-on-tensor regression by showing that RGD and RGN respectively converge linearly and quadratically to a statistically optimal estimate in both rank correctly-parameterized and over-parameterized settings. Our theory reveals an intriguing phenomenon: Riemannian optimization methods naturally adapt to over-parameterization without modifications to their implementation. We also give the first rigorous evidence for the statistical-computational gap in scalar-on-tensor regression under the low-degree polynomials framework. Our theory demonstrates a ``blessing of statistical-computational gap" phenomenon: in a wide range of scenarios in tensor-on-tensor regression for tensors of order three or higher, the computationally required sample size matches what is needed by moderate rank over-parameterization when considering computationally feasible estimators, while there are no such benefits in the matrix settings. This shows moderate rank over-parameterization is essentially ``cost-free" in terms of sample size in tensor-on-tensor regression of order three or higher. Finally, we conduct simulation studies to show the advantages of our proposed methods and to corroborate our theoretical findings.
Learning Polynomial Transformations
Apr 08, 2022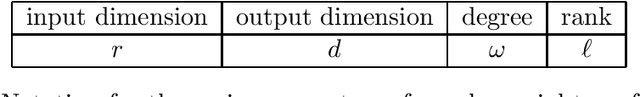
We consider the problem of learning high dimensional polynomial transformations of Gaussians. Given samples of the form $p(x)$, where $x\sim N(0, \mathrm{Id}_r)$ is hidden and $p: \mathbb{R}^r \to \mathbb{R}^d$ is a function where every output coordinate is a low-degree polynomial, the goal is to learn the distribution over $p(x)$. This problem is natural in its own right, but is also an important special case of learning deep generative models, namely pushforwards of Gaussians under two-layer neural networks with polynomial activations. Understanding the learnability of such generative models is crucial to understanding why they perform so well in practice. Our first main result is a polynomial-time algorithm for learning quadratic transformations of Gaussians in a smoothed setting. Our second main result is a polynomial-time algorithm for learning constant-degree polynomial transformations of Gaussian in a smoothed setting, when the rank of the associated tensors is small. In fact our results extend to any rotation-invariant input distribution, not just Gaussian. These are the first end-to-end guarantees for learning a pushforward under a neural network with more than one layer. Along the way, we also give the first polynomial-time algorithms with provable guarantees for tensor ring decomposition, a popular generalization of tensor decomposition that is used in practice to implicitly store large tensors.
On Geometric Connections of Embedded and Quotient Geometries in Riemannian Fixed-rank Matrix Optimization
Oct 23, 2021
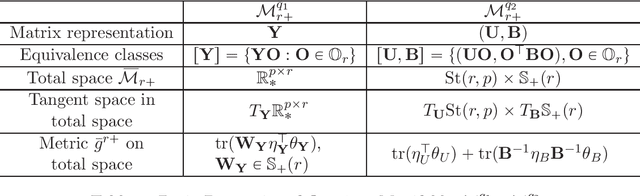

In this paper, we propose a general procedure for establishing the landscape connections of a Riemannian optimization problem under the embedded and quotient geometries. By applying the general procedure to the fixed-rank positive semidefinite (PSD) and general matrix optimization, we establish an exact Riemannian gradient connection under two geometries at every point on the manifold and sandwich inequalities between the spectra of Riemannian Hessians at Riemannian first-order stationary points (FOSPs). These results immediately imply an equivalence on the sets of Riemannian FOSPs, Riemannian second-order stationary points (SOSPs) and strict saddles of fixed-rank matrix optimization under the embedded and the quotient geometries. To the best of our knowledge, this is the first geometric landscape connection between the embedded and the quotient geometries for fixed-rank matrix optimization and it provides a concrete example on how these two geometries are connected in Riemannian optimization. In addition, the effects of the Riemannian metric and quotient structure on the landscape connection are discussed. We also observe an algorithmic connection for fixed-rank matrix optimization under two geometries with some specific Riemannian metrics. A number of novel ideas and technical ingredients including a unified treatment for different Riemannian metrics and new horizontal space representations under quotient geometries are developed to obtain our results. The results in this paper deepen our understanding of geometric connections of Riemannian optimization under different Riemannian geometries and provide a few new theoretical insights to unanswered questions in the literature.
Nonconvex Factorization and Manifold Formulations are Almost Equivalent in Low-rank Matrix Optimization
Aug 03, 2021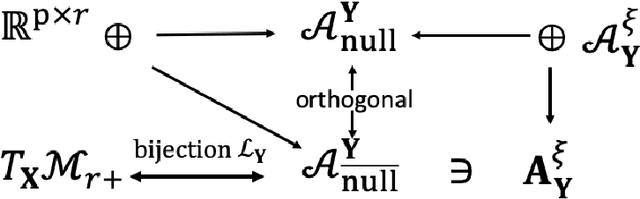
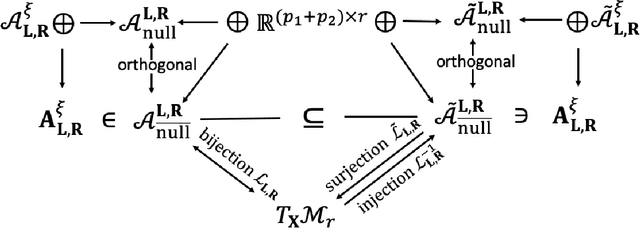
In this paper, we consider the geometric landscape connection of the widely studied manifold and factorization formulations in low-rank positive semidefinite (PSD) and general matrix optimization. We establish an equivalence on the set of first-order stationary points (FOSPs) and second-order stationary points (SOSPs) between the manifold and the factorization formulations. We further give a sandwich inequality on the spectrum of Riemannian and Euclidean Hessians at FOSPs, which can be used to transfer more geometric properties from one formulation to another. Similarities and differences on the landscape connection under the PSD case and the general case are discussed. To the best of our knowledge, this is the first geometric landscape connection between the manifold and the factorization formulations for handling rank constraints. In the general low-rank matrix optimization, the landscape connection of two factorization formulations (unregularized and regularized ones) is also provided. By applying these geometric landscape connections, we are able to solve unanswered questions in literature and establish stronger results in the applications on geometric analysis of phase retrieval, well-conditioned low-rank matrix optimization, and the role of regularization in factorization arising from machine learning and signal processing.
Low-rank Tensor Estimation via Riemannian Gauss-Newton: Statistical Optimality and Second-Order Convergence
Apr 27, 2021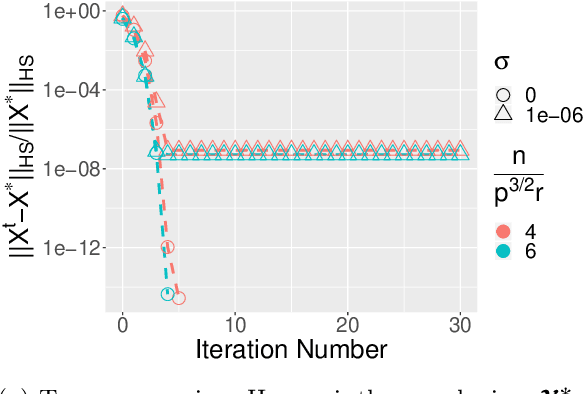
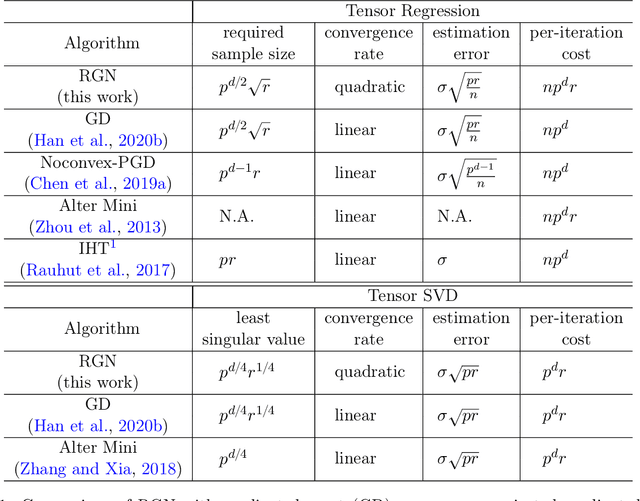
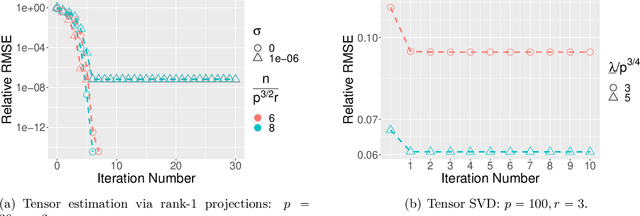
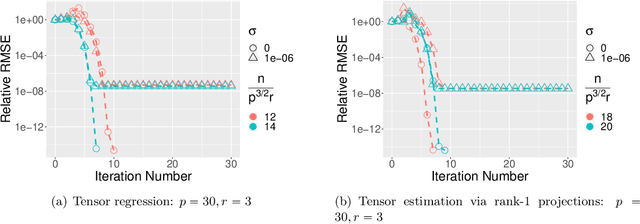
In this paper, we consider the estimation of a low Tucker rank tensor from a number of noisy linear measurements. The general problem covers many specific examples arising from applications, including tensor regression, tensor completion, and tensor PCA/SVD. We propose a Riemannian Gauss-Newton (RGN) method with fast implementations for low Tucker rank tensor estimation. Different from the generic (super)linear convergence guarantee of RGN in the literature, we prove the first quadratic convergence guarantee of RGN for low-rank tensor estimation under some mild conditions. A deterministic estimation error lower bound, which matches the upper bound, is provided that demonstrates the statistical optimality of RGN. The merit of RGN is illustrated through two machine learning applications: tensor regression and tensor SVD. Finally, we provide the simulation results to corroborate our theoretical findings.
Inference for Low-rank Tensors -- No Need to Debias
Dec 29, 2020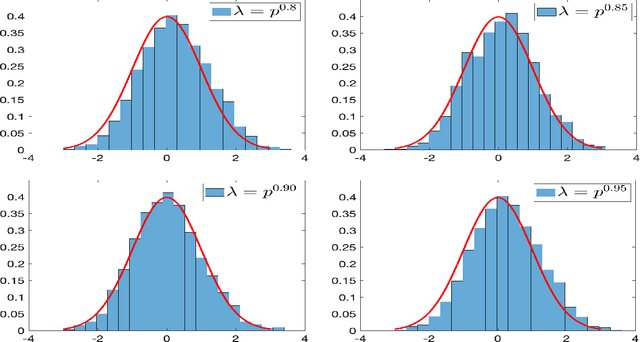
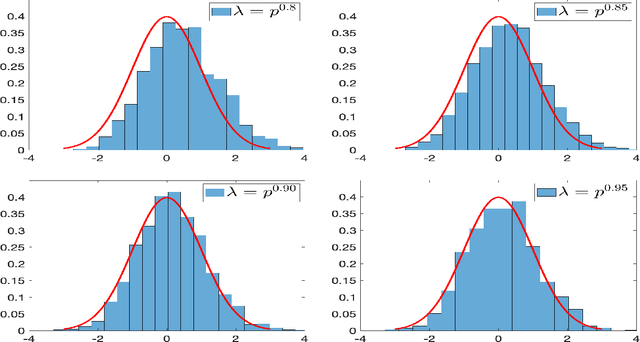
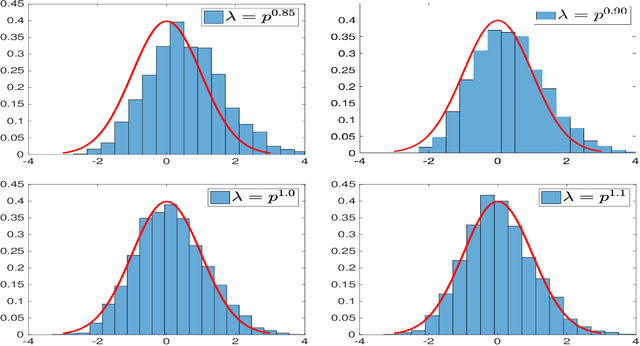
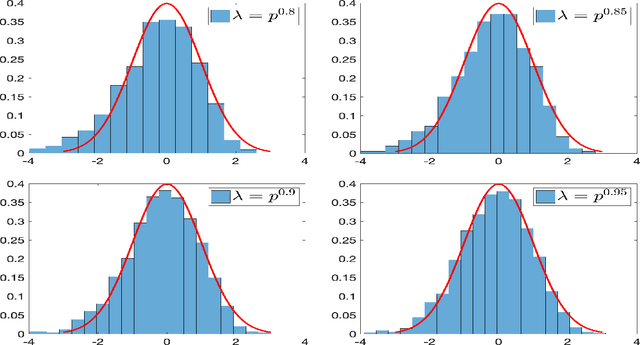
In this paper, we consider the statistical inference for several low-rank tensor models. Specifically, in the Tucker low-rank tensor PCA or regression model, provided with any estimates achieving some attainable error rate, we develop the data-driven confidence regions for the singular subspace of the parameter tensor based on the asymptotic distribution of an updated estimate by two-iteration alternating minimization. The asymptotic distributions are established under some essential conditions on the signal-to-noise ratio (in PCA model) or sample size (in regression model). If the parameter tensor is further orthogonally decomposable, we develop the methods and theory for inference on each individual singular vector. For the rank-one tensor PCA model, we establish the asymptotic distribution for general linear forms of principal components and confidence interval for each entry of the parameter tensor. Finally, numerical simulations are presented to corroborate our theoretical discoveries. In all these models, we observe that different from many matrix/vector settings in existing work, debiasing is not required to establish the asymptotic distribution of estimates or to make statistical inference on low-rank tensors. In fact, due to the widely observed statistical-computational-gap for low-rank tensor estimation, one usually requires stronger conditions than the statistical (or information-theoretic) limit to ensure the computationally feasible estimation is achievable. Surprisingly, such conditions ``incidentally" render a feasible low-rank tensor inference without debiasing.
Exact Clustering in Tensor Block Model: Statistical Optimality and Computational Limit
Dec 18, 2020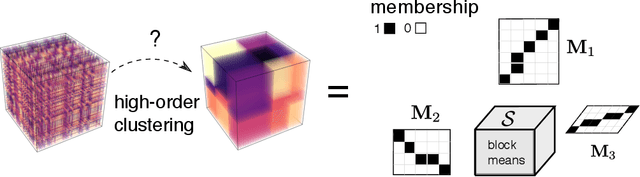

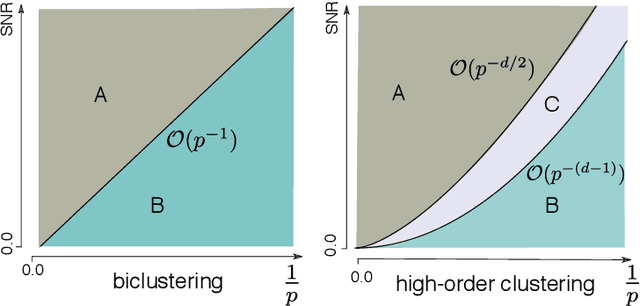

High-order clustering aims to identify heterogeneous substructure in multiway dataset that arises commonly in neuroimaging, genomics, and social network studies. The non-convex and discontinuous nature of the problem poses significant challenges in both statistics and computation. In this paper, we propose a tensor block model and the computationally efficient methods, \emph{high-order Lloyd algorithm} (HLloyd) and \emph{high-order spectral clustering} (HSC), for high-order clustering in tensor block model. The convergence of the proposed procedure is established, and we show that our method achieves exact clustering under reasonable assumptions. We also give the complete characterization for the statistical-computational trade-off in high-order clustering based on three different signal-to-noise ratio regimes. Finally, we show the merits of the proposed procedures via extensive experiments on both synthetic and real datasets.