 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairer Preferences Elicit Improved Human-Aligned Large Language Model Judgments
Jun 17, 2024



Large language models (LLMs) have shown promising abilities as cost-effective and reference-free evaluators for assessing language generation quality. In particular, pairwise LLM evaluators, which compare two generated texts and determine the preferred one, have been employed in a wide range of applications. However, LLMs exhibit preference biases and worrying sensitivity to prompt designs. In this work, we first reveal that the predictive preference of LLMs can be highly brittle and skewed, even with semantically equivalent instructions. We find that fairer predictive preferences from LLMs consistently lead to judgments that are better aligned with humans. Motivated by this phenomenon, we propose an automatic Zero-shot Evaluation-oriented Prompt Optimization framework, ZEPO, which aims to produce fairer preference decisions and improve the alignment of LLM evaluators with human judgments. To this end, we propose a zero-shot learning objective based on the preference decision fairness. ZEPO demonstrates substantial performance improvements over state-of-the-art LLM evaluators, without requiring labeled data, on representative meta-evaluation benchmarks. Our findings underscore the critical correlation between preference fairness and human alignment, positioning ZEPO as an efficient prompt optimizer for bridging the gap between LLM evaluators and human judgments.
Culturally Aware and Adapted NLP: A Taxonomy and a Survey of the State of the Art
Jun 06, 2024



The surge of interest in culturally aware and adapted Natural Language Processing (NLP) has inspired much recent research. However, the lack of common understanding of the concept of "culture" has made it difficult to evaluate progress in this emerging area. Drawing on prior research in NLP and related fields, we propose an extensive taxonomy of elements of culture that can provide a systematic framework for analyzing and understanding research progress. Using the taxonomy, we survey existing resources and models for culturally aware and adapted NLP, providing an overview of the state of the art and the research gaps that still need to be filled.
TopViewRS: Vision-Language Models as Top-View Spatial Reasoners
Jun 04, 2024



Top-view perspective denotes a typical way in which humans read and reason over different types of maps, and it is vital for localization and navigation of humans as well as of `non-human' agents, such as the ones backed by large Vision-Language Models (VLMs). Nonetheless, spatial reasoning capabilities of modern VLMs remain unattested and underexplored. In this work, we thus study their capability to understand and reason over spatial relations from the top view. The focus on top view also enables controlled evaluations at different granularity of spatial reasoning; we clearly disentangle different abilities (e.g., recognizing particular objects versus understanding their relative positions). We introduce the TopViewRS (Top-View Reasoning in Space) dataset, consisting of 11,384 multiple-choice questions with either realistic or semantic top-view map as visual input. We then use it to study and evaluate VLMs across 4 perception and reasoning tasks with different levels of complexity. Evaluation of 10 representative open- and closed-source VLMs reveals the gap of more than 50% compared to average human performance, and it is even lower than the random baseline in some cases. Although additional experiments show that Chain-of-Thought reasoning can boost model capabilities by 5.82% on average, the overall performance of VLMs remains limited. Our findings underscore the critical need for enhanced model capability in top-view spatial reasoning and set a foundation for further research towards human-level proficiency of VLMs in real-world multimodal tasks.
Spectral Editing of Activations for Large Language Model Alignment
May 15, 2024



Large language models (LLMs) often exhibit undesirable behaviours, such as generating untruthful or biased content. Editing their internal representations has been shown to be effective in mitigating such behaviours on top of the existing alignment methods. We propose a novel inference-time editing method, namely spectral editing of activations (SEA), to project the input representations into directions with maximal covariance with the positive demonstrations (e.g., truthful) while minimising covariance with the negative demonstrations (e.g., hallucinated). We also extend our method to non-linear editing using feature functions. We run extensive experiments on benchmarks concerning truthfulness and bias with six open-source LLMs of different sizes and model families. The results demonstrate the superiority of SEA in effectiveness, generalisation to similar tasks, as well as inference and data efficiency. We also show that SEA editing only has a limited negative impact on other model capabilities.
CALRec: Contrastive Alignment of Generative LLMs For Sequential Recommendation
May 03, 2024Traditional recommender systems such as matrix factorization methods rely on learning a shared dense embedding space to represent both items and user preferences. Sequence models such as RNN, GRUs, and, recently, Transformers have also excelled in the task of sequential recommendation. This task requires understanding the sequential structure present in users' historical interactions to predict the next item they may like. Building upon the success of Large Language Models (LLMs) in a variety of tasks, researchers have recently explored using LLMs that are pretrained on vast corpora of text for sequential recommendation. To use LLMs in sequential recommendations, both the history of user interactions and the model's prediction of the next item are expressed in text form. We propose CALRec, a two-stage LLM finetuning framework that finetunes a pretrained LLM in a two-tower fashion using a mixture of two contrastive losses and a language modeling loss: the LLM is first finetuned on a data mixture from multiple domains followed by another round of target domain finetuning. Our model significantly outperforms many state-of-the-art baselines (+37% in Recall@1 and +24% in NDCG@10) and systematic ablation studies reveal that (i) both stages of finetuning are crucial, and, when combined, we achieve improved performance, and (ii) contrastive alignment is effective among the target domains explored in our experiments.
Aligning with Human Judgement: The Role of Pairwise Preference in Large Language Model Evaluators
Mar 26, 2024Large Language Models (LLMs) have demonstrated promising capabilities as automatic evaluators in assessing the quality of generated natural language. However, LLMs still exhibit biases in evaluation and often struggle to generate coherent evaluations that align with human assessments. In this work, we first conduct a systematic study of the misalignment between LLM evaluators and human judgement, revealing that existing calibration methods aimed at mitigating biases are insufficient for effectively aligning LLM evaluators. Inspired by the use of preference data in RLHF, we formulate the evaluation as a ranking problem and introduce Pairwise-preference Search (PairS), an uncertainty-guided search method that employs LLMs to conduct pairwise comparisons and efficiently ranks candidate texts. PairS achieves state-of-the-art performance on representative evaluation tasks and demonstrates significant improvements over direct scoring. Furthermore, we provide insights into the role of pairwise preference in quantifying the transitivity of LLMs and demonstrate how PairS benefits from calibration.
Analyzing and Adapting Large Language Models for Few-Shot Multilingual NLU: Are We There Yet?
Mar 04, 2024Supervised fine-tuning (SFT), supervised instruction tuning (SIT) and in-context learning (ICL) are three alternative, de facto standard approaches to few-shot learning. ICL has gained popularity recently with the advent of LLMs due to its simplicity and sample efficiency. Prior research has conducted only limited investigation into how these approaches work for multilingual few-shot learning, and the focus so far has been mostly on their performance. In this work, we present an extensive and systematic comparison of the three approaches, testing them on 6 high- and low-resource languages, three different NLU tasks, and a myriad of language and domain setups. Importantly, performance is only one aspect of the comparison, where we also analyse the approaches through the optics of their computational, inference and financial costs. Our observations show that supervised instruction tuning has the best trade-off between performance and resource requirements. As another contribution, we analyse the impact of target language adaptation of pretrained LLMs and find that the standard adaptation approaches can (superficially) improve target language generation capabilities, but language understanding elicited through ICL does not improve and remains limited, with low scores especially for low-resource languages.
Self-Augmented In-Context Learning for Unsupervised Word Translation
Feb 15, 2024Recent work has shown that, while large language models (LLMs) demonstrate strong word translation or bilingual lexicon induction (BLI) capabilities in few-shot setups, they still cannot match the performance of 'traditional' mapping-based approaches in the unsupervised scenario where no seed translation pairs are available, especially for lower-resource languages. To address this challenge with LLMs, we propose self-augmented in-context learning (SAIL) for unsupervised BLI: starting from a zero-shot prompt, SAIL iteratively induces a set of high-confidence word translation pairs for in-context learning (ICL) from an LLM, which it then reapplies to the same LLM in the ICL fashion. Our method shows substantial gains over zero-shot prompting of LLMs on two established BLI benchmarks spanning a wide range of language pairs, also outperforming mapping-based baselines across the board. In addition to achieving state-of-the-art unsupervised BLI performance, we also conduct comprehensive analyses on SAIL and discuss its limitations.
Scaling Sparse Fine-Tuning to Large Language Models
Feb 02, 2024Large Language Models (LLMs) are difficult to fully fine-tune (e.g., with instructions or human feedback) due to their sheer number of parameters. A family of parameter-efficient sparse fine-tuning methods have proven promising in terms of performance but their memory requirements increase proportionally to the size of the LLMs. In this work, we scale sparse fine-tuning to state-of-the-art LLMs like LLaMA 2 7B and 13B. We propose SpIEL, a novel sparse fine-tuning method which, for a desired density level, maintains an array of parameter indices and the deltas of these parameters relative to their pretrained values. It iterates over: (a) updating the active deltas, (b) pruning indices (based on the change of magnitude of their deltas) and (c) regrowth of indices. For regrowth, we explore two criteria based on either the accumulated gradients of a few candidate parameters or their approximate momenta estimated using the efficient SM3 optimizer. We experiment with instruction-tuning of LLMs on standard dataset mixtures, finding that SpIEL is often superior to popular parameter-efficient fine-tuning methods like LoRA (low-rank adaptation) in terms of performance and comparable in terms of run time. We additionally show that SpIEL is compatible with both quantization and efficient optimizers, to facilitate scaling to ever-larger model sizes. We release the code for SpIEL at https://github.com/AlanAnsell/peft and for the instruction-tuning experiments at https://github.com/ducdauge/sft-llm.
DIALIGHT: Lightweight Multilingual Development and Evaluation of Task-Oriented Dialogue Systems with Large Language Models
Jan 04, 2024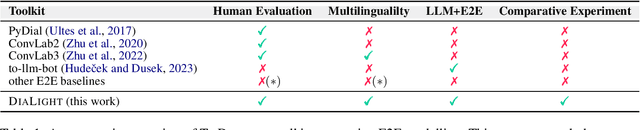
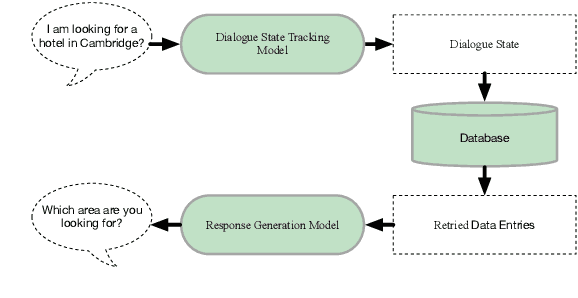
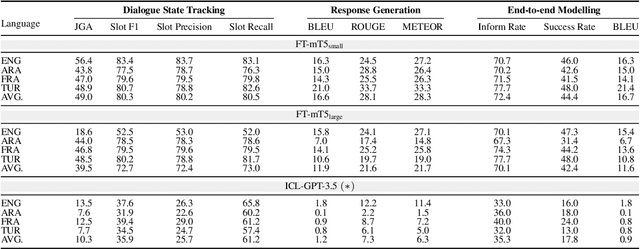
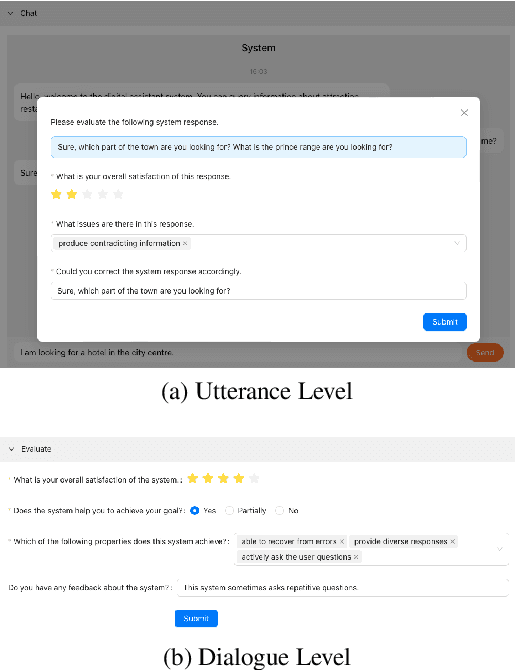
We present DIALIGHT, a toolkit for developing and evaluating multilingual Task-Oriented Dialogue (ToD) systems which facilitates systematic evaluations and comparisons between ToD systems using fine-tuning of Pretrained Language Models (PLMs) and those utilising the zero-shot and in-context learning capabilities of Large Language Models (LLMs). In addition to automatic evaluation, this toolkit features (i) a secure, user-friendly web interface for fine-grained human evaluation at both local utterance level and global dialogue level, and (ii) a microservice-based backend, improving efficiency and scalability. Our evaluations reveal that while PLM fine-tuning leads to higher accuracy and coherence, LLM-based systems excel in producing diverse and likeable responses. However, we also identify significant challenges of LLMs in adherence to task-specific instructions and generating outputs in multiple languages, highlighting areas for future research. We hope this open-sourced toolkit will serve as a valuable resource for researchers aiming to develop and properly evaluate multilingual ToD systems and will lower, currently still high, entry barriers in the field.