 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Full-stack Accelerator Search Technique for Vision Applications
May 26, 2021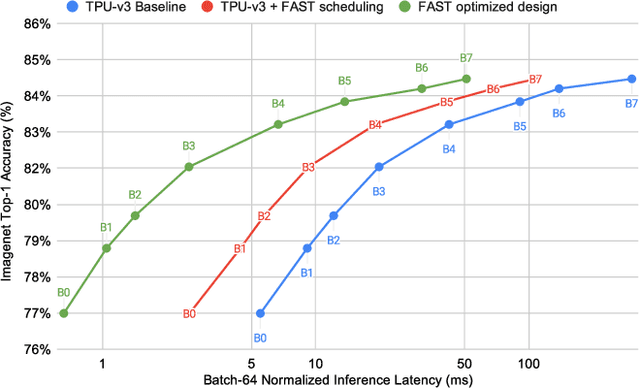
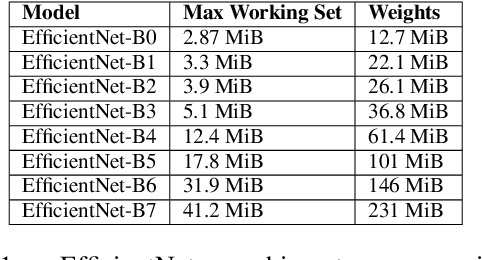
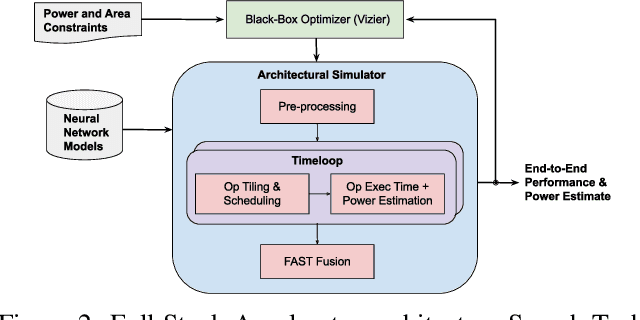
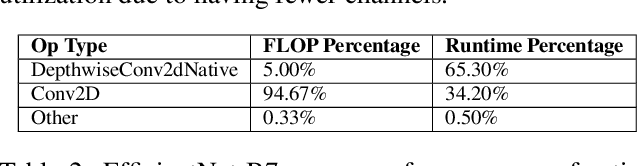
The rapidly-changing ML model landscape presents a unique opportunity for building hardware accelerators optimized for specific datacenter-scale workloads. We propose Full-stack Accelerator Search Technique (FAST), a hardware accelerator search framework that defines a broad optimization environment covering key design decisions within the hardware-software stack, including hardware datapath, software scheduling, and compiler passes such as operation fusion and tensor padding. Although FAST can be used on any number and type of deep learning workload, in this paper we focus on optimizing for a single or small set of vision models, resulting in significantly faster and more power-efficient designs relative to a general purpose ML accelerator. When evaluated on EfficientNet, ResNet50v2, and OCR inference performance relative to a TPU-v3, designs generated by FAST optimized for single workloads can improve Perf/TDP (peak power) by over 6x in the best case and 4x on average. On a limited workload subset, FAST improves Perf/TDP 2.85x on average, with a reduction to 2.35x for a single design optimized over the set of workloads. In addition, we demonstrate a potential 1.8x speedup opportunity for TPU-v3 with improved scheduling.
Transferable Graph Optimizers for ML Compilers
Oct 21, 2020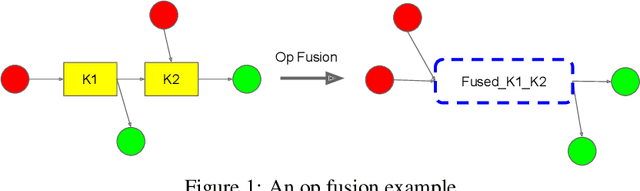

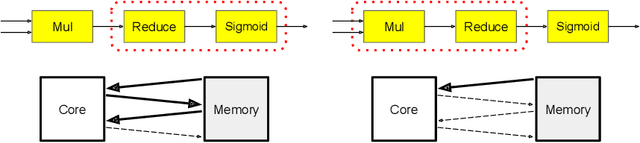
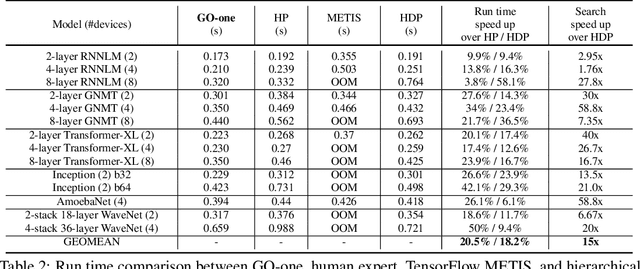
Most compilers for machine learning (ML) frameworks need to solve many correlated optimization problems to generate efficient machine code. Current ML compilers rely on heuristics based algorithms to solve these optimization problems one at a time. However, this approach is not only hard to maintain but often leads to sub-optimal solutions especially for newer model architectures. Existing learning based approaches in the literature are sample inefficient, tackle a single optimization problem, and do not generalize to unseen graphs making them infeasible to be deployed in practice. To address these limitations, we propose an end-to-end, transferable deep reinforcement learning method for computational graph optimization (GO), based on a scalable sequential attention mechanism over an inductive graph neural network. GO generates decisions on the entire graph rather than on each individual node autoregressively, drastically speeding up the search compared to prior methods. Moreover, we propose recurrent attention layers to jointly optimize dependent graph optimization tasks and demonstrate 33%-60% speedup on three graph optimization tasks compared to TensorFlow default optimization. On a diverse set of representative graphs consisting of up to 80,000 nodes, including Inception-v3, Transformer-XL, and WaveNet, GO achieves on average 21% improvement over human experts and 18% improvement over the prior state of the art with 15x faster convergence, on a device placement task evaluated in real systems.
* arXiv admin note: text overlap with arXiv:1910.01578
Chip Placement with Deep Reinforcement Learning
Apr 22, 2020

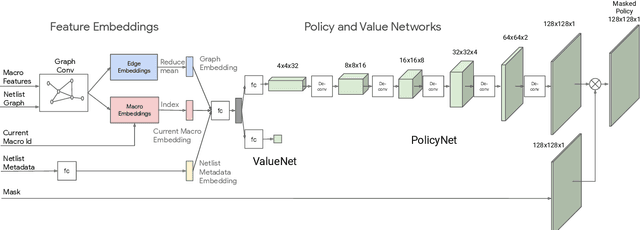
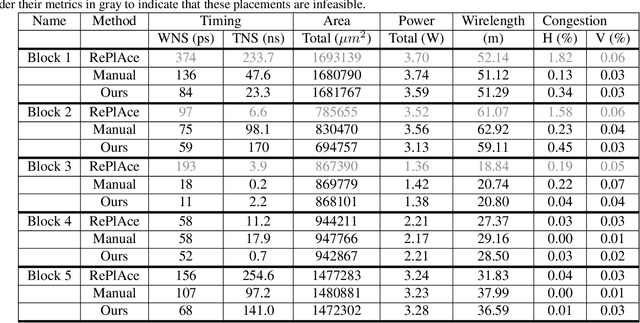
In this work, we present a learning-based approach to chip placement, one of the most complex and time-consuming stages of the chip design process. Unlike prior methods, our approach has the ability to learn from past experience and improve over time. In particular, as we train over a greater number of chip blocks, our method becomes better at rapidly generating optimized placements for previously unseen chip blocks. To achieve these results, we pose placement as a Reinforcement Learning (RL) problem and train an agent to place the nodes of a chip netlist onto a chip canvas. To enable our RL policy to generalize to unseen blocks, we ground representation learning in the supervised task of predicting placement quality. By designing a neural architecture that can accurately predict reward across a wide variety of netlists and their placements, we are able to generate rich feature embeddings of the input netlists. We then use this architecture as the encoder of our policy and value networks to enable transfer learning. Our objective is to minimize PPA (power, performance, and area), and we show that, in under 6 hours, our method can generate placements that are superhuman or comparable on modern accelerator netlists, whereas existing baselines require human experts in the loop and take several weeks.
Placement Optimization with Deep Reinforcement Learning
Mar 18, 2020Placement Optimization is an important problem in systems and chip design, which consists of mapping the nodes of a graph onto a limited set of resources to optimize for an objective, subject to constraints. In this paper, we start by motivating reinforcement learning as a solution to the placement problem. We then give an overview of what deep reinforcement learning is. We next formulate the placement problem as a reinforcement learning problem and show how this problem can be solved with policy gradient optimization. Finally, we describe lessons we have learned from training deep reinforcement learning policies across a variety of placement optimization problems.
Generalized Clustering by Learning to Optimize Expected Normalized Cuts
Oct 16, 2019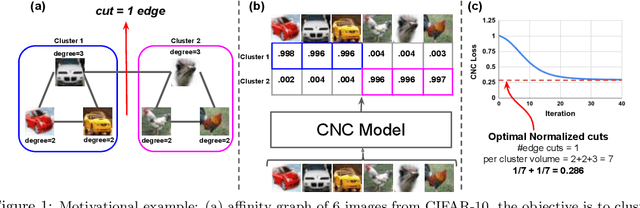
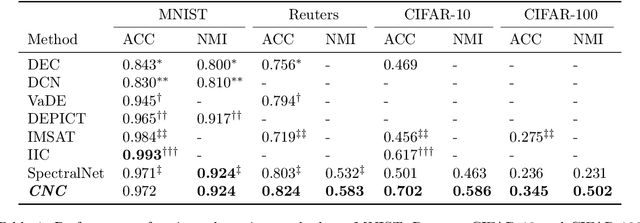

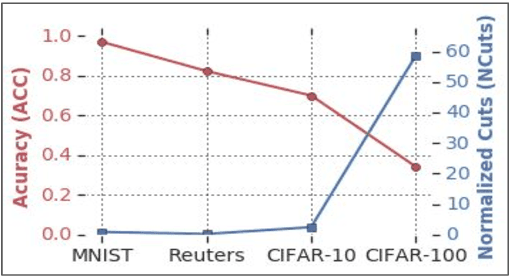
We introduce a novel end-to-end approach for learning to cluster in the absence of labeled examples. Our clustering objective is based on optimizing normalized cuts, a criterion which measures both intra-cluster similarity as well as inter-cluster dissimilarity. We define a differentiable loss function equivalent to the expected normalized cuts. Unlike much of the work in unsupervised deep learning, our trained model directly outputs final cluster assignments, rather than embeddings that need further processing to be usable. Our approach generalizes to unseen datasets across a wide variety of domains, including text, and image. Specifically, we achieve state-of-the-art results on popular unsupervised clustering benchmarks (e.g., MNIST, Reuters, CIFAR-10, and CIFAR-100), outperforming the strongest baselines by up to 10.9%. Our generalization results are superior (by up to 21.9%) to the recent top-performing clustering approach with the ability to generalize.
GDP: Generalized Device Placement for Dataflow Graphs
Sep 28, 2019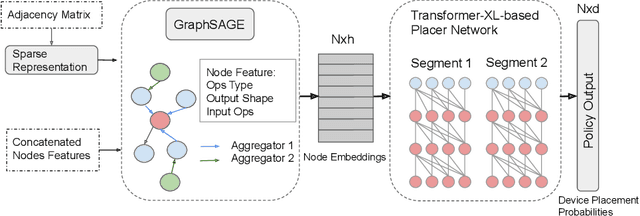
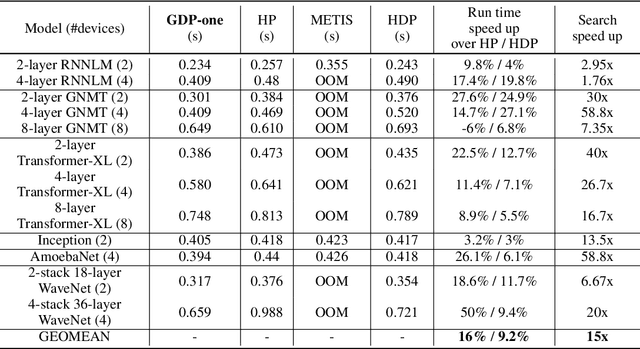
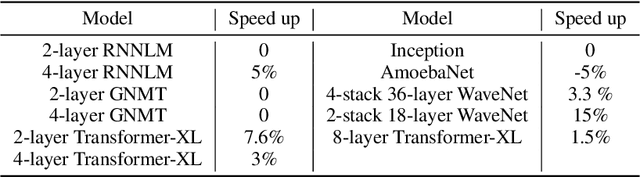
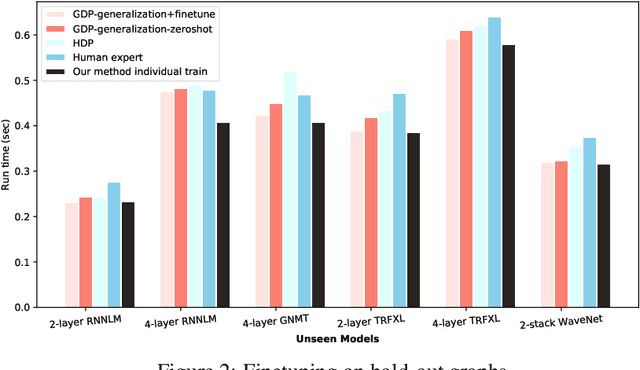
Runtime and scalability of large neural networks can be significantly affected by the placement of operations in their dataflow graphs on suitable devices. With increasingly complex neural network architectures and heterogeneous device characteristics, finding a reasonable placement is extremely challenging even for domain experts. Most existing automated device placement approaches are impractical due to the significant amount of compute required and their inability to generalize to new, previously held-out graphs. To address both limitations, we propose an efficient end-to-end method based on a scalable sequential attention mechanism over a graph neural network that is transferable to new graphs. On a diverse set of representative deep learning models, including Inception-v3, AmoebaNet, Transformer-XL, and WaveNet, our method on average achieves 16% improvement over human experts and 9.2% improvement over the prior art with 15 times faster convergence. To further reduce the computation cost, we pre-train the policy network on a set of dataflow graphs and use a superposition network to fine-tune it on each individual graph, achieving state-of-the-art performance on large hold-out graphs with over 50k nodes, such as an 8-layer GNMT.
GAP: Generalizable Approximate Graph Partitioning Framework
Mar 02, 2019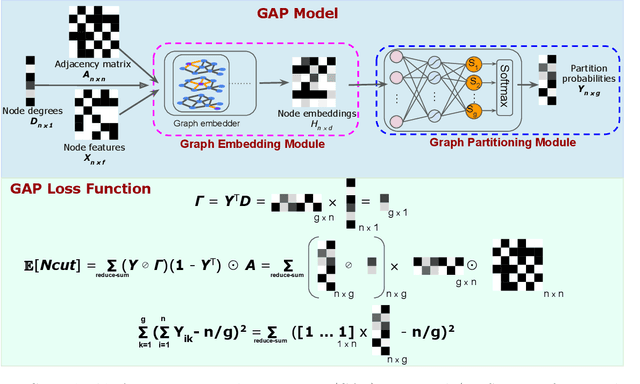
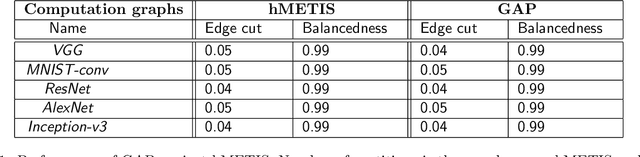

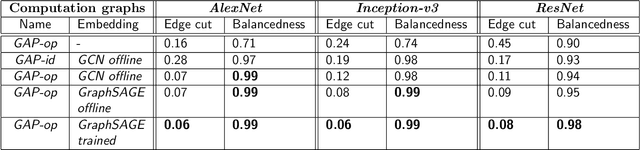
Graph partitioning is the problem of dividing the nodes of a graph into balanced partitions while minimizing the edge cut across the partitions. Due to its combinatorial nature, many approximate solutions have been developed, including variants of multi-level methods and spectral clustering. We propose GAP, a Generalizable Approximate Partitioning framework that takes a deep learning approach to graph partitioning. We define a differentiable loss function that represents the partitioning objective and use backpropagation to optimize the network parameters. Unlike baselines that redo the optimization per graph, GAP is capable of generalization, allowing us to train models that produce performant partitions at inference time, even on unseen graphs. Furthermore, because we learn the representation of the graph while jointly optimizing for the partitioning loss function, GAP can be easily tuned for a variety of graph structures. We evaluate the performance of GAP on graphs of varying sizes and structures, including graphs of widely used machine learning models (e.g., ResNet, VGG, and Inception-V3), scale-free graphs, and random graphs. We show that GAP achieves competitive partitions while being up to 100 times faster than the baseline and generalizes to unseen graphs.
Generating High-Quality and Informative Conversation Responses with Sequence-to-Sequence Models
Jul 31, 2017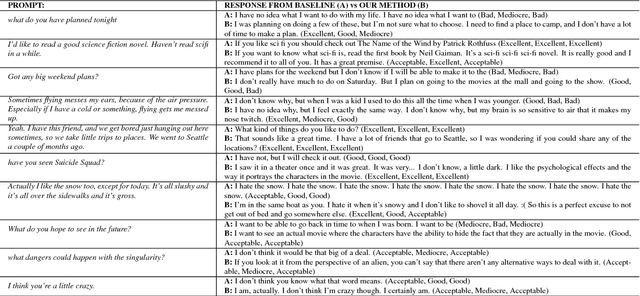

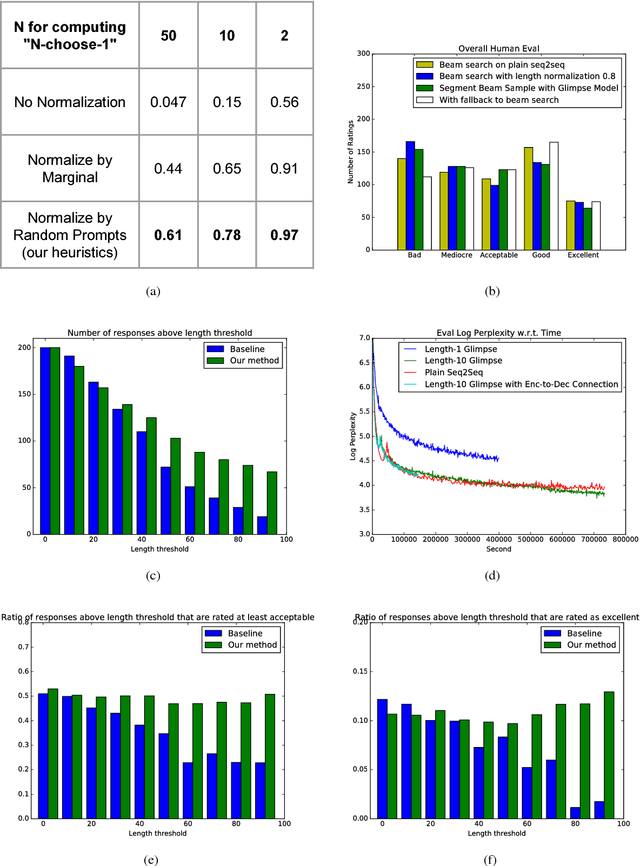
Sequence-to-sequence models have been applied to the conversation response generation problem where the source sequence is the conversation history and the target sequence is the response. Unlike translation, conversation responding is inherently creative. The generation of long, informative, coherent, and diverse responses remains a hard task. In this work, we focus on the single turn setting. We add self-attention to the decoder to maintain coherence in longer responses, and we propose a practical approach, called the glimpse-model, for scaling to large datasets. We introduce a stochastic beam-search algorithm with segment-by-segment reranking which lets us inject diversity earlier in the generation process. We trained on a combined data set of over 2.3B conversation messages mined from the web. In human evaluation studies, our method produces longer responses overall, with a higher proportion rated as acceptable and excellent as length increases, compared to baseline sequence-to-sequence models with explicit length-promotion. A back-off strategy produces better responses overall, in the full spectrum of lengths.
Massive Exploration of Neural Machine Translation Architectures
Mar 21, 2017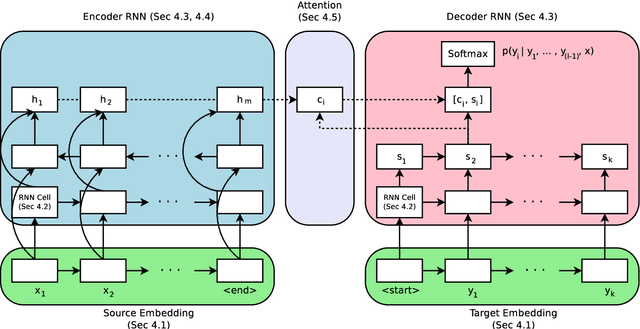


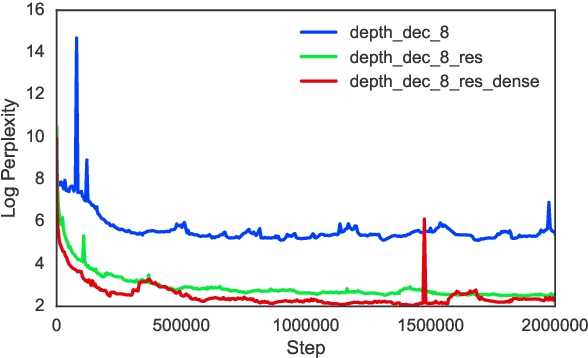
Neural Machine Translation (NMT) has shown remarkable progress over the past few years with production systems now being deployed to end-users. One major drawback of current architectures is that they are expensive to train, typically requiring days to weeks of GPU time to converge. This makes exhaustive hyperparameter search, as is commonly done with other neural network architectures, prohibitively expensive. In this work, we present the first large-scale analysis of NMT architecture hyperparameters. We report empirical results and variance numbers for several hundred experimental runs, corresponding to over 250,000 GPU hours on the standard WMT English to German translation task. Our experiments lead to novel insights and practical advice for building and extending NMT architectures. As part of this contribution, we release an open-source NMT framework that enables researchers to easily experiment with novel techniques and reproduce state of the art results.