 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDALC: A Semi-Supervised Framework for Intent Detection and Active Learning based Correction
Nov 08, 2025



Voice-controlled dialog systems have become immensely popular due to their ability to perform a wide range of actions in response to diverse user queries. These agents possess a predefined set of skills or intents to fulfill specific user tasks. But every system has its own limitations. There are instances where, even for known intents, if any model exhibits low confidence, it results in rejection of utterances that necessitate manual annotation. Additionally, as time progresses, there may be a need to retrain these agents with new intents from the system-rejected queries to carry out additional tasks. Labeling all these emerging intents and rejected utterances over time is impractical, thus calling for an efficient mechanism to reduce annotation costs. In this paper, we introduce IDALC (Intent Detection and Active Learning based Correction), a semi-supervised framework designed to detect user intents and rectify system-rejected utterances while minimizing the need for human annotation. Empirical findings on various benchmark datasets demonstrate that our system surpasses baseline methods, achieving a 5-10% higher accuracy and a 4-8% improvement in macro-F1. Remarkably, we maintain the overall annotation cost at just 6-10% of the unlabelled data available to the system. The overall framework of IDALC is shown in Fig. 1
* Paper accepted in IEEE Transactions on Artificial Intelligence (October 2025)
A Pointer Network-based Approach for Joint Extraction and Detection of Multi-Label Multi-Class Intents
Oct 29, 2024



In task-oriented dialogue systems, intent detection is crucial for interpreting user queries and providing appropriate responses. Existing research primarily addresses simple queries with a single intent, lacking effective systems for handling complex queries with multiple intents and extracting different intent spans. Additionally, there is a notable absence of multilingual, multi-intent datasets. This study addresses three critical tasks: extracting multiple intent spans from queries, detecting multiple intents, and developing a multi-lingual multi-label intent dataset. We introduce a novel multi-label multi-class intent detection dataset (MLMCID-dataset) curated from existing benchmark datasets. We also propose a pointer network-based architecture (MLMCID) to extract intent spans and detect multiple intents with coarse and fine-grained labels in the form of sextuplets. Comprehensive analysis demonstrates the superiority of our pointer network-based system over baseline approaches in terms of accuracy and F1-score across various datasets.
Leveraging the Power of LLMs: A Fine-Tuning Approach for High-Quality Aspect-Based Summarization
Aug 05, 2024



The ever-increasing volume of digital information necessitates efficient methods for users to extract key insights from lengthy documents. Aspect-based summarization offers a targeted approach, generating summaries focused on specific aspects within a document. Despite advancements in aspect-based summarization research, there is a continuous quest for improved model performance. Given that large language models (LLMs) have demonstrated the potential to revolutionize diverse tasks within natural language processing, particularly in the problem of summarization, this paper explores the potential of fine-tuning LLMs for the aspect-based summarization task. We evaluate the impact of fine-tuning open-source foundation LLMs, including Llama2, Mistral, Gemma and Aya, on a publicly available domain-specific aspect based summary dataset. We hypothesize that this approach will enable these models to effectively identify and extract aspect-related information, leading to superior quality aspect-based summaries compared to the state-of-the-art. We establish a comprehensive evaluation framework to compare the performance of fine-tuned LLMs against competing aspect-based summarization methods and vanilla counterparts of the fine-tuned LLMs. Our work contributes to the field of aspect-based summarization by demonstrating the efficacy of fine-tuning LLMs for generating high-quality aspect-based summaries. Furthermore, it opens doors for further exploration of using LLMs for targeted information extraction tasks across various NLP domains.
On The Persona-based Summarization of Domain-Specific Documents
Jun 06, 2024



In an ever-expanding world of domain-specific knowledge, the increasing complexity of consuming, and storing information necessitates the generation of summaries from large information repositories. However, every persona of a domain has different requirements of information and hence their summarization. For example, in the healthcare domain, a persona-based (such as Doctor, Nurse, Patient etc.) approach is imperative to deliver targeted medical information efficiently. Persona-based summarization of domain-specific information by humans is a high cognitive load task and is generally not preferred. The summaries generated by two different humans have high variability and do not scale in cost and subject matter expertise as domains and personas grow. Further, AI-generated summaries using generic Large Language Models (LLMs) may not necessarily offer satisfactory accuracy for different domains unless they have been specifically trained on domain-specific data and can also be very expensive to use in day-to-day operations. Our contribution in this paper is two-fold: 1) We present an approach to efficiently fine-tune a domain-specific small foundation LLM using a healthcare corpus and also show that we can effectively evaluate the summarization quality using AI-based critiquing. 2) We further show that AI-based critiquing has good concordance with Human-based critiquing of the summaries. Hence, such AI-based pipelines to generate domain-specific persona-based summaries can be easily scaled to other domains such as legal, enterprise documents, education etc. in a very efficient and cost-effective manner.
Intent Detection and Entity Extraction from BioMedical Literature
Apr 04, 2024



Biomedical queries have become increasingly prevalent in web searches, reflecting the growing interest in accessing biomedical literature. Despite recent research on large-language models (LLMs) motivated by endeavours to attain generalized intelligence, their efficacy in replacing task and domain-specific natural language understanding approaches remains questionable. In this paper, we address this question by conducting a comprehensive empirical evaluation of intent detection and named entity recognition (NER) tasks from biomedical text. We show that Supervised Fine Tuned approaches are still relevant and more effective than general-purpose LLMs. Biomedical transformer models such as PubMedBERT can surpass ChatGPT on NER task with only 5 supervised examples.
Long Dialog Summarization: An Analysis
Feb 26, 2024

Dialog summarization has become increasingly important in managing and comprehending large-scale conversations across various domains. This task presents unique challenges in capturing the key points, context, and nuances of multi-turn long conversations for summarization. It is worth noting that the summarization techniques may vary based on specific requirements such as in a shopping-chatbot scenario, the dialog summary helps to learn user preferences, whereas in the case of a customer call center, the summary may involve the problem attributes that a user specified, and the final resolution provided. This work emphasizes the significance of creating coherent and contextually rich summaries for effective communication in various applications. We explore current state-of-the-art approaches for long dialog summarization in different domains and benchmark metrics based evaluations show that one single model does not perform well across various areas for distinct summarization tasks.
MatSciRE: Leveraging Pointer Networks to Automate Entity and Relation Extraction for Material Science Knowledge-base Construction
Jan 18, 2024



Material science literature is a rich source of factual information about various categories of entities (like materials and compositions) and various relations between these entities, such as conductivity, voltage, etc. Automatically extracting this information to generate a material science knowledge base is a challenging task. In this paper, we propose MatSciRE (Material Science Relation Extractor), a Pointer Network-based encoder-decoder framework, to jointly extract entities and relations from material science articles as a triplet ($entity1, relation, entity2$). Specifically, we target the battery materials and identify five relations to work on - conductivity, coulombic efficiency, capacity, voltage, and energy. Our proposed approach achieved a much better F1-score (0.771) than a previous attempt using ChemDataExtractor (0.716). The overall graphical framework of MatSciRE is shown in Fig 1. The material information is extracted from material science literature in the form of entity-relation triplets using MatSciRE.
Intent Identification and Entity Extraction for Healthcare Queries in Indic Languages
Feb 19, 2023Scarcity of data and technological limitations for resource-poor languages in developing countries like India poses a threat to the development of sophisticated NLU systems for healthcare. To assess the current status of various state-of-the-art language models in healthcare, this paper studies the problem by initially proposing two different Healthcare datasets, Indian Healthcare Query Intent-WebMD and 1mg (IHQID-WebMD and IHQID-1mg) and one real world Indian hospital query data in English and multiple Indic languages (Hindi, Bengali, Tamil, Telugu, Marathi and Gujarati) which are annotated with the query intents as well as entities. Our aim is to detect query intents and extract corresponding entities. We perform extensive experiments on a set of models in various realistic settings and explore two scenarios based on the access to English data only (less costly) and access to target language data (more expensive). We analyze context specific practical relevancy through empirical analysis. The results, expressed in terms of overall F1 score show that our approach is practically useful to identify intents and entities.
Improving Self-supervised Learning for Out-of-distribution Task via Auxiliary Classifier
Sep 07, 2022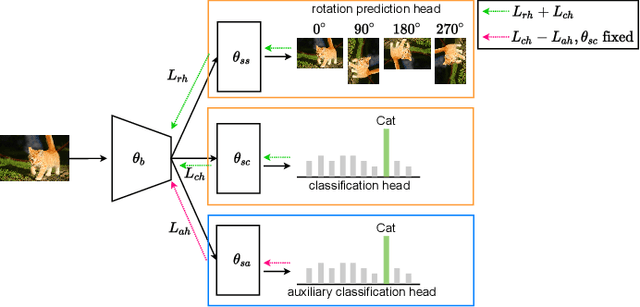
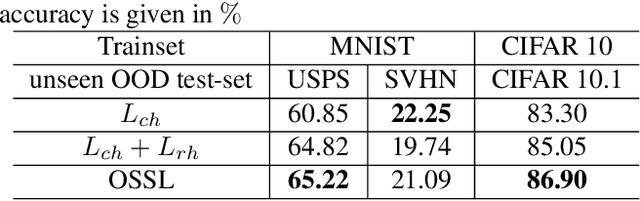

In real world scenarios, out-of-distribution (OOD) datasets may have a large distributional shift from training datasets. This phenomena generally occurs when a trained classifier is deployed on varying dynamic environments, which causes a significant drop in performance. To tackle this issue, we are proposing an end-to-end deep multi-task network in this work. Observing a strong relationship between rotation prediction (self-supervised) accuracy and semantic classification accuracy on OOD tasks, we introduce an additional auxiliary classification head in our multi-task network along with semantic classification and rotation prediction head. To observe the influence of this addition classifier in improving the rotation prediction head, our proposed learning method is framed into bi-level optimisation problem where the upper-level is trained to update the parameters for semantic classification and rotation prediction head. In the lower-level optimisation, only the auxiliary classification head is updated through semantic classification head by fixing the parameters of the semantic classification head. The proposed method has been validated through three unseen OOD datasets where it exhibits a clear improvement in semantic classification accuracy than other two baseline methods. Our code is available on GitHub \url{https://github.com/harshita-555/OSSL}
An Evaluation Framework for Legal Document Summarization
May 17, 2022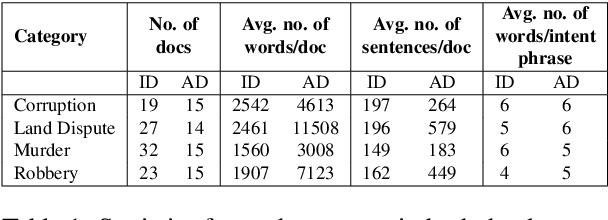
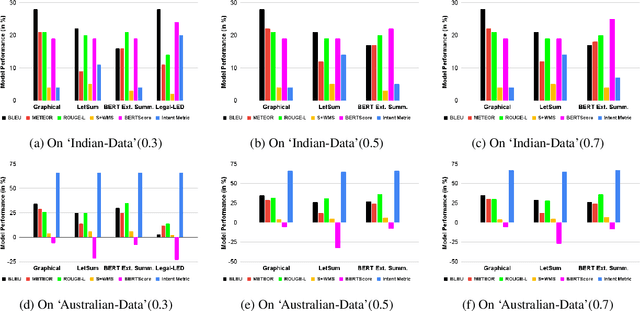
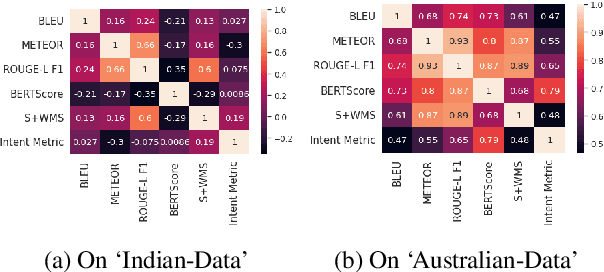
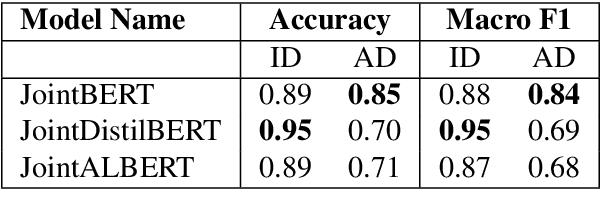
A law practitioner has to go through numerous lengthy legal case proceedings for their practices of various categories, such as land dispute, corruption, etc. Hence, it is important to summarize these documents, and ensure that summaries contain phrases with intent matching the category of the case. To the best of our knowledge, there is no evaluation metric that evaluates a summary based on its intent. We propose an automated intent-based summarization metric, which shows a better agreement with human evaluation as compared to other automated metrics like BLEU, ROUGE-L etc. in terms of human satisfaction. We also curate a dataset by annotating intent phrases in legal documents, and show a proof of concept as to how this system can be automated. Additionally, all the code and data to generate reproducible results is available on Github.