 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Combinations: A Causal Inference Framework for Combinatorial Interventions
Mar 24, 2023



We consider a setting with $N$ heterogeneous units and $p$ interventions. Our goal is to learn unit-specific potential outcomes for any combination of these $p$ interventions, i.e., $N \times 2^p$ causal parameters. Choosing combinations of interventions is a problem that naturally arises in many applications such as factorial design experiments, recommendation engines (e.g., showing a set of movies that maximizes engagement for users), combination therapies in medicine, selecting important features for ML models, etc. Running $N \times 2^p$ experiments to estimate the various parameters is infeasible as $N$ and $p$ grow. Further, with observational data there is likely confounding, i.e., whether or not a unit is seen under a combination is correlated with its potential outcome under that combination. To address these challenges, we propose a novel model that imposes latent structure across both units and combinations. We assume latent similarity across units (i.e., the potential outcomes matrix is rank $r$) and regularity in how combinations interact (i.e., the coefficients in the Fourier expansion of the potential outcomes is $s$ sparse). We establish identification for all causal parameters despite unobserved confounding. We propose an estimation procedure, Synthetic Combinations, and establish finite-sample consistency under precise conditions on the observation pattern. Our results imply Synthetic Combinations consistently estimates unit-specific potential outcomes given $\text{poly}(r) \times (N + s^2p)$ observations. In comparison, previous methods that do not exploit structure across both units and combinations have sample complexity scaling as $\min(N \times s^2p, \ \ r \times (N + 2^p))$. We use Synthetic Combinations to propose a data-efficient experimental design mechanism for combinatorial causal inference. We corroborate our theoretical findings with numerical simulations.
Strategyproof Decision-Making in Panel Data Settings and Beyond
Nov 25, 2022



We propose a framework for decision-making in the presence of strategic agents with panel data, a standard setting in econometrics and statistics where one gets noisy, repeated measurements of multiple units. We consider a setup where there is a pre-intervention period, when the principal observes the outcomes of each unit, after which the principal uses these observations to assign treatment to each unit. Our model can be thought of as a generalization of the synthetic controls and synthetic interventions frameworks, where units (or agents) may strategically manipulate pre-intervention outcomes to receive a more desirable intervention. We identify necessary and sufficient conditions under which a strategyproof mechanism that assigns interventions in the post-intervention period exists. Under a latent factor model assumption, we show that whenever a strategyproof mechanism exists, there is one with a simple closed form. In the setting where there is a single treatment and control (i.e., no other interventions), we establish that there is always a strategyproof mechanism, and provide an algorithm for learning such a mechanism. For the setting of multiple interventions, we provide an algorithm for learning a strategyproof mechanism, if there exists a sufficiently large gap in rewards between the different interventions. Along the way, we prove impossibility results for multi-class strategic classification, which may be of independent interest.
Network Synthetic Interventions: A Framework for Panel Data with Network Interference
Oct 20, 2022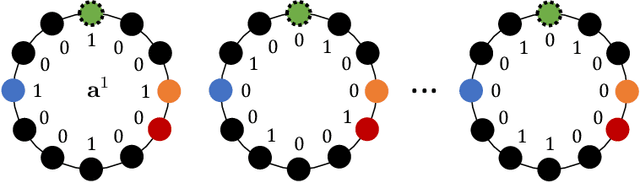
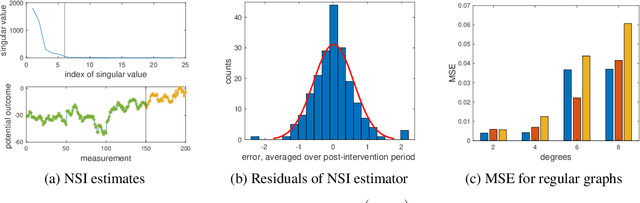
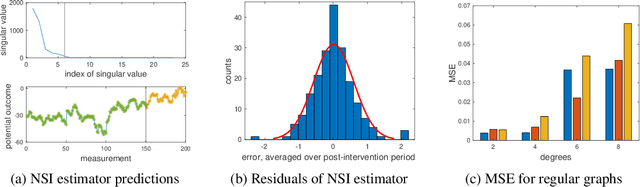
We propose a generalization of the synthetic controls and synthetic interventions methodology to incorporate network interference. We consider the estimation of unit-specific treatment effects from panel data where there are spillover effects across units and in the presence of unobserved confounding. Key to our approach is a novel latent factor model that takes into account network interference and generalizes the factor models typically used in panel data settings. We propose an estimator, "network synthetic interventions", and show that it consistently estimates the mean outcomes for a unit under an arbitrary sequence of treatments for itself and its neighborhood, given certain observation patterns hold in the data. We corroborate our theoretical findings with simulations.
CausalSim: Toward a Causal Data-Driven Simulator for Network Protocols
Jan 05, 2022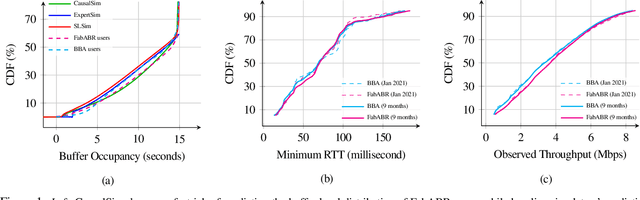
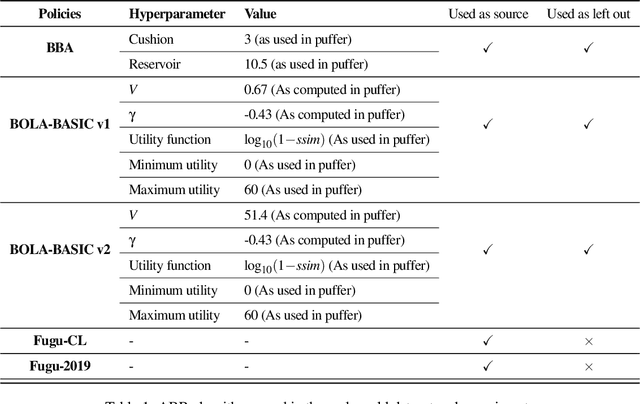
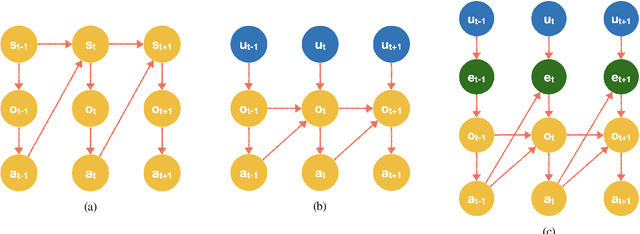
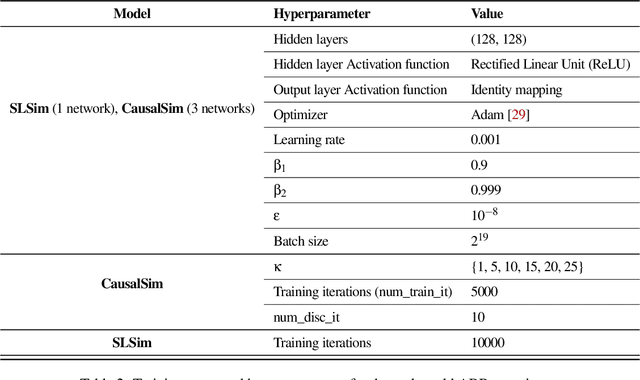
Evaluating the real-world performance of network protocols is challenging. Randomized control trials (RCT) are expensive and inaccessible to most researchers, while expert-designed simulators fail to capture complex behaviors in real networks. We present CausalSim, a data-driven simulator for network protocols that addresses this challenge. Learning network behavior from observational data is complicated due to the bias introduced by the protocols used during data collection. CausalSim uses traces from an initial RCT under a set of protocols to learn a causal network model, effectively removing the biases present in the data. Using this model, CausalSim can then simulate any protocol over the same traces (i.e., for counterfactual predictions). Key to CausalSim is the novel use of adversarial neural network training that exploits distributional invariances that are present due to the training data coming from an RCT. Our extensive evaluation of CausalSim on both real and synthetic datasets and two use cases, including more than nine months of real data from the Puffer video streaming system, shows that it provides accurate counterfactual predictions, reducing prediction error by 44% and 53% on average compared to expert-designed and standard supervised learning baselines.
Causal Matrix Completion
Sep 30, 2021
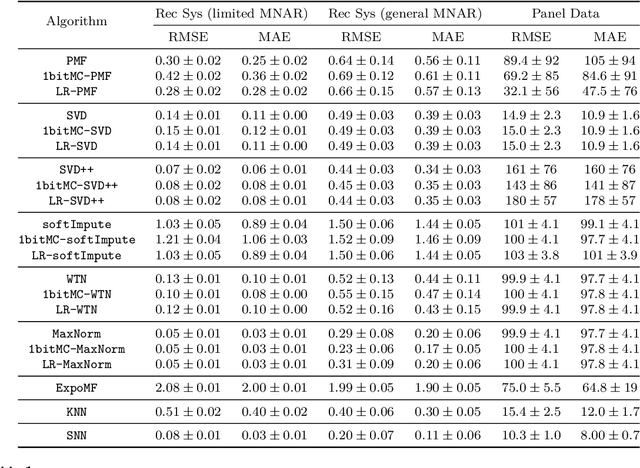
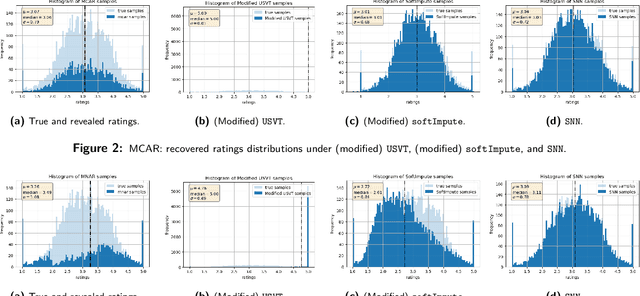
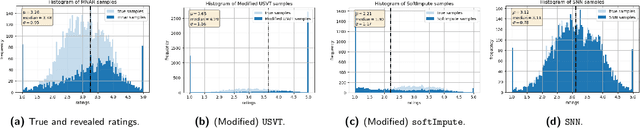
Matrix completion is the study of recovering an underlying matrix from a sparse subset of noisy observations. Traditionally, it is assumed that the entries of the matrix are "missing completely at random" (MCAR), i.e., each entry is revealed at random, independent of everything else, with uniform probability. This is likely unrealistic due to the presence of "latent confounders", i.e., unobserved factors that determine both the entries of the underlying matrix and the missingness pattern in the observed matrix. For example, in the context of movie recommender systems -- a canonical application for matrix completion -- a user who vehemently dislikes horror films is unlikely to ever watch horror films. In general, these confounders yield "missing not at random" (MNAR) data, which can severely impact any inference procedure that does not correct for this bias. We develop a formal causal model for matrix completion through the language of potential outcomes, and provide novel identification arguments for a variety of causal estimands of interest. We design a procedure, which we call "synthetic nearest neighbors" (SNN), to estimate these causal estimands. We prove finite-sample consistency and asymptotic normality of our estimator. Our analysis also leads to new theoretical results for the matrix completion literature. In particular, we establish entry-wise, i.e., max-norm, finite-sample consistency and asymptotic normality results for matrix completion with MNAR data. As a special case, this also provides entry-wise bounds for matrix completion with MCAR data. Across simulated and real data, we demonstrate the efficacy of our proposed estimator.
Causal Inference with Corrupted Data: Measurement Error, Missing Values, Discretization, and Differential Privacy
Jul 06, 2021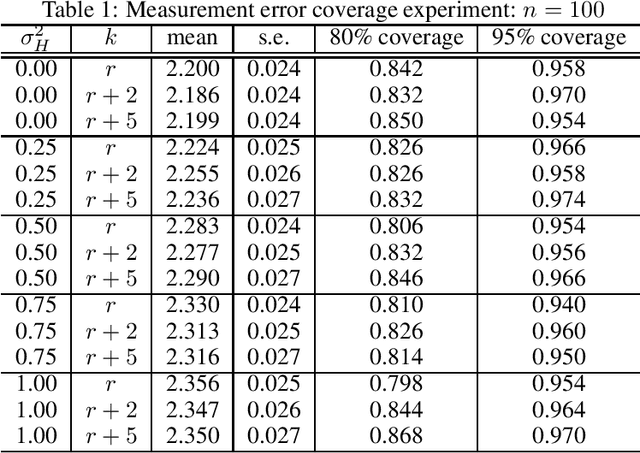
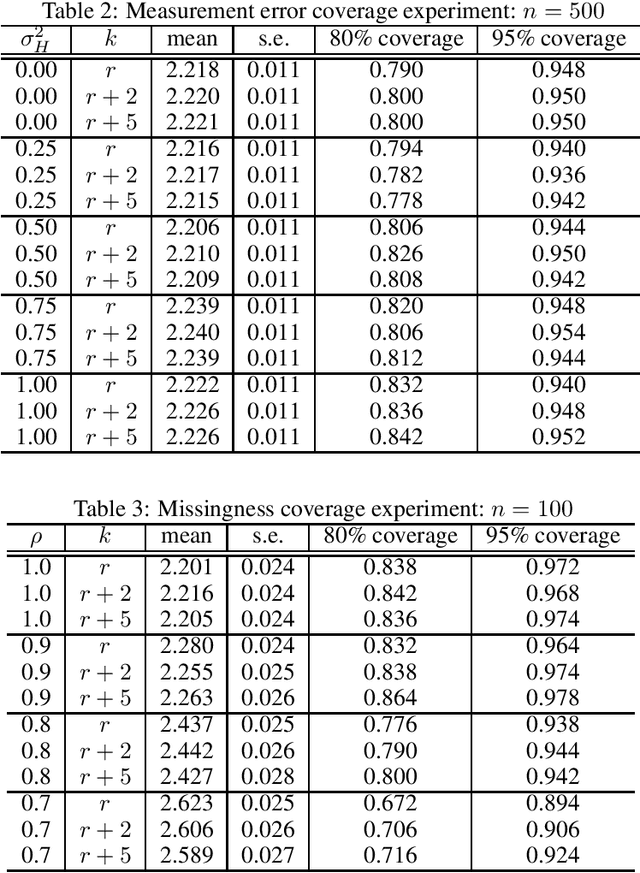
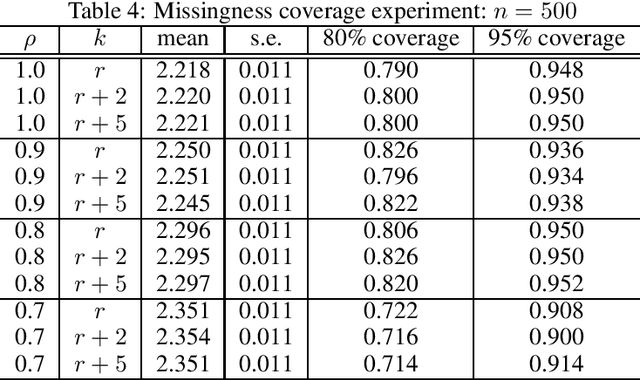
Even the most carefully curated economic data sets have variables that are noisy, missing, discretized, or privatized. The standard workflow for empirical research involves data cleaning followed by data analysis that typically ignores the bias and variance consequences of data cleaning. We formulate a semiparametric model for causal inference with corrupted data to encompass both data cleaning and data analysis. We propose a new end-to-end procedure for data cleaning, estimation, and inference with data cleaning-adjusted confidence intervals. We prove root-n consistency, Gaussian approximation, and semiparametric efficiency for our estimator of the causal parameter by finite sample arguments. Our key assumption is that the true covariates are approximately low rank. In our analysis, we provide nonasymptotic theoretical contributions to matrix completion, statistical learning, and semiparametric statistics. We verify the coverage of the data cleaning-adjusted confidence intervals in simulations.
PerSim: Data-Efficient Offline Reinforcement Learning with Heterogeneous Agents via Personalized Simulators
Mar 17, 2021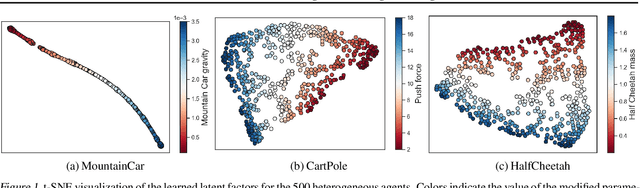

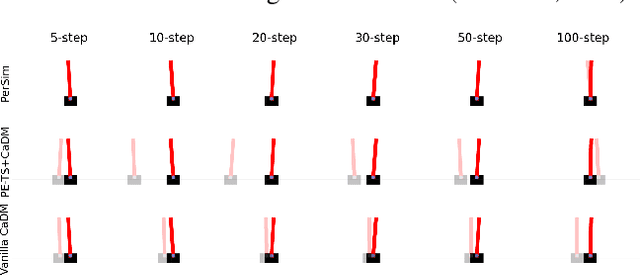
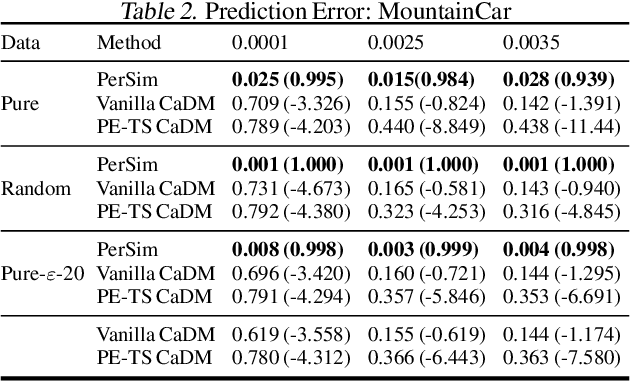
We consider offline reinforcement learning (RL) with heterogeneous agents under severe data scarcity, i.e., we only observe a single historical trajectory for every agent under an unknown, potentially sub-optimal policy. We find that the performance of state-of-the-art offline and model-based RL methods degrade significantly given such limited data availability, even for commonly perceived "solved" benchmark settings such as "MountainCar" and "CartPole". To address this challenge, we propose a model-based offline RL approach, called PerSim, where we first learn a personalized simulator for each agent by collectively using the historical trajectories across all agents prior to learning a policy. We do so by positing that the transition dynamics across agents can be represented as a latent function of latent factors associated with agents, states, and actions; subsequently, we theoretically establish that this function is well-approximated by a "low-rank" decomposition of separable agent, state, and action latent functions. This representation suggests a simple, regularized neural network architecture to effectively learn the transition dynamics per agent, even with scarce, offline data.We perform extensive experiments across several benchmark environments and RL methods. The consistent improvement of our approach, measured in terms of state dynamics prediction and eventual reward, confirms the efficacy of our framework in leveraging limited historical data to simultaneously learn personalized policies across agents.
On Principal Component Regression in a High-Dimensional Error-in-Variables Setting
Oct 27, 2020
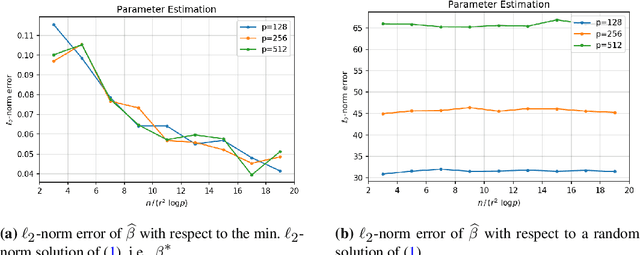
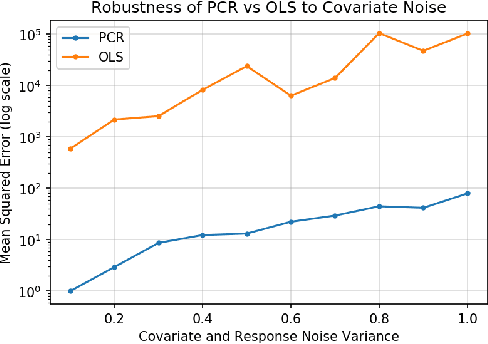
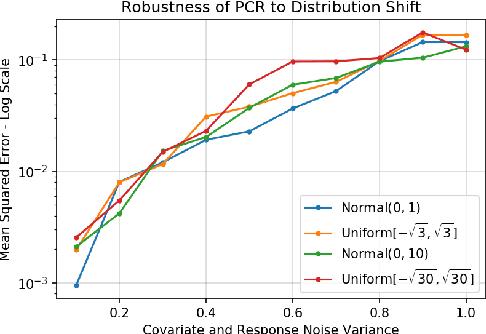
We analyze the classical method of Principal Component Regression (PCR) in the high-dimensional error-in-variables setting. Here, the observed covariates are not only noisy and contain missing data, but the number of covariates can also exceed the sample size. Under suitable conditions, we establish that PCR identifies the unique model parameter with minimum $\ell_2$-norm, and derive non-asymptotic $\ell_2$-rates of convergence that show its consistency. We further provide non-asymptotic out-of-sample prediction performance guarantees that again prove consistency, even in the presence of corrupted unseen data. Notably, our results do not require the out-of-samples covariates to follow the same distribution as that of the in-sample covariates, but rather that they obey a simple linear algebraic constraint. We finish by presenting simulations that illustrate our theoretical results.
On Multivariate Singular Spectrum Analysis
Jun 24, 2020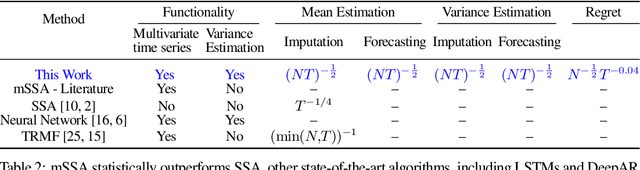
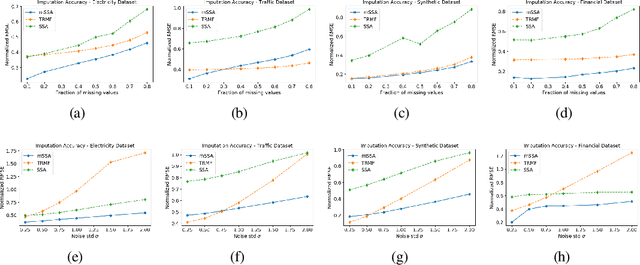
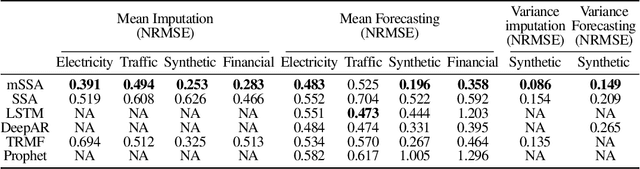
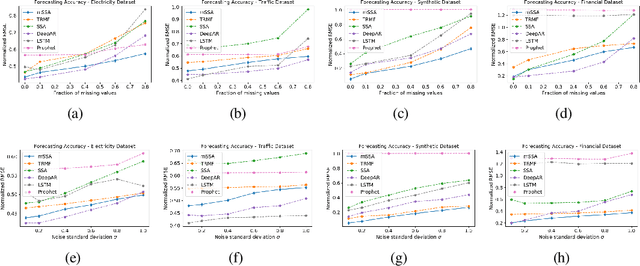
We analyze a variant of multivariate singular spectrum analysis (mSSA), a widely used multivariate time series method, which we find to perform competitively with respect to the state-of-art neural network time series methods (LSTM, DeepAR). Its restriction for single time series, singular spectrum analysis (SSA), has been analyzed recently. Despite its popularity, theoretical understanding of mSSA is absent. Towards this, we introduce a natural spatio-temporal factor model to analyze mSSA. We establish the in-sample prediction error for imputation and forecasting under mSSA scales as $1/\sqrt{NT}$, for $N$ time series with $T$ observations per time series. In contrast, for SSA the error scales as $1/\sqrt{T}$ and for matrix factorization based time series methods, the error scales as ${1}/{\min(N, T)}$. We utilize an online learning framework to analyze the one-step-ahead prediction error of mSSA and establish it has a regret of ${1}/{(\sqrt{N}T^{0.04})}$ with respect to in-sample forecasting error. By applying mSSA on the square of the time series observations, we furnish an algorithm to estimate the time-varying variance of a time series and establish it has in-sample imputation / forecasting error scaling as $1/\sqrt{NT}$. To establish our results, we make three technical contributions. First, we establish that the "stacked" Page Matrix time series representation, the core data structure in mSSA, has an approximate low-rank structure for a large class of time series models used in practice under the spatio-temporal factor model. Second, we extend the theory of online convex optimization to address the variant when the constraints are time-varying. Third, we extend the analysis prediction error analysis of Principle Component Regression beyond recent work to when the covariate matrix is approximately low-rank.
Synthetic Interventions
Jun 13, 2020
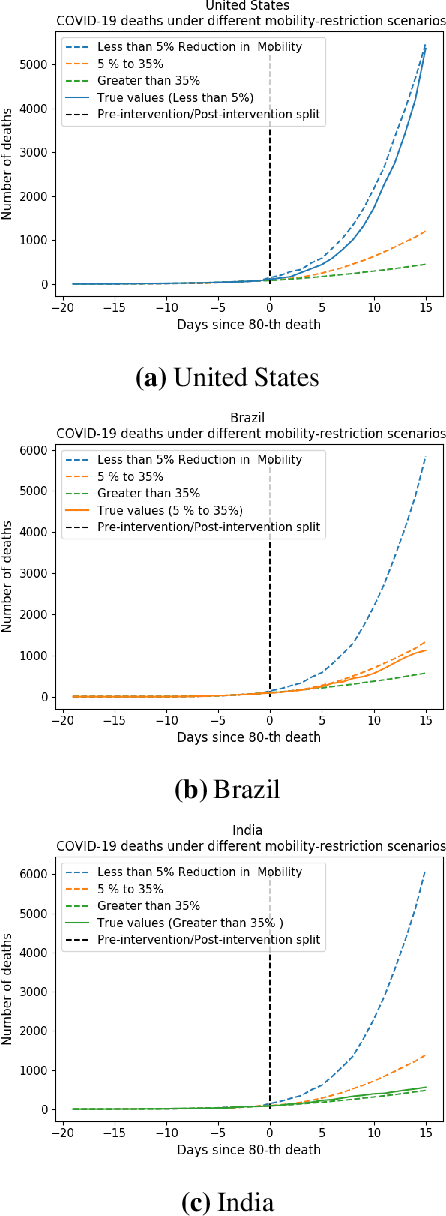

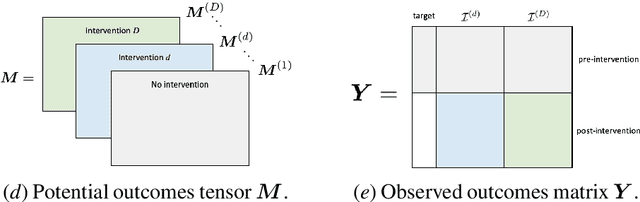
We develop a method to help quantify the impact different levels of mobility restrictions could have had on COVID-19 related deaths across nations. Synthetic control (SC) has emerged as a standard tool in such scenarios to produce counterfactual estimates if a particular intervention had not occurred, using just observational data. However, it remains an important open problem of how to extend SC to obtain counterfactual estimates if a particular intervention had occurred - this is exactly the question of the impact of mobility restrictions stated above. As our main contribution, we introduce synthetic interventions (SI), which helps resolve this open problem by allowing one to produce counterfactual estimates if there are multiple interventions of interest. We prove SI produces consistent counterfactual estimates under a tensor factor model. Our finite sample analysis shows the test error decays as $1/T_0$, where $T_0$ is the amount of observed pre-intervention data. As a special case, this improves upon the $1/\sqrt{T_0}$ bound on test error for SC in prior works. Our test error bound holds under a certain "subspace inclusion" condition; we furnish a data-driven hypothesis test with provable guarantees to check for this condition. This also provides a quantitative hypothesis test for when to use SC, currently absent in the literature. Technically, we establish the parameter estimation and test error for Principal Component Regression (a key subroutine in SI and several SC variants) under the setting of error-in-variable regression decays as $1/T_0$, where $T_0$ is the number of samples observed; this improves the best prior test error bound of $1/\sqrt{T_0}$. In addition to the COVID-19 case study, we show how SI can be used to run data-efficient, personalized randomized control trials using real data from a large e-commerce website and a large developmental economics study.