 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFingerprint Spoof Buster
Dec 12, 2017
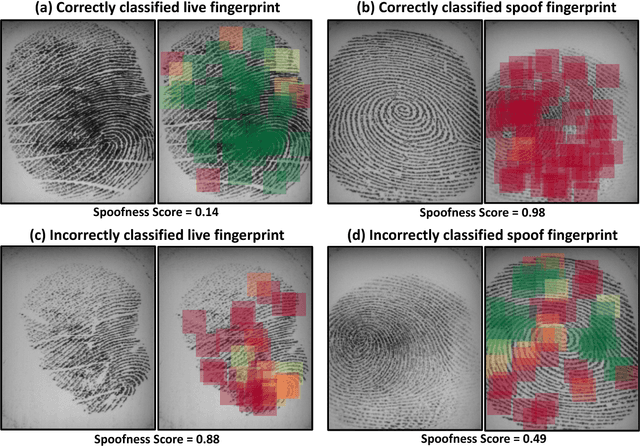
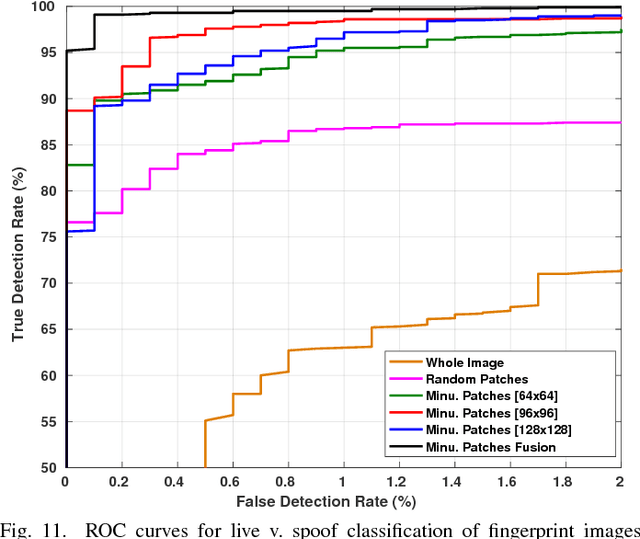

The primary purpose of a fingerprint recognition system is to ensure a reliable and accurate user authentication, but the security of the recognition system itself can be jeopardized by spoof attacks. This study addresses the problem of developing accurate, generalizable, and efficient algorithms for detecting fingerprint spoof attacks. Specifically, we propose a deep convolutional neural network based approach utilizing local patches centered and aligned using fingerprint minutiae. Experimental results on three public-domain LivDet datasets (2011, 2013, and 2015) show that the proposed approach provides state-of-the-art accuracies in fingerprint spoof detection for intra-sensor, cross-material, cross-sensor, as well as cross-dataset testing scenarios. For example, in LivDet 2015, the proposed approach achieves 99.03% average accuracy over all sensors compared to 95.51% achieved by the LivDet 2015 competition winners. Additionally, two new fingerprint presentation attack datasets containing more than 20,000 images, using two different fingerprint readers, and over 12 different spoof fabrication materials are collected. We also present a graphical user interface, called Fingerprint Spoof Buster, that allows the operator to visually examine the local regions of the fingerprint highlighted as live or spoof, instead of relying on only a single score as output by the traditional approaches.
Longitudinal Study of Child Face Recognition
Nov 10, 2017
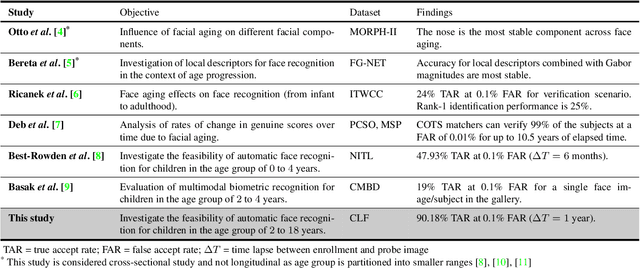

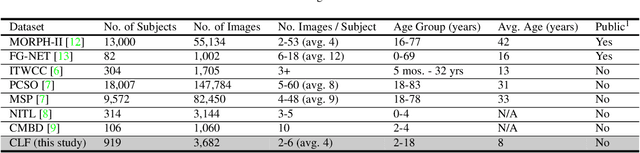
We present a longitudinal study of face recognition performance on Children Longitudinal Face (CLF) dataset containing 3,682 face images of 919 subjects, in the age group [2, 18] years. Each subject has at least four face images acquired over a time span of up to six years. Face comparison scores are obtained from (i) a state-of-the-art COTS matcher (COTS-A), (ii) an open-source matcher (FaceNet), and (iii) a simple sum fusion of scores obtained from COTS-A and FaceNet matchers. To improve the performance of the open-source FaceNet matcher for child face recognition, we were able to fine-tune it on an independent training set of 3,294 face images of 1,119 children in the age group [3, 18] years. Multilevel statistical models are fit to genuine comparison scores from the CLF dataset to determine the decrease in face recognition accuracy over time. Additionally, we analyze both the verification and open-set identification accuracies in order to evaluate state-of-the-art face recognition technology for tracing and identifying children lost at a young age as victims of child trafficking or abduction.
Heterogeneous Face Attribute Estimation: A Deep Multi-Task Learning Approach
Sep 28, 2017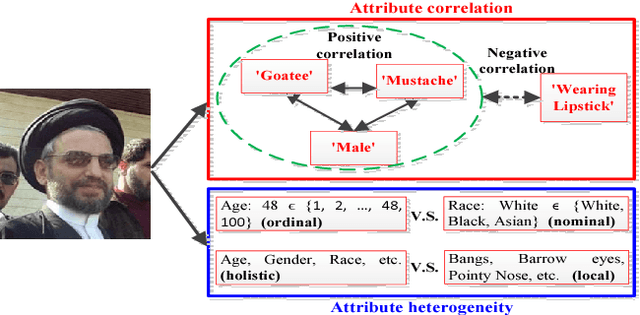
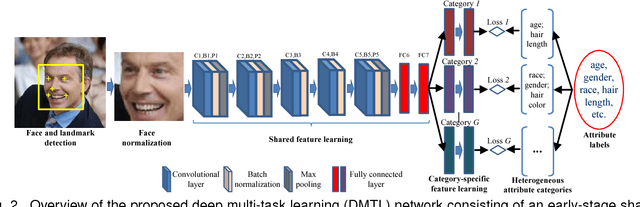
Face attribute estimation has many potential applications in video surveillance, face retrieval, and social media. While a number of methods have been proposed for face attribute estimation, most of them did not explicitly consider the attribute correlation and heterogeneity (e.g., ordinal vs. nominal and holistic vs. local) during feature representation learning. In this paper, we present a Deep Multi-Task Learning (DMTL) approach to jointly estimate multiple heterogeneous attributes from a single face image. In DMTL, we tackle attribute correlation and heterogeneity with convolutional neural networks (CNNs) consisting of shared feature learning for all the attributes, and category-specific feature learning for heterogeneous attributes. We also introduce an unconstrained face database (LFW+), an extension of public-domain LFW, with heterogeneous demographic attributes (age, gender, and race) obtained via crowdsourcing. Experimental results on benchmarks with multiple face attributes (MORPH II, LFW+, CelebA, LFWA, and FotW) show that the proposed approach has superior performance compared to state of the art. Finally, evaluations on a public-domain face database (LAP) with a single attribute show that the proposed approach has excellent generalization ability.
RaspiReader: An Open Source Fingerprint Reader Facilitating Spoof Detection
Aug 25, 2017


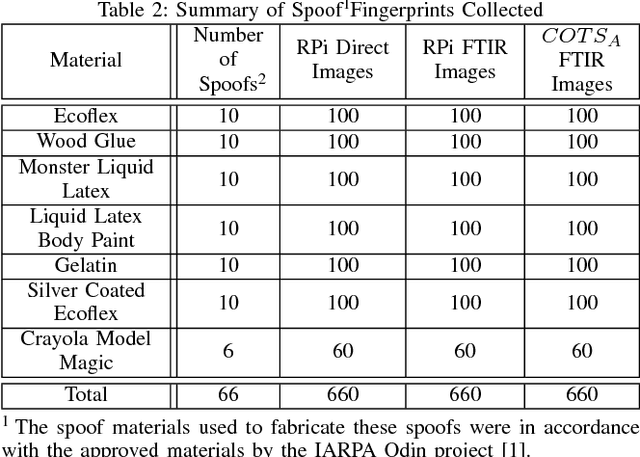
We present the design and prototype of an open source, optical fingerprint reader, called RaspiReader, using ubiquitous components. RaspiReader, a low-cost and easy to assemble reader, provides the fingerprint research community a seamless and simple method for gaining more control over the sensing component of fingerprint recognition systems. In particular, we posit that this versatile fingerprint reader will encourage researchers to explore novel spoof detection methods that integrate both hardware and software. RaspiReader's hardware is customized with two cameras for fingerprint acquisition with one camera providing high contrast, frustrated total internal reflection (FTIR) images, and the other camera outputting direct images. Using both of these image streams, we extract complementary information which, when fused together, results in highly discriminative features for fingerprint spoof (presentation attack) detection. Our experimental results demonstrate a marked improvement over previous spoof detection methods which rely only on FTIR images provided by COTS optical readers. Finally, fingerprint matching experiments between images acquired from the FTIR output of the RaspiReader and images acquired from a COTS fingerprint reader verify the interoperability of the RaspiReader with existing COTS optical readers.
Automatic Face Image Quality Prediction
Jun 29, 2017

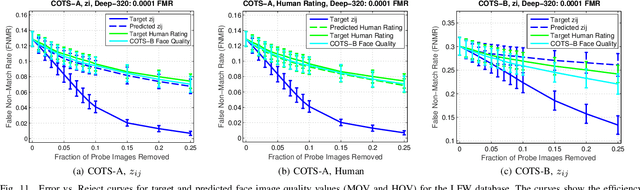
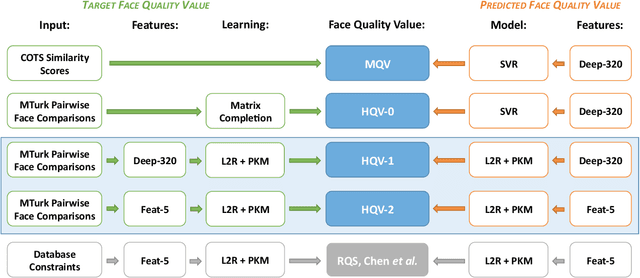
Face image quality can be defined as a measure of the utility of a face image to automatic face recognition. In this work, we propose (and compare) two methods for automatic face image quality based on target face quality values from (i) human assessments of face image quality (matcher-independent), and (ii) quality values computed from similarity scores (matcher-dependent). A support vector regression model trained on face features extracted using a deep convolutional neural network (ConvNet) is used to predict the quality of a face image. The proposed methods are evaluated on two unconstrained face image databases, LFW and IJB-A, which both contain facial variations with multiple quality factors. Evaluation of the proposed automatic face image quality measures shows we are able to reduce the FNMR at 1% FMR by at least 13% for two face matchers (a COTS matcher and a ConvNet matcher) by using the proposed face quality to select subsets of face images and video frames for matching templates (i.e., multiple faces per subject) in the IJB-A protocol. To our knowledge, this is the first work to utilize human assessments of face image quality in designing a predictor of unconstrained face quality that is shown to be effective in cross-database evaluation.
Universal 3D Wearable Fingerprint Targets: Advancing Fingerprint Reader Evaluations
May 22, 2017
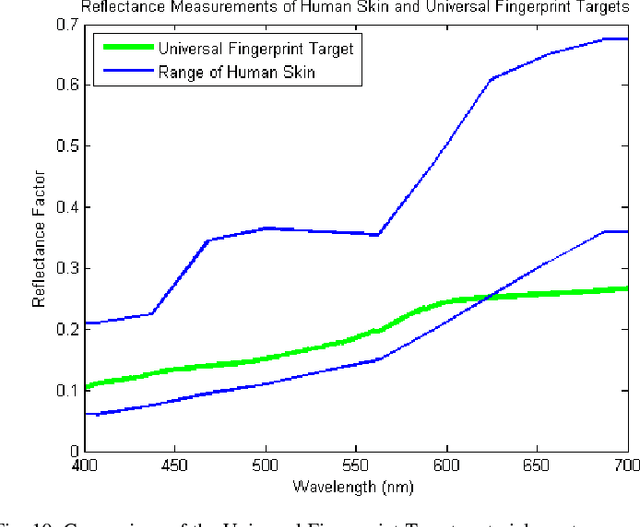


We present the design and manufacturing of high fidelity universal 3D fingerprint targets, which can be imaged on a variety of fingerprint sensing technologies, namely capacitive, contact-optical, and contactless-optical. Universal 3D fingerprint targets enable, for the first time, not only a repeatable and controlled evaluation of fingerprint readers, but also the ability to conduct fingerprint reader interoperability studies. Fingerprint reader interoperability refers to how robust fingerprint recognition systems are to variations in the images acquired by different types of fingerprint readers. To build universal 3D fingerprint targets, we adopt a molding and casting framework consisting of (i) digital mapping of fingerprint images to a negative mold, (ii) CAD modeling a scaffolding system to hold the negative mold, (iii) fabricating the mold and scaffolding system with a high resolution 3D printer, (iv) producing or mixing a material with similar electrical, optical, and mechanical properties to that of the human finger, and (v) fabricating a 3D fingerprint target using controlled casting. Our experiments conducted with PIV and Appendix F certified optical (contact and contactless) and capacitive fingerprint readers demonstrate the usefulness of universal 3D fingerprint targets for controlled and repeatable fingerprint reader evaluations and also fingerprint reader interoperability studies.
Automated Latent Fingerprint Recognition
Apr 06, 2017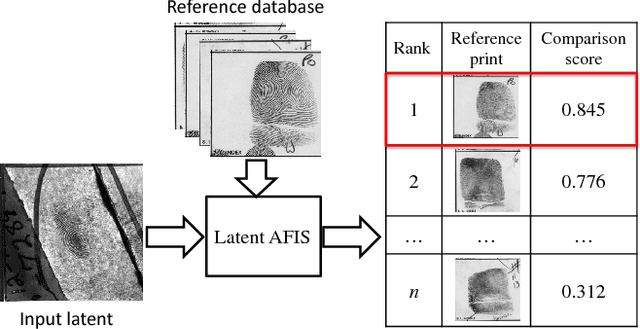
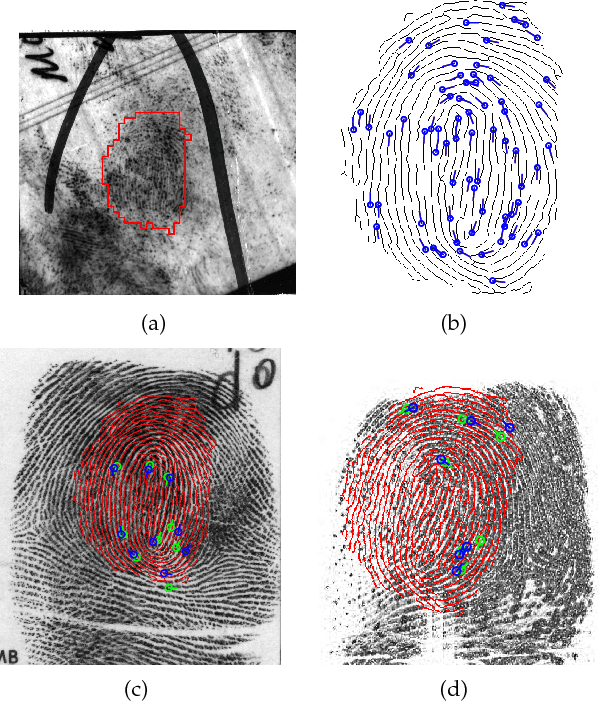


Latent fingerprints are one of the most important and widely used evidence in law enforcement and forensic agencies worldwide. Yet, NIST evaluations show that the performance of state-of-the-art latent recognition systems is far from satisfactory. An automated latent fingerprint recognition system with high accuracy is essential to compare latents found at crime scenes to a large collection of reference prints to generate a candidate list of possible mates. In this paper, we propose an automated latent fingerprint recognition algorithm that utilizes Convolutional Neural Networks (ConvNets) for ridge flow estimation and minutiae descriptor extraction, and extract complementary templates (two minutiae templates and one texture template) to represent the latent. The comparison scores between the latent and a reference print based on the three templates are fused to retrieve a short candidate list from the reference database. Experimental results show that the rank-1 identification accuracies (query latent is matched with its true mate in the reference database) are 64.7% for the NIST SD27 and 75.3% for the WVU latent databases, against a reference database of 100K rolled prints. These results are the best among published papers on latent recognition and competitive with the performance (66.7% and 70.8% rank-1 accuracies on NIST SD27 and WVU DB, respectively) of a leading COTS latent Automated Fingerprint Identification System (AFIS). By score-level (rank-level) fusion of our system with the commercial off-the-shelf (COTS) latent AFIS, the overall rank-1 identification performance can be improved from 64.7% and 75.3% to 73.3% (74.4%) and 76.6% (78.4%) on NIST SD27 and WVU latent databases, respectively.
Asynchronous Multi-Task Learning
Sep 30, 2016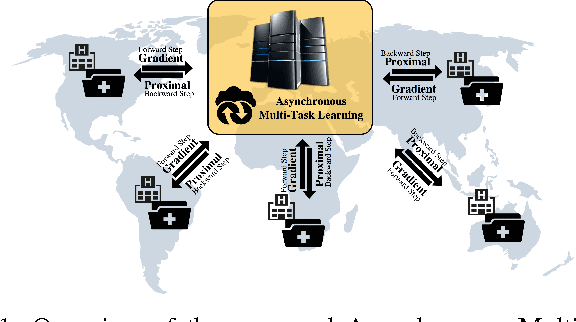
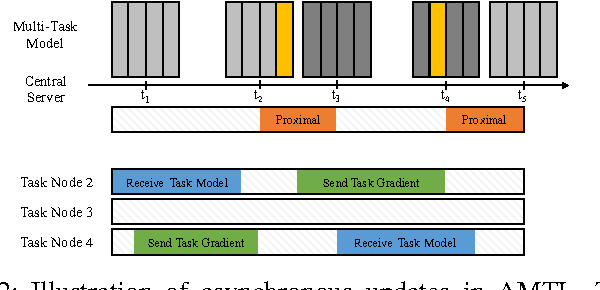
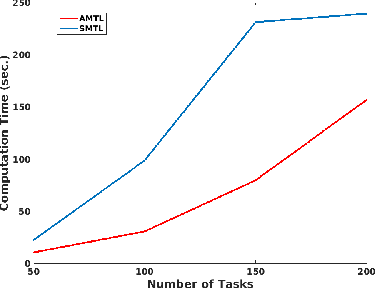
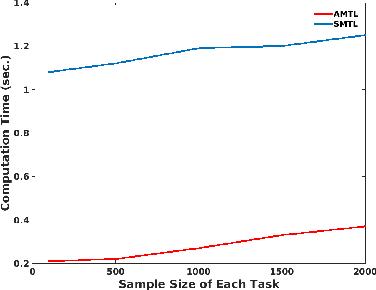
Many real-world machine learning applications involve several learning tasks which are inter-related. For example, in healthcare domain, we need to learn a predictive model of a certain disease for many hospitals. The models for each hospital may be different because of the inherent differences in the distributions of the patient populations. However, the models are also closely related because of the nature of the learning tasks modeling the same disease. By simultaneously learning all the tasks, multi-task learning (MTL) paradigm performs inductive knowledge transfer among tasks to improve the generalization performance. When datasets for the learning tasks are stored at different locations, it may not always be feasible to transfer the data to provide a data-centralized computing environment due to various practical issues such as high data volume and privacy. In this paper, we propose a principled MTL framework for distributed and asynchronous optimization to address the aforementioned challenges. In our framework, gradient update does not wait for collecting the gradient information from all the tasks. Therefore, the proposed method is very efficient when the communication delay is too high for some task nodes. We show that many regularized MTL formulations can benefit from this framework, including the low-rank MTL for shared subspace learning. Empirical studies on both synthetic and real-world datasets demonstrate the efficiency and effectiveness of the proposed framework.
Clustering Millions of Faces by Identity
Apr 04, 2016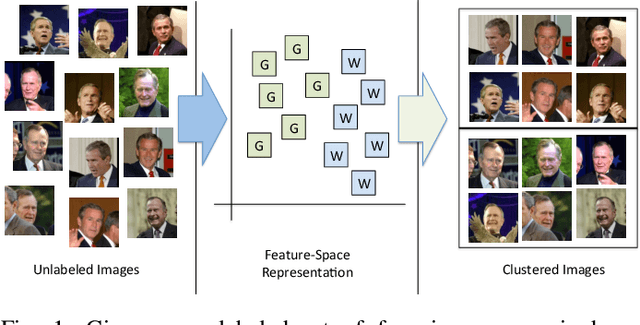

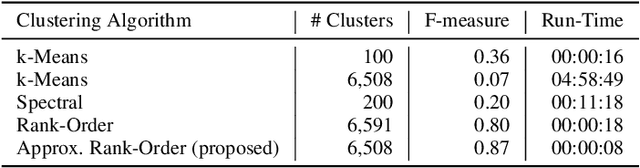
In this work, we attempt to address the following problem: Given a large number of unlabeled face images, cluster them into the individual identities present in this data. We consider this a relevant problem in different application scenarios ranging from social media to law enforcement. In large-scale scenarios the number of faces in the collection can be of the order of hundreds of million, while the number of clusters can range from a few thousand to millions--leading to difficulties in terms of both run-time complexity and evaluating clustering and per-cluster quality. An efficient and effective Rank-Order clustering algorithm is developed to achieve the desired scalability, and better clustering accuracy than other well-known algorithms such as k-means and spectral clustering. We cluster up to 123 million face images into over 10 million clusters, and analyze the results in terms of both external cluster quality measures (known face labels) and internal cluster quality measures (unknown face labels) and run-time. Our algorithm achieves an F-measure of 0.87 on a benchmark unconstrained face dataset (LFW, consisting of 13K faces), and 0.27 on the largest dataset considered (13K images in LFW, plus 123M distractor images). Additionally, we present preliminary work on video frame clustering (achieving 0.71 F-measure when clustering all frames in the benchmark YouTube Faces dataset). A per-cluster quality measure is developed which can be used to rank individual clusters and to automatically identify a subset of good quality clusters for manual exploration.
Nonlinear Local Metric Learning for Person Re-identification
Nov 16, 2015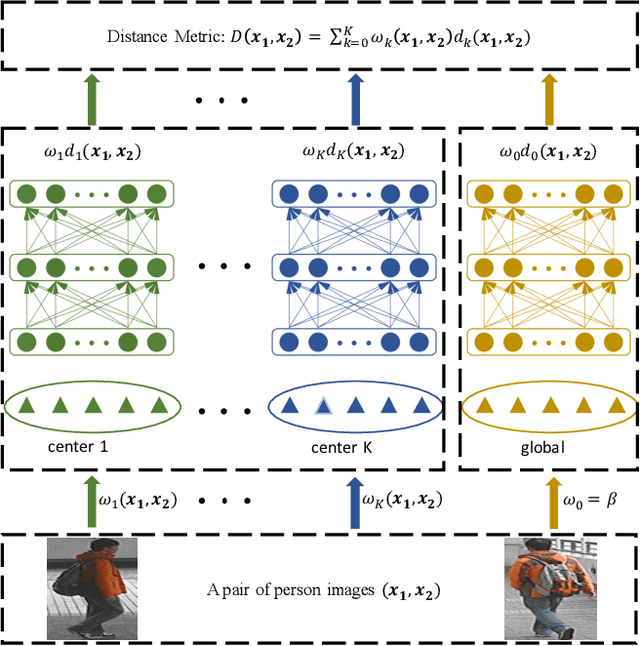
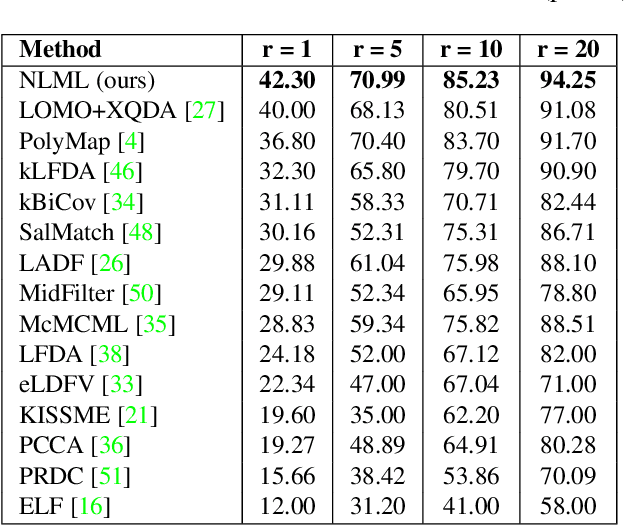


Person re-identification aims at matching pedestrians observed from non-overlapping camera views. Feature descriptor and metric learning are two significant problems in person re-identification. A discriminative metric learning method should be capable of exploiting complex nonlinear transformations due to the large variations in feature space. In this paper, we propose a nonlinear local metric learning (NLML) method to improve the state-of-the-art performance of person re-identification on public datasets. Motivated by the fact that local metric learning has been introduced to handle the data which varies locally and deep neural network has presented outstanding capability in exploiting the nonlinearity of samples, we utilize the merits of both local metric learning and deep neural network to learn multiple sets of nonlinear transformations. By enforcing a margin between the distances of positive pedestrian image pairs and distances of negative pairs in the transformed feature subspace, discriminative information can be effectively exploited in the developed neural networks. Our experiments show that the proposed NLML method achieves the state-of-the-art results on the widely used VIPeR, GRID, and CUHK 01 datasets.