 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap Between Computational Photography and Visual Recognition
Jan 28, 2019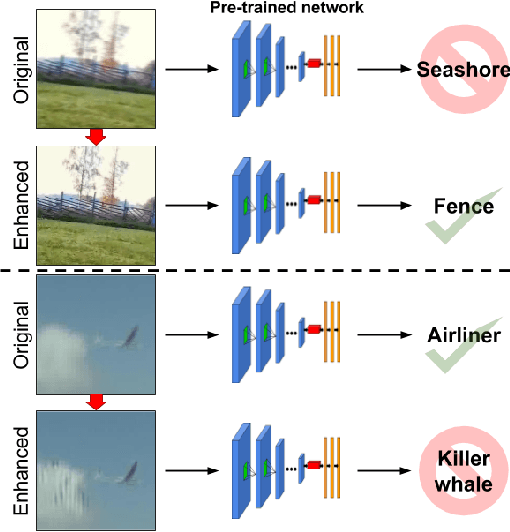
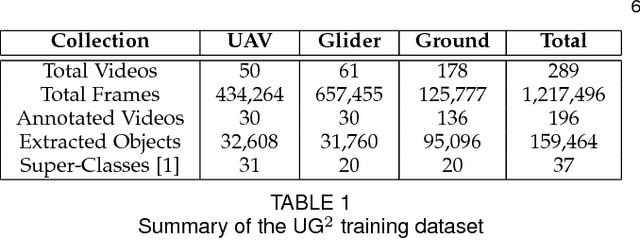

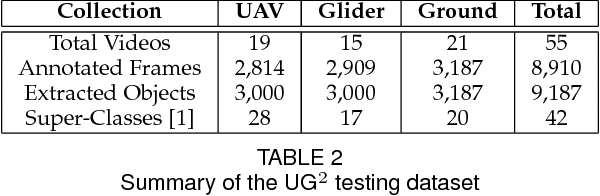
What is the current state-of-the-art for image restoration and enhancement applied to degraded images acquired under less than ideal circumstances? Can the application of such algorithms as a pre-processing step to improve image interpretability for manual analysis or automatic visual recognition to classify scene content? While there have been important advances in the area of computational photography to restore or enhance the visual quality of an image, the capabilities of such techniques have not always translated in a useful way to visual recognition tasks. Consequently, there is a pressing need for the development of algorithms that are designed for the joint problem of improving visual appearance and recognition, which will be an enabling factor for the deployment of visual recognition tools in many real-world scenarios. To address this, we introduce the UG^2 dataset as a large-scale benchmark composed of video imagery captured under challenging conditions, and two enhancement tasks designed to test algorithmic impact on visual quality and automatic object recognition. Furthermore, we propose a set of metrics to evaluate the joint improvement of such tasks as well as individual algorithmic advances, including a novel psychophysics-based evaluation regime for human assessment and a realistic set of quantitative measures for object recognition performance. We introduce six new algorithms for image restoration or enhancement, which were created as part of the IARPA sponsored UG^2 Challenge workshop held at CVPR 2018. Under the proposed evaluation regime, we present an in-depth analysis of these algorithms and a host of deep learning-based and classic baseline approaches. From the observed results, it is evident that we are in the early days of building a bridge between computational photography and visual recognition, leaving many opportunities for innovation in this area.
Face Clustering: Representation and Pairwise Constraints
Jul 27, 2018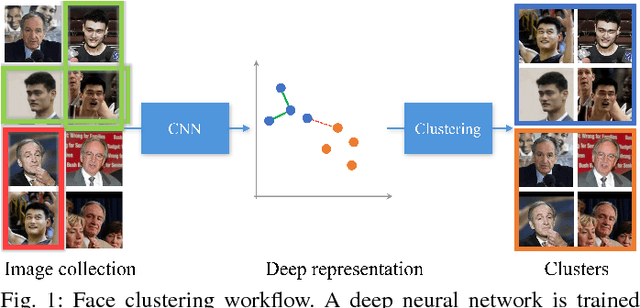
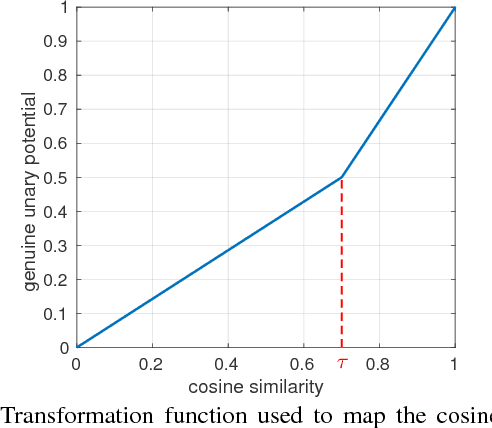


Clustering face images according to their identity has two important applications: (i) grouping a collection of face images when no external labels are associated with images, and (ii) indexing for efficient large scale face retrieval. The clustering problem is composed of two key parts: face representation and choice of similarity for grouping faces. We first propose a representation based on ResNet, which has been shown to perform very well in image classification problems. Given this representation, we design a clustering algorithm, Conditional Pairwise Clustering (ConPaC), which directly estimates the adjacency matrix only based on the similarity between face images. This allows a dynamic selection of number of clusters and retains pairwise similarity between faces. ConPaC formulates the clustering problem as a Conditional Random Field (CRF) model and uses Loopy Belief Propagation to find an approximate solution for maximizing the posterior probability of the adjacency matrix. Experimental results on two benchmark face datasets (LFW and IJB-B) show that ConPaC outperforms well known clustering algorithms such as k-means, spectral clustering and approximate rank-order. Additionally, our algorithm can naturally incorporate pairwise constraints to obtain a semi-supervised version that leads to improved clustering performance. We also propose an k-NN variant of ConPaC, which has a linear time complexity given a k-NN graph, suitable for large datasets.
* This second version is the same as TIFS version. Some experiment results are different from v1 because we correct the protocols
Clustering Millions of Faces by Identity
Apr 04, 2016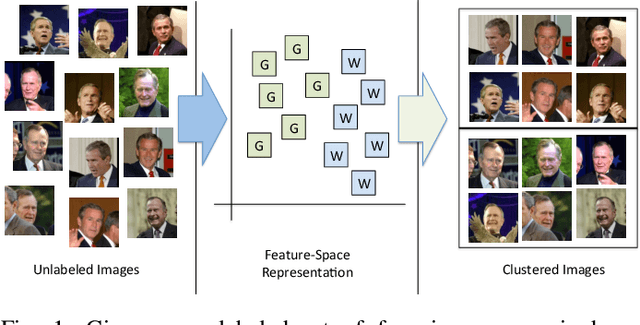

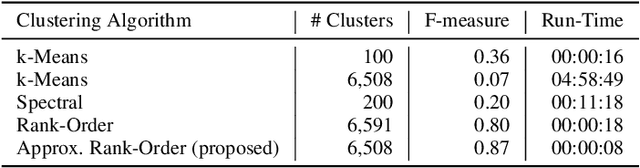
In this work, we attempt to address the following problem: Given a large number of unlabeled face images, cluster them into the individual identities present in this data. We consider this a relevant problem in different application scenarios ranging from social media to law enforcement. In large-scale scenarios the number of faces in the collection can be of the order of hundreds of million, while the number of clusters can range from a few thousand to millions--leading to difficulties in terms of both run-time complexity and evaluating clustering and per-cluster quality. An efficient and effective Rank-Order clustering algorithm is developed to achieve the desired scalability, and better clustering accuracy than other well-known algorithms such as k-means and spectral clustering. We cluster up to 123 million face images into over 10 million clusters, and analyze the results in terms of both external cluster quality measures (known face labels) and internal cluster quality measures (unknown face labels) and run-time. Our algorithm achieves an F-measure of 0.87 on a benchmark unconstrained face dataset (LFW, consisting of 13K faces), and 0.27 on the largest dataset considered (13K images in LFW, plus 123M distractor images). Additionally, we present preliminary work on video frame clustering (achieving 0.71 F-measure when clustering all frames in the benchmark YouTube Faces dataset). A per-cluster quality measure is developed which can be used to rank individual clusters and to automatically identify a subset of good quality clusters for manual exploration.
Face Search at Scale: 80 Million Gallery
Jul 28, 2015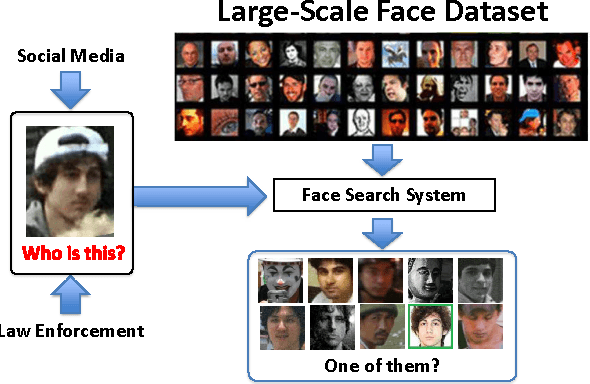
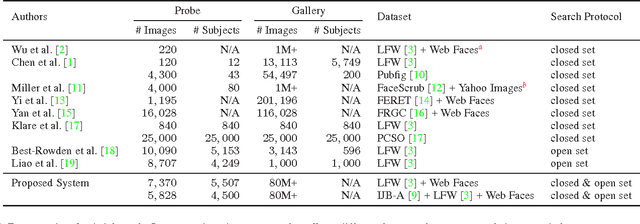
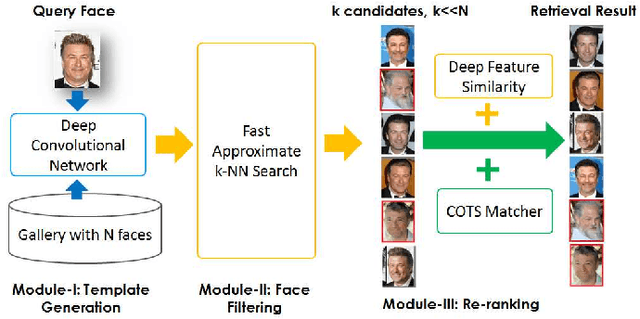
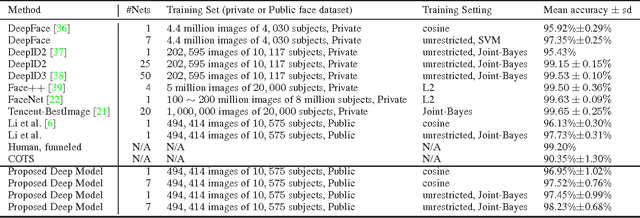
Due to the prevalence of social media websites, one challenge facing computer vision researchers is to devise methods to process and search for persons of interest among the billions of shared photos on these websites. Facebook revealed in a 2013 white paper that its users have uploaded more than 250 billion photos, and are uploading 350 million new photos each day. Due to this humongous amount of data, large-scale face search for mining web images is both important and challenging. Despite significant progress in face recognition, searching a large collection of unconstrained face images has not been adequately addressed. To address this challenge, we propose a face search system which combines a fast search procedure, coupled with a state-of-the-art commercial off the shelf (COTS) matcher, in a cascaded framework. Given a probe face, we first filter the large gallery of photos to find the top-k most similar faces using deep features generated from a convolutional neural network. The k candidates are re-ranked by combining similarities from deep features and the COTS matcher. We evaluate the proposed face search system on a gallery containing 80 million web-downloaded face images. Experimental results demonstrate that the deep features are competitive with state-of-the-art methods on unconstrained face recognition benchmarks (LFW and IJB-A). Further, the proposed face search system offers an excellent trade-off between accuracy and scalability on datasets consisting of millions of images. Additionally, in an experiment involving searching for face images of the Tsarnaev brothers, convicted of the Boston Marathon bombing, the proposed face search system could find the younger brother's (Dzhokhar Tsarnaev) photo at rank 1 in 1 second on a 5M gallery and at rank 8 in 7 seconds on an 80M gallery.