 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpoofGAN: Synthetic Fingerprint Spoof Images
Apr 15, 2022
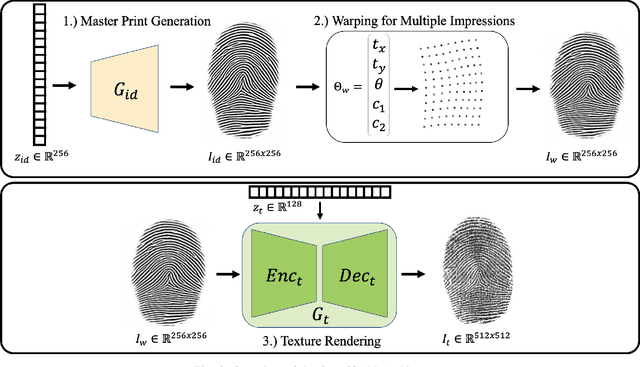


A major limitation to advances in fingerprint spoof detection is the lack of publicly available, large-scale fingerprint spoof datasets, a problem which has been compounded by increased concerns surrounding privacy and security of biometric data. Furthermore, most state-of-the-art spoof detection algorithms rely on deep networks which perform best in the presence of a large amount of training data. This work aims to demonstrate the utility of synthetic (both live and spoof) fingerprints in supplying these algorithms with sufficient data to improve the performance of fingerprint spoof detection algorithms beyond the capabilities when training on a limited amount of publicly available real datasets. First, we provide details of our approach in modifying a state-of-the-art generative architecture to synthesize high quality live and spoof fingerprints. Then, we provide quantitative and qualitative analysis to verify the quality of our synthetic fingerprints in mimicking the distribution of real data samples. We showcase the utility of our synthetic live and spoof fingerprints in training a deep network for fingerprint spoof detection, which dramatically boosts the performance across three different evaluation datasets compared to an identical model trained on real data alone. Finally, we demonstrate that only 25% of the original (real) dataset is required to obtain similar detection performance when augmenting the training dataset with synthetic data.
AdaFace: Quality Adaptive Margin for Face Recognition
Apr 03, 2022
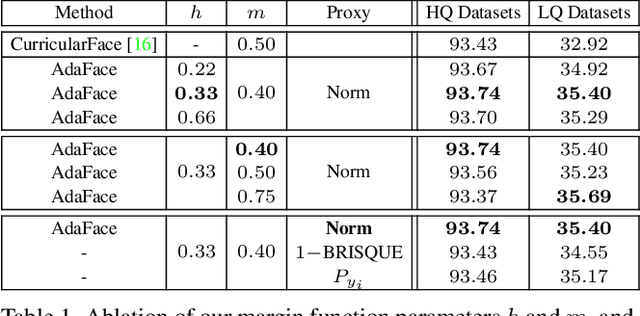


Recognition in low quality face datasets is challenging because facial attributes are obscured and degraded. Advances in margin-based loss functions have resulted in enhanced discriminability of faces in the embedding space. Further, previous studies have studied the effect of adaptive losses to assign more importance to misclassified (hard) examples. In this work, we introduce another aspect of adaptiveness in the loss function, namely the image quality. We argue that the strategy to emphasize misclassified samples should be adjusted according to their image quality. Specifically, the relative importance of easy or hard samples should be based on the sample's image quality. We propose a new loss function that emphasizes samples of different difficulties based on their image quality. Our method achieves this in the form of an adaptive margin function by approximating the image quality with feature norms. Extensive experiments show that our method, AdaFace, improves the face recognition performance over the state-of-the-art (SoTA) on four datasets (IJB-B, IJB-C, IJB-S and TinyFace). Code and models are released in https://github.com/mk-minchul/AdaFace.
PrintsGAN: Synthetic Fingerprint Generator
Jan 20, 2022
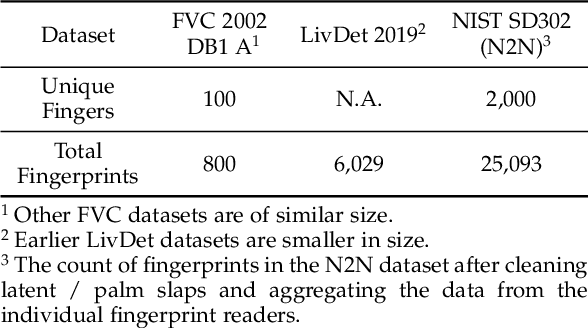


A major impediment to researchers working in the area of fingerprint recognition is the lack of publicly available, large-scale, fingerprint datasets. The publicly available datasets that do exist contain very few identities and impressions per finger. This limits research on a number of topics, including e.g., using deep networks to learn fixed length fingerprint embeddings. Therefore, we propose PrintsGAN, a synthetic fingerprint generator capable of generating unique fingerprints along with multiple impressions for a given fingerprint. Using PrintsGAN, we synthesize a database of 525k fingerprints (35K distinct fingers, each with 15 impressions). Next, we show the utility of the PrintsGAN generated dataset by training a deep network to extract a fixed-length embedding from a fingerprint. In particular, an embedding model trained on our synthetic fingerprints and fine-tuned on a small number of publicly available real fingerprints (25K prints from NIST SD302) obtains a TAR of 87.03% @ FAR=0.01% on the NIST SD4 database (a boost from TAR=73.37% when only trained on NIST SD302). Prevailing synthetic fingerprint generation methods do not enable such performance gains due to i) lack of realism or ii) inability to generate multiple impressions per finger. We plan to release our database of synthetic fingerprints to the public.
RealGait: Gait Recognition for Person Re-Identification
Jan 13, 2022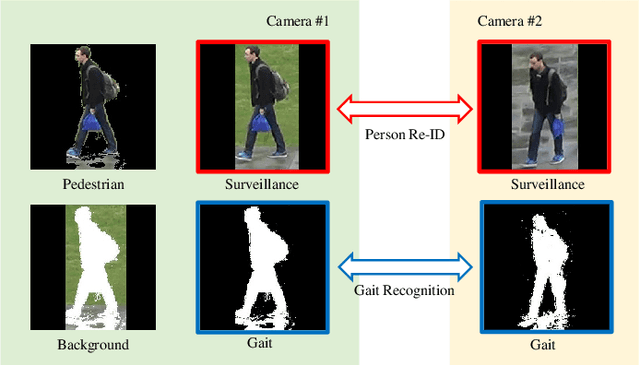
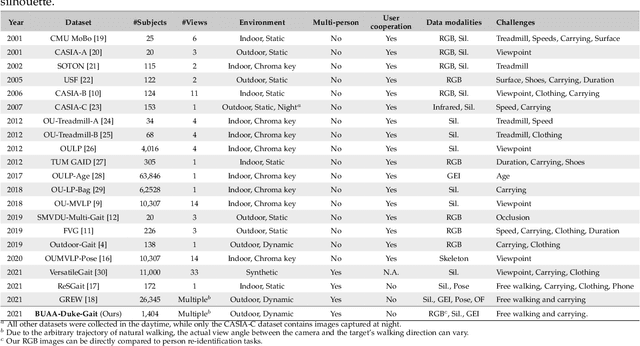


Human gait is considered a unique biometric identifier which can be acquired in a covert manner at a distance. However, models trained on existing public domain gait datasets which are captured in controlled scenarios lead to drastic performance decline when applied to real-world unconstrained gait data. On the other hand, video person re-identification techniques have achieved promising performance on large-scale publicly available datasets. Given the diversity of clothing characteristics, clothing cue is not reliable for person recognition in general. So, it is actually not clear why the state-of-the-art person re-identification methods work as well as they do. In this paper, we construct a new gait dataset by extracting silhouettes from an existing video person re-identification challenge which consists of 1,404 persons walking in an unconstrained manner. Based on this dataset, a consistent and comparative study between gait recognition and person re-identification can be carried out. Given that our experimental results show that current gait recognition approaches designed under data collected in controlled scenarios are inappropriate for real surveillance scenarios, we propose a novel gait recognition method, called RealGait. Our results suggest that recognizing people by their gait in real surveillance scenarios is feasible and the underlying gait pattern is probably the true reason why video person re-idenfification works in practice.
Trustworthy AI: A Computational Perspective
Aug 02, 2021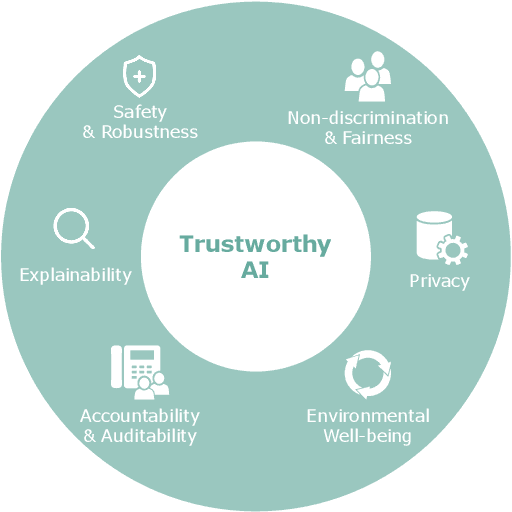
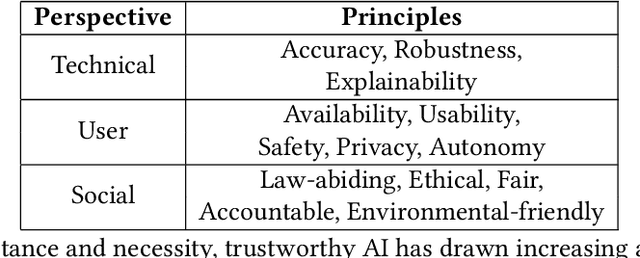
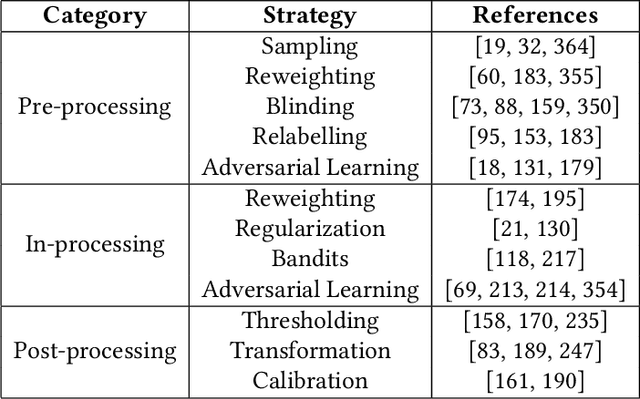
In the past few decades, artificial intelligence (AI) technology has experienced swift developments, changing everyone's daily life and profoundly altering the course of human society. The intention of developing AI is to benefit humans, by reducing human labor, bringing everyday convenience to human lives, and promoting social good. However, recent research and AI applications show that AI can cause unintentional harm to humans, such as making unreliable decisions in safety-critical scenarios or undermining fairness by inadvertently discriminating against one group. Thus, trustworthy AI has attracted immense attention recently, which requires careful consideration to avoid the adverse effects that AI may bring to humans, so that humans can fully trust and live in harmony with AI technologies. Recent years have witnessed a tremendous amount of research on trustworthy AI. In this survey, we present a comprehensive survey of trustworthy AI from a computational perspective, to help readers understand the latest technologies for achieving trustworthy AI. Trustworthy AI is a large and complex area, involving various dimensions. In this work, we focus on six of the most crucial dimensions in achieving trustworthy AI: (i) Safety & Robustness, (ii) Non-discrimination & Fairness, (iii) Explainability, (iv) Privacy, (v) Accountability & Auditability, and (vi) Environmental Well-Being. For each dimension, we review the recent related technologies according to a taxonomy and summarize their applications in real-world systems. We also discuss the accordant and conflicting interactions among different dimensions and discuss potential aspects for trustworthy AI to investigate in the future.
Biometrics: Trust, but Verify
May 31, 2021
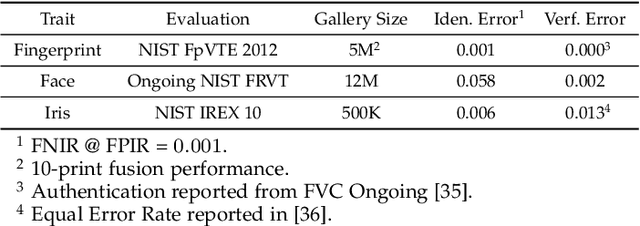
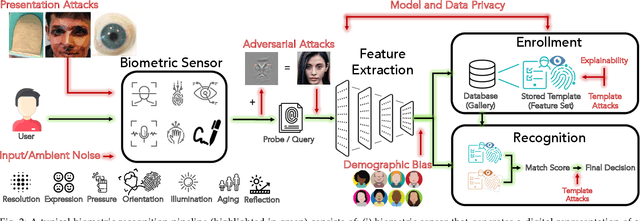

Over the past two decades, biometric recognition has exploded into a plethora of different applications around the globe. This proliferation can be attributed to the high levels of authentication accuracy and user convenience that biometric recognition systems afford end-users. However, in-spite of the success of biometric recognition systems, there are a number of outstanding problems and concerns pertaining to the various sub-modules of biometric recognition systems that create an element of mistrust in their use - both by the scientific community and also the public at large. Some of these problems include: i) questions related to system recognition performance, ii) security (spoof attacks, adversarial attacks, template reconstruction attacks and demographic information leakage), iii) uncertainty over the bias and fairness of the systems to all users, iv) explainability of the seemingly black-box decisions made by most recognition systems, and v) concerns over data centralization and user privacy. In this paper, we provide an overview of each of the aforementioned open-ended challenges. We survey work that has been conducted to address each of these concerns and highlight the issues requiring further attention. Finally, we provide insights into how the biometric community can address core biometric recognition systems design issues to better instill trust, fairness, and security for all.
C2CL: Contact to Contactless Fingerprint Matching
Apr 08, 2021
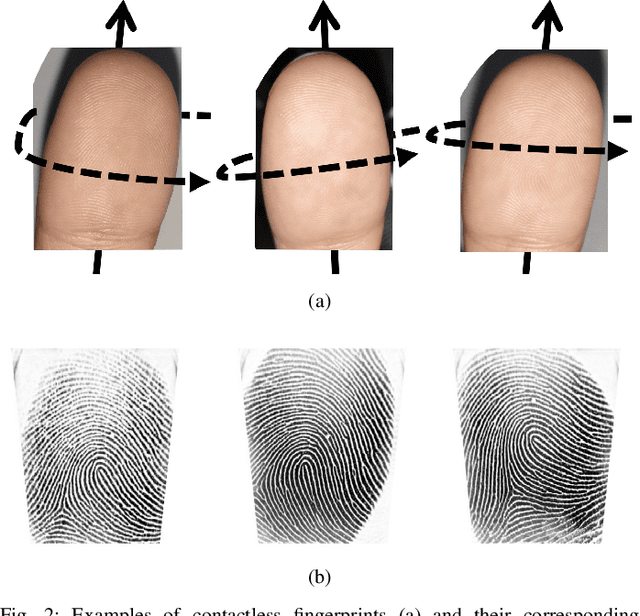
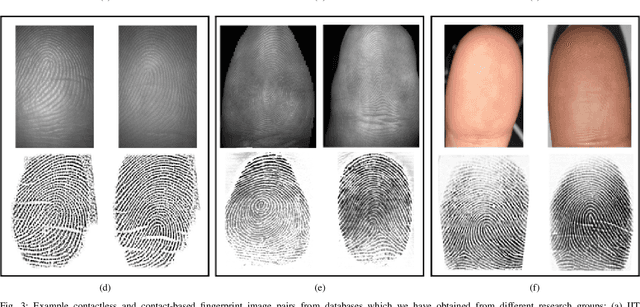
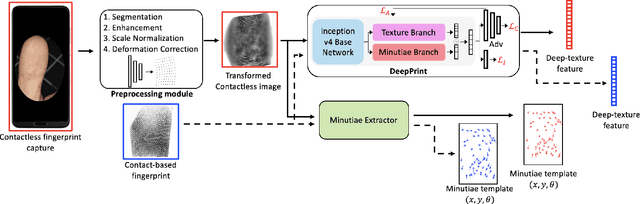
Matching contactless fingerprints or finger photos to contact-based fingerprint impressions has received increased attention in the wake of COVID-19 due to the superior hygiene of the contactless acquisition and the widespread availability of low cost mobile phones capable of capturing photos of fingerprints with sufficient resolution for verification purposes. This paper presents an end-to-end automated system, called C2CL, comprised of a mobile finger photo capture app, preprocessing, and matching algorithms to handle the challenges inhibiting previous cross-matching methods; namely i) low ridge-valley contrast of contactless fingerprints, ii) varying roll, pitch, yaw, and distance of the finger to the camera, iii) non-linear distortion of contact-based fingerprints, and vi) different image qualities of smartphone cameras. Our preprocessing algorithm segments, enhances, scales, and unwarps contactless fingerprints, while our matching algorithm extracts both minutiae and texture representations. A sequestered dataset of 9,888 contactless 2D fingerprints and corresponding contact-based fingerprints from 206 subjects (2 thumbs and 2 index fingers for each subject) acquired using our mobile capture app is used to evaluate the cross-database performance of our proposed algorithm. Furthermore, additional experimental results on 3 publicly available datasets demonstrate, for the first time, contact to contactless fingerprint matching accuracy that is comparable to existing contact to contact fingerprint matching systems (TAR in the range of 96.67% to 98.15% at FAR=0.01%).
FedFace: Collaborative Learning of Face Recognition Model
Apr 07, 2021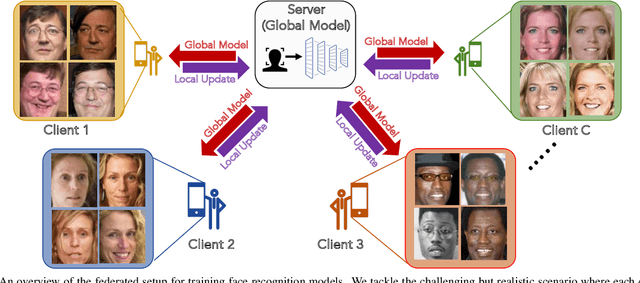
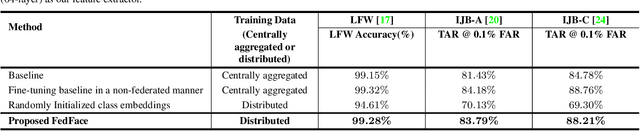
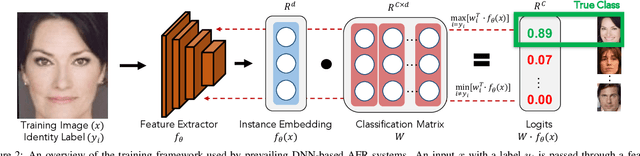

DNN-based face recognition models require large centrally aggregated face datasets for training. However, due to the growing data privacy concerns and legal restrictions, accessing and sharing face datasets has become exceedingly difficult. We propose FedFace, a federated learning (FL) framework for collaborative learning of face recognition models in a privacy preserving manner. FedFace utilizes the face images available on multiple clients to learn an accurate and generalizable face recognition model where the face images stored at each client are neither shared with other clients nor the central host. We tackle the a challenging and yet realistic scenario where each client is a mobile device containing face images pertaining to only the owner of the device (one identity per client). Conventional FL algorithms such as FedAvg are not suitable for this setting because they lead to a trivial solution where all the face features collapse into a single point in the embedding space. Our experiments show that FedFace can utilize face images available on 1,000 mobile devices to enhance the performance of a pre-trained face recognition model, CosFace, from a TAR of 81.43% to 83.79% on IJB-A (@ 0.1% FAR). For LFW, the recognition accuracy under the LFW protocol is increased from 99.15% to 99.28%. FedFace is able to do this while ensuring that the face images are never shared between devices or between the device and the server. Our code and pre-trained models will be publicly available.
Unified Detection of Digital and Physical Face Attacks
Apr 05, 2021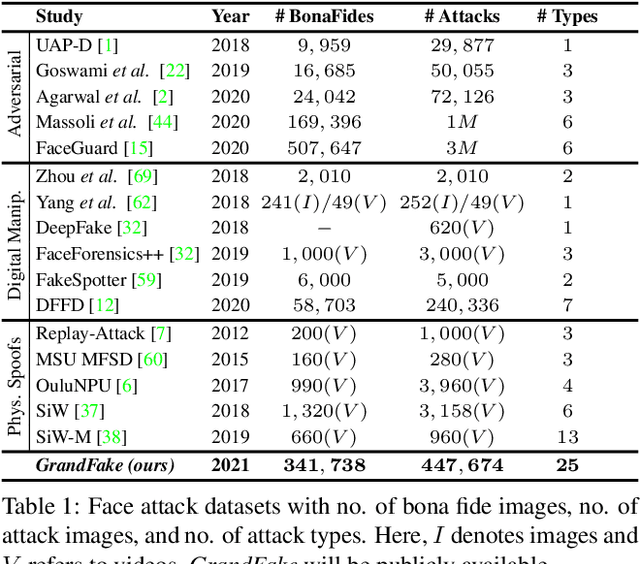
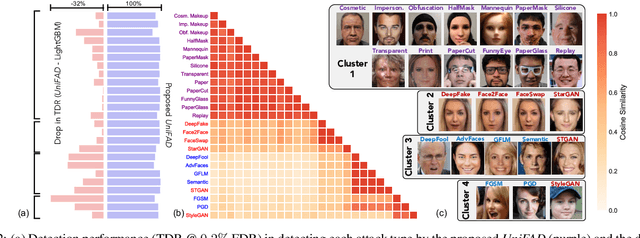
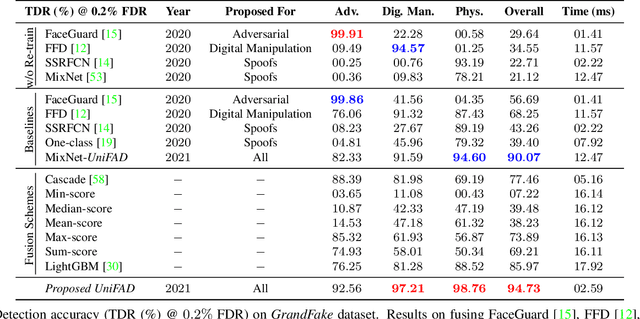
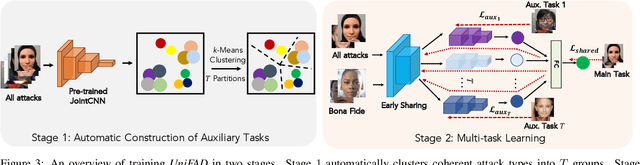
State-of-the-art defense mechanisms against face attacks achieve near perfect accuracies within one of three attack categories, namely adversarial, digital manipulation, or physical spoofs, however, they fail to generalize well when tested across all three categories. Poor generalization can be attributed to learning incoherent attacks jointly. To overcome this shortcoming, we propose a unified attack detection framework, namely UniFAD, that can automatically cluster 25 coherent attack types belonging to the three categories. Using a multi-task learning framework along with k-means clustering, UniFAD learns joint representations for coherent attacks, while uncorrelated attack types are learned separately. Proposed UniFAD outperforms prevailing defense methods and their fusion with an overall TDR = 94.73% @ 0.2% FDR on a large fake face dataset consisting of 341K bona fide images and 448K attack images of 25 types across all 3 categories. Proposed method can detect an attack within 3 milliseconds on a Nvidia 2080Ti. UniFAD can also identify the attack types and categories with 75.81% and 97.37% accuracies, respectively.
FaceGuard: A Self-Supervised Defense Against Adversarial Face Images
Nov 28, 2020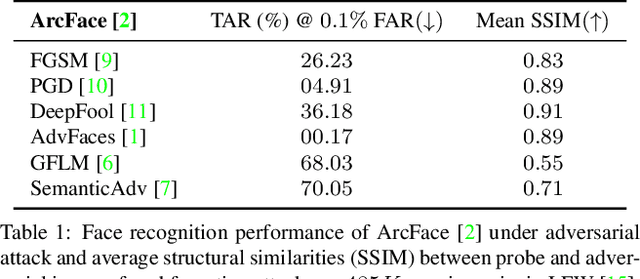

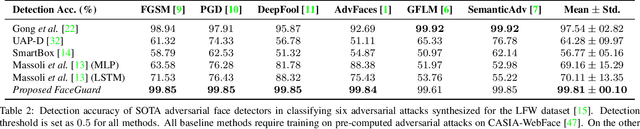
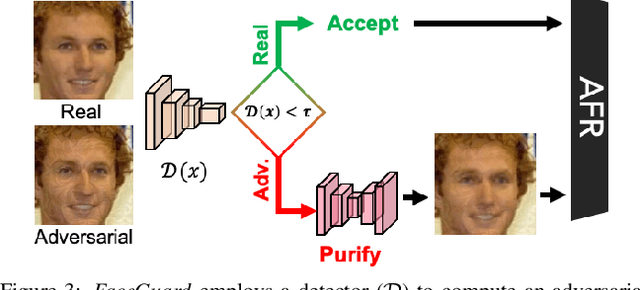
Prevailing defense mechanisms against adversarial face images tend to overfit to the adversarial perturbations in the training set and fail to generalize to unseen adversarial attacks. We propose a new self-supervised adversarial defense framework, namely FaceGuard, that can automatically detect, localize, and purify a wide variety of adversarial faces without utilizing pre-computed adversarial training samples. During training, FaceGuard automatically synthesizes challenging and diverse adversarial attacks, enabling a classifier to learn to distinguish them from real faces and a purifier attempts to remove the adversarial perturbations in the image space. Experimental results on LFW dataset show that FaceGuard can achieve 99.81% detection accuracy on six unseen adversarial attack types. In addition, the proposed method can enhance the face recognition performance of ArcFace from 34.27% TAR @ 0.1% FAR under no defense to 77.46% TAR @ 0.1% FAR.