 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEGASUS: A Policy Search Method for Large MDPs and POMDPs
Jan 16, 2013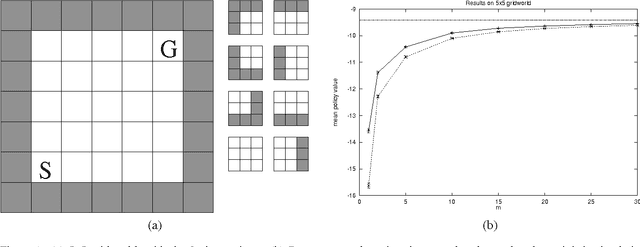
We propose a new approach to the problem of searching a space of policies for a Markov decision process (MDP) or a partially observable Markov decision process (POMDP), given a model. Our approach is based on the following observation: Any (PO)MDP can be transformed into an "equivalent" POMDP in which all state transitions (given the current state and action) are deterministic. This reduces the general problem of policy search to one in which we need only consider POMDPs with deterministic transitions. We give a natural way of estimating the value of all policies in these transformed POMDPs. Policy search is then simply performed by searching for a policy with high estimated value. We also establish conditions under which our value estimates will be good, recovering theoretical results similar to those of Kearns, Mansour and Ng (1999), but with "sample complexity" bounds that have only a polynomial rather than exponential dependence on the horizon time. Our method applies to arbitrary POMDPs, including ones with infinite state and action spaces. We also present empirical results for our approach on a small discrete problem, and on a complex continuous state/continuous action problem involving learning to ride a bicycle.
Building high-level features using large scale unsupervised learning
Jul 12, 2012

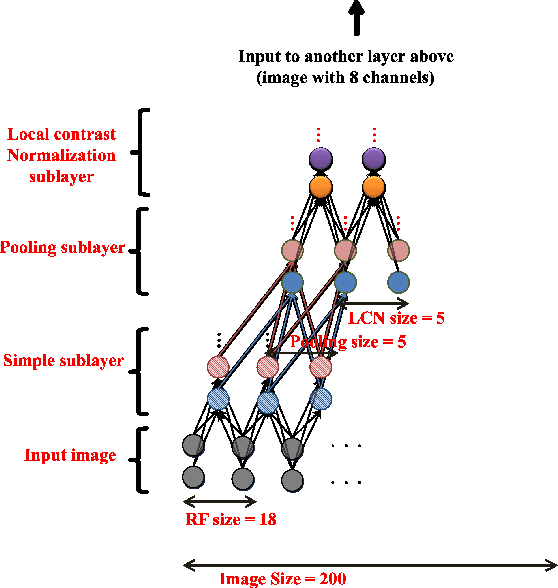
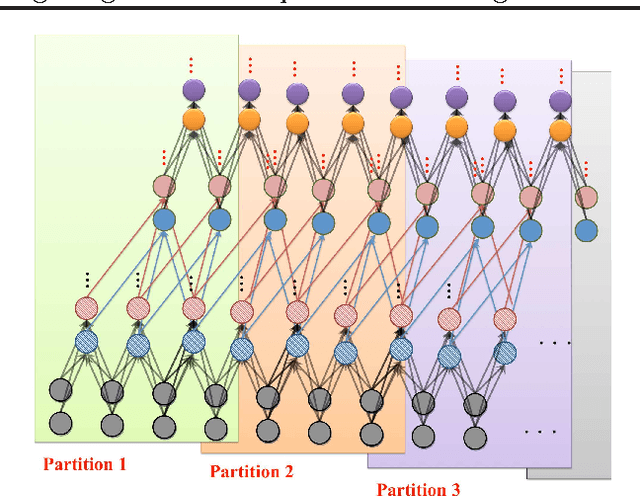
We consider the problem of building high-level, class-specific feature detectors from only unlabeled data. For example, is it possible to learn a face detector using only unlabeled images? To answer this, we train a 9-layered locally connected sparse autoencoder with pooling and local contrast normalization on a large dataset of images (the model has 1 billion connections, the dataset has 10 million 200x200 pixel images downloaded from the Internet). We train this network using model parallelism and asynchronous SGD on a cluster with 1,000 machines (16,000 cores) for three days. Contrary to what appears to be a widely-held intuition, our experimental results reveal that it is possible to train a face detector without having to label images as containing a face or not. Control experiments show that this feature detector is robust not only to translation but also to scaling and out-of-plane rotation. We also find that the same network is sensitive to other high-level concepts such as cat faces and human bodies. Starting with these learned features, we trained our network to obtain 15.8% accuracy in recognizing 20,000 object categories from ImageNet, a leap of 70% relative improvement over the previous state-of-the-art.
Learning Factor Graphs in Polynomial Time & Sample Complexity
Jul 04, 2012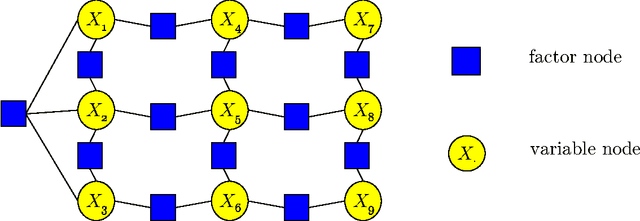



We study computational and sample complexity of parameter and structure learning in graphical models. Our main result shows that the class of factor graphs with bounded factor size and bounded connectivity can be learned in polynomial time and polynomial number of samples, assuming that the data is generated by a network in this class. This result covers both parameter estimation for a known network structure and structure learning. It implies as a corollary that we can learn factor graphs for both Bayesian networks and Markov networks of bounded degree, in polynomial time and sample complexity. Unlike maximum likelihood estimation, our method does not require inference in the underlying network, and so applies to networks where inference is intractable. We also show that the error of our learned model degrades gracefully when the generating distribution is not a member of the target class of networks.
Shift-Invariance Sparse Coding for Audio Classification
Jun 20, 2012
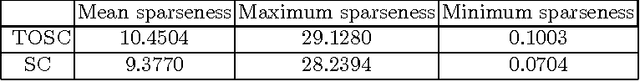


Sparse coding is an unsupervised learning algorithm that learns a succinct high-level representation of the inputs given only unlabeled data; it represents each input as a sparse linear combination of a set of basis functions. Originally applied to modeling the human visual cortex, sparse coding has also been shown to be useful for self-taught learning, in which the goal is to solve a supervised classification task given access to additional unlabeled data drawn from different classes than that in the supervised learning problem. Shift-invariant sparse coding (SISC) is an extension of sparse coding which reconstructs a (usually time-series) input using all of the basis functions in all possible shifts. In this paper, we present an efficient algorithm for learning SISC bases. Our method is based on iteratively solving two large convex optimization problems: The first, which computes the linear coefficients, is an L1-regularized linear least squares problem with potentially hundreds of thousands of variables. Existing methods typically use a heuristic to select a small subset of the variables to optimize, but we present a way to efficiently compute the exact solution. The second, which solves for bases, is a constrained linear least squares problem. By optimizing over complex-valued variables in the Fourier domain, we reduce the coupling between the different variables, allowing the problem to be solved efficiently. We show that SISC's learned high-level representations of speech and music provide useful features for classification tasks within those domains. When applied to classification, under certain conditions the learned features outperform state of the art spectral and cepstral features.