 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Materials Science Procedural Text Corpus: Annotating Materials Synthesis Procedures with Shallow Semantic Structures
May 16, 2019
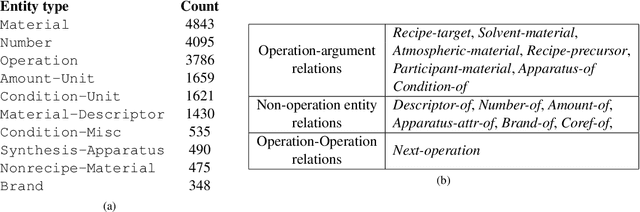
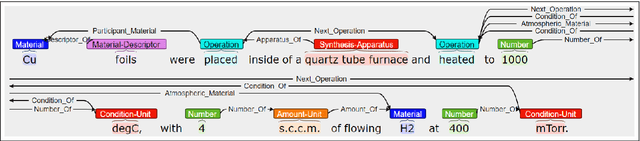

Materials science literature contains millions of materials synthesis procedures described in unstructured natural language text. Large-scale analysis of these synthesis procedures would facilitate deeper scientific understanding of materials synthesis and enable automated synthesis planning. Such analysis requires extracting structured representations of synthesis procedures from the raw text as a first step. To facilitate the training and evaluation of synthesis extraction models, we introduce a dataset of 230 synthesis procedures annotated by domain experts with labeled graphs that express the semantics of the synthesis sentences. The nodes in this graph are synthesis operations and their typed arguments, and labeled edges specify relations between the nodes. We describe this new resource in detail and highlight some specific challenges to annotating scientific text with shallow semantic structure. We make the corpus available to the community to promote further research and development of scientific information extraction systems.
Multi-step Retriever-Reader Interaction for Scalable Open-domain Question Answering
May 14, 2019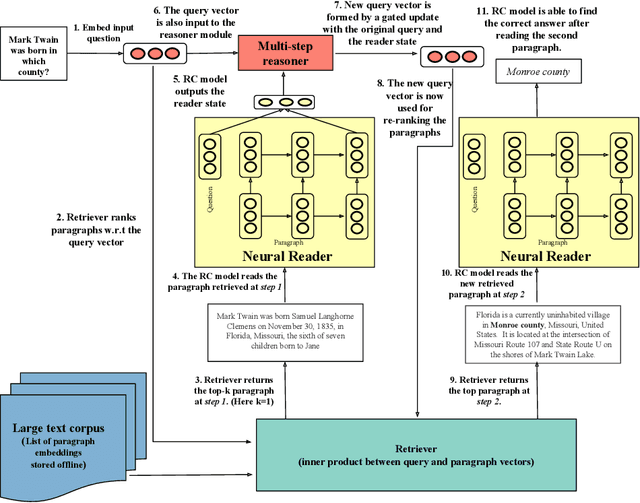
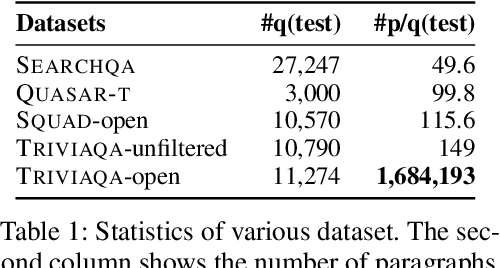
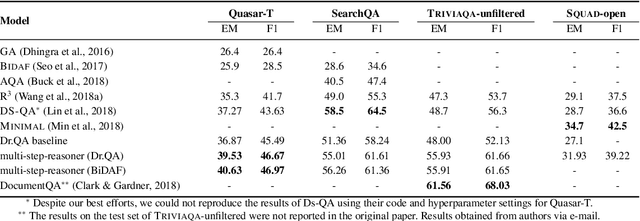
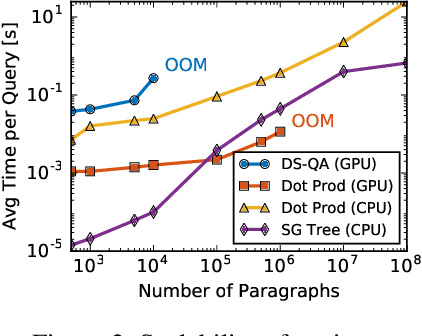
This paper introduces a new framework for open-domain question answering in which the retriever and the reader iteratively interact with each other. The framework is agnostic to the architecture of the machine reading model, only requiring access to the token-level hidden representations of the reader. The retriever uses fast nearest neighbor search to scale to corpora containing millions of paragraphs. A gated recurrent unit updates the query at each step conditioned on the state of the reader and the reformulated query is used to re-rank the paragraphs by the retriever. We conduct analysis and show that iterative interaction helps in retrieving informative paragraphs from the corpus. Finally, we show that our multi-step-reasoning framework brings consistent improvement when applied to two widely used reader architectures DrQA and BiDAF on various large open-domain datasets --- TriviaQA-unfiltered, QuasarT, SearchQA, and SQuAD-Open.
OpenKI: Integrating Open Information Extraction and Knowledge Bases with Relation Inference
Apr 12, 2019
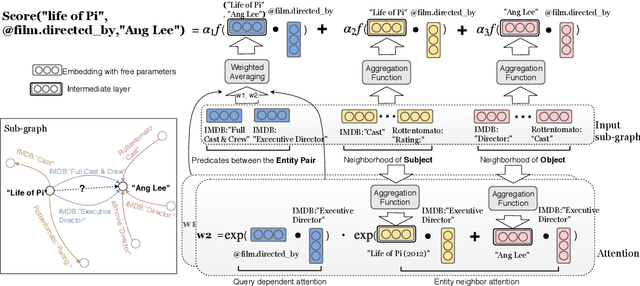
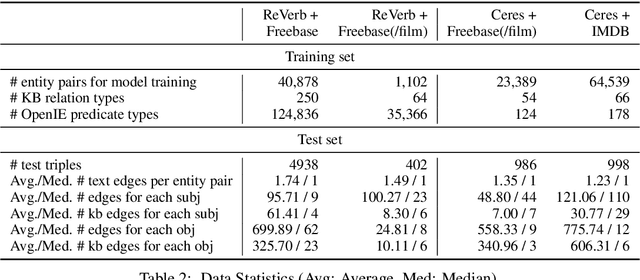
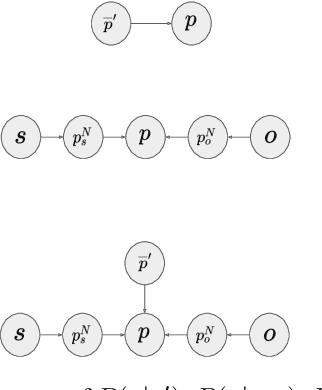
In this paper, we consider advancing web-scale knowledge extraction and alignment by integrating OpenIE extractions in the form of (subject, predicate, object) triples with Knowledge Bases (KB). Traditional techniques from universal schema and from schema mapping fall in two extremes: either they perform instance-level inference relying on embedding for (subject, object) pairs, thus cannot handle pairs absent in any existing triples; or they perform predicate-level mapping and completely ignore background evidence from individual entities, thus cannot achieve satisfying quality. We propose OpenKI to handle sparsity of OpenIE extractions by performing instance-level inference: for each entity, we encode the rich information in its neighborhood in both KB and OpenIE extractions, and leverage this information in relation inference by exploring different methods of aggregation and attention. In order to handle unseen entities, our model is designed without creating entity-specific parameters. Extensive experiments show that this method not only significantly improves state-of-the-art for conventional OpenIE extractions like ReVerb, but also boosts the performance on OpenIE from semi-structured data, where new entity pairs are abundant and data are fairly sparse.
Unsupervised Latent Tree Induction with Deep Inside-Outside Recursive Autoencoders
Apr 04, 2019
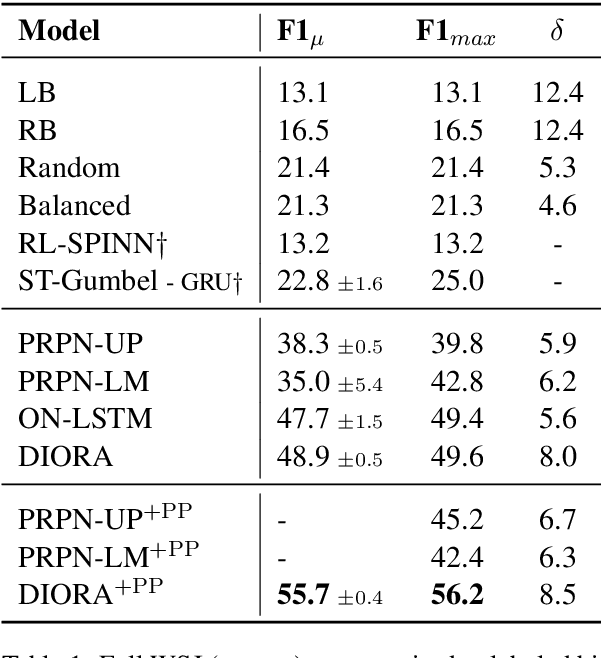
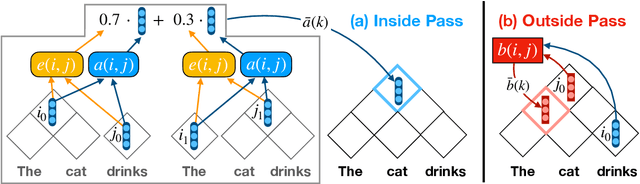
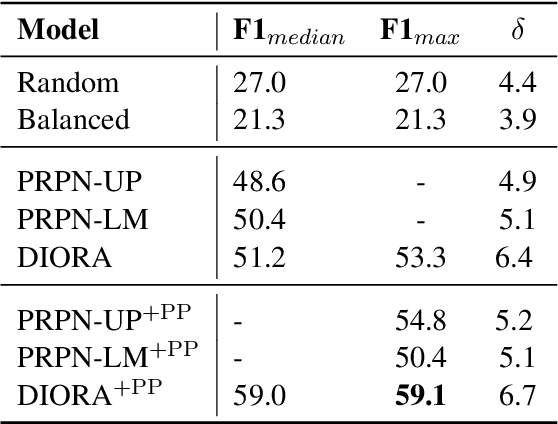
We introduce deep inside-outside recursive autoencoders (DIORA), a fully-unsupervised method for discovering syntax that simultaneously learns representations for constituents within the induced tree. Our approach predicts each word in an input sentence conditioned on the rest of the sentence and uses inside-outside dynamic programming to consider all possible binary trees over the sentence. At test time the CKY algorithm extracts the highest scoring parse. DIORA achieves a new state-of-the-art F1 in unsupervised binary constituency parsing (unlabeled) in two benchmark datasets, WSJ and MultiNLI.
Inorganic Materials Synthesis Planning with Literature-Trained Neural Networks
Dec 31, 2018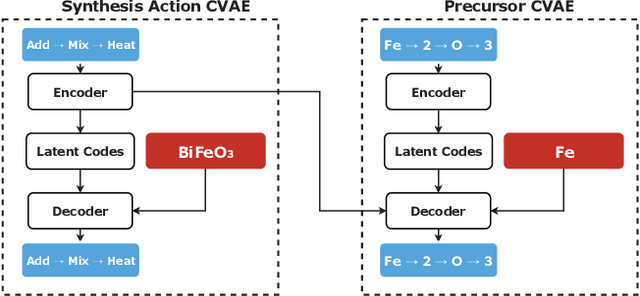
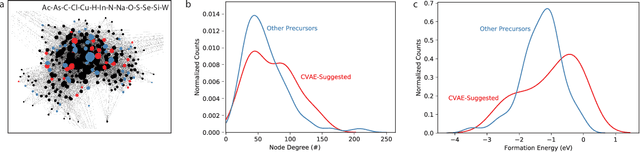
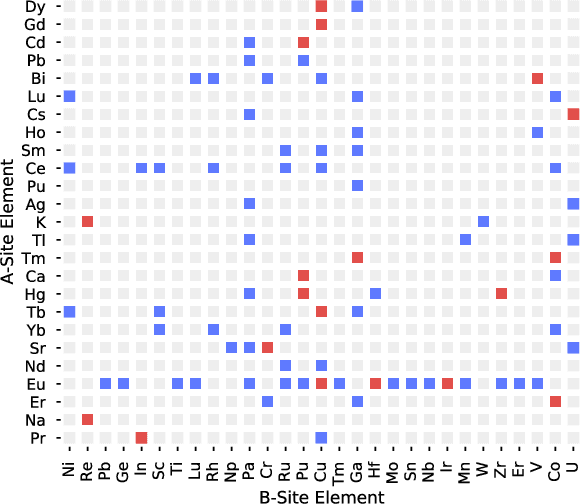

Leveraging new data sources is a key step in accelerating the pace of materials design and discovery. To complement the strides in synthesis planning driven by historical, experimental, and computed data, we present an automated method for connecting scientific literature to synthesis insights. Starting from natural language text, we apply word embeddings from language models, which are fed into a named entity recognition model, upon which a conditional variational autoencoder is trained to generate syntheses for arbitrary materials. We show the potential of this technique by predicting precursors for two perovskite materials, using only training data published over a decade prior to their first reported syntheses. We demonstrate that the model learns representations of materials corresponding to synthesis-related properties, and that the model's behavior complements existing thermodynamic knowledge. Finally, we apply the model to perform synthesizability screening for proposed novel perovskite compounds.
Search-Guided, Lightly-supervised Training of Structured Prediction Energy Networks
Dec 22, 2018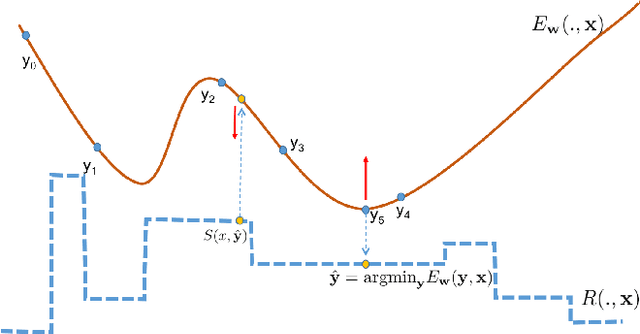
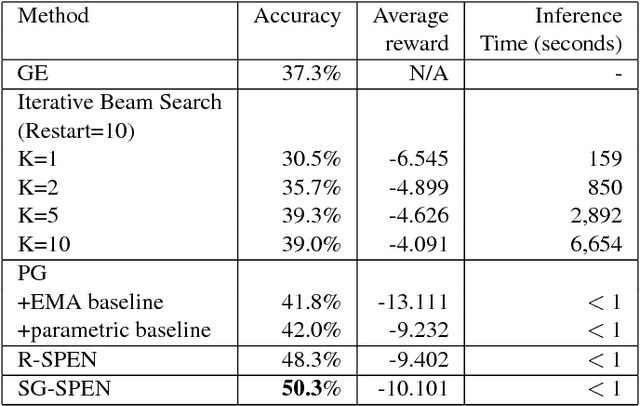
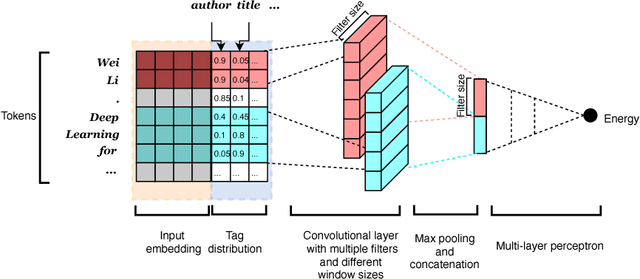

In structured output prediction tasks, labeling ground-truth training output is often expensive. However, for many tasks, even when the true output is unknown, we can evaluate predictions using a scalar reward function, which may be easily assembled from human knowledge or non-differentiable pipelines. But searching through the entire output space to find the best output with respect to this reward function is typically intractable. In this paper, we instead use efficient truncated randomized search in this reward function to train structured prediction energy networks (SPENs), which provide efficient test-time inference using gradient-based search on a smooth, learned representation of the score landscape, and have previously yielded state-of-the-art results in structured prediction. In particular, this truncated randomized search in the reward function yields previously unknown local improvements, providing effective supervision to SPENs, avoiding their traditional need for labeled training data.
Syntax Helps ELMo Understand Semantics: Is Syntax Still Relevant in a Deep Neural Architecture for SRL?
Nov 12, 2018
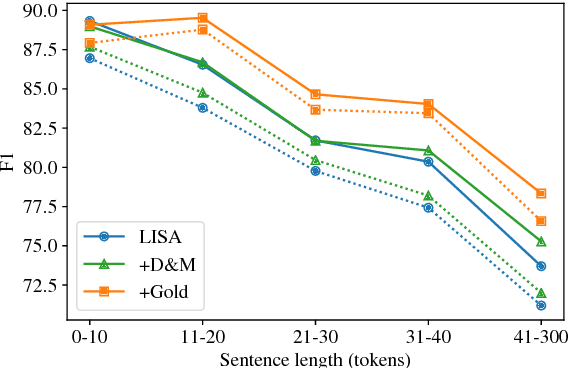
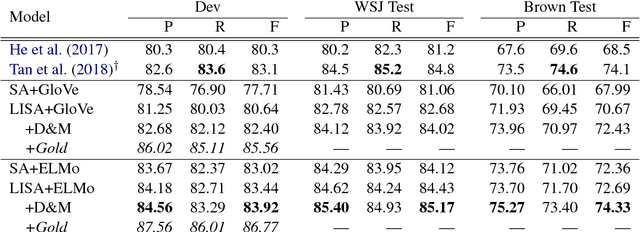
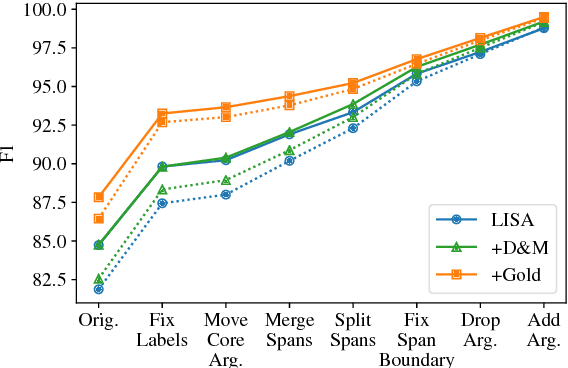
Do unsupervised methods for learning rich, contextualized token representations obviate the need for explicit modeling of linguistic structure in neural network models for semantic role labeling (SRL)? We address this question by incorporating the massively successful ELMo embeddings (Peters et al., 2018) into LISA (Strubell et al., 2018), a strong, linguistically-informed neural network architecture for SRL. In experiments on the CoNLL-2005 shared task we find that though ELMo out-performs typical word embeddings, beginning to close the gap in F1 between LISA with predicted and gold syntactic parses, syntactically-informed models still out-perform syntax-free models when both use ELMo, especially on out-of-domain data. Our results suggest that linguistic structures are indeed still relevant in this golden age of deep learning for NLP.
Building Dynamic Knowledge Graphs from Text using Machine Reading Comprehension
Oct 12, 2018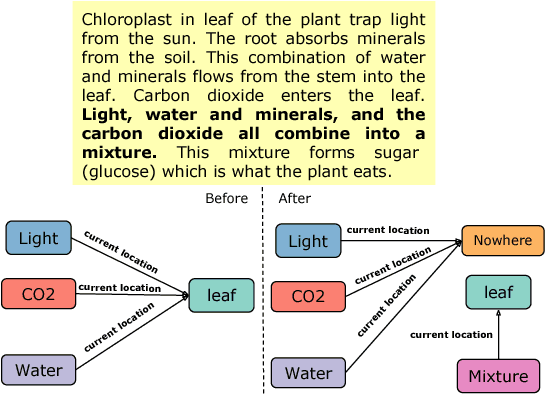

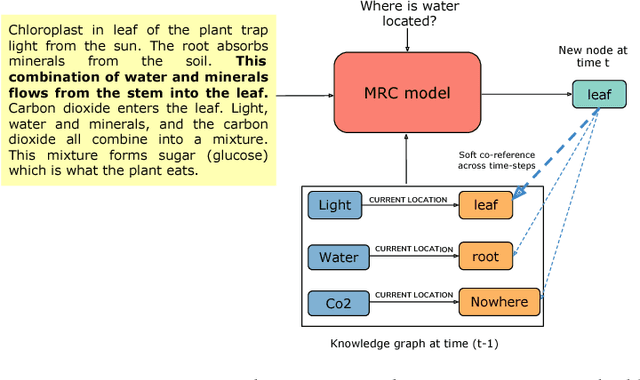
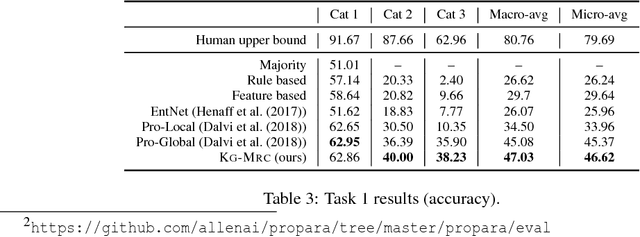
We propose a neural machine-reading model that constructs dynamic knowledge graphs from procedural text. It builds these graphs recurrently for each step of the described procedure, and uses them to track the evolving states of participant entities. We harness and extend a recently proposed machine reading comprehension (MRC) model to query for entity states, since these states are generally communicated in spans of text and MRC models perform well in extracting entity-centric spans. The explicit, structured, and evolving knowledge graph representations that our model constructs can be used in downstream question answering tasks to improve machine comprehension of text, as we demonstrate empirically. On two comprehension tasks from the recently proposed PROPARA dataset (Dalvi et al., 2018), our model achieves state-of-the-art results. We further show that our model is competitive on the RECIPES dataset (Kiddon et al., 2015), suggesting it may be generally applicable. We present some evidence that the model's knowledge graphs help it to impose commonsense constraints on its predictions.
Embedded-State Latent Conditional Random Fields for Sequence Labeling
Sep 28, 2018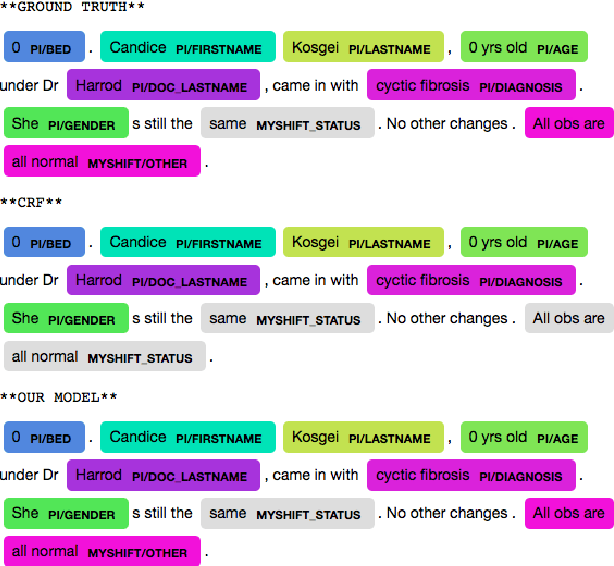
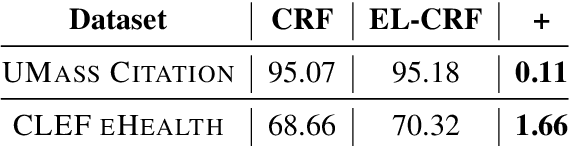
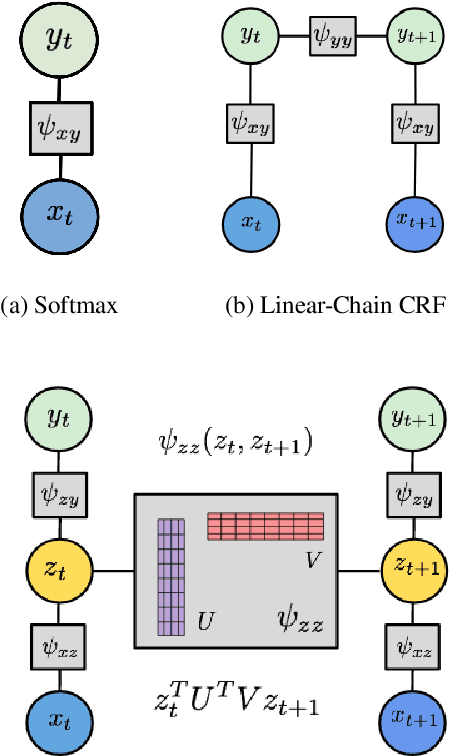
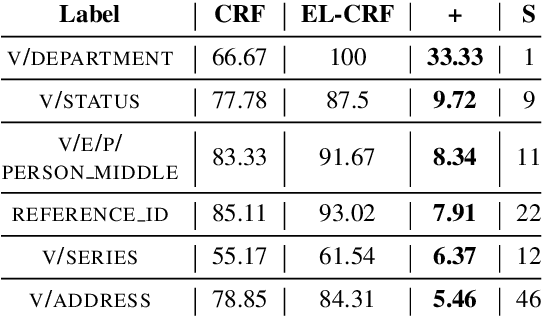
Complex textual information extraction tasks are often posed as sequence labeling or \emph{shallow parsing}, where fields are extracted using local labels made consistent through probabilistic inference in a graphical model with constrained transitions. Recently, it has become common to locally parametrize these models using rich features extracted by recurrent neural networks (such as LSTM), while enforcing consistent outputs through a simple linear-chain model, representing Markovian dependencies between successive labels. However, the simple graphical model structure belies the often complex non-local constraints between output labels. For example, many fields, such as a first name, can only occur a fixed number of times, or in the presence of other fields. While RNNs have provided increasingly powerful context-aware local features for sequence tagging, they have yet to be integrated with a global graphical model of similar expressivity in the output distribution. Our model goes beyond the linear chain CRF to incorporate multiple hidden states per output label, but parametrizes their transitions parsimoniously with low-rank log-potential scoring matrices, effectively learning an embedding space for hidden states. This augmented latent space of inference variables complements the rich feature representation of the RNN, and allows exact global inference obeying complex, learned non-local output constraints. We experiment with several datasets and show that the model outperforms baseline CRF+RNN models when global output constraints are necessary at inference-time, and explore the interpretable latent structure.
Linguistically-Informed Self-Attention for Semantic Role Labeling
Aug 28, 2018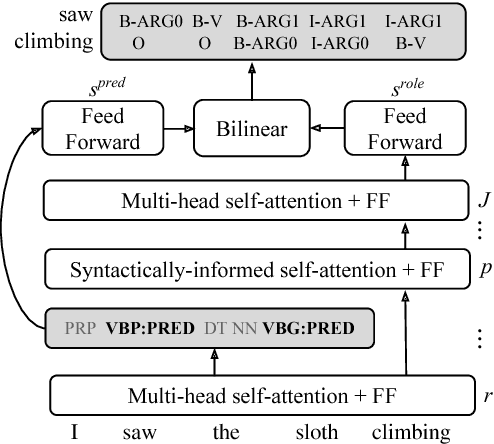
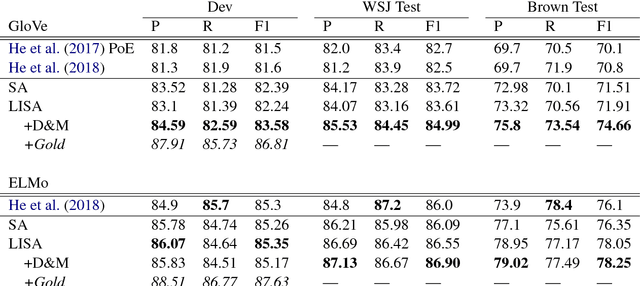
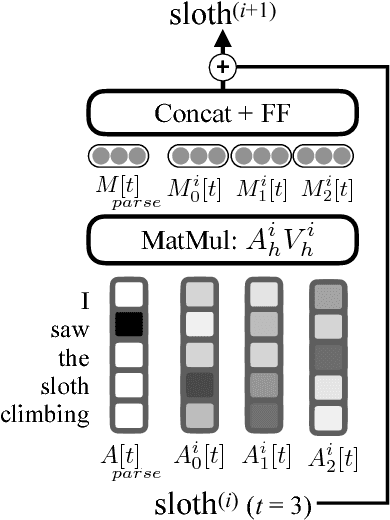
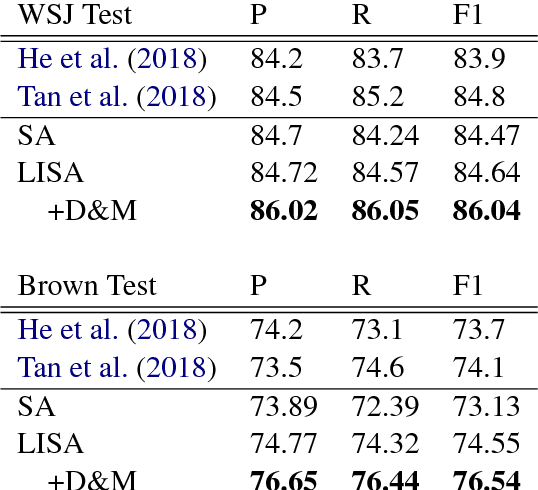
Current state-of-the-art semantic role labeling (SRL) uses a deep neural network with no explicit linguistic features. However, prior work has shown that gold syntax trees can dramatically improve SRL decoding, suggesting the possibility of increased accuracy from explicit modeling of syntax. In this work, we present linguistically-informed self-attention (LISA): a neural network model that combines multi-head self-attention with multi-task learning across dependency parsing, part-of-speech tagging, predicate detection and SRL. Unlike previous models which require significant pre-processing to prepare linguistic features, LISA can incorporate syntax using merely raw tokens as input, encoding the sequence only once to simultaneously perform parsing, predicate detection and role labeling for all predicates. Syntax is incorporated by training one attention head to attend to syntactic parents for each token. Moreover, if a high-quality syntactic parse is already available, it can be beneficially injected at test time without re-training our SRL model. In experiments on CoNLL-2005 SRL, LISA achieves new state-of-the-art performance for a model using predicted predicates and standard word embeddings, attaining 2.5 F1 absolute higher than the previous state-of-the-art on newswire and more than 3.5 F1 on out-of-domain data, nearly 10% reduction in error. On ConLL-2012 English SRL we also show an improvement of more than 2.5 F1. LISA also out-performs the state-of-the-art with contextually-encoded (ELMo) word representations, by nearly 1.0 F1 on news and more than 2.0 F1 on out-of-domain text.