 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREACT 2026: The Fourth Multiple Appropriate Facial Reaction Generation Challenge: Personalised MAFRG and Appropriate EEG Reaction Prediction
Jun 06, 2026In dyadic interactions, various human facial reactions could be appropriate for responding to each human speaker behaviour. Following the successful organisation of the REACT 2023, 2024 and 2025 challenge series, a body of generative deep learning (DL) models have been developed for the problem of multiple appropriate facial reaction generation (MAFRG). This year, we propose the REACT 2026 challenge encouraging the development and benchmarking of Machine Learning (ML) models that can generate multiple personalised, appropriate, diverse, realistic and synchronised human-style facial reactions expressed by a specific human listener for responding to each given speaker behaviour. As a key of the challenge, we continuously provide challenge participants with MARS dataset introduced by REACT 2025 but additionally provide individual-level Big-Five personality labels and EEG recordings. This introduces a new one-to-many personalised facial reaction generation setting combining human expressive behavioural, affective and neurophysiological signals, which remains largely unexplored in current dyadic interaction modelling. This paper also presents the challenge guidelines and new baselines on the four proposed sub-challenges: Offline generic and personalised MAFRG as well as Online generic and personalised MAFRG, respectively, which are publicly available at https://github.com/reactmultimodalchallenge/baseline_react2026.
REACT 2025: the Third Multiple Appropriate Facial Reaction Generation Challenge
May 22, 2025



In dyadic interactions, a broad spectrum of human facial reactions might be appropriate for responding to each human speaker behaviour. Following the successful organisation of the REACT 2023 and REACT 2024 challenges, we are proposing the REACT 2025 challenge encouraging the development and benchmarking of Machine Learning (ML) models that can be used to generate multiple appropriate, diverse, realistic and synchronised human-style facial reactions expressed by human listeners in response to an input stimulus (i.e., audio-visual behaviours expressed by their corresponding speakers). As a key of the challenge, we provide challenge participants with the first natural and large-scale multi-modal MAFRG dataset (called MARS) recording 137 human-human dyadic interactions containing a total of 2856 interaction sessions covering five different topics. In addition, this paper also presents the challenge guidelines and the performance of our baselines on the two proposed sub-challenges: Offline MAFRG and Online MAFRG, respectively. The challenge baseline code is publicly available at https://github.com/reactmultimodalchallenge/baseline_react2025
MultiTaskVIF: Segmentation-oriented visible and infrared image fusion via multi-task learning
May 10, 2025Visible and infrared image fusion (VIF) has attracted significant attention in recent years. Traditional VIF methods primarily focus on generating fused images with high visual quality, while recent advancements increasingly emphasize incorporating semantic information into the fusion model during training. However, most existing segmentation-oriented VIF methods adopt a cascade structure comprising separate fusion and segmentation models, leading to increased network complexity and redundancy. This raises a critical question: can we design a more concise and efficient structure to integrate semantic information directly into the fusion model during training-Inspired by multi-task learning, we propose a concise and universal training framework, MultiTaskVIF, for segmentation-oriented VIF models. In this framework, we introduce a multi-task head decoder (MTH) to simultaneously output both the fused image and the segmentation result during training. Unlike previous cascade training frameworks that necessitate joint training with a complete segmentation model, MultiTaskVIF enables the fusion model to learn semantic features by simply replacing its decoder with MTH. Extensive experimental evaluations validate the effectiveness of the proposed method. Our code will be released upon acceptance.
Environment Complexity and Nash Equilibria in a Sequential Social Dilemma
Aug 04, 2024Multi-agent reinforcement learning (MARL) methods, while effective in zero-sum or positive-sum games, often yield suboptimal outcomes in general-sum games where cooperation is essential for achieving globally optimal outcomes. Matrix game social dilemmas, which abstract key aspects of general-sum interactions, such as cooperation, risk, and trust, fail to model the temporal and spatial dynamics characteristic of real-world scenarios. In response, our study extends matrix game social dilemmas into more complex, higher-dimensional MARL environments. We adapt a gridworld implementation of the Stag Hunt dilemma to more closely match the decision-space of a one-shot matrix game while also introducing variable environment complexity. Our findings indicate that as complexity increases, MARL agents trained in these environments converge to suboptimal strategies, consistent with the risk-dominant Nash equilibria strategies found in matrix games. Our work highlights the impact of environment complexity on achieving optimal outcomes in higher-dimensional game-theoretic MARL environments.
Amortised Experimental Design and Parameter Estimation for User Models of Pointing
Jul 19, 2023



User models play an important role in interaction design, supporting automation of interaction design choices. In order to do so, model parameters must be estimated from user data. While very large amounts of user data are sometimes required, recent research has shown how experiments can be designed so as to gather data and infer parameters as efficiently as possible, thereby minimising the data requirement. In the current article, we investigate a variant of these methods that amortises the computational cost of designing experiments by training a policy for choosing experimental designs with simulated participants. Our solution learns which experiments provide the most useful data for parameter estimation by interacting with in-silico agents sampled from the model space thereby using synthetic data rather than vast amounts of human data. The approach is demonstrated for three progressively complex models of pointing.
Amortised Design Optimization for Item Response Theory
Jul 19, 2023Item Response Theory (IRT) is a well known method for assessing responses from humans in education and psychology. In education, IRT is used to infer student abilities and characteristics of test items from student responses. Interactions with students are expensive, calling for methods that efficiently gather information for inferring student abilities. Methods based on Optimal Experimental Design (OED) are computationally costly, making them inapplicable for interactive applications. In response, we propose incorporating amortised experimental design into IRT. Here, the computational cost is shifted to a precomputing phase by training a Deep Reinforcement Learning (DRL) agent with synthetic data. The agent is trained to select optimally informative test items for the distribution of students, and to conduct amortised inference conditioned on the experiment outcomes. During deployment the agent estimates parameters from data, and suggests the next test item for the student, in close to real-time, by taking into account the history of experiments and outcomes.
Online simulator-based experimental design for cognitive model selection
Mar 03, 2023The problem of model selection with a limited number of experimental trials has received considerable attention in cognitive science, where the role of experiments is to discriminate between theories expressed as computational models. Research on this subject has mostly been restricted to optimal experiment design with analytically tractable models. However, cognitive models of increasing complexity, with intractable likelihoods, are becoming more commonplace. In this paper, we propose BOSMOS: an approach to experimental design that can select between computational models without tractable likelihoods. It does so in a data-efficient manner, by sequentially and adaptively generating informative experiments. In contrast to previous approaches, we introduce a novel simulator-based utility objective for design selection, and a new approximation of the model likelihood for model selection. In simulated experiments, we demonstrate that the proposed BOSMOS technique can accurately select models in up to 2 orders of magnitude less time than existing LFI alternatives for three cognitive science tasks: memory retention, sequential signal detection and risky choice.
Rediscovering Affordance: A Reinforcement Learning Perspective
Jan 07, 2022

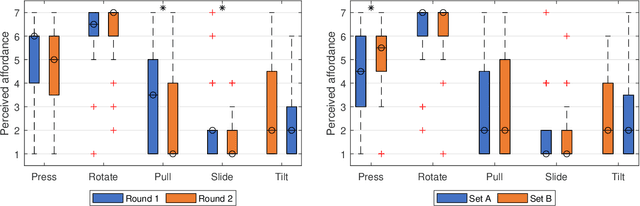
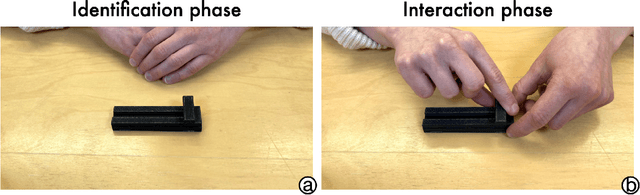
Affordance refers to the perception of possible actions allowed by an object. Despite its relevance to human-computer interaction, no existing theory explains the mechanisms that underpin affordance-formation; that is, how affordances are discovered and adapted via interaction. We propose an integrative theory of affordance-formation based on the theory of reinforcement learning in cognitive sciences. The key assumption is that users learn to associate promising motor actions to percepts via experience when reinforcement signals (success/failure) are present. They also learn to categorize actions (e.g., "rotating" a dial), giving them the ability to name and reason about affordance. Upon encountering novel widgets, their ability to generalize these actions determines their ability to perceive affordances. We implement this theory in a virtual robot model, which demonstrates human-like adaptation of affordance in interactive widgets tasks. While its predictions align with trends in human data, humans are able to adapt affordances faster, suggesting the existence of additional mechanisms.
Likelihood-Free Inference in State-Space Models with Unknown Dynamics
Nov 02, 2021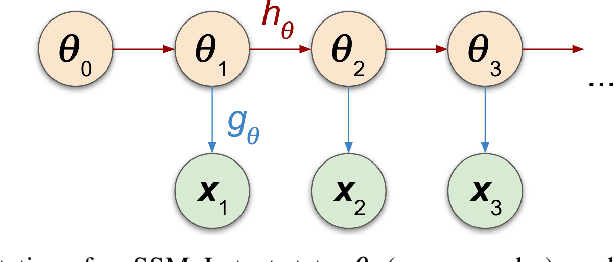
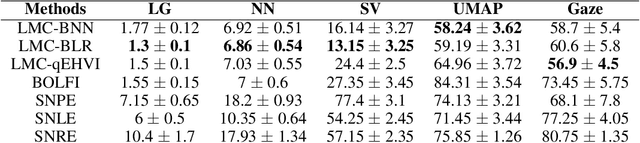
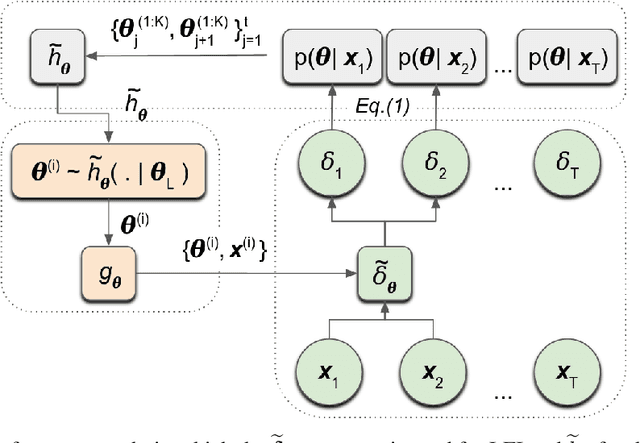
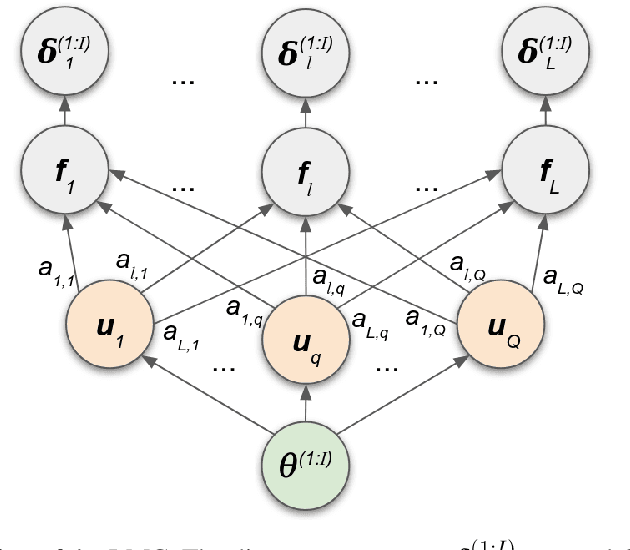
We introduce a method for inferring and predicting latent states in the important and difficult case of state-space models where observations can only be simulated, and transition dynamics are unknown. In this setting, the likelihood of observations is not available and only synthetic observations can be generated from a black-box simulator. We propose a way of doing likelihood-free inference (LFI) of states and state prediction with a limited number of simulations. Our approach uses a multi-output Gaussian process for state inference, and a Bayesian Neural Network as a model of the transition dynamics for state prediction. We improve upon existing LFI methods for the inference task, while also accurately learning transition dynamics. The proposed method is necessary for modelling inverse problems in dynamical systems with computationally expensive simulations, as demonstrated in experiments with non-stationary user models.
Implications of Human Irrationality for Reinforcement Learning
Jun 07, 2020
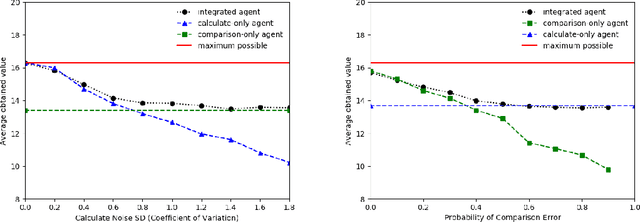

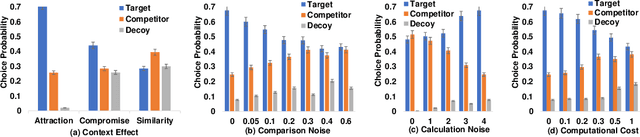
Recent work in the behavioural sciences has begun to overturn the long-held belief that human decision making is irrational, suboptimal and subject to biases. This turn to the rational suggests that human decision making may be a better source of ideas for constraining how machine learning problems are defined than would otherwise be the case. One promising idea concerns human decision making that is dependent on apparently irrelevant aspects of the choice context. Previous work has shown that by taking into account choice context and making relational observations, people can maximize expected value. Other work has shown that Partially observable Markov decision processes (POMDPs) are a useful way to formulate human-like decision problems. Here, we propose a novel POMDP model for contextual choice tasks and show that, despite the apparent irrationalities, a reinforcement learner can take advantage of the way that humans make decisions. We suggest that human irrationalities may offer a productive source of inspiration for improving the design of AI architectures and machine learning methods.