 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep compositional robotic planners that follow natural language commands
Feb 19, 2020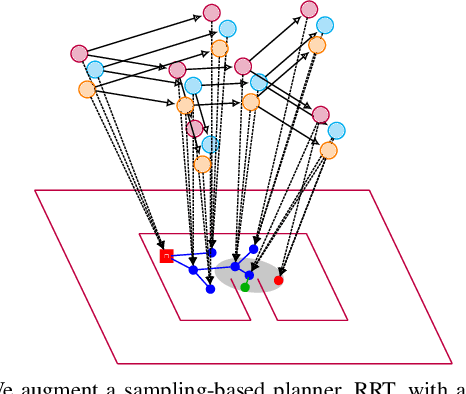
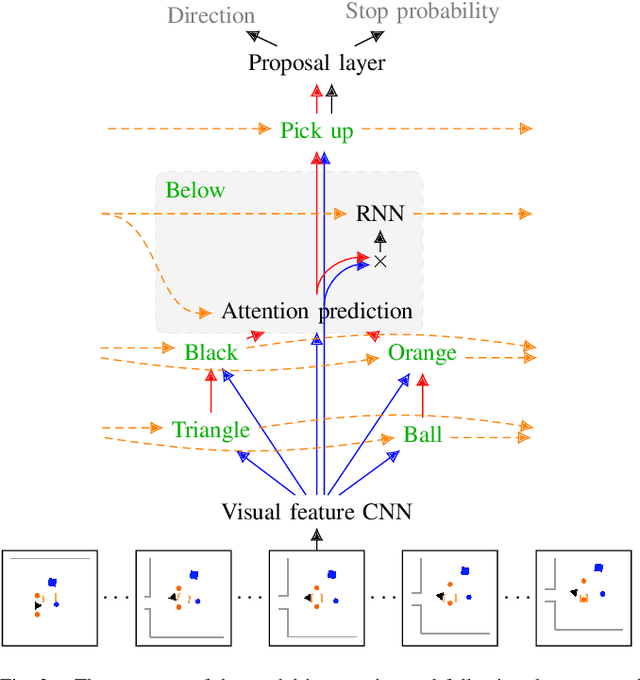


We demonstrate how a sampling-based robotic planner can be augmented to learn to understand a sequence of natural language commands in a continuous configuration space to move and manipulate objects. Our approach combines a deep network structured according to the parse of a complex command that includes objects, verbs, spatial relations, and attributes, with a sampling-based planner, RRT. A recurrent hierarchical deep network controls how the planner explores the environment, determines when a planned path is likely to achieve a goal, and estimates the confidence of each move to trade off exploitation and exploration between the network and the planner. Planners are designed to have near-optimal behavior when information about the task is missing, while networks learn to exploit observations which are available from the environment, making the two naturally complementary. Combining the two enables generalization to new maps, new kinds of obstacles, and more complex sentences that do not occur in the training set. Little data is required to train the model despite it jointly acquiring a CNN that extracts features from the environment as it learns the meanings of words. The model provides a level of interpretability through the use of attention maps allowing users to see its reasoning steps despite being an end-to-end model. This end-to-end model allows robots to learn to follow natural language commands in challenging continuous environments.
Temporal Grounding Graphs for Language Understanding with Accrued Visual-Linguistic Context
Nov 16, 2018
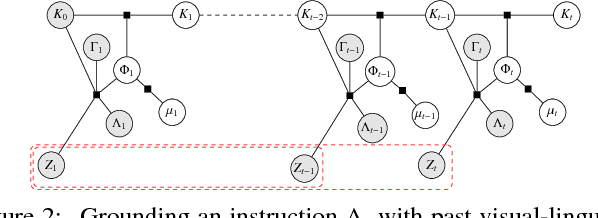

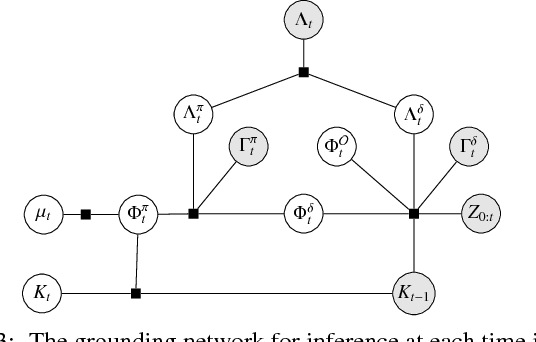
A robot's ability to understand or ground natural language instructions is fundamentally tied to its knowledge about the surrounding world. We present an approach to grounding natural language utterances in the context of factual information gathered through natural-language interactions and past visual observations. A probabilistic model estimates, from a natural language utterance, the objects,relations, and actions that the utterance refers to, the objectives for future robotic actions it implies, and generates a plan to execute those actions while updating a state representation to include newly acquired knowledge from the visual-linguistic context. Grounding a command necessitates a representation for past observations and interactions; however, maintaining the full context consisting of all possible observed objects, attributes, spatial relations, actions, etc., over time is intractable. Instead, our model, Temporal Grounding Graphs, maintains a learned state representation for a belief over factual groundings, those derived from natural-language interactions, and lazily infers new groundings from visual observations using the context implied by the utterance. This work significantly expands the range of language that a robot can understand by incorporating factual knowledge and observations of its workspace in its inference about the meaning and grounding of natural-language utterances.
Deep sequential models for sampling-based planning
Oct 01, 2018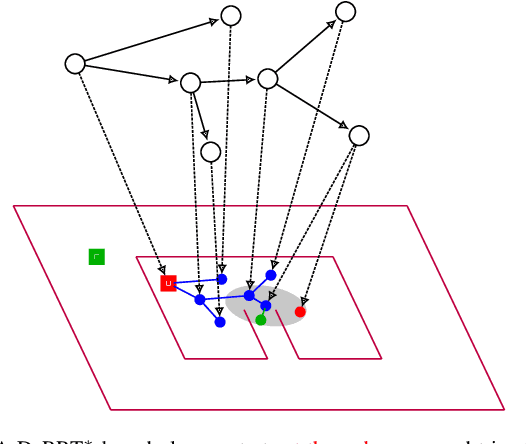

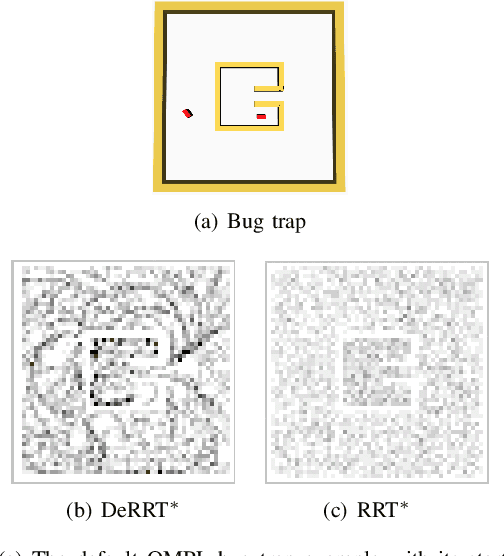
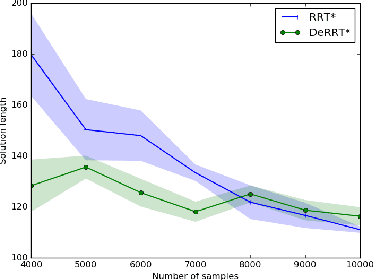
We demonstrate how a sequence model and a sampling-based planner can influence each other to produce efficient plans and how such a model can automatically learn to take advantage of observations of the environment. Sampling-based planners such as RRT generally know nothing of their environments even if they have traversed similar spaces many times. A sequence model, such as an HMM or LSTM, guides the search for good paths. The resulting model, called DeRRT*, observes the state of the planner and the local environment to bias the next move and next planner state. The neural-network-based models avoid manual feature engineering by co-training a convolutional network which processes map features and observations from sensors. We incorporate this sequence model in a manner that combines its likelihood with the existing bias for searching large unexplored Voronoi regions. This leads to more efficient trajectories with fewer rejected samples even in difficult domains such as when escaping bug traps. This model can also be used for dimensionality reduction in multi-agent environments with dynamic obstacles. Instead of planning in a high-dimensional space that includes the configurations of the other agents, we plan in a low-dimensional subspace relying on the sequence model to bias samples using the observed behavior of the other agents. The techniques presented here are general, include both graphical models and deep learning approaches, and can be adapted to a range of planners.
Anchoring and Agreement in Syntactic Annotations
Sep 21, 2016

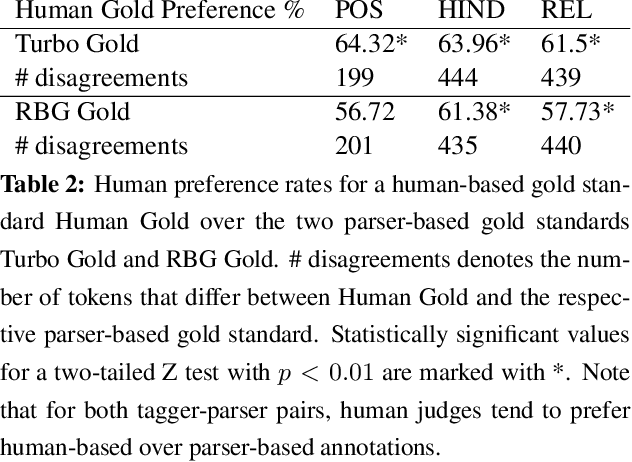
We present a study on two key characteristics of human syntactic annotations: anchoring and agreement. Anchoring is a well known cognitive bias in human decision making, where judgments are drawn towards pre-existing values. We study the influence of anchoring on a standard approach to creation of syntactic resources where syntactic annotations are obtained via human editing of tagger and parser output. Our experiments demonstrate a clear anchoring effect and reveal unwanted consequences, including overestimation of parsing performance and lower quality of annotations in comparison with human-based annotations. Using sentences from the Penn Treebank WSJ, we also report systematically obtained inter-annotator agreement estimates for English dependency parsing. Our agreement results control for parser bias, and are consequential in that they are on par with state of the art parsing performance for English newswire. We discuss the impact of our findings on strategies for future annotation efforts and parser evaluations.
Do You See What I Mean? Visual Resolution of Linguistic Ambiguities
Mar 26, 2016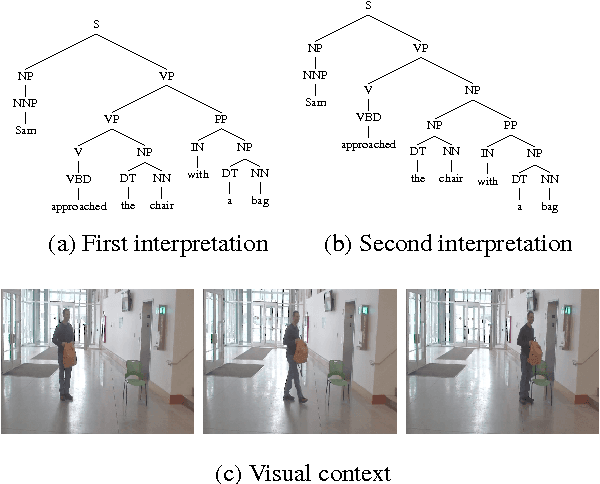
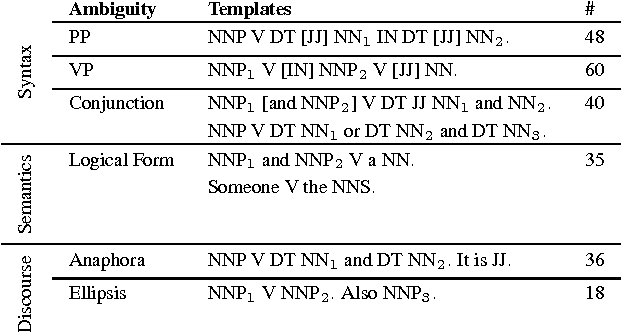
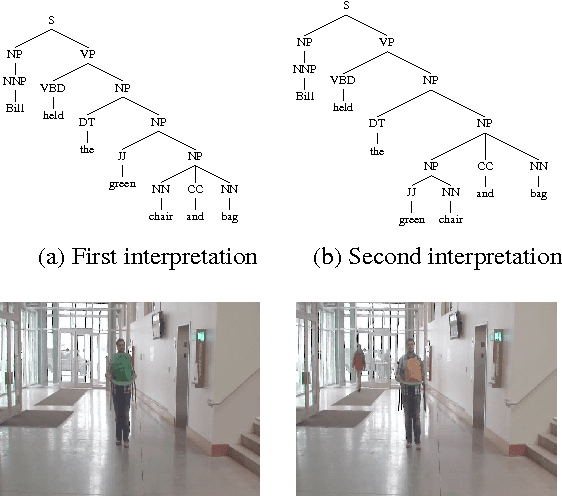

Understanding language goes hand in hand with the ability to integrate complex contextual information obtained via perception. In this work, we present a novel task for grounded language understanding: disambiguating a sentence given a visual scene which depicts one of the possible interpretations of that sentence. To this end, we introduce a new multimodal corpus containing ambiguous sentences, representing a wide range of syntactic, semantic and discourse ambiguities, coupled with videos that visualize the different interpretations for each sentence. We address this task by extending a vision model which determines if a sentence is depicted by a video. We demonstrate how such a model can be adjusted to recognize different interpretations of the same underlying sentence, allowing to disambiguate sentences in a unified fashion across the different ambiguity types.
* EMNLP 2015
Video In Sentences Out
Aug 09, 2014
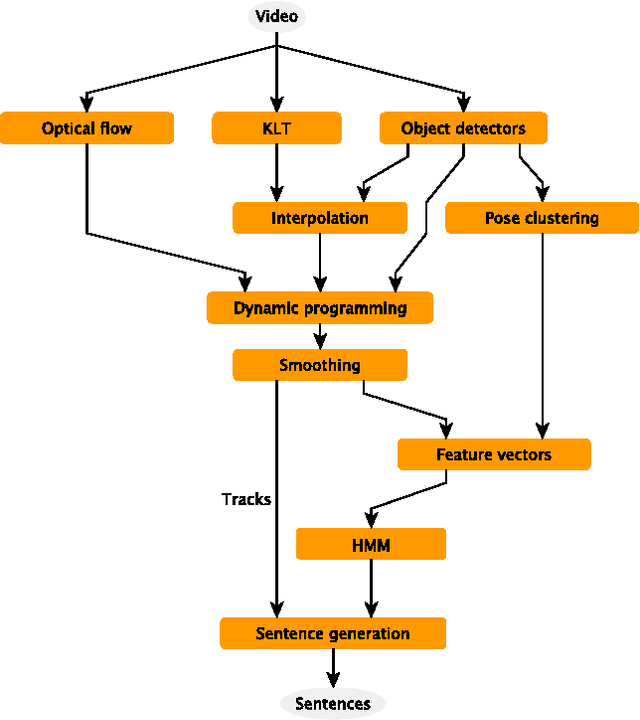


We present a system that produces sentential descriptions of video: who did what to whom, and where and how they did it. Action class is rendered as a verb, participant objects as noun phrases, properties of those objects as adjectival modifiers in those noun phrases, spatial relations between those participants as prepositional phrases, and characteristics of the event as prepositional-phrase adjuncts and adverbial modifiers. Extracting the information needed to render these linguistic entities requires an approach to event recognition that recovers object tracks, the trackto-role assignments, and changing body posture.
Seeing What You're Told: Sentence-Guided Activity Recognition In Video
May 28, 2014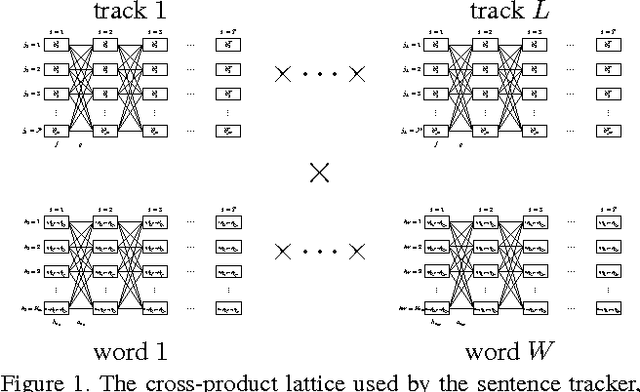



We present a system that demonstrates how the compositional structure of events, in concert with the compositional structure of language, can interplay with the underlying focusing mechanisms in video action recognition, thereby providing a medium, not only for top-down and bottom-up integration, but also for multi-modal integration between vision and language. We show how the roles played by participants (nouns), their characteristics (adjectives), the actions performed (verbs), the manner of such actions (adverbs), and changing spatial relations between participants (prepositions) in the form of whole sentential descriptions mediated by a grammar, guides the activity-recognition process. Further, the utility and expressiveness of our framework is demonstrated by performing three separate tasks in the domain of multi-activity videos: sentence-guided focus of attention, generation of sentential descriptions of video, and query-based video search, simply by leveraging the framework in different manners.
Saying What You're Looking For: Linguistics Meets Video Search
Sep 20, 2013

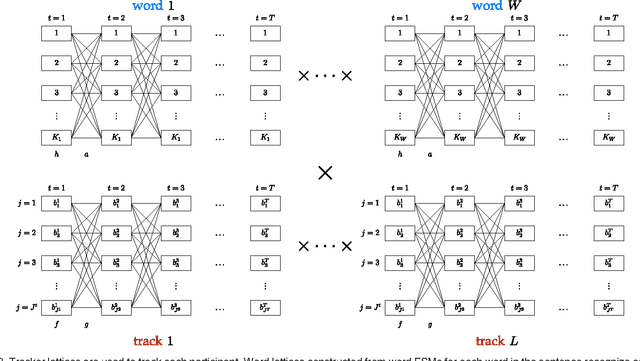

We present an approach to searching large video corpora for video clips which depict a natural-language query in the form of a sentence. This approach uses compositional semantics to encode subtle meaning that is lost in other systems, such as the difference between two sentences which have identical words but entirely different meaning: "The person rode the horse} vs. \emph{The horse rode the person". Given a video-sentence pair and a natural-language parser, along with a grammar that describes the space of sentential queries, we produce a score which indicates how well the video depicts the sentence. We produce such a score for each video clip in a corpus and return a ranked list of clips. Furthermore, this approach addresses two fundamental problems simultaneously: detecting and tracking objects, and recognizing whether those tracks depict the query. Because both tracking and object detection are unreliable, this uses knowledge about the intended sentential query to focus the tracker on the relevant participants and ensures that the resulting tracks are described by the sentential query. While earlier work was limited to single-word queries which correspond to either verbs or nouns, we show how one can search for complex queries which contain multiple phrases, such as prepositional phrases, and modifiers, such as adverbs. We demonstrate this approach by searching for 141 queries involving people and horses interacting with each other in 10 full-length Hollywood movies.
Large-Scale Automatic Labeling of Video Events with Verbs Based on Event-Participant Interaction
Apr 16, 2012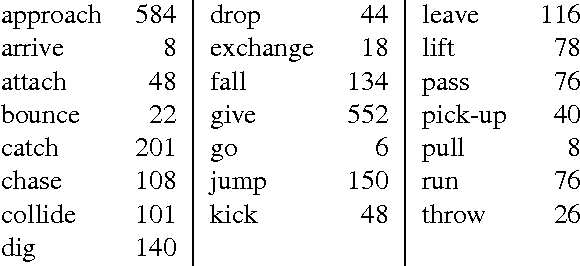



We present an approach to labeling short video clips with English verbs as event descriptions. A key distinguishing aspect of this work is that it labels videos with verbs that describe the spatiotemporal interaction between event participants, humans and objects interacting with each other, abstracting away all object-class information and fine-grained image characteristics, and relying solely on the coarse-grained motion of the event participants. We apply our approach to a large set of 22 distinct verb classes and a corpus of 2,584 videos, yielding two surprising outcomes. First, a classification accuracy of greater than 70% on a 1-out-of-22 labeling task and greater than 85% on a variety of 1-out-of-10 subsets of this labeling task is independent of the choice of which of two different time-series classifiers we employ. Second, we achieve this level of accuracy using a highly impoverished intermediate representation consisting solely of the bounding boxes of one or two event participants as a function of time. This indicates that successful event recognition depends more on the choice of appropriate features that characterize the linguistic invariants of the event classes than on the particular classifier algorithms.
Seeing Unseeability to See the Unseeable
Apr 12, 2012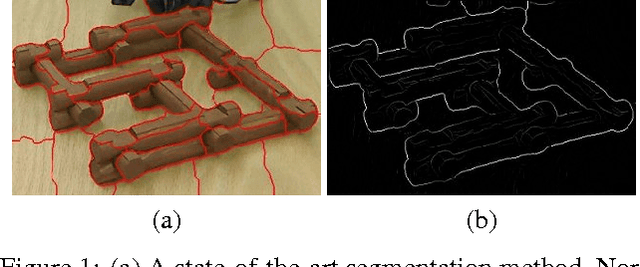
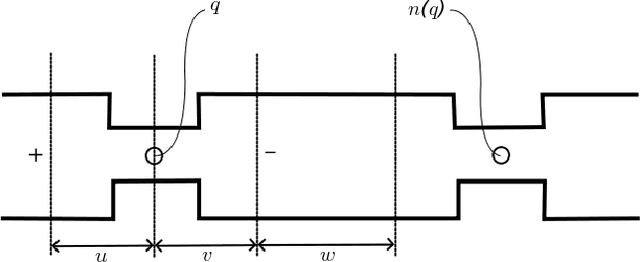

We present a framework that allows an observer to determine occluded portions of a structure by finding the maximum-likelihood estimate of those occluded portions consistent with visible image evidence and a consistency model. Doing this requires determining which portions of the structure are occluded in the first place. Since each process relies on the other, we determine a solution to both problems in tandem. We extend our framework to determine confidence of one's assessment of which portions of an observed structure are occluded, and the estimate of that occluded structure, by determining the sensitivity of one's assessment to potential new observations. We further extend our framework to determine a robotic action whose execution would allow a new observation that would maximally increase one's confidence.