 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim-to-Real Robot Learning from Pixels with Progressive Nets
May 22, 2018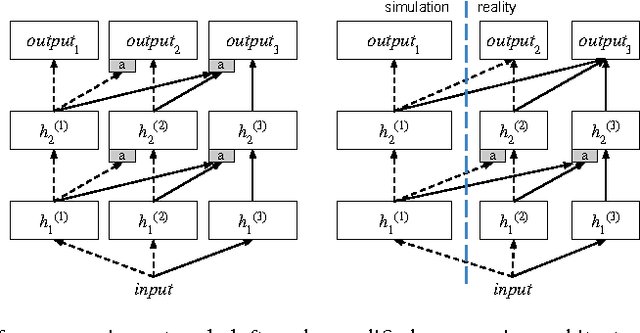

Applying end-to-end learning to solve complex, interactive, pixel-driven control tasks on a robot is an unsolved problem. Deep Reinforcement Learning algorithms are too slow to achieve performance on a real robot, but their potential has been demonstrated in simulated environments. We propose using progressive networks to bridge the reality gap and transfer learned policies from simulation to the real world. The progressive net approach is a general framework that enables reuse of everything from low-level visual features to high-level policies for transfer to new tasks, enabling a compositional, yet simple, approach to building complex skills. We present an early demonstration of this approach with a number of experiments in the domain of robot manipulation that focus on bridging the reality gap. Unlike other proposed approaches, our real-world experiments demonstrate successful task learning from raw visual input on a fully actuated robot manipulator. Moreover, rather than relying on model-based trajectory optimisation, the task learning is accomplished using only deep reinforcement learning and sparse rewards.
PathNet: Evolution Channels Gradient Descent in Super Neural Networks
Jan 30, 2017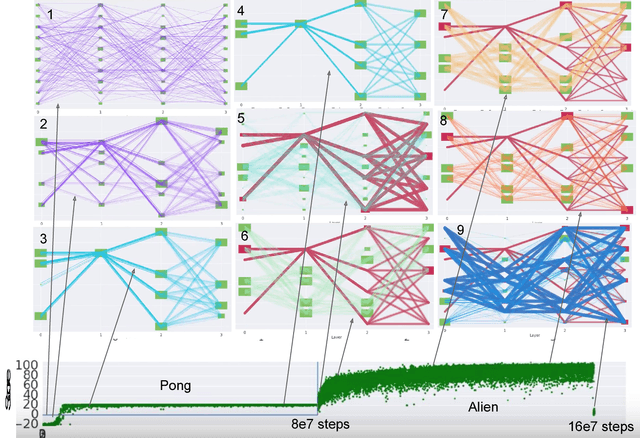
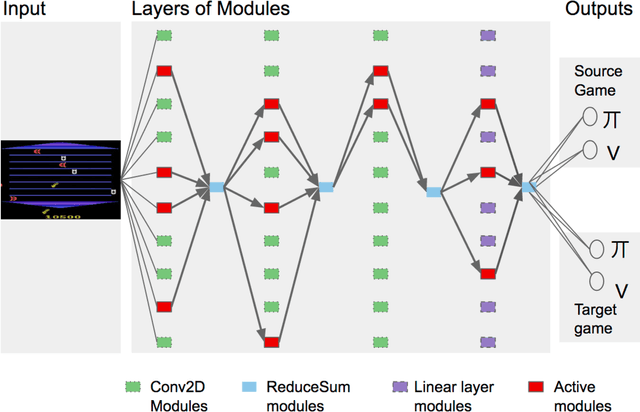
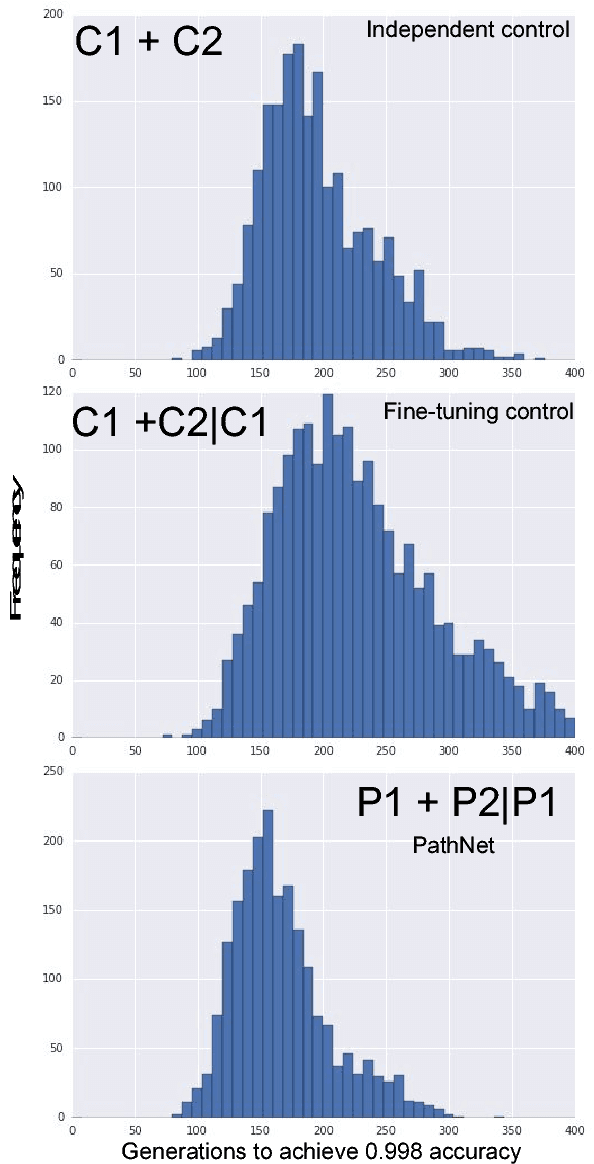
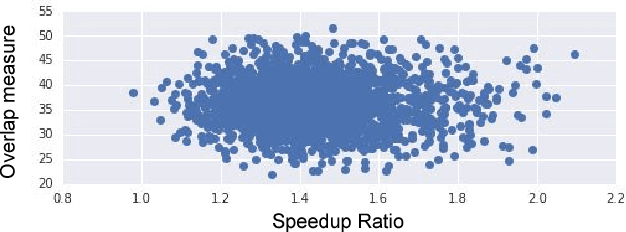
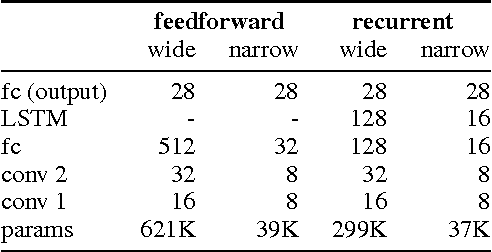
For artificial general intelligence (AGI) it would be efficient if multiple users trained the same giant neural network, permitting parameter reuse, without catastrophic forgetting. PathNet is a first step in this direction. It is a neural network algorithm that uses agents embedded in the neural network whose task is to discover which parts of the network to re-use for new tasks. Agents are pathways (views) through the network which determine the subset of parameters that are used and updated by the forwards and backwards passes of the backpropogation algorithm. During learning, a tournament selection genetic algorithm is used to select pathways through the neural network for replication and mutation. Pathway fitness is the performance of that pathway measured according to a cost function. We demonstrate successful transfer learning; fixing the parameters along a path learned on task A and re-evolving a new population of paths for task B, allows task B to be learned faster than it could be learned from scratch or after fine-tuning. Paths evolved on task B re-use parts of the optimal path evolved on task A. Positive transfer was demonstrated for binary MNIST, CIFAR, and SVHN supervised learning classification tasks, and a set of Atari and Labyrinth reinforcement learning tasks, suggesting PathNets have general applicability for neural network training. Finally, PathNet also significantly improves the robustness to hyperparameter choices of a parallel asynchronous reinforcement learning algorithm (A3C).
Overcoming catastrophic forgetting in neural networks
Jan 25, 2017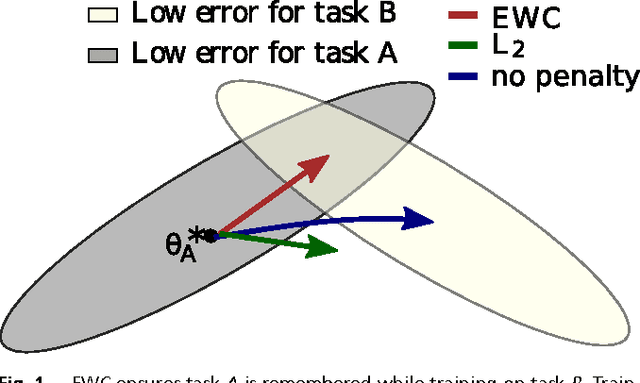
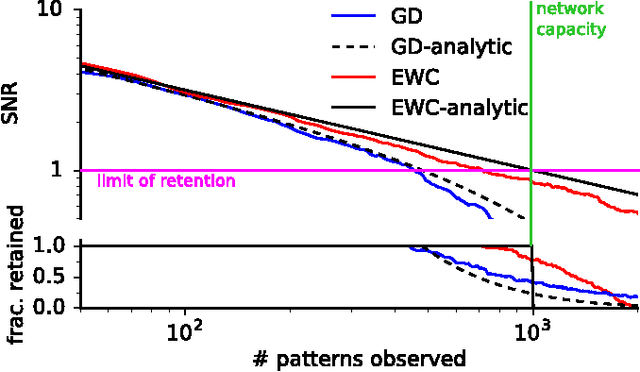
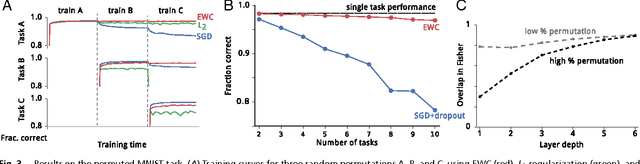
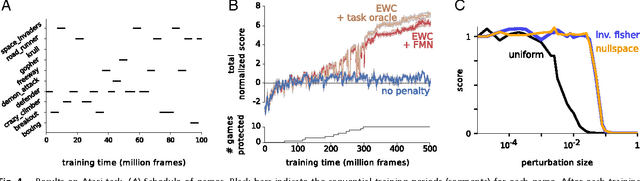
The ability to learn tasks in a sequential fashion is crucial to the development of artificial intelligence. Neural networks are not, in general, capable of this and it has been widely thought that catastrophic forgetting is an inevitable feature of connectionist models. We show that it is possible to overcome this limitation and train networks that can maintain expertise on tasks which they have not experienced for a long time. Our approach remembers old tasks by selectively slowing down learning on the weights important for those tasks. We demonstrate our approach is scalable and effective by solving a set of classification tasks based on the MNIST hand written digit dataset and by learning several Atari 2600 games sequentially.
Progressive Neural Networks
Sep 07, 2016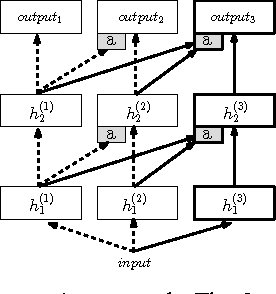
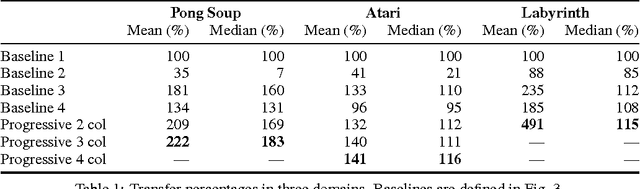

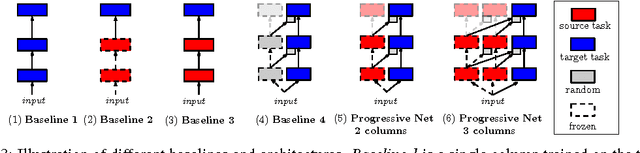
Learning to solve complex sequences of tasks--while both leveraging transfer and avoiding catastrophic forgetting--remains a key obstacle to achieving human-level intelligence. The progressive networks approach represents a step forward in this direction: they are immune to forgetting and can leverage prior knowledge via lateral connections to previously learned features. We evaluate this architecture extensively on a wide variety of reinforcement learning tasks (Atari and 3D maze games), and show that it outperforms common baselines based on pretraining and finetuning. Using a novel sensitivity measure, we demonstrate that transfer occurs at both low-level sensory and high-level control layers of the learned policy.
Policy Distillation
Jan 07, 2016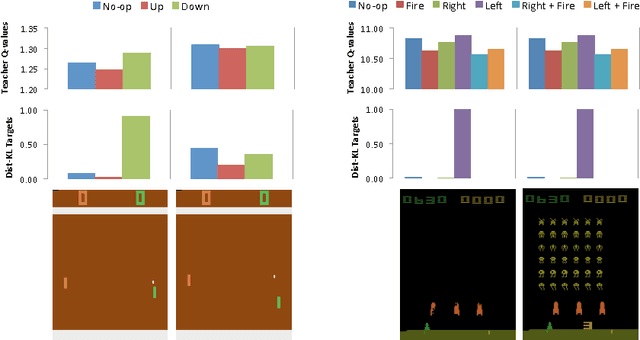
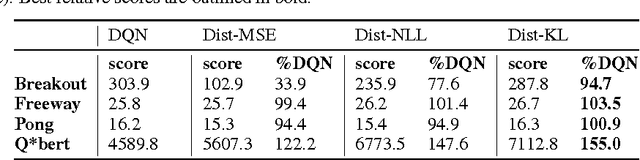
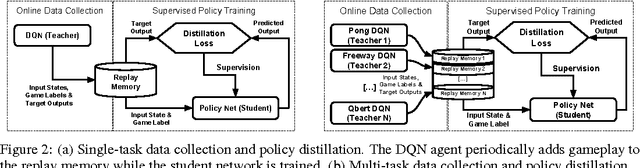
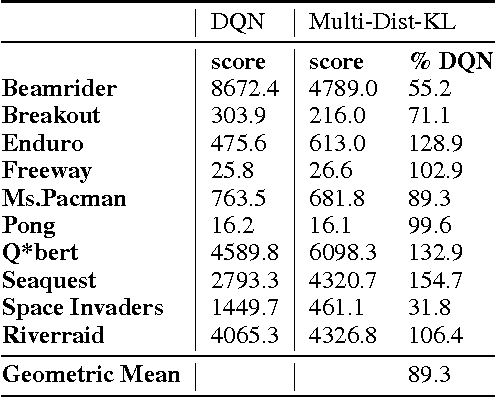
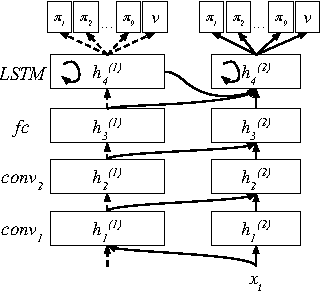
Policies for complex visual tasks have been successfully learned with deep reinforcement learning, using an approach called deep Q-networks (DQN), but relatively large (task-specific) networks and extensive training are needed to achieve good performance. In this work, we present a novel method called policy distillation that can be used to extract the policy of a reinforcement learning agent and train a new network that performs at the expert level while being dramatically smaller and more efficient. Furthermore, the same method can be used to consolidate multiple task-specific policies into a single policy. We demonstrate these claims using the Atari domain and show that the multi-task distilled agent outperforms the single-task teachers as well as a jointly-trained DQN agent.