 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating Self-Expression and Visual Content in Hashtag Supervision
Nov 27, 2017



The variety, abundance, and structured nature of hashtags make them an interesting data source for training vision models. For instance, hashtags have the potential to significantly reduce the problem of manual supervision and annotation when learning vision models for a large number of concepts. However, a key challenge when learning from hashtags is that they are inherently subjective because they are provided by users as a form of self-expression. As a consequence, hashtags may have synonyms (different hashtags referring to the same visual content) and may be ambiguous (the same hashtag referring to different visual content). These challenges limit the effectiveness of approaches that simply treat hashtags as image-label pairs. This paper presents an approach that extends upon modeling simple image-label pairs by modeling the joint distribution of images, hashtags, and users. We demonstrate the efficacy of such approaches in image tagging and retrieval experiments, and show how the joint model can be used to perform user-conditional retrieval and tagging.
Conditional Similarity Networks
Apr 10, 2017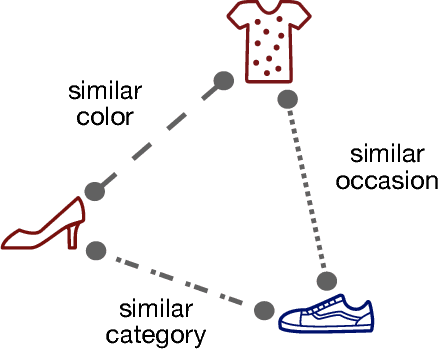

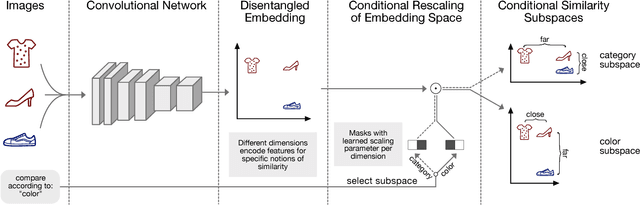

What makes images similar? To measure the similarity between images, they are typically embedded in a feature-vector space, in which their distance preserve the relative dissimilarity. However, when learning such similarity embeddings the simplifying assumption is commonly made that images are only compared to one unique measure of similarity. A main reason for this is that contradicting notions of similarities cannot be captured in a single space. To address this shortcoming, we propose Conditional Similarity Networks (CSNs) that learn embeddings differentiated into semantically distinct subspaces that capture the different notions of similarities. CSNs jointly learn a disentangled embedding where features for different similarities are encoded in separate dimensions as well as masks that select and reweight relevant dimensions to induce a subspace that encodes a specific similarity notion. We show that our approach learns interpretable image representations with visually relevant semantic subspaces. Further, when evaluating on triplet questions from multiple similarity notions our model even outperforms the accuracy obtained by training individual specialized networks for each notion separately.
Learning From Noisy Large-Scale Datasets With Minimal Supervision
Apr 10, 2017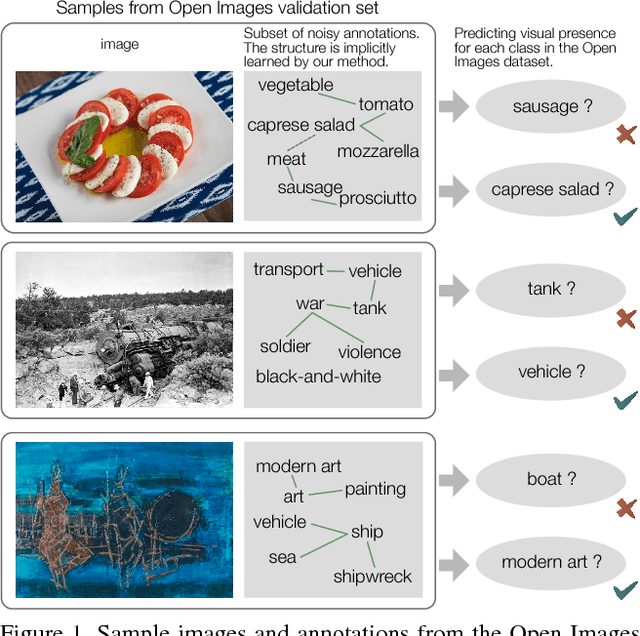
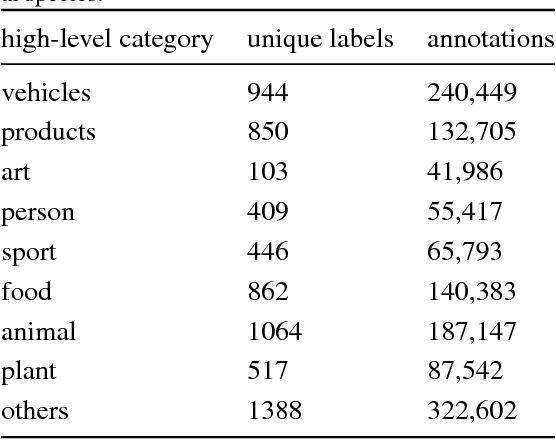
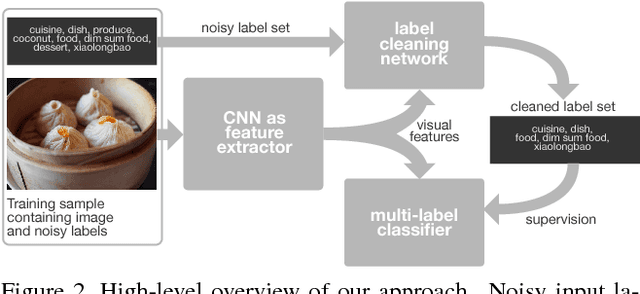
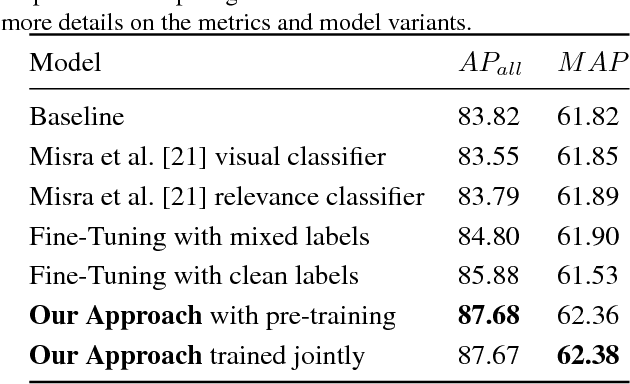
We present an approach to effectively use millions of images with noisy annotations in conjunction with a small subset of cleanly-annotated images to learn powerful image representations. One common approach to combine clean and noisy data is to first pre-train a network using the large noisy dataset and then fine-tune with the clean dataset. We show this approach does not fully leverage the information contained in the clean set. Thus, we demonstrate how to use the clean annotations to reduce the noise in the large dataset before fine-tuning the network using both the clean set and the full set with reduced noise. The approach comprises a multi-task network that jointly learns to clean noisy annotations and to accurately classify images. We evaluate our approach on the recently released Open Images dataset, containing ~9 million images, multiple annotations per image and over 6000 unique classes. For the small clean set of annotations we use a quarter of the validation set with ~40k images. Our results demonstrate that the proposed approach clearly outperforms direct fine-tuning across all major categories of classes in the Open Image dataset. Further, our approach is particularly effective for a large number of classes with wide range of noise in annotations (20-80% false positive annotations).
Residual Networks Behave Like Ensembles of Relatively Shallow Networks
Oct 27, 2016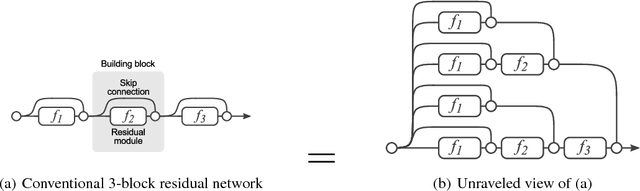
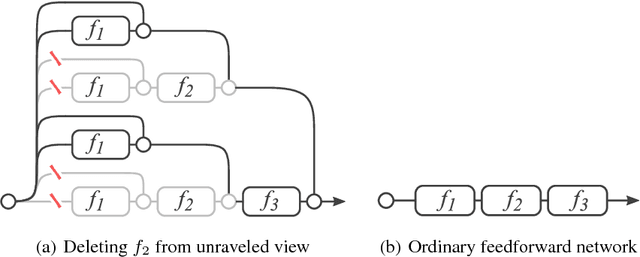
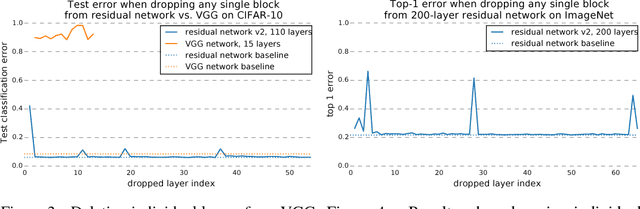
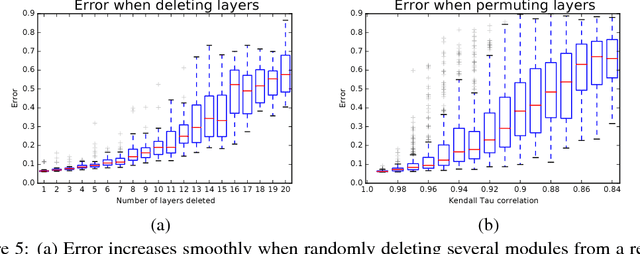
In this work we propose a novel interpretation of residual networks showing that they can be seen as a collection of many paths of differing length. Moreover, residual networks seem to enable very deep networks by leveraging only the short paths during training. To support this observation, we rewrite residual networks as an explicit collection of paths. Unlike traditional models, paths through residual networks vary in length. Further, a lesion study reveals that these paths show ensemble-like behavior in the sense that they do not strongly depend on each other. Finally, and most surprising, most paths are shorter than one might expect, and only the short paths are needed during training, as longer paths do not contribute any gradient. For example, most of the gradient in a residual network with 110 layers comes from paths that are only 10-34 layers deep. Our results reveal one of the key characteristics that seem to enable the training of very deep networks: Residual networks avoid the vanishing gradient problem by introducing short paths which can carry gradient throughout the extent of very deep networks.
COCO-Text: Dataset and Benchmark for Text Detection and Recognition in Natural Images
Jun 19, 2016

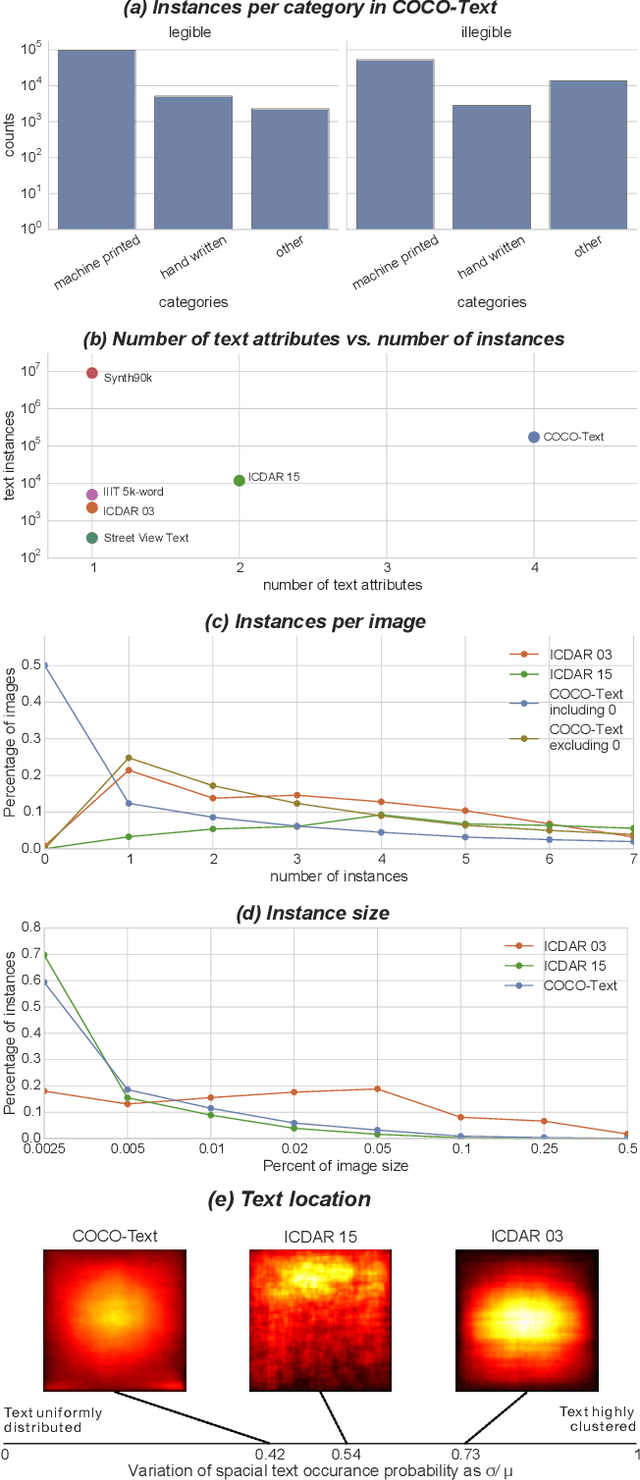
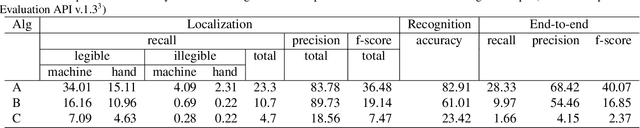
This paper describes the COCO-Text dataset. In recent years large-scale datasets like SUN and Imagenet drove the advancement of scene understanding and object recognition. The goal of COCO-Text is to advance state-of-the-art in text detection and recognition in natural images. The dataset is based on the MS COCO dataset, which contains images of complex everyday scenes. The images were not collected with text in mind and thus contain a broad variety of text instances. To reflect the diversity of text in natural scenes, we annotate text with (a) location in terms of a bounding box, (b) fine-grained classification into machine printed text and handwritten text, (c) classification into legible and illegible text, (d) script of the text and (e) transcriptions of legible text. The dataset contains over 173k text annotations in over 63k images. We provide a statistical analysis of the accuracy of our annotations. In addition, we present an analysis of three leading state-of-the-art photo Optical Character Recognition (OCR) approaches on our dataset. While scene text detection and recognition enjoys strong advances in recent years, we identify significant shortcomings motivating future work.
On Optimizing Human-Machine Task Assignments
Sep 24, 2015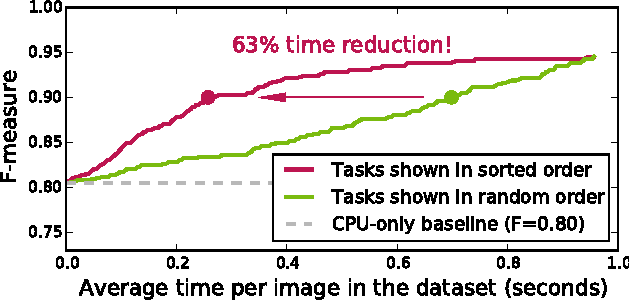
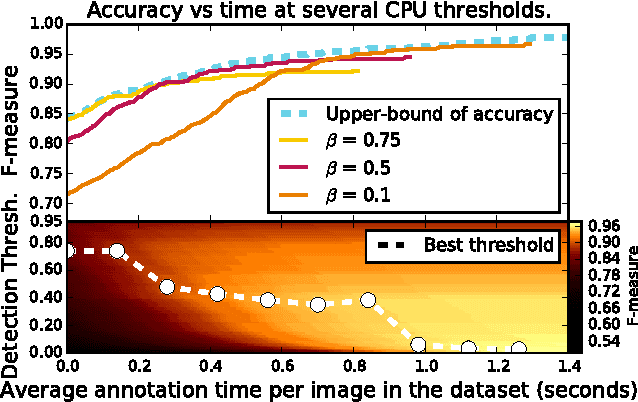
When crowdsourcing systems are used in combination with machine inference systems in the real world, they benefit the most when the machine system is deeply integrated with the crowd workers. However, if researchers wish to integrate the crowd with "off-the-shelf" machine classifiers, this deep integration is not always possible. This work explores two strategies to increase accuracy and decrease cost under this setting. First, we show that reordering tasks presented to the human can create a significant accuracy improvement. Further, we show that greedily choosing parameters to maximize machine accuracy is sub-optimal, and joint optimization of the combined system improves performance.
Learning Visual Clothing Style with Heterogeneous Dyadic Co-occurrences
Sep 24, 2015
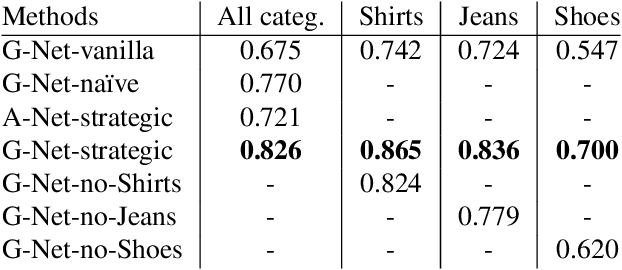
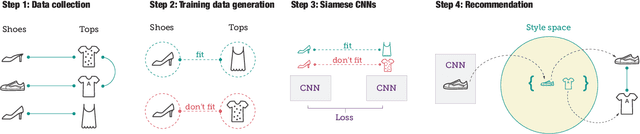

With the rapid proliferation of smart mobile devices, users now take millions of photos every day. These include large numbers of clothing and accessory images. We would like to answer questions like `What outfit goes well with this pair of shoes?' To answer these types of questions, one has to go beyond learning visual similarity and learn a visual notion of compatibility across categories. In this paper, we propose a novel learning framework to help answer these types of questions. The main idea of this framework is to learn a feature transformation from images of items into a latent space that expresses compatibility. For the feature transformation, we use a Siamese Convolutional Neural Network (CNN) architecture, where training examples are pairs of items that are either compatible or incompatible. We model compatibility based on co-occurrence in large-scale user behavior data; in particular co-purchase data from Amazon.com. To learn cross-category fit, we introduce a strategic method to sample training data, where pairs of items are heterogeneous dyads, i.e., the two elements of a pair belong to different high-level categories. While this approach is applicable to a wide variety of settings, we focus on the representative problem of learning compatible clothing style. Our results indicate that the proposed framework is capable of learning semantic information about visual style and is able to generate outfits of clothes, with items from different categories, that go well together.
Household Electricity Demand Forecasting -- Benchmarking State-of-the-Art Methods
Apr 01, 2014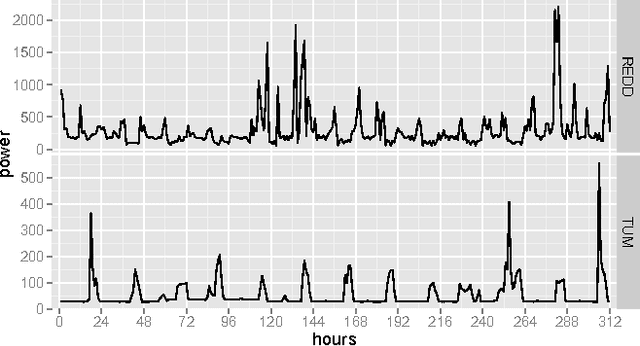
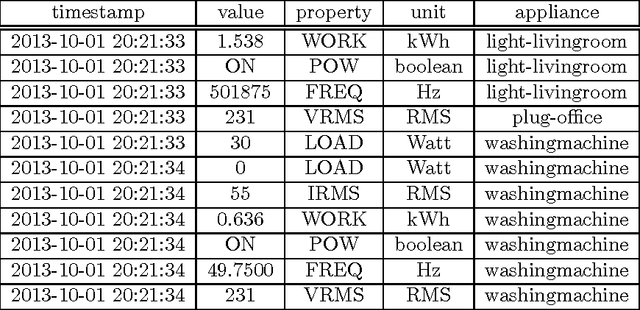
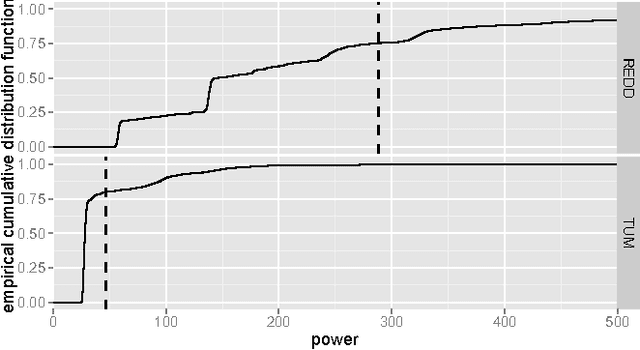
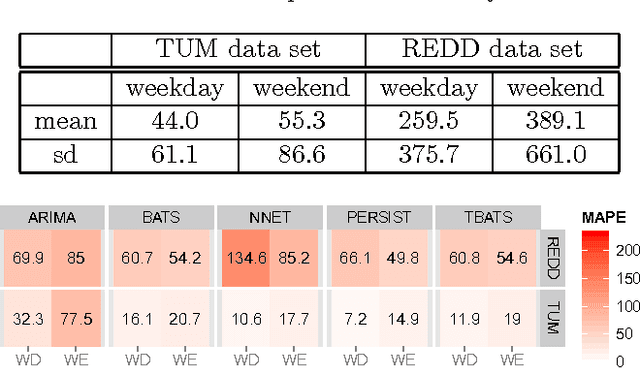
The increasing use of renewable energy sources with variable output, such as solar photovoltaic and wind power generation, calls for Smart Grids that effectively manage flexible loads and energy storage. The ability to forecast consumption at different locations in distribution systems will be a key capability of Smart Grids. The goal of this paper is to benchmark state-of-the-art methods for forecasting electricity demand on the household level across different granularities and time scales in an explorative way, thereby revealing potential shortcomings and find promising directions for future research in this area. We apply a number of forecasting methods including ARIMA, neural networks, and exponential smoothening using several strategies for training data selection, in particular day type and sliding window based strategies. We consider forecasting horizons ranging between 15 minutes and 24 hours. Our evaluation is based on two data sets containing the power usage of individual appliances at second time granularity collected over the course of several months. The results indicate that forecasting accuracy varies significantly depending on the choice of forecasting methods/strategy and the parameter configuration. Measured by the Mean Absolute Percentage Error (MAPE), the considered state-of-the-art forecasting methods rarely beat corresponding persistence forecasts. Overall, we observed MAPEs in the range between 5 and >100%. The average MAPE for the first data set was ~30%, while it was ~85% for the other data set. These results show big room for improvement. Based on the identified trends and experiences from our experiments, we contribute a detailed discussion of promising future research.